如需與 Amazon Timestream for LiveAnalytics 類似的功能,請考慮使用 Amazon Timestream for InfluxDB。它提供簡化的資料擷取和單一位數毫秒查詢回應時間,以進行即時分析。在這裡進一步了解。
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Architecture
Amazon Timestream for Live Analytics 從頭開始設計,以大規模收集、存放和處理時間序列資料。其無伺服器架構支援可獨立擴展的完全解耦資料擷取、儲存和查詢處理系統。此設計可簡化每個子系統,讓您更輕鬆地實現不變的可靠性、消除擴展瓶頸,並減少相關系統故障的機會。隨著系統擴展,每個因素都變得更加重要。
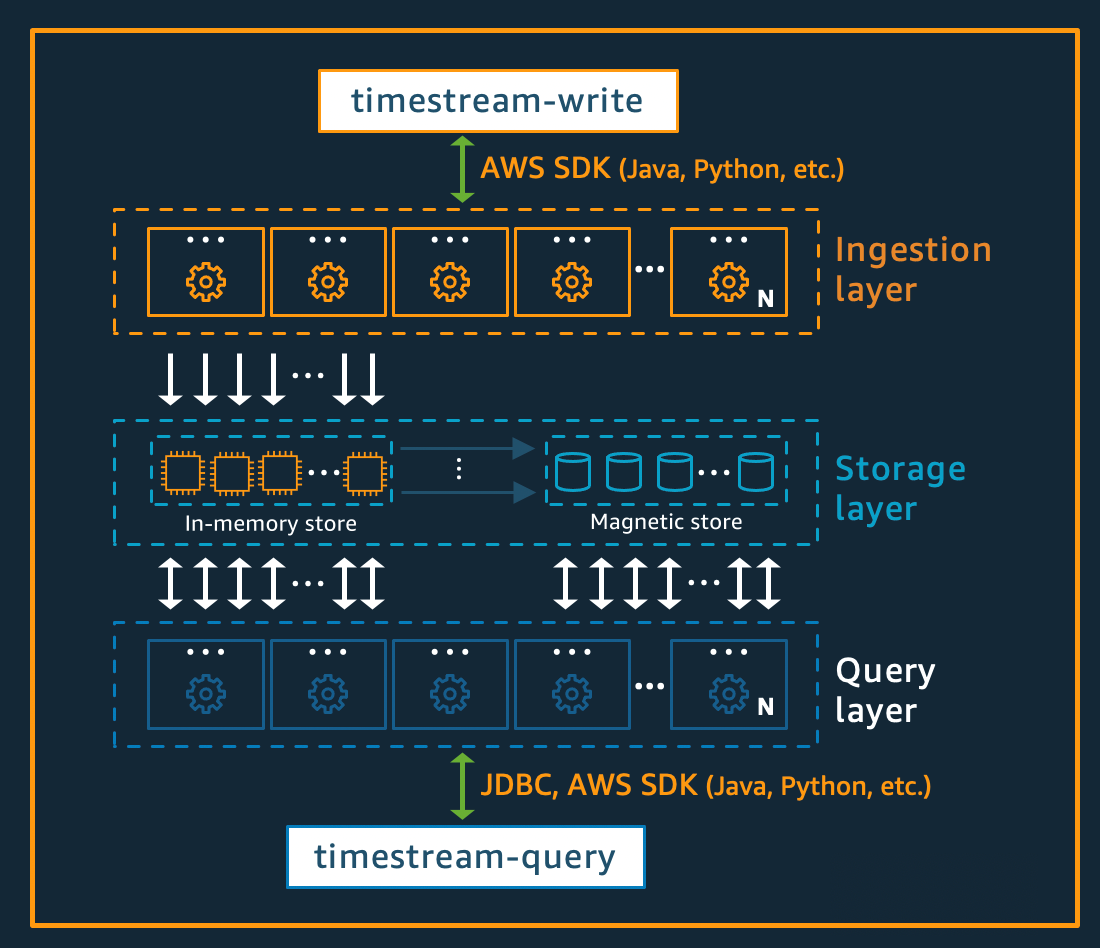
寫入架構
寫入時間序列資料時,Amazon Timestream for Live Analytics 會將資料表、分割區的寫入路由至處理高輸送量資料寫入的容錯記憶體存放區執行個體。記憶體存放區接著會在不同的儲存系統中實現耐用性,將資料複寫至三個可用區域 (AZs)。複寫是以規定人數為基礎,因此節點或整個可用區域遺失不會中斷寫入可用性。在近乎即時的時間內,其他記憶體內儲存節點會同步至資料,以提供查詢。讀取器複本節點也會跨越 AZs,以確保高可用性。
Timestream for Live Analytics 支援將資料直接寫入磁性存放區,適用於產生較低輸送量延遲產生資料的應用程式。延遲抵達資料是指時間戳記早於目前時間的資料。與記憶體存放區中的高輸送量寫入類似,寫入磁性存放區的資料會複寫到三個 AZs,而複寫是以規定人數為基礎。
無論是將資料寫入記憶體或磁性存放區,Timestream for Live Analytics 都會在資料寫入儲存體之前自動編製索引和分割資料。單一 Timestream for Live Analytics 資料表可能會有數百個、數千個或甚至數百萬個分割區。個別分割區不會直接彼此通訊,也不會共用任何資料 (共用無架構)。而是透過高可用性的分割區追蹤和索引服務來追蹤資料表的分割區。這提供了另一個分離問題,專門為了將系統中的故障影響降至最低,並使相互關聯的故障不太可能發生。
