本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 SageMaker Clarify 進行公平性、模型可解釋性和偏差偵測
您可以使用 Amazon SageMaker Clarify 來了解公平性和模型可解釋性,以及解釋和偵測模型中的偏差。您可以設定 Amazon SageMaker Clarify 處理任務,以計算偏差指標和特徵歸因,並產生模型可解釋性的報告。SageMaker Clarify 處理工作是使用專門的 SageMaker Clarify 容器影像來實作。下頁描述 SageMaker Clarify 的運作方式,以及如何開始使用分析。
什麼是機器學習預測的公平性和模型可解釋性?
機器學習 (ML) 模型不斷協助在各種領域做出決策,包括金融服務、醫療保健、教育和人力資源。政策制定者、監管者和倡導者提高了對機器學習 (ML) 和資料驅動系統帶來的道德和政策挑戰的意識。Amazon SageMaker Clarify 可協助您了解 ML 模型進行特定預測的原因,以及在訓練或推論期間,此偏差是否會影響此預測。SageMaker Clarify 也會提供工具,其可協助您建置較少偏差且更易於理解的機器學習模型。SageMaker Clarify 也可以產生模型治理報告,您可以將這些報告提供給風險與合規團隊,以及外部監管機構。使用 SageMaker Clarify,您可以執行下列動作:
-
偵測模型預測中的偏差,並協助解釋該模型預測。
-
識別訓練前資料中的偏差類型。
-
識別訓練後資料中的偏差類型,這些偏差可能會在訓練期間或在模型生產中時出現。
SageMaker Clarify 可協助解釋您的模型如何使用特徵歸因進行預測。它還可以監控生產中的推論模型是否存在偏差或特徵歸因偏離。此資訊可在下列區域中協助您:
-
法規 – 政策制定者和其他監管者可能會擔心使用 ML 模型輸出的決策會產生歧視性影響。例如,ML 模型可能會編碼偏差並影響自動化決策。
-
