翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
PostgreSQL プールモデル
プールモデルは、単一の PostgreSQL インスタンス (Amazon RDS または Aurora) をプロビジョニングし、行レベルのセキュリティ (RLS)SELECTクエリによって返されるテーブル内の行、または INSERT、、UPDATEおよび DELETE コマンドによって影響を受ける行を制限します。プールモデルは、すべてのテナントデータを 1 つの PostgreSQL スキーマに一元化するため、コスト効率が大幅に向上し、維持する運用オーバーヘッドが少なくなります。このソリューションのモニタリングも、一元化により大幅に簡素化されます。ただし、プールモデルでテナント固有の影響をモニタリングするには、通常、アプリケーションで追加の計測が必要です。これは、デフォルトで PostgreSQL はどのテナントがリソースを消費しているかを認識しないためです。新しいインフラストラクチャが不要なため、テナントのオンボーディングが簡素化されます。この俊敏性により、テナントオンボーディングワークフローの迅速で自動化された実行が容易になります。
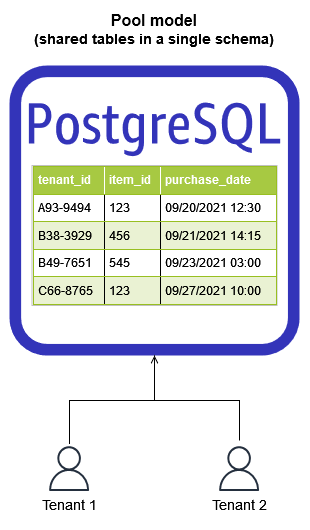
プールモデルは一般的にコスト効率が高く、管理が容易ですが、いくつかの欠点があります。ノイズの多い近隣現象をプールモデルで完全に排除することはできません。ただし、PostgreSQL インスタンスで適切なリソースを利用できるようにし、クエリをリードレプリカや Amazon ElastiCache にオフロードするなど、PostgreSQL の負荷を軽減するための戦略を使用することで軽減できます。アプリケーション計測はテナント固有のアクティビティをログに記録してモニタリングできるため、効果的なモニタリングはテナントのパフォーマンス分離の懸念への対応にも役立ちます。最後に、一部の SaaS のお客様は、RLS が提供する論理的な分離で十分ではないと判断し、追加の分離対策を要求する場合があります。
