本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
處理中復原和無檢查點訓練
HyperPod 無檢查點訓練使用模型備援來啟用容錯訓練。核心原則是模型和最佳化工具狀態會完全複寫到多個節點群組,並在每個群組中同步複寫權重更新和最佳化工具狀態變更。當失敗時,運作狀態良好的複本會完成其最佳化工具步驟,並將更新的模型/最佳化工具狀態傳輸到復原複本。
此模型備援型方法可啟用多種錯誤處理機制:
-
處理中復原:即使發生故障,程序仍會保持作用中狀態,讓 GPU 記憶體中的所有模型和最佳化工具狀態保持最新值
-
緩和中止處理:受控中止和資源清理受影響的操作
-
程式碼區塊重新執行:僅重新執行可執行程式碼區塊 (RCB) 內受影響的程式碼區段
-
無遺失訓練進度的無檢查點復原:由於程序持續存在且狀態會保留在記憶體中,因此不會遺失訓練進度;發生故障時,訓練會從上一個步驟繼續,而不是從上一個儲存的檢查點繼續
無檢查點組態
以下是無檢查點訓練的核心程式碼片段。
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank wait_rank() def main(): @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=PEFTCheckpointManager(enable_offload=True), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), ) def run_main(cfg, caller: Optional[HPCallWrapper] = None): ... trainer = Trainer( strategy=CheckpointlessMegatronStrategy(..., num_distributed_optimizer_instances=2), callbacks=[..., CheckpointlessCallback(...)], ) trainer.fresume = resume trainer._checkpoint_connector = CheckpointlessCompatibleConnector(trainer) trainer.wrapper = caller
wait_rank:所有排名都會等待 HyperpodTrainingOperator 基礎設施的排名資訊。HPWrapper:Python 函數包裝函式,可啟用可重新執行程式碼區塊 (RCB) 的重新啟動功能。實作使用內容管理員而非 Python 裝飾項目,因為裝飾項目無法判斷在執行時間要監控RCBs 數量。CudaHealthCheck:透過與 GPU 同步,確保目前程序的 CUDA 內容處於良好狀態。使用 LOCAL_RANK 環境變數指定的裝置,如果未設定 LOCAL_RANK,則預設為主執行緒的 CUDA 裝置。HPAgentK8sAPIFactory:此 API 可讓無檢查點訓練查詢 Kubernetes 訓練叢集中其他 Pod 的訓練狀態。它還提供基礎設施層級的障礙,確保所有排名成功完成中止和重新啟動操作,然後再繼續。CheckpointManager:管理記憶體內檢查點和peer-to-peer復原,以實現無檢查點容錯能力。它有下列核心責任:記憶體內檢查點管理:儲存和管理記憶體中的 NeMo 模型檢查點,以便在無檢查點復原案例期間無需磁碟 I/O 即可快速復原。
復原可行性驗證:透過驗證全域步驟一致性、排名運作狀態和模型狀態完整性,判斷是否可以進行無檢查點復原。
Peer-to-Peer復原協調:使用分散式通訊來協調運作狀態良好和失敗排名之間的檢查點轉移,以快速復原。
RNG 狀態管理:保留和還原 Python、NumPy、PyTorch 和 Megatron 之間的隨機數字產生器狀態,以進行確定性復原。
【選用】 檢查點卸載:如果 GPU 沒有足夠的記憶體容量,則將記憶體檢查點中的卸載至 CPU。
PEFTCheckpointManager:它CheckpointManager透過保留 PEFT 微調的基本模型權重來擴展。CheckpointlessAbortManager:遇到錯誤時,管理背景執行緒中的中止操作。根據預設,它會中止 TransformerEngine、Checkpointing、TorchDistributed 和 DataLoader。使用者可以視需要註冊自訂中止處理常式。中止完成後,所有通訊都必須停止,且所有程序和執行緒都必須終止,以防止資源洩漏。CheckpointlessFinalizeCleanup:針對在背景執行緒中無法安全中止或清除的元件,處理主執行緒中的最終清除操作。CheckpointlessMegatronStrategy:這會從 Nemo 中的MegatronStrategy從 繼承。請注意,無檢查點訓練num_distributed_optimizer_instances至少需要 2 個,才能進行最佳化工具複寫。此策略也負責基本屬性註冊和程序群組初始化,例如無根。CheckpointlessCallback:閃電回呼,整合 NeMo 訓練與無檢查點訓練的容錯能力系統。它有下列核心責任:訓練步驟生命週期管理:追蹤訓練進度並與 ParameterUpdateLock 協調,以根據訓練狀態 (第一步與後續步驟) 啟用/停用無檢查點復原。
檢查點狀態協調:管理記憶體內 PEFT 基礎模型檢查點儲存/還原。
CheckpointlessCompatibleConnector:PTLCheckpointConnector,嘗試將檢查點檔案預先載入至記憶體,並以此優先順序決定來源路徑:嘗試無檢查點復原
如果無檢查點傳回無,則傳回 parent.resume_start()
請參閱範例
概念
