本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
建立 Apache Iceberg 資料表
AWS Lake Formation 支援建立 Apache Iceberg 資料表,這些資料表使用 中的 Apache Parquet 資料格式, AWS Glue Data Catalog 以及 Amazon S3 中的資料。Data Catalog 中的資料表是中繼資料定義,表示資料存放區中的資料。Lake Formation 預設會建立 Iceberg v2 資料表。有關 v1 和 v2 資料表之間的區別,請參閱 Apache Iceberg 文件中的格式版本變更
Apache Iceberg
您可以使用 Lake Formation 主控台或 AWS Glue API 中的 CreateTable操作,在 Data Catalog 中建立 Iceberg 資料表。如需詳細資訊,請參閱 CreateTable 動作 (Python: create_table)。
當您在 Data Catalog 中建立 Iceberg 資料表時,必須在 Amazon S3 中指定資料表格式和中繼資料檔案路徑,才能執行讀取和寫入。
當您向 註冊 Amazon S3 資料位置時,您可以使用 Lake Formation 使用精細存取控制許可來保護 Iceberg 資料表 AWS Lake Formation。對於 Amazon S3 中的來源資料和未向 Lake Formation 註冊的中繼資料,存取權取決於 Amazon S3 和 AWS Glue 動作的 IAM 許可政策。如需詳細資訊,請參閱管理 Lake Formation 許可。
注意
Data Catalog 不支援建立分區和新增 Iceberg 資料表屬性。
先決條件
若要在 Data Catalog 中建立 Iceberg 資料表,並設定 Lake Formation 資料存取許可,需要滿足下列要求:
-
在沒有向 Lake Formation 註冊資料的情況下建立 Iceberg 資料表所需的許可。
除了在 Data Catalog 中建立資料表所需的許可之外,資料表建立者還需要下列許可:
s3:PutObjecton resource arn:aws:s3:::{bucketName}-
s3:GetObjecton resource arn:aws:s3:::{bucketName} -
s3:DeleteObjecton resource arn:aws:s3:::{bucketName}
-
在向 Lake Formation 註冊資料的情況下建立 Iceberg 資料表所需的許可:
若要使用 Lake Formation 來管理和保護資料湖中的資料,請使用 Lake Formation 註冊具有資料表資料的 Amazon S3 位置。這可讓 Lake Formation 將登入資料提供給 AWS 分析服務,例如 Athena、Redshift Spectrum 和 Amazon EMR 來存取資料。如需註冊 Amazon S3 位置的詳細資訊,請參閱 將 Amazon S3 位置新增至您的資料湖。
讀取和寫入向 Lake Formation 註冊的基礎資料的主體需要下列許可:
-
lakeformation:GetDataAccess -
DATA_LOCATION_ACCESS在某個位置擁有資料位置許可的主體在所有子位置也擁有位置許可。
如需資料位置許可的詳細資訊,請參閱 基礎資料存取控制。
-
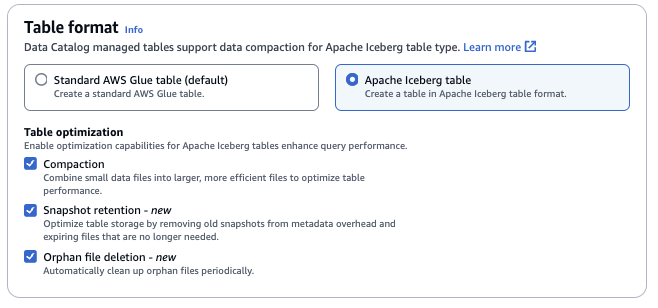
若要啟用壓縮,服務需要擔任有權在 Data Catalog 中更新資料表的 IAM 角色。如需詳細資訊,請參閱資料表最佳化先決條件。
建立 Iceberg 資料表
您可以使用 Lake Formation 主控台或此頁面所記載 AWS Command Line Interface 的方式建立 Iceberg v1 和 v2 資料表。您也可以使用 AWS Glue 主控台或 建立 Iceberg 資料表 AWS Glue 編目程式。如需詳細資訊,請參閱《 AWS Glue 開發人員指南》中的 Data Catalog 和編目程式。
若要建立 Iceberg 資料表