本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 Amazon SageMaker HyperPod 中使用彈性訓練
彈性訓練是新的 Amazon SageMaker HyperPod 功能,可根據運算資源可用性和工作負載優先順序自動擴展訓練任務。彈性訓練任務可以從模型訓練所需的最低運算資源開始,並透過跨不同節點組態 (世界大小) 的自動檢查點和恢復來動態擴展或縮減。透過自動調整資料平行複本的數量來實現擴展。在高叢集使用率期間,彈性訓練任務可設定為自動縮減規模,以回應較高優先順序任務的資源請求,為關鍵工作負載釋放運算能力。當資源在離峰期間釋放時,彈性訓練任務會自動縮減規模以加速訓練,然後在較高優先順序的工作負載再次需要資源時縮減規模。
彈性訓練建置在 HyperPod 訓練運算子之上,並整合下列元件:
-
任務佇列、優先順序和排程的 Amazon SageMaker HyperPod 任務控管
-
PyTorch 分散式檢查點 (DCP)
用於可擴展狀態和檢查點管理,例如 DCP
支援的架構
-
PyTorch 搭配分散式資料平行 (DDP) 和全碎片資料平行 (FSDP)
-
PyTorch 分散式檢查點 (DCP)
先決條件
SageMaker HyperPod EKS 叢集
您必須具有執行中具有 Amazon EKS 協同運作的 SageMaker HyperPod 叢集。如需建立 HyperPod EKS 叢集的資訊,請參閱:
SageMaker HyperPod 訓練運算子
訓練運算子 v. 1.2 及更高版本支援 Elastic Training。
若要將訓練運算子安裝為 EKS 附加元件,請參閱:https://https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-eks-operator-install.html
(建議) 安裝和設定任務控管和 Kueue
建議您透過 HyperPod 任務控管來安裝和設定 Kueue,以透過彈性訓練指定工作負載優先順序。Kueue 提供更強大的工作負載管理,其具有佇列、優先順序、分類排程、資源追蹤和優雅先佔,對於在多租戶訓練環境中操作至關重要。
-
Gang 排程可確保訓練任務的所有必要 Pod 一起啟動。這可防止某些 Pod 啟動,而其他 Pod 則保持待定狀態,這可能會導致資源浪費。
-
溫和的先佔允許較低優先順序的彈性任務,為較高優先順序的工作負載產生資源。彈性任務可以正常擴展,而不會被強制移出,從而改善整體叢集穩定性。
建議您設定下列 Kueue 元件:
-
定義相對任務重要性的 PriorityClasses
-
ClusterQueues 可管理跨團隊或工作負載的全域資源共用和配額
-
LocalQueues 將任務從個別命名空間路由到適當的 ClusterQueue
如需更進階的設定,您也可以納入:
-
公平共用政策,以平衡多個團隊的資源用量
-
自訂先佔規則以強制執行組織 SLAs 或成本控制
請參閱:
(建議) 設定使用者命名空間和資源配額
在 Amazon EKS 上部署此功能時,我們建議套用一組基礎叢集層級組態,以確保團隊之間的隔離、資源公平性和營運一致性。
命名空間和存取組態
為每個團隊或專案使用不同的命名空間來組織工作負載。這可讓您套用精細隔離和控管。我們也建議您設定 AWS IAM 到 Kubernetes RBAC 映射,將個別 IAM 使用者或角色與其對應的命名空間建立關聯。
關鍵實務包括:
-
當工作負載需要 AWS 許可時,使用 IAM Roles for Service Accounts (IRSA) 將 IAM 角色映射至 Kubernetes 服務帳戶。https://https://docs.aws.amazon.com/eks/latest/userguide/access-entries.html
-
套用 RBAC 政策,將使用者限制為其指定的命名空間 (例如
Role/RoleBinding而非整個叢集的許可)。
資源和運算限制
為了防止資源爭用並確保團隊之間的公平排程,請在命名空間層級套用配額和限制:
-
ResourceQuotas 可限制彙總 CPU、記憶體、儲存體和物件計數 (Pod、PVCs、服務等)。
-
LimitRanges 可強制執行預設和最高每個 Pod 或每個容器 CPU 和記憶體限制。
-
視需要使用 PodDisruptionBudgets (PDBs) 來定義彈性期望。
-
選用:命名空間層級佇列限制 (例如,透過任務控管或 Kueue),以防止使用者過度提交任務。
這些限制條件有助於維持叢集穩定性,並支援分散式訓練工作負載的可預測排程。
自動調整規模
SageMaker HyperPod on EKS 支援透過 Karpenter 進行叢集自動擴展。當 Karpenter 或類似資源佈建器與彈性訓練搭配使用時,叢集以及彈性訓練任務可能會在彈性訓練任務提交後自動擴展。這是因為彈性訓練運算子採取貪婪的方法, 一律會要求超過可用的運算資源,直到達到任務設定的最大限制為止。這是因為彈性訓練運算子會持續請求其他資源,做為彈性任務執行的一部分,這可能會觸發節點佈建。Karpenter 等持續資源佈建器將透過擴展運算叢集來提供請求。
為了讓這些擴展可預測且受到控制,建議您在建立彈性訓練任務的命名空間中設定命名空間層級 ResourceQuotas。ResourceQuotas 有助於限制任務可請求的最大資源,防止不受限制的叢集成長,同時仍允許定義限制內的彈性行為。
例如,適用於 8 ml.p5.48xlarge 執行個體的 ResourceQuota 將具有下列形式:
apiVersion: v1 kind: ResourceQuota metadata: name: <quota-name> namespace: <namespace-name> spec: hard: nvidia.com/gpu: "64" vpc.amazonaws.com/efa: "256" requests.cpu: "1536" requests.memory: "5120Gi" limits.cpu: "1536" limits.memory: "5120Gi"