本節介紹無檢查點訓練概念。Amazon SageMaker HyperPod 上的無檢查點訓練支援處理中復原。此 API 界面遵循與 NVRx APIs類似的格式。
概念 - 可重新執行的程式碼區塊 (RCB)
當失敗發生時,運作狀態良好的程序會保持運作狀態,但一部分的程式碼必須重新執行,才能復原訓練狀態和 Python 堆疊。可重新執行的程式碼區塊 (RCB) 是在故障復原期間重新執行的特定程式碼區段。在下列範例中,RDB 包含整個訓練指令碼 (即 main() 下的所有項目),這表示每個故障復原都會重新啟動訓練指令碼,同時保留記憶體內模型和最佳化工具狀態。
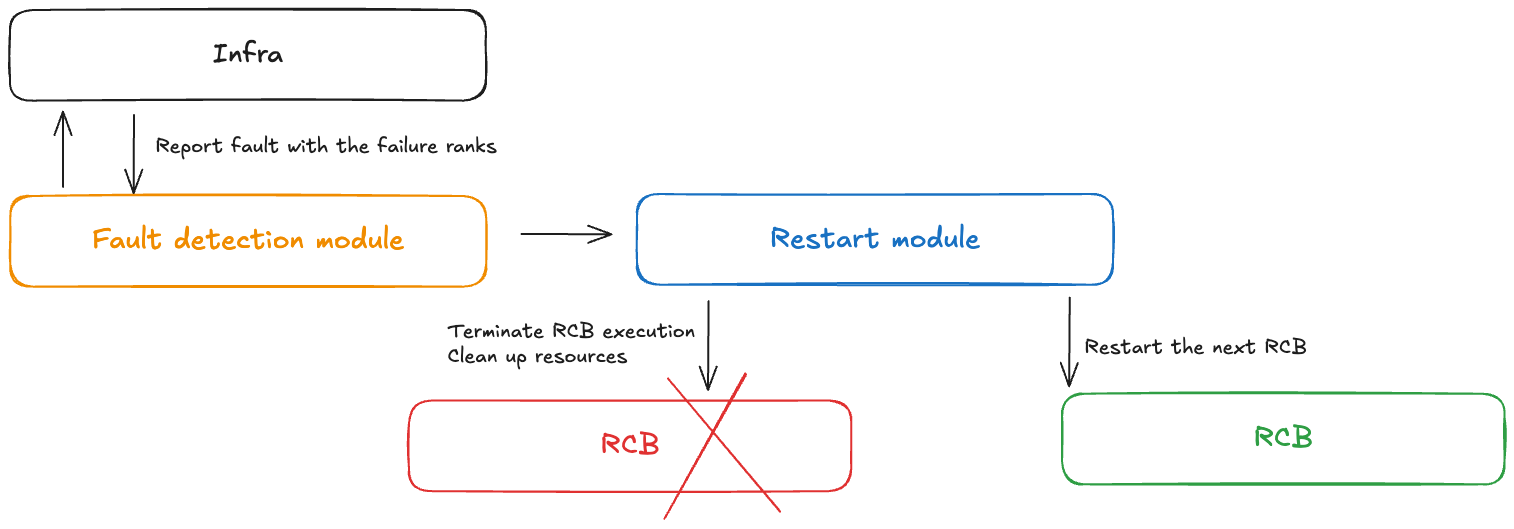
概念 - 故障控制
故障控制器模組會在無檢查點訓練期間發生失敗時收到通知。此故障控制器包含下列元件:
故障偵測模組:接收基礎設施故障通知
RCB APIs:讓使用者能夠在其程式碼中定義可重新執行的程式碼區塊 (RCB)
重新啟動模組:終止 RCB、清除資源,以及重新啟動 RCB
概念 - 模型備援
大型模型訓練通常需要夠大的資料平行大小,才能有效率地訓練模型。在 PyTorch DDP 和 Horovod 等傳統資料平行處理中,模型會完全複寫。更進階的碎片資料平行處理技術,例如 DeepSpeed ZeRO 最佳化工具與 FSDP 也支援混合碎片模式,允許碎片群組內的模型/最佳化工具狀態碎片,以及跨複寫群組完整複寫。NeMo 也透過允許備援的引數 num_distributed_optimizer_instances 提供此混合碎片功能。
不過,新增備援表示模型不會在整個叢集中完全碎片,導致更高的裝置記憶體使用量。備援記憶體的數量會根據使用者實作的特定模型碎片技術而有所不同。低精度模型權重、漸層和啟用記憶體不會受到影響,因為它們會透過模型平行處理進行碎片處理。高精確度的主模型權重/梯度和最佳化工具狀態會受到影響。新增一個備援模型複本可增加裝置記憶體用量,大約等同於一個 DCP 檢查點大小。
混合碎片會將整個 DP 群組的集合分成相對較小的集合。之前,整個 DP 群組都有一個減少散射和一個全集。在混合碎片之後,減少散射只會在每個模型複本內執行,而且跨模型複本群組會有全部減少。所有集合也會在每個模型複本內執行。因此,整個通訊磁碟區大致保持不變,但集體執行的群組較小,因此我們預期會有更好的延遲。
概念 - 失敗和重新啟動類型
下表記錄不同的故障類型和相關聯的復原機制。無檢查點訓練會先透過程序內復原嘗試失敗復原,接著再重新啟動程序層級。只有在發生災難性故障 (例如,多個節點同時故障) 時,才會回到任務層級重新啟動。
| 失敗類型 | 原因 | 復原類型 | 復原機制 |
|---|---|---|---|
| 處理中失敗 | 程式碼層級錯誤、例外狀況 | 處理中復原 (IPR) | 在現有程序中重新執行 RCB;運作狀態良好的程序會保持作用中狀態 |
| 程序重新啟動失敗 | CUDA 內容損毀,終止程序 | 程序層級重新啟動 (PLR) | SageMaker HyperPod 訓練運算子會重新啟動程序;略過 K8s Pod 重新啟動 |
| 節點替換失敗 | 永久節點/GPU 硬體故障 | 任務層級重新啟動 (JLR) | 取代失敗的節點;重新啟動整個訓練任務 |
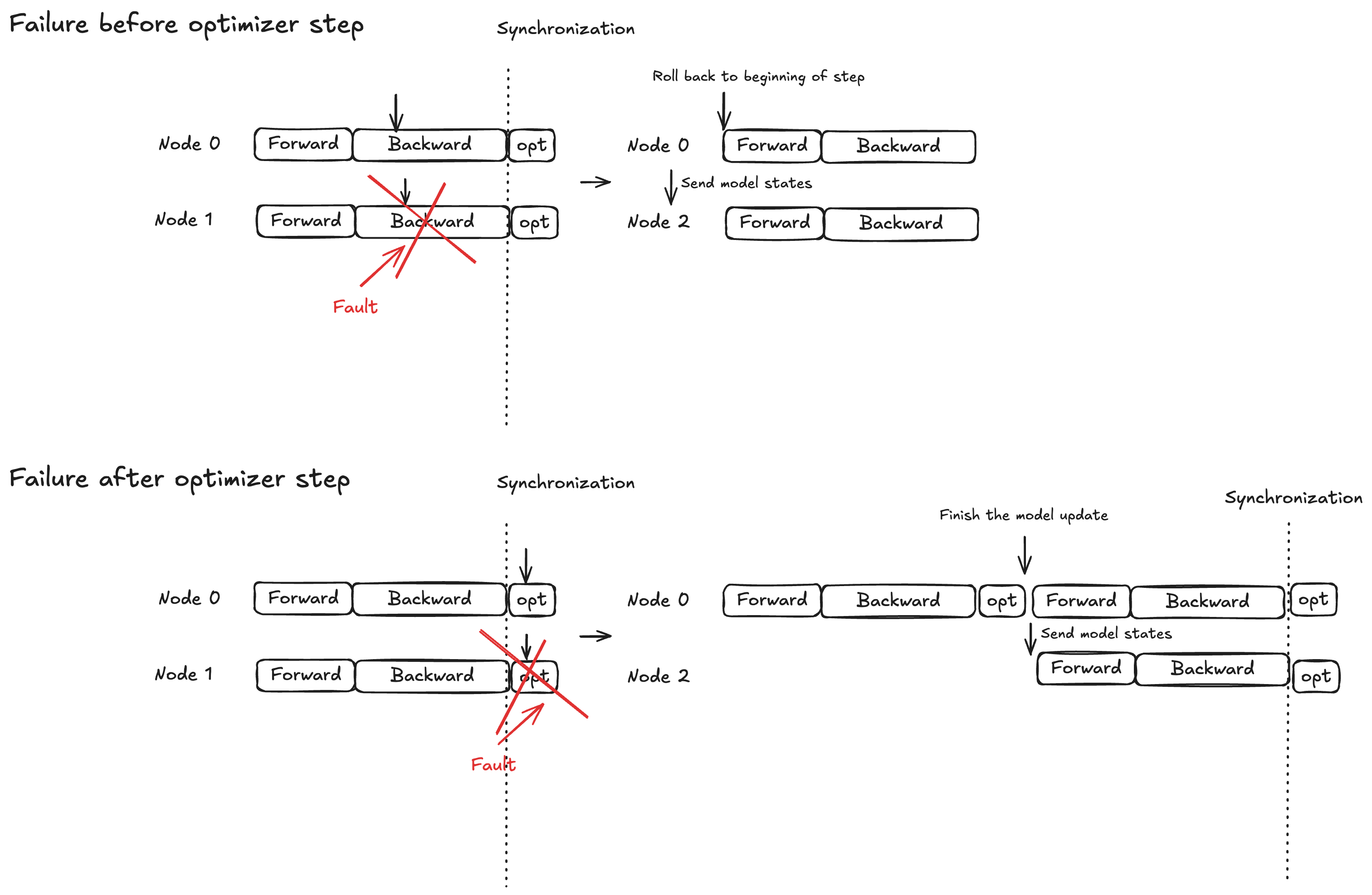
概念 - 最佳化工具步驟的原子鎖定保護
模型執行分為三個階段:向前傳播、向後傳播和最佳化工具步驟。復原行為會根據失敗時間而有所不同:
向前/向後傳播:轉返至目前訓練步驟的開頭,並將模型狀態廣播至替代節點 (s)
最佳化工具步驟:允許運作狀態良好的複本在鎖定保護下完成步驟,然後將更新的模型狀態廣播至替代節點 (s)
此策略可確保絕對不會捨棄已完成的最佳化工具更新,有助於縮短故障復原時間。
無檢查點訓練流程圖
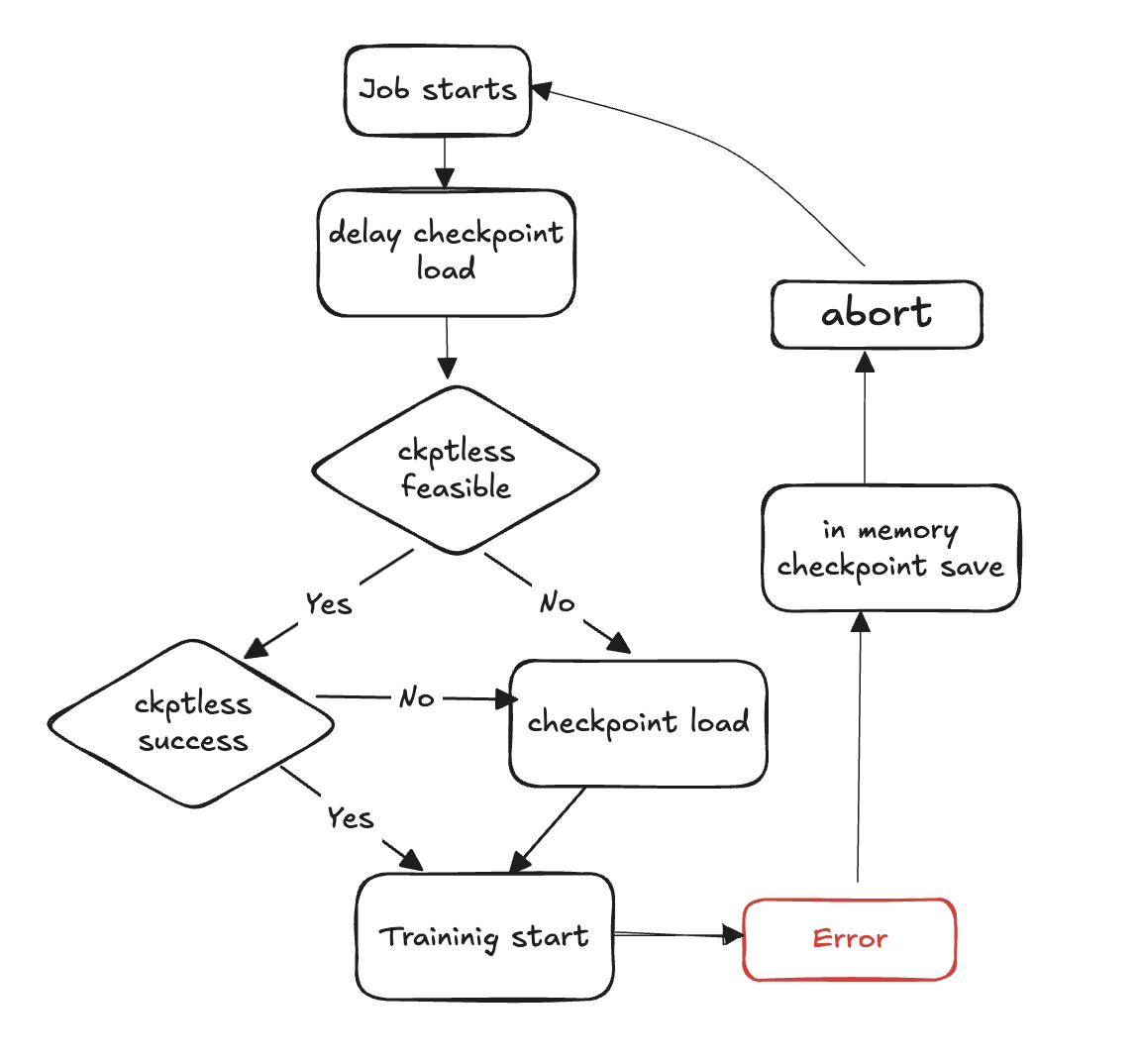
下列步驟概述故障偵測和無檢查點復原程序:
訓練迴圈啟動
發生錯誤
評估無檢查點恢復可行性
檢查是否可以執行無檢查點繼續
如果可行,則嘗試無檢查點恢復
如果 恢復失敗,則從儲存載入至檢查點
如果繼續成功,訓練會從復原狀態繼續
如果不可行,請回到從儲存載入的檢查點
清除資源 - 中止所有程序群組、後端和免費資源,以準備重新啟動。
繼續訓練迴圈 - 開始新的訓練迴圈,程序會返回步驟 1。
API 參考
wait_rank
hyperpod_checkpointless_training.inprocess.train_utils.wait_rank()
等待並從 HyperPod 擷取排名資訊,然後使用分散式訓練變數更新目前的程序環境。
此函數會取得分散式訓練的正確排名指派和環境變數。它可確保每個程序都能取得分散式訓練任務中其角色的適當組態。
參數
無
傳回值
無
行為
程序檢查:如果從子程序呼叫 ,則略過執行 (僅在 MainProcess 中執行)
環境擷取:
WORLD_SIZE從環境變數取得目前RANK和HyperPod 通訊:從 HyperPod
hyperpod_wait_rank_info()擷取排名資訊的呼叫環境更新:使用從 HyperPod 收到的工作者特定環境變數來更新目前的程序環境
環境變數
函數會讀取下列環境變數:
RANK (int) – 目前的程序排名 (預設:如果未設定,則為 -1)
WORLD_SIZE (int) – 分散式任務中的程序總數 (預設值:如果未設定,則為 0)
引發
AssertionError – 如果 HyperPod 的回應不是預期的格式,或缺少必要欄位
範例
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank # Call before initializing distributed training wait_rank() # Now environment variables are properly set for this rank import torch.distributed as dist dist.init_process_group(backend='nccl')
