本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
非對稱 Shapley 值
SageMaker Clarify 時間序列預測模型解釋解決方案是植根於合作博弈論
背景介紹
目標是計算指定預測模型 f 的輸入特徵歸因。預測模型採用下列輸入:
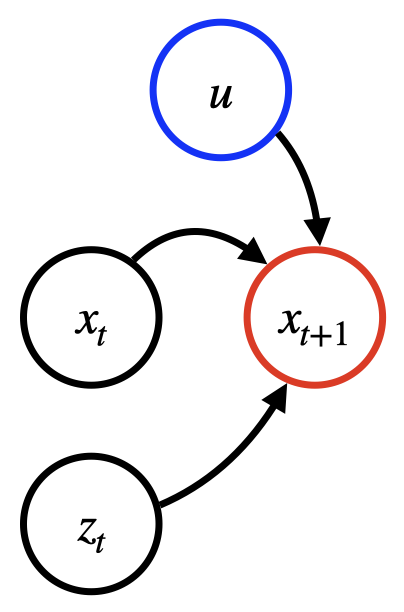
過去時間序列 (目標 TS)。例如,這可能是巴黎柏林路線過去每日的火車乘客,以 xt 表示。
(選用) 共變數時間序列。例如,這可能是節日和天氣資料,以 zt ∈ RS 表示。使用時,共變數 TS 只能用於過去時間步驟,或者也可以用於未來時間步驟 (包含在節日行事曆中)。
(選用) 靜態共變數,例如服務品質 (例如一流或二流),以 u ∈ RE 表示。
可以省略靜態共變數、動態共變數或兩者,取決於特定應用程式案例。假設預測範圍 K ≥ 0 (例如 K=30 天),則可以透過下列公式描述模型預測的特徵:f(x[1:T], z[1:T+K], u) = x[T+1:T +K+1]。
下圖顯示典型預測模型的相依性結構。時間 t+1 的預測取決於先前提到的三種輸入類型。
Method
透過在原始輸入衍生的一系列點上查詢時間序列模型 f 來計算解釋。在博弈理論建構之後,Clarify 會平均預測中迭代地計算輸入混淆 (亦即,設定為基準值) 部分所導致的差異。時間結構可以按時間順序或反時間順序或兩者進行導覽。按時間順序的解釋是透過從第一個時間步驟開始迭代地新增資訊來建置的,而按反時間順序的解釋則是從最後一個步驟開始。在出現近期性偏差的情況下,後者模式可能更合適,例如預測股票價格時。計算解釋的一個重要屬性是,如果模型提供確定性輸出,它們會加總到原始模型輸出。
產生的歸因
產生的歸因是分數,標記特定時間步驟或輸入特徵對每個預測時間步驟最終預測的個別貢獻。Clarify 提供以下兩個精細程度進行解釋:
時間解釋成本低廉,且僅提供特定時間步驟的相關資訊,例如了解過去第 19 天的資訊對預測未來第 1 天有多少貢獻。這些歸因不會個別解釋靜態共變數,也不會彙總目標和共變數時間序列的解釋。歸因是矩陣 A,其中每個 Atk 都是時間步驟 t 對預測時間步驟 T+k 的歸因。請注意,如果模型接受未來的共變數,t 可以大於 T。
精細解釋在運算上更為密集,並會提供輸入變數所有歸因的完整明細。
注意
精細解釋僅支援按時間順序排序。
產生的歸因是由下列項目組成的三元組:
與輸入時間序列相關的矩陣 Ax ∈ RT×K,其中 Atkx 是 xt 對預測步驟 T+k 的歸因
與共變數時間序列相關的張量 Az ∈ RT+K×S×K,其中 Atskz 是 zts (即 sth 共變數 TS) 對預測步驟 T+k 的歸因
與靜態共變數相關的矩陣 Au ∈ RE×K,其中 Aeku 是 ue (eth 靜態共變數) 對預測步驟 T+k 的歸因
無論精細程度為何,解釋也會包含偏移向量 B ∈ RK,在所有資料混淆時,代表模型的「基本行為」。