商業 – 受管制網域可能需要 ML 模型如何進行預測的可靠說明。對於依賴可靠性、安全性和合規性的產業而言,模型可解釋性可能特別重要。這些可以包括金融服務、人力資源、醫療保健和自動化運輸。例如,貸款應用程式可能需要提供有關 ML 模型如何對貸款主管、預測者和客戶進行特定預測的說明。
-
資料科學 – 當資料科學家和機器學習工程師可以判斷模型是根據雜訊還是不相關的特徵進行推論時,他們可以偵錯並改善 ML 模型。他們也可以了解其模型的限制,以及其模型可能遇到的故障模式。
如需示範如何針對將 SageMaker Clarify 整合到 SageMaker AI 管道的詐騙性汽車宣告建構和建置完整機器學習模型的部落格文章,請參閱 Architect,並使用 建置完整的機器學習生命週期 AWS:end-to-end Amazon SageMaker AI
在 ML 生命週期中評估公平性和可解釋性的最佳實務
公平性做為程序 – 偏差和公平性的概念取決於應用程式。偏差的測量和偏差指標的選擇可能受到社交、法律和其他非技術考量的引導。成功採用公平性感知 ML 方法包括建立共識並實現關鍵利益相關者之間的協作。這些可能包括產品、政策、法律、工程、AI/ML 團隊、最終使用者和社群。
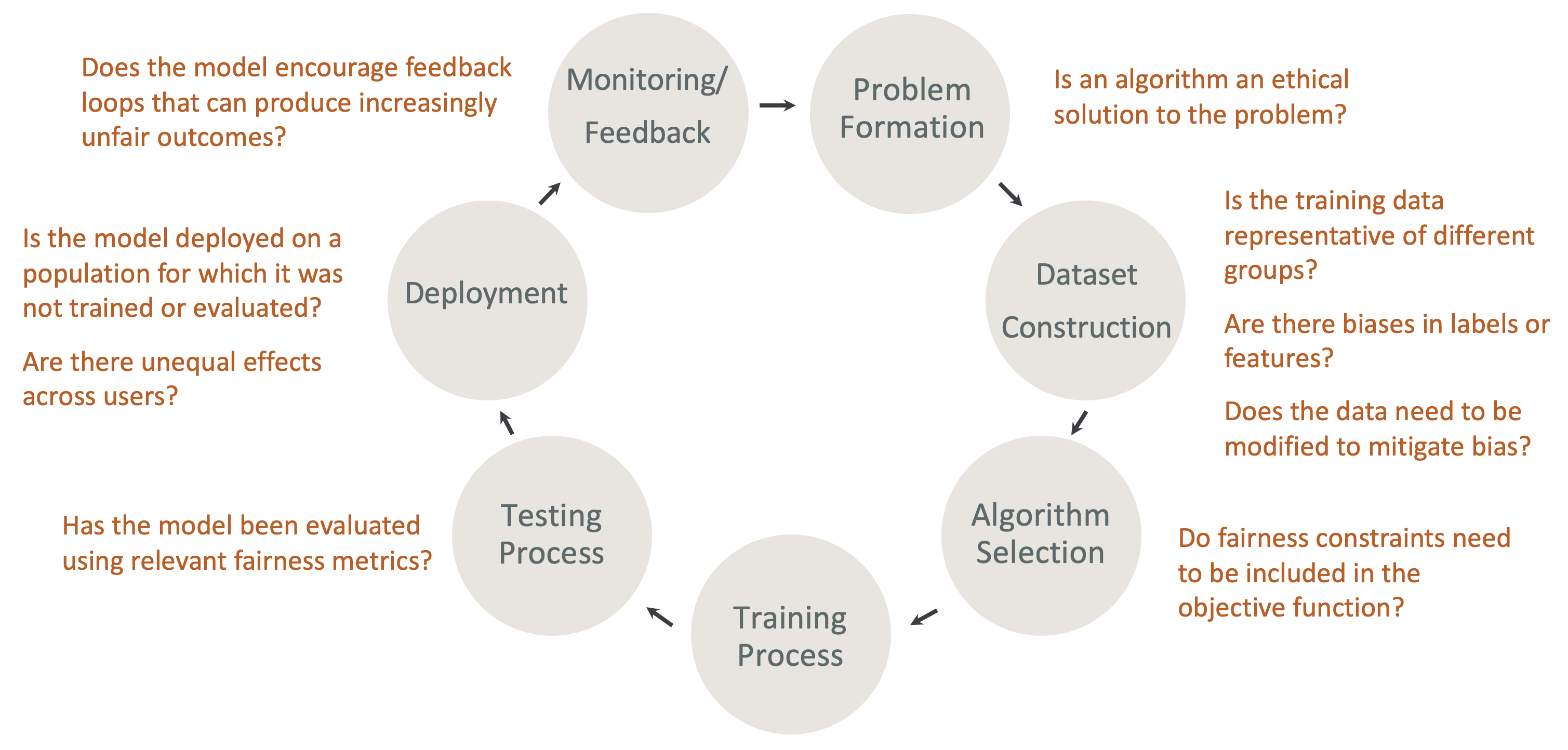
ML 生命週期中設計公平性和可解釋性 – 在 ML 生命週期的每個階段考慮公平性和可解釋性。這些階段包括問題形成、資料集建構、演算法選擇、模型訓練程序、測試程序、部署,以及監控和意見回饋。具備正確的工具進行此分析非常重要。我們建議在 ML 生命週期期間詢問下列問題:
-
模型是否鼓勵可能產生越來越不公平結果的意見回饋迴圈?
-
演算法是否為問題的道德解決方案?
-
訓練資料是否代表不同群組?
-
標籤或特徵中是否存在偏差?
-
是否需要修改資料以緩解偏差?
-
目標函式中是否需要包括公平性限制條件?
-
模型是否已使用相關的公平性指標進行評估?
-
使用者之間的效果是否不平等?
