本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
# 建立模型套件映像
Amazon SageMaker AI 模型套件是預先訓練的模型,可進行預測,不需要買方進一步訓練。您可以在 SageMaker AI 中建立模型套件,並在其中發佈您的機器學習產品 AWS Marketplace。下列各節說明如何為其建立模型套件 AWS Marketplace。這包括建立容器映像,以及在本機建置和測試映像。
**Topics**
+ [概觀](#ml-model-package-images-overview)
+ [建立模型套件的推論映像](#ml-creating-an-inference-image-for-model-packages)
## 概觀
模型套件包含下列元件:
+ 儲存在 [Amazon Elastic Container Registry](https://aws.amazon.com/ecr/) (Amazon ECR) 中的推論映像
+ (選用) 模型成品,分別存放在 [Amazon S3](https://aws.amazon.com/s3/) 中
**注意**
模型成品是模型用來進行預測的檔案,通常是您自己的訓練程序的結果。成品可以是模型所需的任何檔案類型,但必須使用.tar.gz 壓縮。對於模型套件,它們可以綁定在您的推論映像中,或單獨存放在 Amazon SageMaker AI 中。Amazon S3 中存放的模型成品會在執行時間載入推論容器。發佈模型套件時,這些成品會發佈並存放在買方無法直接存取的 AWS Marketplace 擁有 Amazon S3 儲存貯體中。
**提示**
如果您的推論模型使用 Gluon、Keras、MXNet、PyTorch、TensorFlow、TensorFlow-Lite 或 ONNX 等深度學習架構建置,請考慮使用 Amazon SageMaker AI Neo。Neo 可以自動最佳化部署到特定系列雲端執行個體類型的推論模型`ml.p2`,例如 `ml.c4`、 和其他。如需詳細資訊,請參閱《*Amazon SageMaker AI 開發人員指南*》中的[使用 Neo 最佳化模型效能](https://docs.aws.amazon.com/sagemaker/latest/dg/neo.html)。
下圖顯示發佈和使用模型套件產品的工作流程。
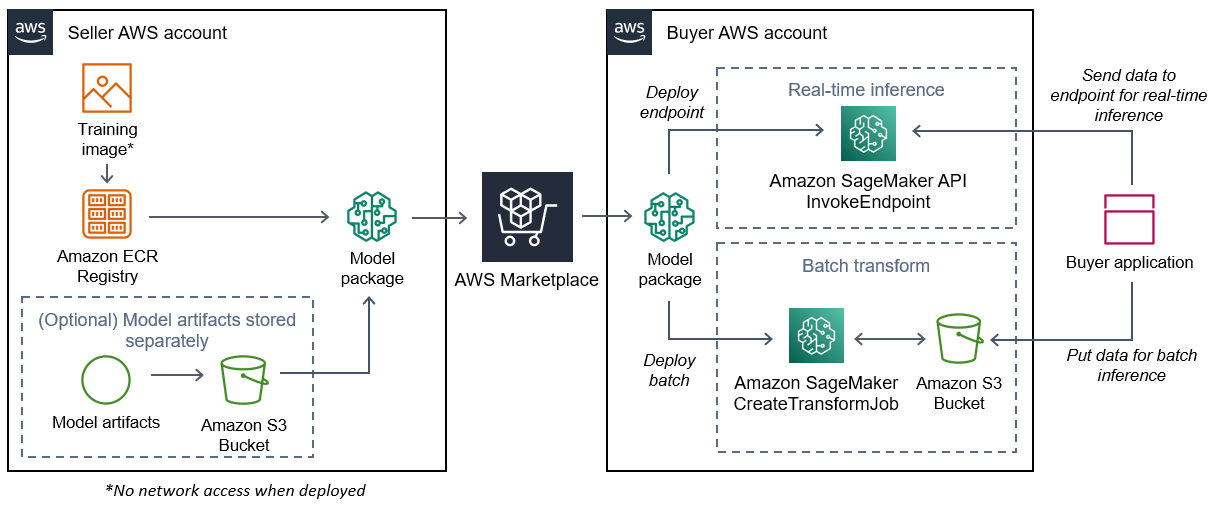
為 建立 SageMaker AI 模型套件的工作流程 AWS Marketplace 包括以下步驟:
1. 賣方會建立推論映像 (部署時無法存取網路),並將其推送至 Amazon ECR 登錄檔。
模型成品可以綁定在推論影像中,也可以單獨存放在 S3 中。
1. 然後,賣方會在 Amazon SageMaker AI 中建立模型套件資源,並發佈其 ML 產品 AWS Marketplace。
1. 買方訂閱 ML 產品並部署模型。
**注意**
模型可以部署為即時推論的端點,也可以部署為批次任務,以同時取得整個資料集的預測。如需詳細資訊,請參閱[部署推論模型](https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-model.html)。
1. SageMaker AI 會執行推論映像。推論映像中未綁定的任何賣方提供的模型成品都會在執行時間動態載入。
1. SageMaker AI 使用容器的 HTTP 端點將買方的推論資料傳遞至容器,並傳回預測結果。
## 建立模型套件的推論映像
本節提供逐步解說,將您的推論程式碼封裝到模型套件產品的推論映像中。程序包含下列步驟:
**Topics**
+ [步驟 1:建立容器映像](#ml-step-1-creating-the-container-image)
+ [步驟 2:在本機建置和測試映像](#ml-step-2-building-and-testing-the-image-locally)
