本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
記憶體映射的資料載入器
另一個重新啟動額外負荷來自資料載入:訓練叢集在資料載入器初始化、從遠端檔案系統下載資料,並分批處理時保持閒置狀態。
為了解決這個問題,我們推出了記憶體映射 DataLoader(MMAP) 資料載入器,它在持久性記憶體中快取預先擷取的批次,以確保它們即使在錯誤引發的重新啟動後仍然可用。此方法可省去資料載入器設定時間,並可讓訓練使用快取的批次立即恢復,同時在背景中重新初始化和擷取後續資料。資料快取位於需要訓練資料和維護兩種批次類型的每個排名上:最近用於訓練的已取用批次,以及準備好立即使用的預先擷取批次。
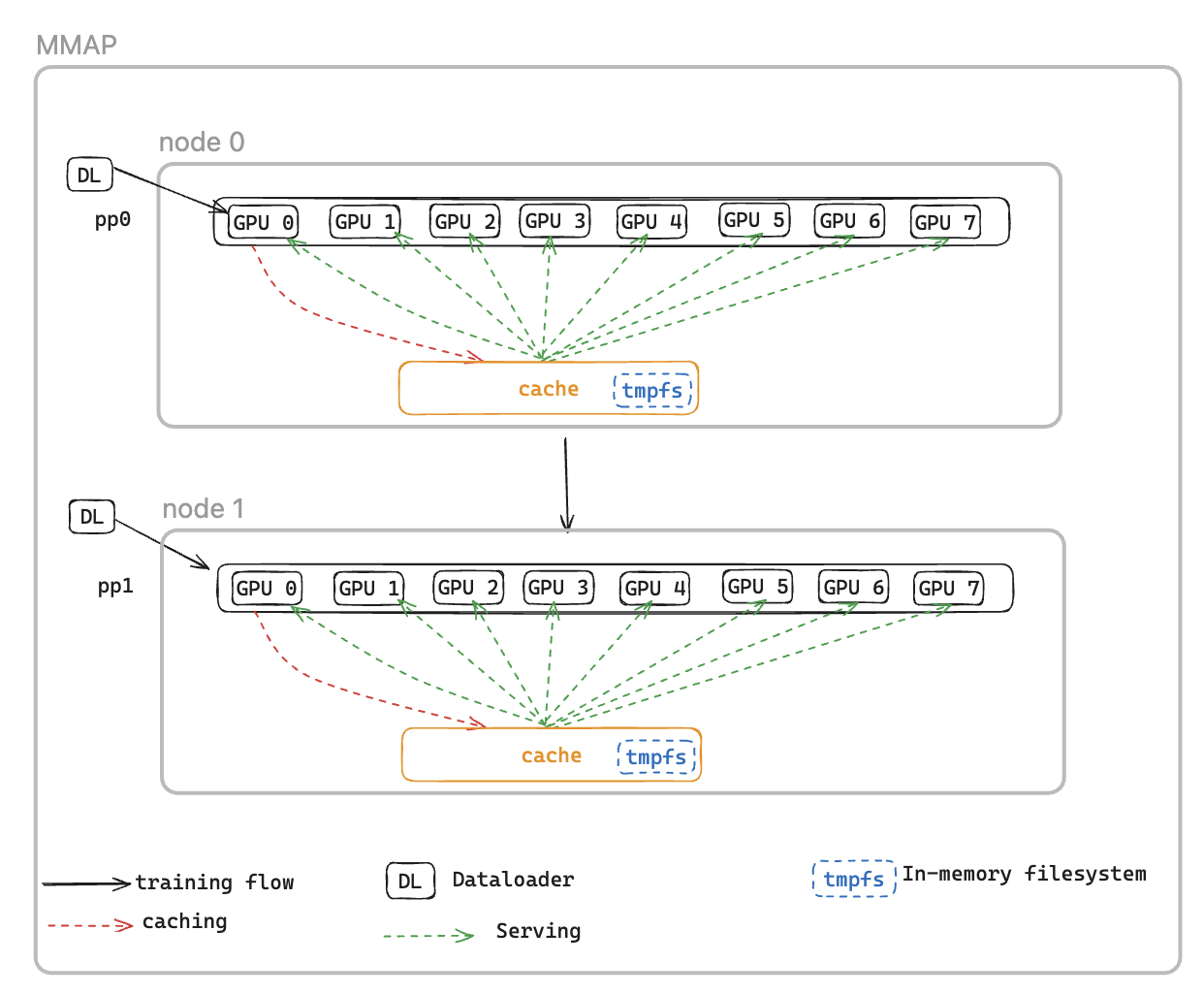
MMAP 資料載入器提供下列兩個功能:
資料預先擷取 - 主動擷取和快取資料載入器產生的資料
持久性快取 - 將已取用和預先擷取的批次存放在臨時檔案系統中,在程序重新啟動後仍能存活
使用快取,訓練任務將受益於:
減少記憶體足跡 - 利用記憶體映射的 I/O 來維護主機 CPU 記憶體中資料的單一共用複本,消除 GPU 程序之間的備援複本 (例如,在具有 8 GPUs 的 p5 執行個體上,將 8 個複本減少為 1 個)
更快的復原 - 讓訓練立即從快取批次恢復,減少重新啟動的平均時間 (MTTR),無需等待資料載入器重新初始化和產生第一批次
MMAP 組態
若要使用 MMAP,只需將原始資料模組傳入 MMAPDataModule
data_module=MMAPDataModule( data_module=MY_DATA_MODULE(...), mmap_config=CacheResumeMMAPConfig( cache_dir=self.cfg.mmap.cache_dir, checkpoint_frequency=self.cfg.mmap.checkpoint_frequency), )
CacheResumeMMAPConfig:MMAP Dataloader 參數控制快取目錄位置、大小限制和資料擷取委派。根據預設,每個節點只有 TP 排名 0 會從來源擷取資料,而相同資料複寫群組中的其他排名會從共用快取讀取,消除備援傳輸。
MMAPDataModule:它會包裝原始資料模組,並傳回 mmap 資料載入器以進行訓練和驗證。
請參閱啟用 MMAP 的範例
API 參考
CacheResumeMMAPConfig
class hyperpod_checkpointless_training.dataloader.config.CacheResumeMMAPConfig( cache_dir='/dev/shm/pdl_cache', prefetch_length=10, val_prefetch_length=10, lookback_length=2, checkpoint_frequency=None, model_parallel_group=None, enable_batch_encryption=False)
HyperPod 無檢查點訓練中快取-恢復記憶體映射 (MMAP) 資料載入器功能的組態類別。
此組態可透過快取和預先擷取功能實現高效率的資料載入,允許透過在記憶體映射檔案中維護快取的資料批次,在失敗後快速恢復訓練。
參數
-
cache_dir (str、選用) – 儲存快取資料批次的目錄路徑。預設:"/dev/shm/pdl_cache"
-
prefetch_length (int、選用) – 在訓練期間要預先擷取的批次數。預設:10
-
val_prefetch_length (int、選用) – 驗證期間要預先擷取的批次數量。預設:10
-
lookback_length (int、選用) – 要保留在快取中以供潛在重複使用的先前使用批次數量。預設:2
-
checkpoint_frequency (int、選用) – 模型檢查點步驟的頻率。用於快取效能最佳化。預設:無
-
model_parallel_group (物件,選用) – 模型平行處理的程序群組。如果無,則會自動建立 。預設:無
-
enable_batch_encryption (bool,選用) – 是否啟用快取批次資料的加密。預設:False
方法