建置訓練容器
HyperPod 訓練運算子使用透過 HyperPod Elastic Agent python 套件 (https://www.piwheels.org/project/hyperpod-elastic-agent/torchrun命令取代為 hyperpodrun以啟動訓練。如需詳細資訊,請參閱:
訓練容器範例:
FROM ... ... RUN pip install hyperpod-elastic-agent ENTRYPOINT ["entrypoint.sh"] # entrypoint.sh ... hyperpodrun --nnodes=node_count --nproc-per-node=proc_count \ --rdzv-backend hyperpod \ # Optional ... # Other torchrun args # pre-traing arg_group --pre-train-script pre.sh --pre-train-args "pre_1 pre_2 pre_3" \ # post-train arg_group --post-train-script post.sh --post-train-args "post_1 post_2 post_3" \ training.py --script-args
訓練程式碼修改
SageMaker HyperPod 提供一組已設定為使用彈性政策執行的配方。
若要啟用自訂 PyTorch 訓練指令碼的彈性訓練,您需要對訓練迴圈進行細微修改。本指南會逐步解說必要的修改,以確保您的訓練任務回應運算資源可用性變更時發生的彈性擴展事件。在所有彈性事件 (例如,節點可用或節點已先佔) 期間,訓練任務會收到彈性事件訊號,用於透過儲存檢查點來協調正常關機,並使用新世界組態從儲存的檢查點重新啟動來繼續訓練。若要使用自訂訓練指令碼啟用彈性訓練,您需要:
偵測彈性擴展事件
在您的訓練迴圈中,檢查每次反覆運算期間的彈性事件:
from hyperpod_elastic_agent.elastic_event_handler import elastic_event_detected def train_epoch(model, dataloader, optimizer, args): for batch_idx, batch_data in enumerate(dataloader): # Forward and backward pass loss = model(batch_data).loss loss.backward() optimizer.step() optimizer.zero_grad() # Handle checkpointing and elastic scaling should_checkpoint = (batch_idx + 1) % args.checkpoint_freq == 0 elastic_event = elastic_event_detected() # Save checkpoint if scaling-up or scaling down job if should_checkpoint or elastic_event: save_checkpoint(model, optimizer, scheduler, checkpoint_dir=args.checkpoint_dir, step=global_step) if elastic_event: print("Elastic scaling event detected. Checkpoint saved.") return
實作檢查點儲存和檢查點載入
注意:我們建議您使用 PyTorch 分散式檢查點 (DCP) 來儲存模型和最佳化工具狀態,因為 DCP 支援從世界大小不同的檢查點恢復。其他檢查點格式可能不支援不同世界大小的檢查點載入,在這種情況下,您將需要實作自訂邏輯來處理動態世界大小變更。
import torch.distributed.checkpoint as dcp from torch.distributed.checkpoint.state_dict import get_state_dict, set_state_dict def save_checkpoint(model, optimizer, lr_scheduler, user_content, checkpoint_path): """Save checkpoint using DCP for elastic training.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler, **user_content } dcp.save( state_dict=state_dict, storage_writer=dcp.FileSystemWriter(checkpoint_path) ) def load_checkpoint(model, optimizer, lr_scheduler, checkpoint_path): """Load checkpoint using DCP with automatic resharding.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler } dcp.load( state_dict=state_dict, storage_reader=dcp.FileSystemReader(checkpoint_path) ) return model, optimizer, lr_scheduler
(選用) 使用具狀態資料載入器