備註
僅在主要程序中執行;子程序呼叫會自動略過
函數會封鎖,直到 HyperPod 提供排名資訊為止
HPWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPWrapper( *, abort=Compose(HPAbortTorchDistributed()), finalize=None, health_check=None, hp_api_factory=None, abort_timeout=None, enabled=True, trace_file_path=None, async_raise_before_abort=True, early_abort_communicator=False, checkpoint_manager=None, check_memory_status=True)
Python 函數包裝函式,可在 HyperPod 無檢查點訓練中啟用可重新執行程式碼區塊 (RCB) 的重新啟動功能。
此包裝函式透過監控訓練執行,並在發生故障時跨分散式程序協調重新啟動,提供容錯能力和自動復原功能。它使用內容管理員方法,而不是裝飾項目,在整個訓練生命週期中維護全域資源。
參數
abort (中止,選用) – 偵測到失敗時,非同步中止執行。預設:
Compose(HPAbortTorchDistributed())finalize (Finalize,選用) – 在重新啟動期間執行的 Rank-local Finalize 處理常式。預設:
Nonehealth_check (HealthCheck,選用) – 在重新啟動期間執行排名本機運作狀態檢查。預設:
Nonehp_api_factory (可呼叫、選用) – 用於建立 HyperPod API 以與 HyperPod 互動的原廠函數。預設:
Noneabort_timeout (浮點數,選用) – 在錯誤控制執行緒中中止呼叫的逾時。預設:
Noneenabled (bool,選用) – 啟用包裝函式功能。當 時
False,包裝函式會變成傳遞。預設:Truetrace_file_path (str,選用) – VizTracer 分析追蹤檔案的路徑。預設:
Noneasync_raise_before_abort (bool、選用) – 在錯誤控制執行緒中中止之前啟用提升。預設:
Trueearly_abort_communicator (bool,選用) – 在中止資料載入器之前中止通訊器 (NCCL/Gloo)。預設:
Falsecheckpoint_manager (任何、選用) – 在復原期間處理檢查點的管理員。預設:
Nonecheck_memory_status (bool、選用) – 啟用記憶體狀態檢查和記錄。預設:
True
方法
def __call__(self, fn)
包裝函數以啟用重新啟動功能。
參數:
fn (可呼叫) – 要與重新啟動功能包裝的函數
傳回:
可呼叫 – 具有重新啟動功能的包裝函數,如果停用,則為原始函數
範例
from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager from hyperpod_checkpointless_training.nemo_plugins.patches import patch_megatron_optimizer from hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector import CheckpointlessCompatibleConnector from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=CheckpointManager(enable_offload=False), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), )def training_function(): # Your training code here pass
備註
包裝函式
torch.distributed需要可用當 時
enabled=False,包裝函式會變成傳遞,並傳回原始函數不變包裝函式會維護全域資源,例如在整個訓練生命週期中監控執行緒
trace_file_path提供 時支援 VizTracer 分析與 HyperPod 整合,跨分散式訓練進行協調故障處理
HPCallWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPCallWrapper(wrapper)
在執行期間監控和管理重新啟動程式碼區塊 (RCB) 的狀態。
此類別處理 RCB 執行的生命週期,包括故障偵測、與重新啟動的其他排名協調,以及清除操作。它可管理分散式同步,並確保所有訓練程序的復原一致。
參數
wrapper (HPWrapper) – 包含全域處理中復原設定的父包裝函式
Attributes
step_upon_restart (int) – 用於追蹤自上次重新啟動後步驟的計數器,用於確定重新啟動策略
方法
def initialize_barrier()
遇到 RCB 的例外狀況後,請等待 HyperPod 障礙物同步處理。
def start_hp_fault_handling_thread()
啟動故障處理執行緒以監控和協調故障。
def handle_fn_exception(call_ex)
處理執行函數或 RCB 的例外狀況。
參數:
call_ex (例外狀況) – 監控函數的例外狀況
def restart(term_ex)
執行重新啟動處理常式,包括定案、垃圾回收和運作狀態檢查。
參數:
term_ex (RankShouldRestart) – 觸發重新啟動的終止例外狀況
def launch(fn, *a, **kw)
以適當的例外狀況處理執行 RCB。
參數:
fn (可呼叫) – 要執行的函數
a – 函數引數
kw – 函數關鍵字引數
def run(fn, a, kw)
處理重新啟動和障礙同步的主要執行迴圈。
參數:
fn (可呼叫) – 要執行的函數
a – 函數引數
kw – 函數關鍵字引數
def shutdown()
關閉錯誤處理和監控執行緒。
備註
自動處理協調復原的
RankShouldRestart例外狀況管理記憶體追蹤和中止、重新啟動期間的垃圾回收
根據故障時間同時支援程序內復原和 PLR (程序層級重新啟動) 策略
CudaHealthCheck
class hyperpod_checkpointless_training.inprocess.health_check.CudaHealthCheck(timeout=datetime.timedelta(seconds=30))
確保目前程序的 CUDA 內容在無檢查點訓練復原期間處於良好狀態。
此運作狀態檢查會與 GPU 同步,以確認 CUDA 內容在訓練失敗後未損毀。它會執行 GPU 同步操作,以偵測任何可能無法成功恢復訓練的問題。運作狀態檢查會在分散式群組銷毀並完成之後執行。
參數
逾時 (datetime.timedelta,選用) – GPU 同步操作的逾時持續時間。預設:
datetime.timedelta(seconds=30)
方法
__call__(state, train_ex=None)
執行 CUDA 運作狀態檢查,以驗證 GPU 內容完整性。
參數:
狀態 (HPState) – 包含排名和分散式資訊的目前 HyperPod 狀態
train_ex (例外,選用) – 觸發重新啟動的原始訓練例外狀況。預設:
None
傳回:
元組 – 如果運作狀態檢查通過,則包含
(state, train_ex)不變的元組
引發:
TimeoutError – 如果 GPU 同步逾時,表示可能損毀的 CUDA 內容
狀態保留:如果所有檢查都通過,則傳回原始狀態和例外狀況不變
範例
import datetime from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # Create CUDA health check with custom timeout cuda_health_check = CudaHealthCheck( timeout=datetime.timedelta(seconds=60) ) # Use with HPWrapper for fault-tolerant training @HPWrapper( health_check=cuda_health_check, enabled=True ) def training_function(): # Your training code here pass
備註
使用執行緒實作 GPU 同步的逾時保護
旨在偵測可能阻止成功恢復訓練的損毀 CUDA 內容
在分散式訓練案例中,應該做為容錯管道的一部分使用
HPAgentK8sAPIFactory
class hyperpod_checkpointless_training.inprocess.train_utils.HPAgentK8sAPIFactory()
用於建立 HPAgentK8sAPI 執行個體的工廠類別,可與 HyperPod 基礎設施通訊,以進行分散式訓練協調。
此工廠提供標準化方法來建立和設定 HPAgentK8sAPI 物件,以處理訓練程序與 HyperPod 控制平面之間的通訊。它會封裝基礎通訊端用戶端和 API 執行個體的建立,確保訓練系統不同部分的組態一致。
方法
__call__()
建立並傳回針對 HyperPod 通訊設定的 HPAgentK8sAPI 執行個體。
傳回:
HPAgentK8sAPI – 用於與 HyperPod 基礎設施通訊的設定 API 執行個體
範例
from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck # Create the factory hp_api_factory = HPAgentK8sAPIFactory() # Use with HPWrapper for fault-tolerant training hp_wrapper = HPWrapper( hp_api_factory=hp_api_factory, health_check=CudaHealthCheck(), abort_timeout=60.0, enabled=True ) @hp_wrapper def training_function(): # Your distributed training code here pass
備註
旨在與 HyperPod 的 Kubernetes 型基礎設施無縫搭配使用。在分散式訓練案例中,協調錯誤處理和復原至關重要
CheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.CheckpointManager( enable_checksum=False, enable_offload=False)
管理記憶體內檢查點和peer-to-peer復原,以在分散式訓練中實現無檢查點容錯能力。
此類別提供 HyperPod 無檢查點訓練的核心功能,包括管理記憶體中的 NeMo 模型檢查點、驗證復原可行性,以及在運作狀態良好和失敗排名之間協調peer-to-peer檢查點轉移。它消除了復原期間對磁碟 I/O 的需求,大幅減少了復原的平均時間 (MTTR)。