create(dataloader_init_callable, parallel_state_util, step, is_data_loading_rank, create_model_parallel_group_callable, name='Train', is_val=False, cached_len=0)
建立並傳回設定的 MMAP 資料載入器執行個體。
參數
-
dataloader_init_callable (可呼叫) – 初始化基礎資料載入器的函數
-
parallel_state_util (物件) – 用於管理跨程序平行狀態的公用程式
-
step (int) – 要在訓練期間繼續的資料步驟
-
is_data_loading_rank (可呼叫) – 如果目前排名應載入資料,則傳回 True 的函數
-
create_model_parallel_group_callable (Callable) – 建立模型平行處理群組的函數
-
name (str、選用) – 資料載入器的名稱識別符。預設:「訓練」
-
is_val (bool,選用) – 這是否為驗證資料載入器。預設:False
-
cached_len (int、選用) – 從現有快取恢復時的快取資料長度。預設:0
傳回 CacheResumePrefetchedDataLoader或 CacheResumeReadDataLoader – 設定的 MMAP 資料載入器執行個體
ValueError 如果步驟參數為 ,則引發 None。
範例
from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig # Create configuration config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100, enable_batch_encryption=False ) # Create dataloader dataloader = config.create( dataloader_init_callable=my_dataloader_init, parallel_state_util=parallel_util, step=current_step, is_data_loading_rank=lambda: rank == 0, create_model_parallel_group_callable=create_mp_group, name="TrainingData" )
備註
-
快取目錄應有足夠的空間和快速的 I/O 效能 (例如,記憶體內儲存的 /dev/shm)。
-
設定 會將快取管理與模型檢查點保持一致,以
checkpoint_frequency改善快取效能 -
對於驗證資料載入器 (
is_val=True),步驟會重設為 0,並強制冷啟動 -
根據目前排名是否負責資料載入,使用不同的資料載入器實作
MMAPDataModule
class hyperpod_checkpointless_training.dataloader.mmap_data_module.MMAPDataModule( data_module, mmap_config, parallel_state_util=MegatronParallelStateUtil(), is_data_loading_rank=None)
PyTorch Lightning DataModule 包裝函式,可將記憶體映射 (MMAP) 資料載入功能套用至現有的 DataModules,以進行無檢查點訓練。
此類別包裝現有的 PyTorch Lightning DataModule,並使用 MMAP 功能增強它,以便在訓練失敗期間實現高效的資料快取和快速復原。它維持與原始 DataModule 介面的相容性,同時新增無檢查點訓練功能。
Parameters
- data_module (pl.LightningDataModule)
要包裝的基礎 DataModule (例如 LLMDataModule)
- mmap_config (MMAPConfig)
定義快取行為和參數的 MMAP 組態物件
parallel_state_util(MegatronParallelStateUtil,選用)用於跨分散式程序管理平行狀態的公用程式。預設:MegatronParallelStateUtil()