如果您只針對單一 epoch 進行訓練 (亦即,透過整個資料集傳遞一次),則模型必須只看到每個資料範例一次。如果訓練任務在 epoch 中停止,並以不同的世界大小繼續,如果未保留資料載入器狀態,則會重複先前處理的資料範例。狀態資料載入器透過儲存和還原資料載入器的位置來防止這種情況,確保繼續執行會從彈性擴展事件繼續,而無需重新處理任何範例。我們建議使用 StatefulDataLoaderstate_dict()和 torch.utils.data.DataLoader load_state_dict()方法的插入式取代,啟用資料載入程序的時段中檢查點。
提交彈性訓練任務
HyperPod 訓練運算子會定義新的資源類型 - hyperpodpytorchjob。彈性訓練會擴展此資源類型,並新增以下反白顯示的欄位:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 1 maxReplicas: 4 # Increment amount of pods in fixed-size groups # Amount of pods will be equal to minReplicas + N * replicaIncrementStep replicaIncrementStep: 1 # ... or Provide an exact amount of pods that required for training replicaDiscreteValues: [2,4,8] # How long traing operator wait job to save checkpoint and exit during # scaling events. Job will be force-stopped after this period of time gracefulShutdownTimeoutInSeconds: 600 # When scaling event is detected: # how long job controller waits before initiate scale-up. # Some delay can prevent from frequent scale-ups and scale-downs scalingTimeoutInSeconds: 60 # In case of faults, specify how long elastic training should wait for # recovery, before triggering a scale-down faultyScaleDownTimeoutInSeconds: 30 ... replicaSpecs: - name: pods replicas: 4 # Initial replica count maxReplicas: 8 # Max for this replica spec (should match elasticPolicy.maxReplicas) ...
使用 kubectl
您之後可以使用下列命令啟動彈性訓練。
kubectl apply -f elastic-training-job.yaml
使用 SageMaker 配方
彈性訓練任務可以透過 SageMaker HyperPod 配方
注意
我們已在 Hyperpod Recipe 上包含 46 個 SFO 和 DPO 任務的彈性配方。使用者可以在現有的靜態啟動器指令碼上,使用一行變更來啟動這些任務:
++recipes.elastic_policy.is_elastic=true
除了靜態配方之外,彈性配方還會新增下列欄位來定義彈性行為:
彈性政策
elastic_policy 欄位定義彈性訓練任務的任務層級組態,其具有下列組態:
-
is_elastic:bool- 如果此任務是彈性任務 -
min_nodes:int- 用於彈性訓練的節點數量下限 -
max_nodes:int- 用於彈性訓練的節點數量上限 -
replica_increment_step: -int固定大小群組中 Pod 的增量量,此欄位與我們稍後scale_config定義的 互斥。 -
use_graceful_shutdown:bool如果在擴展事件期間使用正常關機,則預設為true。 -
scaling_timeout:int- 逾時前擴展事件期間的等待時間,以秒為單位 -
graceful_shutdown_timeout:int- 正常關機的等待時間
以下是此欄位的範例定義,您也可以在配方中的 Hyperpod Recipe 儲存庫中找到 : recipes_collection/recipes/fine-tuning/llama/llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.yaml
<static recipe> ... elastic_policy: is_elastic: true min_nodes: 1 max_nodes: 16 use_graceful_shutdown: true scaling_timeout: 600 graceful_shutdown_timeout: 600
擴展組態
scale_config 欄位定義每個特定擴展的覆寫組態。這是索引鍵/值字典,其中索引鍵是代表目標縮放的整數,而值是基礎配方的子集。我們<key>大規模使用 <value>來更新基本/靜態配方中的特定組態。以下顯示此欄位的範例:
scale_config: ... 2: trainer: num_nodes: 2 training_config: training_args: train_batch_size: 128 micro_train_batch_size: 8 learning_rate: 0.0004 3: trainer: num_nodes: 3 training_config: training_args: train_batch_size: 128 learning_rate: 0.0004 uneven_batch: use_uneven_batch: true num_dp_groups_with_small_batch_size: 16 small_local_batch_size: 5 large_local_batch_size: 6 ...