儲存架構
當資料存放在 Timestream for Live Analytics 中時,資料會根據資料寫入的內容屬性,依時間順序以及跨時間進行組織。除了時間之外,具有分隔「空間」的分割方案對於大規模擴展時間序列系統非常重要。這是因為大多數的時間序列資料是在目前時間或前後寫入。因此,僅按時間分割在分配寫入流量或允許在查詢時間有效剔除資料方面沒有什麼好處。這對極端擴展時間序列處理很重要,它允許 Timestream for Live Analytics 以無伺服器方式擴展比其他主要系統更高的數量級。產生的分割區稱為「平鋪」,因為它們代表二維空間 (設計為類似大小) 的分割。Live Analytics 資料表的時間串流會以單一分割區 (並排) 開始,然後視需要在空間維度中分割。當圖磚達到特定大小時,就會在時間維度中分割,以便在資料大小增加時實現更好的讀取平行處理。
Timestream for Live Analytics 旨在自動管理時間序列資料的生命週期。Timestream for Live Analytics 提供兩個資料存放區:記憶體內存放區和經濟實惠的磁性存放區。它也支援設定資料表層級政策,以自動跨存放區傳輸資料。傳入的高輸送量資料寫入會落在記憶體存放區中,其中的資料已針對寫入進行最佳化,以及針對目前時間執行的讀取,以強化儀表板和警示類型查詢。當寫入、警示和儀表板需求的主要時間範圍已過時,可讓資料自動從記憶體存放區流向磁性存放區,以最佳化成本。Timestream for Live Analytics 允許為此目的在記憶體存放區上設定資料保留政策。延遲抵達資料的資料寫入會直接寫入磁性存放區。
一旦資料在磁性存放區中可用 (由於記憶體存放區保留期過期或直接寫入磁性存放區),就會將其重組為針對大型磁碟區資料讀取進行高度最佳化的格式。磁性存放區也有資料保留政策,如果資料超過其實用性的時間閾值,則可以設定該政策。當資料超過為磁性存放區保留政策定義的時間範圍時,會自動將其移除。因此,使用 Timestream for Live Analytics,除了某些組態之外,資料生命週期管理會在幕後無縫進行。