推論映像是包含推論邏輯的 Docker 映像。執行時間的容器公開 HTTP 端點,以允許 SageMaker AI 將資料傳入和傳出您的容器。
**注意**
以下是推論映像的封裝程式碼範例。如需詳細資訊,請參閱在 GitHub [上使用 Docker 容器搭配 SageMaker AI](https://docs.aws.amazon.com/sagemaker/latest/dg/your-algorithms.html) 和 [AWS Marketplace SageMaker AI 範例](https://github.com/aws/amazon-sagemaker-examples/tree/master/aws_marketplace)。
下列範例使用 Web 服務 [Flask](https://pypi.org/project/Flask/) 以簡化操作,而且不視為生產就緒。
### 步驟 1:建立容器映像
若要讓推論映像與 SageMaker AI 相容,Docker 映像必須公開 HTTP 端點。當您的容器執行時, SageMaker AI 會將要推論的買方輸入傳遞至容器的 HTTP 端點。推論結果會在 HTTP 回應的內文中傳回。
下列逐步解說使用 Linux Ubuntu 發行版本,在開發環境中使用 Docker CLI。
+ [建立 Web 伺服器指令碼](#ml-create-the-web-server-script)
+ [建立容器執行的指令碼](#ml-create-the-script-for-the-container-run)
+ [建立 `Dockerfile`](#ml-create-the-dockerfile)
+ [封裝或上傳模型成品](#ml-package-or-upload-the-model-artifacts)
#### 建立 Web 伺服器指令碼
此範例使用稱為 [Flask](https://pypi.org/project/Flask/) 的 Python 伺服器,但您可以使用適用於架構的任何 Web 伺服器。
**注意**
為了簡化起見,此處使用 [Flask](https://pypi.org/project/Flask/)。它不被視為生產就緒的 Web 伺服器。
建立 Flask Web 伺服器指令碼,在 SageMaker AI 使用的 TCP 連接埠 8080 上提供兩個 HTTP 端點。以下是兩個預期的端點:
+ `/ping` – SageMaker AI 向此端點發出 HTTP GET 請求,以檢查您的容器是否已準備就緒。當您的容器準備就緒時,它會使用 HTTP 200 回應碼來回應此端點的 HTTP GET 請求。
+ `/invocations` – SageMaker AI 向此端點發出 HTTP POST 請求以進行推論。推論的輸入資料會在請求的內文中傳送。使用者指定的內容類型會在 HTTP 標頭中傳遞。回應的內文是推論輸出。如需逾時的詳細資訊,請參閱 [建立機器學習產品的需求和最佳實務](ml-listing-requirements-and-best-practices.md)。
**`./web_app_serve.py`**
```
# Import modules
import json
import re
from flask import Flask
from flask import request
app = Flask(__name__)
# Create a path for health checks
@app.route("/ping")
def endpoint_ping():
return ""
# Create a path for inference
@app.route("/invocations", methods=["POST"])
def endpoint_invocations():
# Read the input
input_str = request.get_data().decode("utf8")