上述組態定義規模為 2 和 3 的訓練組態。在這兩種情況下,我們使用學習率 4e-4,批次大小為 128。但是,在規模 2 時,我們使用 8 micro_train_batch_size的 ,而規模 3 時,我們使用不均勻的批次大小,因為訓練批次大小無法平均分割到 3 個節點。
不均勻的批次大小
這是定義全域批次大小無法平均除以排名數時批次分佈行為的欄位。它並非專屬於彈性訓練,但它是實現更精細擴展精細度的功能。
-
use_uneven_batch:bool- 如果使用不均勻的批次分佈 -
num_dp_groups_with_small_batch_size:int- 在不均勻的批次分佈中,有些排名使用較小的本機批次大小,而其他排名則使用較大的批次大小。全域批次大小應等於small_local_batch_size * num_dp_groups_with_small_batch_size + (world_size-num_dp_groups_with_small_batch_size) * large_local_batch_size -
small_local_batch_size:int- 此值是較小的本機批次大小 -
large_local_batch_size:int- 此值是較大的本機批次大小
在 MLFlow 上監控訓練
Hyperpod 配方任務支援透過 MLFlow 的可觀測性。使用者可以在配方中指定 MLFlow 組態:
training_config: mlflow: tracking_uri: "<local_file_path or MLflow server URL>" run_id: "<MLflow run ID>" experiment_name: "<MLflow experiment name, e.g. llama_exps>" run_name: "<run name, e.g. llama3.1_8b>"
這些組態會對應至對應的 MLFlow 設定
定義彈性配方之後,我們可以使用啟動器指令碼,例如 launcher_scripts/llama/run_llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.sh 來啟動彈性訓練任務。這類似於使用 Hyperpod 配方啟動靜態任務。
注意
配方支援的彈性訓練任務會自動從最新的檢查點繼續,不過,根據預設,每次重新啟動都會建立新的訓練目錄。若要正確啟用從最後一個檢查點繼續,我們需要確保重複使用相同的訓練目錄。這可以透過設定