參數
enable_checksum (bool、選用) – 在復原期間啟用完整性檢查的模型狀態檢查總和驗證。預設:
Falseenable_offload (bool,選用) – 啟用從 GPU 到 CPU 記憶體的檢查點卸載,以減少 GPU 記憶體用量。預設:
False
Attributes
global_step (int 或 None) – 與儲存檢查點相關聯的目前訓練步驟
rng_states (清單或無) – 用於確定性復原的存放隨機數字產生器狀態
checkum_manager (MemoryChecksumManager) – 模型狀態檢查總和驗證的管理員
parameter_update_lock (ParameterUpdateLock) – 在復原期間協調參數更新的鎖定
方法
save_checkpoint(trainer)
將 NeMo 模型檢查點儲存在記憶體中,以實現潛在的無檢查點復原。
參數:
訓練程式 (pytorch_lightning.Trainer) – PyTorch Lightning 訓練程式執行個體
備註:
在批次結束時或在例外狀況處理期間由 CheckpointlessCallback 呼叫
建立沒有磁碟 I/O 額外負荷的復原點
儲存完整的模型、最佳化工具和排程器狀態
delete_checkpoint()
刪除記憶體內檢查點並執行清除操作。
備註:
清除檢查點資料、RNG 狀態和快取張量
執行垃圾收集和 CUDA 快取清除
在成功復原後或不再需要檢查點時呼叫
try_checkpointless_load(trainer)
從對等排名載入狀態以嘗試無檢查點復原。
參數:
訓練程式 (pytorch_lightning.Trainer) – PyTorch Lightning 訓練程式執行個體
傳回:
dict 或 None – 如果成功,則還原檢查點;如果需要回復至磁碟,則無
備註:
無檢查點復原的主要進入點
在嘗試 P2P 傳輸之前驗證復原可行性
復原嘗試後,一律清除記憶體內檢查點
checkpointless_recovery_feasible(trainer, include_checksum_verification=True)
判斷目前失敗案例是否可以進行無檢查點復原。
參數:
訓練程式 (pytorch_lightning.Trainer) – PyTorch Lightning 訓練程式執行個體
include_checksum_verification (bool,選用) – 是否包含檢查總和驗證。預設:
True
傳回:
bool – 如果無檢查點復原可行,則為 true,否則為 False
驗證條件:
運作狀態良好的排名之間的全域步驟一致性
可供復原的足夠運作狀態良好的複本
模型狀態檢查總和完整性 (如果啟用)
store_rng_states()
存放所有隨機數字產生器狀態以進行確定性復原。
備註:
擷取 Python、NumPy、PyTorch CPU/GPU 和 Megatron RNG 狀態
在復原後維持訓練決定性的必要條件
load_rng_states()
還原所有 RNG 狀態以繼續進行確定性復原。
備註:
還原所有先前儲存的 RNG 狀態
確保訓練以相同的隨機序列繼續
maybe_offload_checkpoint()
如果啟用卸載,將檢查點從 GPU 卸載到 CPU 記憶體。
備註:
減少大型模型的 GPU 記憶體用量
僅在 執行
enable_offload=True維護檢查點可存取性以進行復原
範例
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=CheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
驗證:使用檢查總和驗證檢查點完整性 (如果啟用)
備註
使用分散式通訊基本概念實現高效的 P2P 傳輸
自動處理張量 dtype 轉換和裝置置放
MemoryChecksumManager – 處理模型狀態完整性驗證
PEFTCheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.PEFTCheckpointManager( *args, **kwargs)
使用個別的基礎和轉接器處理來管理 PEFT (參數效率微調) 的檢查點,以最佳化無檢查點復原。
這個專門的檢查點管理器擴展 CheckpointManager,透過將基本模型權重與轉接器參數分開來最佳化 PEFT 工作流程。
參數
從 CheckpointManager 繼承所有參數:
enable_checksum (bool、選用) – 啟用模型狀態檢查總和驗證。預設:
Falseenable_offload (bool,選用) – 啟用檢查點卸載至 CPU 記憶體。預設:
False
其他屬性
params_to_save (集合) – 應儲存為轉接器參數的參數名稱集
base_model_weights (dict 或 None) – 快取的基礎模型權重,儲存一次並重複使用
base_model_keys_to_extract (清單或無) – 在 P2P 傳輸期間擷取基礎模型張量的金鑰
方法
maybe_save_base_model(trainer)
儲存基礎模型權重一次,篩選掉轉接器參數。
參數:
訓練程式 (pytorch_lightning.Trainer) – PyTorch Lightning 訓練程式執行個體
備註:
僅在第一次呼叫時儲存基礎模型權重;後續呼叫為無操作
篩選掉轉接器參數,以僅存放凍結的基礎模型權重
基礎模型權重會保留在多個訓練工作階段中
save_checkpoint(trainer)
將 NeMo PEFT 轉接器模型檢查點儲存在記憶體中,以實現潛在的無檢查點復原。