-
模型是否部署在未經訓練或評估的人口上?
SageMaker AI 說明和偏差文件指南
在訓練模型前後,可能會發生偏差,並可在資料中測量偏差。SageMaker Clarify 可以在訓練後提供模型預測的說明,以及為部署到生產的模型提供說明。SageMaker Clarify 也可以監控生產中的模型,在其基準解釋性歸因中是否有任何偏離,並在需要時計算基準。使用 SageMaker Clarify 解釋和偵測偏差的文件結構如下:
-
如需為偏差和可解釋性設定處理任務的相關資訊,請參閱設定 SageMaker Clarify 處理工作。
-
如需在預先處理資料用來訓練模型之前在其中偵測偏差的相關資訊,請參閱訓練前資料偏差。
-
如需偵測訓練後資料和模型偏差的相關資訊,請參閱訓練後資料和模型偏差。
-
如需用來解釋訓練後模型預測的模型不可知特徵歸因方法的相關資訊,請參閱模型可解釋性。
-
如需監控是否有特徵歸因偏離模型訓練期間建立的基準的相關資訊,請參閱生產中模型的特徵屬性偏離。
-
如需監控生產中模型是否偏離基準的相關資訊,請參閱生產中模型的偏差偏離。
-
如需從 SageMaker AI 端點即時取得說明的相關資訊,請參閱SageMaker Clarify 線上可解釋性。
SageMaker Clarify 處理工作的運作方式
您可以使用 SageMaker Clarify 來分析資料集和模型的可解釋性和偏差。SageMaker Clarify 處理工作會使用 SageMaker Clarify 處理容器與包含輸入資料集的 Amazon S3 儲存貯體進行互動。您也可以使用 SageMaker Clarify 來分析部署至 SageMaker AI 推論端點的客戶模型。
下圖顯示 SageMaker Clarify 處理工作如何與輸入資料互動,以及如何選擇性地與客戶模型互動。此互動取決於所執行的分析的特定類型。SageMaker Clarify 處理容器會從 S3 儲存貯體取得要分析的輸入資料集和組態。對於某些分析類型 (包括特徵分析),SageMaker Clarify 處理容器必須將請求傳送至模型容器。然後,它會從模型容器傳送的回應中擷取模型預測。之後,SageMaker Clarify 處理容器會計算分析結果並將其儲存至 S3 儲存貯體。

您可以在機器學習工作流程生命週期的多個階段中執行 SageMaker Clarify 處理工作。SageMaker Clarify 可協助您計算下列分析類型:
-
訓練前偏差指標。這些指標可協助您瞭解資料中的偏差,以便您可以解決問題,並在更公平的資料集上訓練模型。如需訓練前偏差指標的相關資訊,請參閱訓練前偏差指標。若要執行工作以分析訓練前的偏差指標,您必須將資料集和 JSON 分析組態檔案提供給 分析組態檔案。
-
訓練後偏差指標。這些指標可協助您了解演算法、超參數選擇所導致的任何偏差,或是在流程早期不明顯的任何偏差。如需訓練後偏差指標的詳細資訊,請參閱訓練後資料和模型偏差指標。除了資料和標籤之外,SageMaker Clarify 還使用模型預測來識別偏差。若要執行工作以分析訓練後的偏差指標,您必須提供資料集和 JSON 分析組態檔案。組態應包括模型或端點名稱。
-
Shapley 值,可協助您了解特徵對模型預測內容的影響。如需 Shapley 值的詳細資訊,請參閱使用塑形值的特徵屬性。此功能需要訓練過的模型。
-
部分相依性圖 (PDP),可協助您了解如果改變一個特徵的值,預測的目標變數會改變多少。如需 PDP 的詳細資訊,請參閱部分相依性繪圖 (PDP) 分析。此特徵需要已訓練的模型。
SageMaker Clarify 需要模型預測來計算訓練後的偏差指標和功能屬性。您可以提供端點,或是 SageMaker Clarify 將使用您的模型名稱來建立暫時端點,也稱為陰影端點。計算完成後,SageMaker Clarify 容器會刪除陰影端點。在高層級中,SageMaker Clarify 容器會完成下列步驟:
-
驗證輸入和參數。
-
建立陰影端點 (如果有提供模型名稱)。
-
將輸入資料集載入資料框架。
-
如有必要,可從端點取得模型預測。
-
計算偏差指標和功能屬性。
-
刪除陰影端點。
-
產生分析結果。
SageMaker Clarify 處理工作完成後,分析結果將儲存於您在工作的處理輸出參數中指定的輸出位置。這些結果包括有偏差指標和全域功能屬性的 JSON 檔案、視覺化報告,以及本機功能屬性的其他檔案。您可以從輸出位置下載結果並查看。
如需有關偏差指標、可解釋性以及如何解譯的其他資訊,請參閱了解 Amazon SageMaker Clarify 如何協助偵測偏差
範例筆記本
下列各節包含筆記本以協助您開始使用 SageMaker Clarify,將其用於特殊任務,包括分散式任務內的任務,以及將其用於電腦視覺。
開始使用
下列範例筆記本說明如何使用 SageMaker Clarify 來開始使用可解釋性和模型偏差任務。這些任務包括建立處理任務、訓練機器學習 (ML) 模型,以及監控模型預測:
-
使用 Amazon SageMaker Clarify 進行可解釋性和偏差偵測
- 使用 SageMaker Clarify 建立處理任務,以偵測偏差和解釋模型預測。 -
監控偏差偏離和功能屬性偏離 Amazon SageMaker Clarify
— 使用 Amazon SageMaker Model Monitor 監控隨著時間的偏差偏離和功能屬性偏離。 -
如何將 JSON Lines 格式的資料集讀入
SageMaker Clarify 處理任務。 -
緩解偏差、訓練另一個無偏差的模型,並將其放入模型登錄
– 使用虛擬少數類別過抽樣技術 (SMOTE) 和 SageMaker Clarify 來緩解偏差、訓練另一個模型,然後將新模型放入模型註冊庫。此範例筆記本也會說明如何將新的模型成品,包括資料、程式碼和模型中繼資料,放入模型註冊庫中。此筆記本是系列的一部分,說明如何將 SageMaker Clarify 整合至 SageMaker AI 管道,其描述在透過 AWS設計和建置完整的機器學習生命週期 部落格文章中。
特殊案例
下列筆記本說明如何將 SageMaker Clarify 用於您自己容器內包括的特殊案例,以及用於自然語言處理任務:
-
使用 SageMaker Clarify 實現公平性和可解釋性 (自帶容器)
- 建置您自己的模型和容器,其可與 SageMaker Clarify 整合,以測量偏差並產生可解釋性分析報告。此範例筆記本也會介紹關鍵術語,並說明如何透過 SageMaker Studio Classic 存取報告。 -
使用 SageMaker Clarify Spark 分散式處理實現公平性和可解釋性
- 使用分散式處理來執行 SageMaker Clarify 任務,測量資料集的訓練前偏差和模型的訓練後偏差。此範例筆記本也說明如何取得模型輸出上輸入特徵重要性的解釋,以及透過 SageMaker Studio Classic 存取可解釋性分析報告。 -
使用 SageMaker Clarify - 部分相依性圖 (PDP) 實現可解釋性
- 使用 SageMaker Clarify 產生 PDP 並存取模型可解釋性報告。 -
使用 SageMaker Clarify 自然語言處理 (NLP) 可解釋性來解釋文字情緒分析
- 使用 SageMaker Clarify 進行文字情緒分析。
這些筆記本已通過驗證,可在 Amazon SageMaker Studio Classic 中執行。如果您需要有關如何在 Studio Classic 中開啟筆記本的指示,請參閱建立或開啟 Amazon SageMaker Studio Classic 筆記本。如果系統提示您選擇核心,請選擇 Python 3 (資料科學)。