recipes.training_config.training_args.override_training_dir=true
使用案例範例和限制
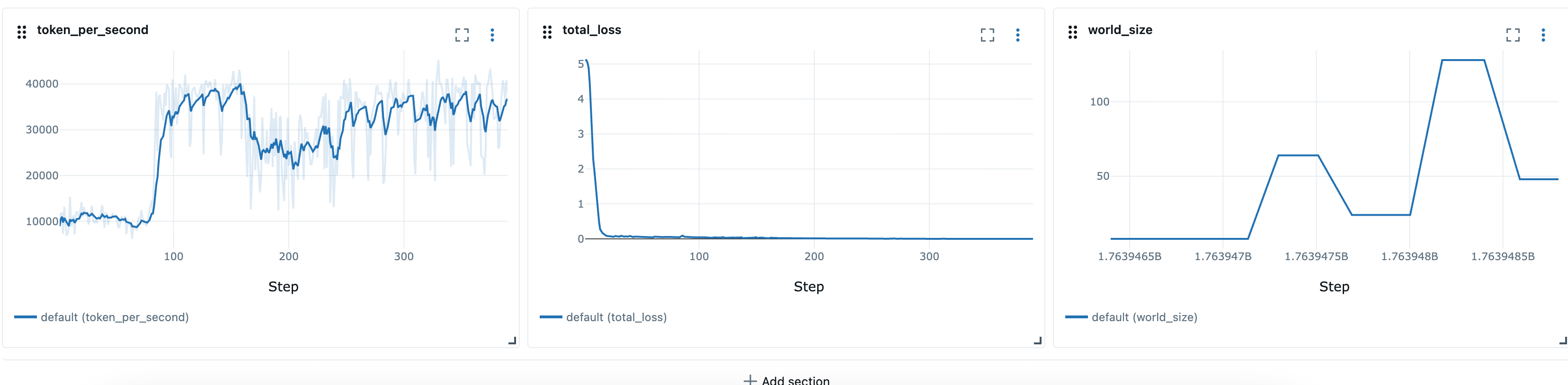
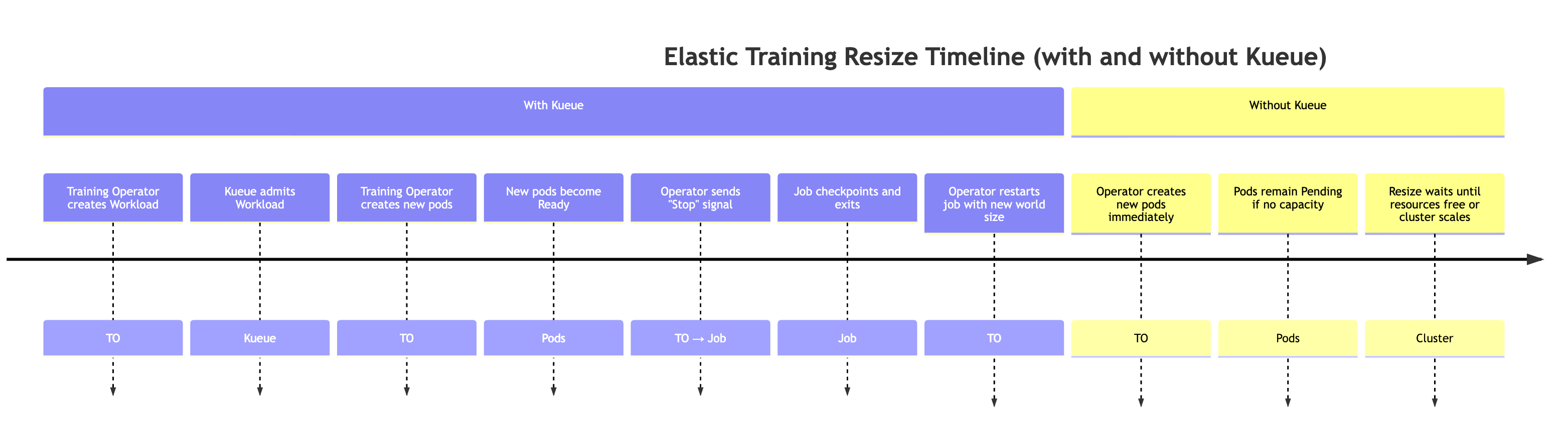
當有更多資源可用時擴展
當叢集上有更多資源可用時 (例如,其他工作負載完成)。在此事件期間,訓練控制器會自動擴展訓練任務。此行為說明如下。
為了模擬有更多資源可用的情況,我們可以提交高優先順序任務,然後刪除高優先順序任務以釋放資源。
# Submit a high-priority job on your cluster. As a result of this command # resources will not be available for elastic training kubectl apply -f high_prioriy_job.yaml # Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Wait for training to start.... # Delete high priority job. This command will make additional resources available for # elastic training kubectl delete -f high_prioriy_job.yaml # Observe the scale-up of elastic job
預期的行為:
-
訓練運算子會建立 Kueue 工作負載 當彈性訓練任務請求變更世界大小時,訓練運算子會產生代表新資源需求的額外 Kueue 工作負載物件。
-
Kueue 認可 Workload Kueue 會根據可用的資源、優先順序和佇列政策來評估請求。核准後,系統會認可工作負載。
-
訓練運算子會建立額外的 Pod 在許可時,運算子會啟動達到新世界大小所需的額外 Pod。
-
當新的 Pod 準備就緒時,訓練運算子會將特殊的彈性事件訊號傳送至訓練指令碼。
-
訓練任務會執行檢查點,以準備正常關機。訓練程序會呼叫 elastic_event_detected() 函數,定期檢查彈性事件訊號。一旦偵測到,就會啟動檢查點。成功完成檢查點後,訓練程序會乾淨地結束。
-
訓練運算子會以新的世界大小重新啟動任務 運算子會等待所有程序結束,然後使用更新的世界大小和最新的檢查點重新啟動訓練任務。
注意:未使用 Kueue 時,訓練運算子會略過前兩個步驟。它會立即嘗試建立新世界大小所需的額外 Pod。如果叢集中沒有足夠的資源可用,這些 Pod 將保持待定狀態,直到容量可用為止。