參數:
訓練程式 (pytorch_lightning.Trainer) – PyTorch Lightning 訓練程式執行個體
備註:
maybe_save_base_model()如果基礎模型尚未儲存,則自動呼叫篩選檢查點以僅包含轉接器參數和訓練狀態
與完整模型檢查點相比,大幅減少檢查點大小
try_base_model_checkpointless_load(trainer)
嘗試 PEFT 基礎模型透過從對等排名載入狀態來加權無檢查點復原。
參數:
訓練程式 (pytorch_lightning.Trainer) – PyTorch Lightning 訓練程式執行個體
傳回:
dict 或 None – 如果成功,則還原基礎模型檢查點;如果需要備用,則無
備註:
在模型初始化期間用來復原基礎模型權重
復原後不會清除基本模型權重 (保留以供重複使用)
針對model-weights-only復原案例進行最佳化
try_checkpointless_load(trainer)
嘗試 PEFT 轉接器透過從對等排名載入狀態來加權無檢查點復原。
參數:
訓練程式 (pytorch_lightning.Trainer) – PyTorch Lightning 訓練程式執行個體
傳回:
dict 或 None – 如果成功,則還原轉接器檢查點;如果需要備用,則無
備註:
僅復原轉接器參數、最佳化工具狀態和排程器
成功復原後自動載入最佳化工具與排程器狀態
復原嘗試後清除轉接器檢查點
is_adapter_key(key)
檢查狀態索引鍵是否屬於轉接器參數。
參數:
金鑰 (str 或 tuple) – 要檢查的狀態 dict 金鑰
傳回:
bool – 如果金鑰是轉接器參數則為 True,如果是基本模型參數則為 False
偵測邏輯:
檢查金鑰是否已
params_to_save設定識別包含 ".adapter" 的金鑰。substring
識別結尾為 ".adapters" 的金鑰
對於元組索引鍵, 會檢查參數是否需要漸層
maybe_offload_checkpoint()
將基本模型權重從 GPU 卸載至 CPU 記憶體。
備註:
擴展父方法以處理基礎模型權重卸載
轉接器權重通常很小,不需要卸載
設定內部旗標以追蹤卸載狀態
備註
專為參數高效微調案例 (LoRA、轉接器等) 而設計
自動處理基礎模型和轉接器參數的分離
範例
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import PEFTCheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=PEFTCheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
CheckpointlessAbortManager
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessAbortManager()
工廠類別,用於建立和管理無檢查點容錯能力的中止元件組成。
此公用程式類別提供靜態方法來建立、自訂和管理 HyperPod 無檢查點訓練中錯誤處理期間使用的中止元件合成。它簡化了中止序列的組態,以便在故障復原期間處理分散式訓練元件、資料載入器和架構特定資源的清除。
參數
無 (所有方法皆為靜態)
靜態方法
get_default_checkpointless_abort()
取得包含所有標準中止元件的預設中止合成執行個體。
傳回:
Compose – 預設編寫的中止執行個體與所有中止元件
預設元件:
AbortTransformerEngine() – 清除 TransformerEngine 資源
HPCheckpointingAbort() – 處理檢查點系統清除
HPAbortTorchDistributed() – 中止 PyTorch 分散式操作
HPDataLoaderAbort() – 停止和清除資料載入器
create_custom_abort(abort_instances)
建立僅具有指定中止執行個體的自訂中止撰寫。
參數:
abort_instances (Abort) – 要包含在 compose 中的中止執行個體變數數量
傳回:
編寫 – 新編寫的中止執行個體僅包含指定的元件
引發:
ValueError – 如果未提供中止執行個體
override_abort(abort_compose, abort_type, new_abort)
使用新元件取代 Compose 執行個體中的特定中止元件。
參數:
abort_compose (Compose) – 要修改的原始 Compose 執行個體
abort_type (類型) – 要取代的中止元件類型 (例如
HPCheckpointingAbort)new_abort (Abort) – 要用來取代的新中止執行個體
傳回:
Compose – 取代指定元件的新 Compose 執行個體
引發:
ValueError – 如果 abort_compose 沒有 'instances' 屬性
範例
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager # The strategy automatically integrates with HPWrapper @HPWrapper( abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), health_check=CudaHealthCheck(), finalize=CheckpointlessFinalizeCleanup(), enabled=True ) def training_function(): trainer.fit(...)