查詢架構
即時分析查詢的時間串流是以 SQL 文法表示,該文法具有時間序列特定支援 (時間序列特定資料類型和函數) 的延伸,因此熟悉 SQL 的開發人員可以輕鬆學習曲線。然後,由自適應的分散式查詢引擎處理查詢,該引擎使用來自圖磚追蹤和索引服務的中繼資料,在發出查詢時無縫存取和合併跨資料存放區的資料。這使得體驗與客戶產生良好的共鳴,因為它會將許多 Rube Goldberg 複雜性摺疊成簡單且熟悉的資料庫抽象。
查詢是由專用工作者群執行,其中註冊執行指定查詢的工作者數量取決於查詢複雜性和資料大小。在查詢執行時間機群和系統的儲存機群上,透過大量平行處理來實現對大型資料集的複雜查詢效能。快速且有效率地分析大量資料的能力是 Timestream for Live Analytics 的最大優勢之一。執行超過 TB 或甚至 PB 資料的單一查詢,可能會有數千台機器同時運作。
行動架構
為了確保 Timestream for Live Analytics 可以為您的應用程式提供幾乎無限的擴展,同時確保 99.99% 的可用性,系統也使用行動架構設計。Timestream for Live Analytics 不會將系統整體擴展,而是將其分割成多個較小的複本,稱為儲存格。這允許以完整規模測試儲存格,並防止一個儲存格中的系統問題影響指定區域中任何其他儲存格中的活動。雖然 Timestream for Live Analytics 旨在支援每個區域的多個儲存格,但請考慮以下虛構案例,其中一個區域中有 2 個儲存格。
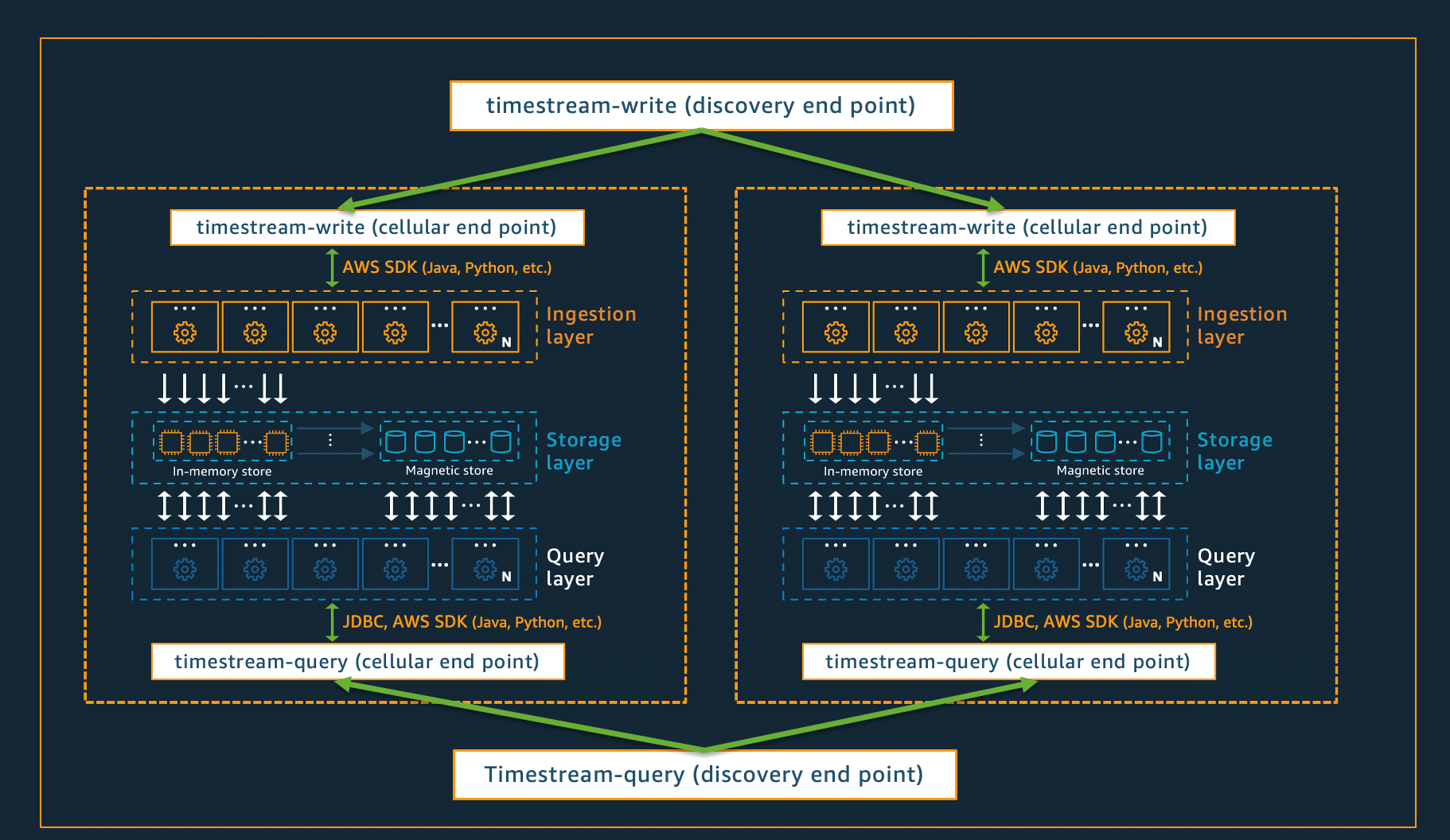
在上述案例中,資料擷取和查詢請求會先由探索端點分別處理,以進行資料擷取和查詢。然後,探索端點會識別包含客戶資料的儲存格,並將請求導向至該儲存格的適當擷取或查詢端點。使用 SDKs時,這些端點管理任務會透明地為您處理。
注意