由高優先順序任務先佔
當高優先順序任務需要資源時,彈性任務可以自動縮減規模。若要模擬此行為,您可以提交彈性訓練任務,該任務使用訓練開始時的可用資源數目上限,而不是提交高優先順序任務,並觀察先佔行為。
# Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Submit a high-priority job on your cluster. As a result of this command # some amount of resources will be kubectl apply -f high_prioriy_job.yaml # Observe scale-down behaviour
當高優先順序任務需要資源時,Kue 可以先佔低優先順序彈性訓練工作負載 (可能有多個與彈性訓練任務相關聯的工作負載物件)。先佔程序遵循以下順序:
-
已提交高優先順序任務 任務會建立新的 Kueue 工作負載,但由於叢集資源不足,無法認可工作負載。
-
Kueue 會先佔彈性訓練任務的其中一個工作負載 彈性任務可能有多個作用中的工作負載 (每個世界大小的組態各一個)。Kueue 根據優先順序和佇列政策選取要先佔的項目。
-
訓練運算子會傳送彈性事件訊號。觸發先佔後,訓練運算子會通知執行中的訓練程序正常停止。
-
訓練程序會執行檢查點。訓練任務會定期檢查彈性事件訊號。偵測到時,它會開始協調檢查點,以在關閉之前保留進度。
-
訓練運算子會清除 Pod 和工作負載。運算子等待檢查點完成,然後刪除屬於先佔工作負載一部分的訓練 Pod。它也會從 Kueue 中移除對應的工作負載物件。
-
高優先順序工作負載會受到認可。釋放資源後,Kue 會認可高優先順序任務,讓任務開始執行。
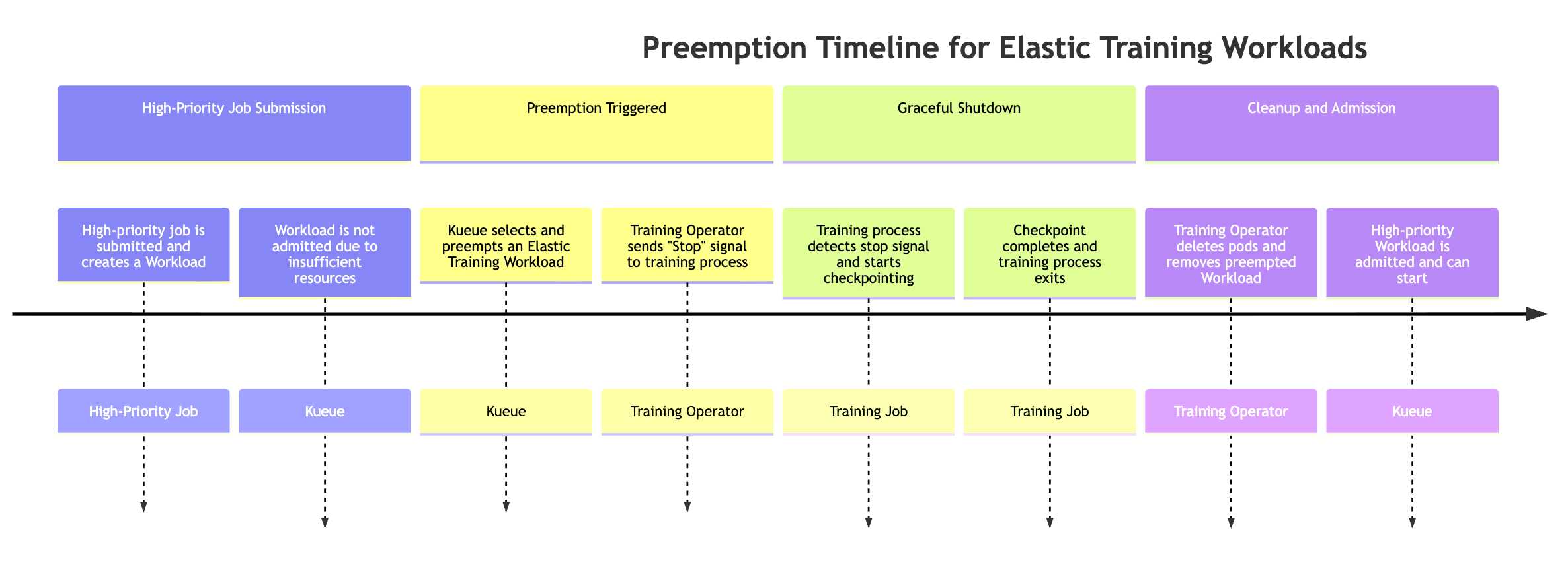
先佔可能會導致整個訓練任務暫停,這可能不適合所有工作流程。為了避免完全暫停任務,同時仍允許彈性擴展,客戶可以透過定義兩個replicaSpec區段,在相同的訓練任務中設定兩個不同的優先順序層級:
-
具有正常或高優先順序的主要 (固定) replicaSpec
-
包含保持訓練任務執行所需的最低複本數量。
-
使用較高的 PriorityClass,確保永遠不會先佔這些複本。
-
即使叢集處於資源壓力下, 仍會維持基準進度。
-
-
具有較低優先順序的彈性 (可擴展) replicaSpec
-
包含額外的選用複本,可在彈性擴展期間提供額外的運算。
-