# Add your inference code between these comments.
#
#
#
#
#
# Add your inference code above this comment.
# Return a response with a prediction
response = {"prediction":"a","text":input_str}
return json.dumps(response)
```
在先前的範例中,沒有實際的推論邏輯。針對您的實際推論影像,將推論邏輯新增至 Web 應用程式,以便處理輸入並傳回實際預測。
您的推論映像必須包含所有必要的相依性,因為它將無法存取網際網路,也無法呼叫任何 AWS 服務。
**注意**
即時和批次推論都會呼叫相同的程式碼
#### 建立容器執行的指令碼
建立名為 SageMaker AI `serve` 在執行 Docker 容器映像時執行的指令碼。下列指令碼會啟動 HTTP Web 伺服器。
**`./serve`**
```
#!/bin/bash
# Run flask server on port 8080 for SageMaker
flask run --host 0.0.0.0 --port 8080
```
#### 建立 `Dockerfile`
在建置內容`Dockerfile`中建立 。此範例使用 Ubuntu 18.04,但您可以從適用於架構的任何基礎映像開始。
`./Dockerfile`
```
FROM ubuntu:18.04
# Specify encoding
ENV LC_ALL=C.UTF-8
ENV LANG=C.UTF-8
# Install python-pip
RUN apt-get update \
&& apt-get install -y python3.6 python3-pip \
&& ln -s /usr/bin/python3.6 /usr/bin/python \
&& ln -s /usr/bin/pip3 /usr/bin/pip;
# Install flask server
RUN pip install -U Flask;
# Add a web server script to the image
# Set an environment to tell flask the script to run
COPY /web_app_serve.py /web_app_serve.py
ENV FLASK_APP=/web_app_serve.py
# Add a script that Amazon SageMaker AI will run
# Set run permissions
# Prepend program directory to $PATH
COPY /serve /opt/program/serve
RUN chmod 755 /opt/program/serve
ENV PATH=/opt/program:${PATH}
```
會將先前建立的兩個指令碼`Dockerfile`新增至映像。`serve` 指令碼的目錄會新增至 PATH,以便在容器執行時執行。
#### 封裝或上傳模型成品
從訓練模型到推論影像提供模型成品的兩種方式如下:
+ 使用推論映像靜態封裝。
+ 在執行時間動態載入。由於它是動態載入的,因此您可以使用相同的映像來封裝不同的機器學習模型。
如果您想要使用推論影像封裝模型成品,請在 中包含成品`Dockerfile`。
如果您想要動態載入模型成品,請將這些成品分別存放在 Amazon S3 的壓縮檔案 (.tar.gz) 中。建立模型套件時,請指定壓縮檔案的位置,SageMaker AI 會在執行容器`/opt/ml/model/`時擷取內容並將其複製到容器目錄。發佈模型套件時,這些成品會發佈並存放在買方無法直接存取的擁有 Amazon S3 儲存貯體中 AWS Marketplace 。
### 步驟 2:在本機建置和測試映像
在建置內容中,現在存在下列檔案:
+ `./Dockerfile`
+ `./web_app_serve.py`
+ `./serve`
+ 您的推論邏輯和 (選用) 相依性
接下來建置、執行和測試容器映像。
#### 建置映像
在建置內容中執行 Docker 命令,以建置和標記映像。此範例使用標籤 `my-inference-image`。
```
sudo docker build --tag my-inference-image ./
```
執行此 Docker 命令來建置映像後,您應該會看到輸出,因為 Docker 會根據 中的每行建置映像`Dockerfile`。完成後,您應該會看到類似以下內容的內容。
```
Successfully built abcdef123456
Successfully tagged my-inference-image:latest
```
#### 在本機執行
建置完成後,您可以在本機測試映像。
```
sudo docker run \
--rm \
--publish 8080:8080/tcp \
--detach \
--name my-inference-container \
my-inference-image \
serve
```
以下是 命令的詳細資訊:
+ `--rm` – 停止後自動移除容器。
+ `--publish 8080:8080/tcp` – 公開連接埠 8080 以模擬 SageMaker AI 傳送 HTTP 請求的連接埠。
+ `--detach` – 在背景執行容器。
+ `--name my-inference-container` – 為此執行中的容器命名。
+ `my-inference-image` – 執行建置的映像。
+ `serve` – 執行與執行容器時 SageMaker AI 執行的相同指令碼。
執行此命令後,Docker 會從您建置的推論映像建立容器,並在背景執行。容器會執行`serve`指令碼,這會啟動您的 Web 伺服器以進行測試。
#### 測試 ping HTTP 端點
當 SageMaker AI 執行您的容器時,它會定期 ping 端點。 當端點傳回狀態碼為 200 的 HTTP 回應時,它會向 SageMaker AI 發出訊號,表示容器已準備好進行推論。您可以執行下列命令來測試此項目,該命令會測試端點並包含回應標頭。
```
curl --include http://127.0.0.1:8080/ping
```
範例輸出如下所示。
```
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 0
Server: MyServer/0.16.0 Python/3.6.8
Date: Mon, 21 Oct 2019 06:58:54 GMT
```
#### 測試推論 HTTP 端點
當容器將 200 狀態碼傳回 ping 表示已準備好時,SageMaker AI 會透過`POST`請求將推論資料傳遞至 `/invocations` HTTP 端點。執行下列命令來測試推論點。
```
curl \
--request POST \
--data "hello world" \
http://127.0.0.1:8080/invocations
```
範例輸出如下所示。
`{"prediction": "a", "text": "hello world"}`
當這兩個 HTTP 端點正常運作時,推論映像現在與 SageMaker AI 相容。
**注意**
模型套件產品的模型有兩種部署方式:即時和批次。在這兩種部署中,SageMaker AI 在執行 Docker 容器時使用相同的 HTTP 端點。
若要停止容器,請執行下列命令。
```
sudo docker container stop my-inference-container
```
當您的推論映像準備就緒並經過測試時,您可以繼續 [將映像上傳至 Amazon Elastic Container Registry](ml-uploading-your-images.md)。