備註
自訂組態允許對清除行為進行微調控制
中止操作對於在故障復原期間正確清理資源至關重要
CheckpointlessFinalizeCleanup
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessFinalizeCleanup()
在故障偵測後執行全面的清除,以準備在無檢查點訓練期間進行程序內復原。
此最終處理常式會透過銷毀訓練元件參考來執行架構特定的清除操作,包括 Megatron/TransformerEngine 中止、DDP 清除、模組重新載入和記憶體清除。它可確保訓練環境正確重設,以成功進行程序內復原,而不需要完全終止程序。
參數
無
Attributes
訓練程式 (pytorch_lightning.Trainer 或 None) – 參考 PyTorch Lightning 訓練程式執行個體
方法
__call__(*a, **kw)
執行完整的清除操作,以進行程序內復原準備。
參數:
a – 可變位置引數 (繼承自最終化界面)
kw – 可變關鍵字引數 (從最終化界面繼承)
清除操作:
Megatron 架構清除 – 呼叫
abort_megatron()清除 Megatron 特定的資源TransformerEngine 清除 – 呼叫
abort_te()清除 TransformerEngine 資源RoPE 清除 – 呼叫
cleanup_rope()清除旋轉位置內嵌資源DDP 清除 – 呼叫
cleanup_ddp()清除 DistributedDataParallel 資源模組重新載入 – 呼叫
reload_megatron_and_te()重新載入架構模組Lightning 模組清除 – 選擇性地清除 Lightning 模組以減少 GPU 記憶體
記憶體清除 – 銷毀可用記憶體的訓練元件參考
register_attributes(trainer)
註冊訓練器執行個體,以便在清除操作期間使用。
參數:
訓練程式 (pytorch_lightning.Trainer) – 要註冊的 PyTorch Lightning 訓練程式執行個體
與 CheckpointlessCallback 整合
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( ... finalize=CheckpointlessFinalizeCleanup(), ) def training_function(): trainer.fit(...)
備註
清除操作會以特定順序執行,以避免相依性問題
記憶體清理使用垃圾回收自我檢查來尋找目標物件
所有清除操作的設計都具有等冪性且安全可重試
CheckpointlessMegatronStrategy
class hyperpod_checkpointless_training.nemo_plugins.megatron_strategy.CheckpointlessMegatronStrategy(*args, **kwargs)
具有整合式無檢查點復原功能的 NeMo Megatron 策略,可用於容錯分散式訓練。
請注意,無檢查點訓練num_distributed_optimizer_instances至少需要 2 個,才能進行最佳化工具複寫。此策略也負責基本屬性註冊和程序群組初始化。
參數
從 MegatronStrategy 繼承所有參數:
標準 NeMo MegatronStrategy 初始化參數
分散式訓練組態選項
模型平行處理設定
Attributes
base_store (torch.distributed.TCPStore 或 None) – 用於程序群組協調的分散式存放區
方法
setup(trainer)
初始化策略,並向培訓人員註冊容錯能力元件。
參數:
訓練程式 (pytorch_lightning.Trainer) – PyTorch Lightning 訓練程式執行個體
設定操作:
父系設定 – 呼叫父系 MegatronStrategy 設定
錯誤注入註冊 – 如果存在,則註冊 HPFaultInjectionCallback 勾點
完成註冊 – 向完成清除處理常式註冊培訓人員
中止註冊 – 向支援它的中止處理常式註冊訓練程式
setup_distributed()
使用具有字首或無根連線的 TCPStore 初始化程序群組。
load_model_state_dict(checkpoint, strict=True)
具有無檢查點復原相容性的載入模型狀態指示。
參數:
checkpoint (Mapping【str, Any】) – 包含模型狀態的檢查點字典
strict (bool,選用) – 是否嚴格強制執行狀態索引鍵比對。預設:
True
get_wrapper()
取得 HPCallWrapper 執行個體以進行容錯能力協調。
傳回:
HPCallWrapper – 連接至訓練器的包裝函式執行個體,用於容錯能力
is_peft()
透過檢查 PEFT 回呼,檢查訓練組態中是否已啟用 PEFT (參數效率微調)
傳回:
bool – 如果存在 PEFT 回呼,則為 true,否則為 False
teardown()
覆寫 PyTorch Lightning 原生遞減,以委派清除作業中止處理常式。
範例
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( checkpoint_manager=checkpoint_manager, enabled=True ) def training_function(): trainer = pl.Trainer(strategy=CheckpointlessMegatronStrategy()) trainer.fit(model, datamodule)
CheckpointlessCallback
class hyperpod_checkpointless_training.nemo_plugins.callbacks.CheckpointlessCallback( enable_inprocess=False, enable_checkpointless=False, enable_checksum=False, clean_tensor_hook=False, clean_lightning_module=False)
閃電回呼,整合 NeMo 訓練與無檢查點訓練的容錯能力系統。
此回呼會管理處理中復原功能的步驟追蹤、檢查點儲存和參數更新協調。它可做為 PyTorch Lightning 訓練迴圈與 HyperPod 無檢查點訓練機制之間的主要整合點,協調整個訓練生命週期的容錯能力操作。
參數
enable_inprocess (bool,選用) – 啟用處理中復原功能。預設:
Falseenable_checkpointless (bool,選用) – 啟用無檢查點復原 (需要
enable_inprocess=True)。預設:Falseenable_checksum (bool,選用) – 啟用模型狀態檢查總和驗證 (需要
enable_checkpointless=True)。預設:Falseclean_tensor_hook (bool,選用) – 在清除期間清除所有 GPU 張量的張量勾點 (昂貴的操作)。預設:
Falseclean_lightning_module (bool,選用) – 每次重新啟動後,啟用 Lightning 模組清除以釋放 GPU 記憶體。預設:
False
Attributes
tried_adapter_checkpointless (bool) – 追蹤是否已嘗試轉接器無檢查點還原的旗標
方法
get_wrapper_from_trainer(trainer)
從訓練人員取得 HPCallWrapper 執行個體,以進行容錯能力協調。
參數:
訓練程式 (pytorch_lightning.Trainer) – PyTorch Lightning 訓練程式執行個體
傳回:
HPCallWrapper – 容錯能力操作的包裝函式執行個體