使用較低的 PriorityClass,允許 Kueue 在優先順序較高的任務需要資源時先佔這些複本。
-
確保僅回收彈性部分,同時核心訓練不會中斷。
-
此組態會啟用部分先佔,其中只會回收彈性容量 - 維持訓練持續性,同時仍支援多租戶環境中的公平資源共用。範例:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 2 maxReplicas: 8 replicaIncrementStep: 2 ... replicaSpecs: - name: base replicas: 2 template: spec: priorityClassName: high-priority # set high-priority to avoid evictions ... - name: elastic replicas: 0 maxReplicas: 6 template: spec: priorityClassName: low-priority. # Set low-priority for elastic part ...
處理 Pod 移出、Pod 損毀和硬體降級:
HyperPod 訓練運算子包含內建機制,可在意外中斷時復原訓練程序。中斷可能因各種原因而發生,例如訓練程式碼失敗、Pod 移出、節點故障、硬體降級和其他執行時間問題。
發生這種情況時,運算子會自動嘗試重新建立受影響的 Pod,並從最新的檢查點繼續訓練。如果無法立即復原,例如,由於備用容量不足,操作員可以暫時減少世界大小並縮減彈性訓練任務,以繼續進度。
當彈性訓練任務當機或遺失複本時,系統的行為如下:
-
復原階段 (使用備用節點) 訓練控制器會等待
faultyScaleDownTimeoutInSeconds資源變成可用,並透過在備用容量上重新部署 Pod 來嘗試復原失敗的複本。 -
彈性縮減 如果無法在逾時時段內復原,訓練運算子會將任務縮減為較小的世界大小 (如果任務的彈性政策允許的話)。然後,以較少的複本繼續訓練。
-
彈性擴展 當其他資源再次可用時,運算子會自動將訓練任務擴展回偏好的世界大小。
此機制可確保即使在資源壓力或部分基礎設施故障的情況下,訓練也能以最短的停機時間繼續,同時仍能利用彈性擴展。
搭配其他 HyperPod 功能使用彈性訓練
彈性訓練目前不支援無檢查點訓練功能、HyperPod 受管分層檢查點或 Spot 執行個體。
注意
我們收集某些例行彙總和匿名操作指標,以提供必要的服務可用性。這些指標的建立是全自動化的,不涉及基礎模型訓練工作負載的人工審核。這些指標與任務和擴展操作、資源管理和基本服務功能相關。