is_data_loading_rank(可呼叫、選用)如果目前排名應載入資料,則傳回 True 的函數。如果無,則預設為 parallel_state_util.is_tp_0。預設:無
Attributes
global_step(int)目前全域訓練步驟,用於從檢查點繼續
cached_train_dl_len(int)訓練資料載入器的快取長度
cached_val_dl_len(int)驗證資料載入器的快取長度
方法
setup(stage=None)
為指定的訓練階段設定基礎資料模組。
stage(str、選用)訓練階段 ('fit'、'validate'、'test' 或 'predict')。預設:無
train_dataloader()
使用 MMAP 包裝建立訓練 DataLoader。
傳回:DataLoader – MMAP 包裝的訓練 DataLoader,具有快取和預先擷取功能
val_dataloader()
使用 MMAP 包裝建立驗證 DataLoader。
傳回:DataLoader – 使用快取功能的 MMAP 包裝驗證 DataLoader
test_dataloader()
如果基礎資料模組支援,請建立測試 DataLoader。
傳回:DataLoader 或無 – 從基礎資料模組測試 DataLoader,如果不支援則測試無
predict_dataloader()
如果基礎資料模組支援預測 DataLoader,請建立預測 DataLoader。
傳回:DataLoader 或 None – 從基礎資料模組預測 DataLoader,如果不支援則為 None
load_checkpoint(checkpoint)
載入檢查點資訊,以從特定步驟繼續訓練。
- 檢查點 (dict)
包含 'global_step' 索引鍵的檢查點字典
get_underlying_data_module()
取得基礎包裝的資料模組。
傳回:pl.LightningDataModule – 包裝的原始資料模組
state_dict()
取得 MMAP DataModule 的狀態字典以進行檢查點。
傳回:dict – 包含快取資料載入器長度的字典
load_state_dict(state_dict)
載入狀態字典以還原 MMAP DataModule 狀態。
state_dict(裁剪)要載入的狀態字典
屬性
data_sampler
將基礎資料模組的資料取樣器公開至 NeMo 架構。
傳回:物件或無 – 基礎資料模組的資料取樣器
範例
from hyperpod_checkpointless_training.dataloader.mmap_data_module import MMAPDataModule from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig from my_project import MyLLMDataModule # Create MMAP configuration mmap_config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100 ) # Create original data module original_data_module = MyLLMDataModule( data_path="/path/to/data", batch_size=32 ) # Wrap with MMAP capabilities mmap_data_module = MMAPDataModule( data_module=original_data_module, mmap_config=mmap_config ) # Use in PyTorch Lightning Trainer trainer = pl.Trainer() trainer.fit(model, data=mmap_data_module) # Resume from checkpoint checkpoint = {"global_step": 1000} mmap_data_module.load_checkpoint(checkpoint)
備註
包裝函式使用 __getattr__ 委派對基礎資料模組的大多數屬性存取權
只有資料載入排名會實際初始化並使用基礎資料模組;其他排名則使用仿造資料載入器
保留快取的資料載入器長度,以在訓練恢復期間最佳化效能