on_train_batch_start(trainer, pl_module, batch, batch_idx, *args, **kwargs)
在每個訓練批次開始時呼叫 ,以管理步驟追蹤和復原。
參數:
訓練程式 (pytorch_lightning.Trainer) – PyTorch Lightning 訓練程式執行個體
pl_module (pytorch_lightning.LightningModule) – 正在訓練的 Lightning 模組
批次 – 目前的訓練批次資料
batch_idx (int) – 目前批次的索引
args – 其他位置引數
kwargs – 其他關鍵字引數
on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx)
在每個訓練批次結束時釋放參數更新鎖定。
參數:
訓練程式 (pytorch_lightning.Trainer) – PyTorch Lightning 訓練程式執行個體
pl_module (pytorch_lightning.LightningModule) – 正在訓練的 Lightning 模組
output (STEP_OUTPUT) – 訓練步驟輸出
批次 (任何) – 目前的訓練批次資料
batch_idx (int) – 目前批次的索引
備註:
鎖定釋放時間可確保無檢查點復原可在參數更新完成後繼續
只有在
enable_inprocess和enable_checkpointless皆為 True 時才執行
get_peft_callback(trainer)
從訓練人員的回呼清單中擷取 PEFT 回呼。
參數:
訓練程式 (pytorch_lightning.Trainer) – PyTorch Lightning 訓練程式執行個體
傳回:
PEFT 或無 – 如果找到 PEFT 回呼執行個體,則無
_try_adapter_checkpointless_restore(trainer, params_to_save)
嘗試無檢查點還原 PEFT 轉接器參數。
參數:
訓練程式 (pytorch_lightning.Trainer) – PyTorch Lightning 訓練程式執行個體
params_to_save (集合) – 要儲存為轉接器參數的參數名稱集
備註:
每個訓練工作階段僅執行一次 (以
tried_adapter_checkpointless旗標控制)使用轉接器參數資訊設定檢查點管理員
範例
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager import pytorch_lightning as pl # Create checkpoint manager checkpoint_manager = CheckpointManager( enable_checksum=True, enable_offload=True ) # Create checkpointless callback with full fault tolerance checkpointless_callback = CheckpointlessCallback( enable_inprocess=True, enable_checkpointless=True, enable_checksum=True, clean_tensor_hook=True, clean_lightning_module=True ) # Use with PyTorch Lightning trainer trainer = pl.Trainer( callbacks=[checkpointless_callback], strategy=CheckpointlessMegatronStrategy() ) # Training with fault tolerance trainer.fit(model, datamodule=data_module)
記憶體管理
clean_tensor_hook:清除期間移除張量掛鉤 (昂貴但徹底)
clean_lightning_module:在重新啟動期間釋放 Lightning 模組 GPU 記憶體
這兩個選項都有助於在故障復原期間減少記憶體使用量
與 ParameterUpdateLock 協調執行緒安全參數更新追蹤
CheckpointlessCompatibleConnector
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector.CheckpointlessCompatibleConnector()
PyTorch Lightning 檢查點連接器,整合無檢查點復原與傳統磁碟型檢查點載入。
此連接器擴展 PyTorch Lightning 的 _CheckpointConnector,以提供無檢查點復原與標準檢查點還原之間的無縫整合。它會先嘗試無檢查點復原,然後在無檢查點復原不可行或失敗時回到磁碟型檢查點載入。
參數
從 _CheckpointConnector 繼承所有參數
方法
resume_start(checkpoint_path=None)
嘗試以無檢查點復原優先順序預先載入檢查點。
參數:
checkpoint_path (str 或 None,選用) – 通往磁碟檢查點的備用路徑。預設:
None
resume_end()
完成檢查點載入程序並執行載入後操作。
備註
透過無檢查點復原支援擴展 PyTorch Lightning 的內部
_CheckpointConnector類別維持與標準 PyTorch Lightning 檢查點工作流程的完整相容性
CheckpointlessAutoResume
class hyperpod_checkpointless_training.nemo_plugins.resume.CheckpointlessAutoResume()
使用延遲設定擴展 NeMo 的 AutoResume,以在檢查點路徑解析之前啟用無檢查點復原驗證。
此類別實作兩階段初始化策略,允許在回到傳統磁碟型檢查點載入之前進行無檢查點復原驗證。它會有條件地延遲 AutoResume 設定以防止過早檢查點路徑解析,讓 CheckpointManager 先驗證無檢查點peer-to-peer復原是否可行。
參數
從 AutoResume 繼承所有參數
方法
setup(trainer, model=None, force_setup=False)
有條件地延遲 AutoResume 設定,以啟用無檢查點復原驗證。
參數:
訓練程式 (pytorch_lightning.Trainer 或 Lightning.fabric.Fabric) – PyTorch Lightning 訓練程式或 Fabric 執行個體
model (選用) – 用於設定的模型執行個體。預設:
Noneforce_setup (bool,選用) – 如果為 True,請略過延遲並立即執行 AutoResume 設定。預設:
False
範例
from hyperpod_checkpointless_training.nemo_plugins.resume import CheckpointlessAutoResume from hyperpod_checkpointless_training.nemo_plugins.megatron_strategy import CheckpointlessMegatronStrategy import pytorch_lightning as pl # Create trainer with checkpointless auto-resume trainer = pl.Trainer( strategy=CheckpointlessMegatronStrategy(), resume=CheckpointlessAutoResume() )
備註
使用啟用無檢查點復原的延遲機制擴展 NeMo 的 AutoResume 類別
可與 搭配使用
CheckpointlessCompatibleConnector,以實現完整的復原工作流程
