本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
支援 Spark DataFrame 的 DynamoDB 連接器
具有 Spark DataFrame 支援的 DynamoDB 連接器可讓您使用 Spark DataFrame APIs 從 DynamoDB 中讀取和寫入資料表。連接器設定步驟與以 DynamicFrame 為基礎的連接器相同,可在這裡找到。
若要在 DataFrame 型連接器程式庫中載入 ,請務必將 DynamoDB 連線連接至 Glue 任務。
注意
Glue 主控台 UI 目前不支援建立 DynamoDB 連線。您可以使用 Glue CLI (CreateConnection) 來建立 DynamoDB 連線:
aws glue create-connection \ --connection-input '{ \ "Name": "my-dynamodb-connection", \ "ConnectionType": "DYNAMODB", \ "ConnectionProperties": {}, \ "ValidateCredentials": false, \ "ValidateForComputeEnvironments": ["SPARK"] \ }'
建立 DynamoDB 連線時,您可以透過 CLI (CreateJob、UpdateJob ) 或直接在「任務詳細資訊」頁面將其連接至 Glue 任務:
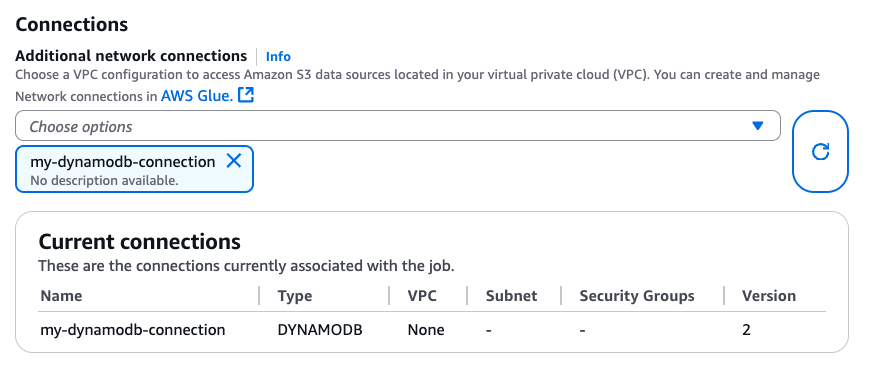
在確保 DYNAMODB 類型的連線連接至 Glue 任務時,您可以從 DataFrame 型連接器利用下列讀取、寫入和匯出操作。
使用 DataFrame 型連接器從 DynamoDB 讀取和寫入
下列程式碼範例示範如何透過 DataFrame 型連接器讀取和寫入 DynamoDB 資料表。其展示從一個資料表讀取以及寫入另一個資料表。
透過 DataFrame 型連接器使用 DynamoDB 匯出
對於大於 80 GB 的 DynamoDB 資料表大小,匯出操作偏好讀取操作。下列程式碼範例示範如何從資料表讀取、匯出至 S3,以及透過以 DataFrame 為基礎的連接器列印分割區數量。
注意
DynamoDB 匯出功能可透過 Scala DynamoDBExport 物件使用。Python 使用者可以透過 Spark 的 JVM 交錯存取它,或使用適用於 Python 的 AWS 開發套件 (boto3) 搭配 DynamoDB ExportTableToPointInTime API。
組態選項
讀取選項
| 選項 | 描述 | 預設 |
|---|---|---|
dynamodb.input.tableName |
DynamoDB 資料表名稱 (必要) | - |
dynamodb.throughput.read |
要使用的讀取容量單位 (RCU)。如果未指定,dynamodb.throughput.read.ratio則用於計算。 |
- |
dynamodb.throughput.read.ratio |
要使用的讀取容量單位 (RCU) 比率 | 0.5 |
dynamodb.table.read.capacity |
用於計算輸送量的隨需資料表讀取容量。此參數僅在隨需容量資料表中有效。預設為暖傳輸量讀取單位。 | - |
dynamodb.splits |
定義平行掃描操作中使用的區段數量。如果未提供,連接器將計算合理的預設值。 | - |
dynamodb.consistentRead |
是否使用強式一致讀取 | FALSE |
dynamodb.input.retry |
定義發生可重試的例外狀況時,我們執行的重試次數。 | 10 |
寫入選項
| 選項 | 描述 | 預設 |
|---|---|---|
dynamodb.output.tableName |
DynamoDB 資料表名稱 (必要) | - |
dynamodb.throughput.write |
要使用的寫入容量單位 (WCU)。如果未指定,dynamodb.throughput.write.ratio則用於計算。 |
- |
dynamodb.throughput.write.ratio |
要使用的寫入容量單位 (WCU) 比率 | 0.5 |
dynamodb.table.write.capacity |
用於計算輸送量的隨需資料表寫入容量。此參數僅在隨需容量資料表中有效。預設為暖輸送量寫入單位。 | - |
dynamodb.item.size.check.enabled |
如果為 true,連接器會計算項目大小,並在大小超過大小上限時中止,然後再寫入 DynamoDB 資料表。 | TRUE |
dynamodb.output.retry |
定義發生可重試的例外狀況時,我們執行的重試次數。 | 10 |
匯出選項
| 選項 | 描述 | 預設 |
|---|---|---|
dynamodb.export |
如果設定為ddb啟用 AWS Glue DynamoDB 匯出連接器,在 Glue AWS 任務期間ExportTableToPointInTimeRequet將調用新的連接器。系統將使用從 dynamodb.s3.bucket 和 dynamodb.s3.prefix 傳遞的位置產生新的匯出。如果設定為 s3 啟用 AWS Glue DynamoDB 匯出連接器,但 會略過建立新的 DynamoDB 匯出,而是使用 dynamodb.s3.bucket和 dynamodb.s3.prefix作為該資料表過去匯出的 Amazon S3 位置。 |
ddb |
dynamodb.tableArn |
要讀取的 DynamoDB 資料表。若將 dynamodb.export 設為 ddb,則為必要項目。 |
|
dynamodb.simplifyDDBJson |
如果設定為 true, 會執行轉換,以簡化匯出中存在的 DynamoDB JSON 結構結構結構的結構描述。 |
FALSE |
dynamodb.s3.bucket |
在 DynamoDB 匯出期間存放暫存資料的 S3 儲存貯體 (必要) | |
dynamodb.s3.prefix |
在 DynamoDB 匯出期間存放暫存資料的 S3 字首 | |
dynamodb.s3.bucketOwner |
指出跨帳戶 Amazon S3 存取所需的儲存貯體擁有者 | |
dynamodb.s3.sse.algorithm |
用於儲存暫存資料的儲存貯體的加密類型。有效值為 AES256 和 KMS。 |
|
dynamodb.s3.sse.kmsKeyId |
用於加密存放暫存資料的 S3 儲存貯體的 AWS KMS 受管金鑰 ID (如適用)。 | |
dynamodb.exportTime |
應進行匯出的時間點。有效值:代表 ISO-8601 執行個體的字串。 |
一般選項
| 選項 | 描述 | 預設 |
|---|---|---|
dynamodb.sts.roleArn |
跨帳戶存取要擔任的 IAM 角色 ARN | - |
dynamodb.sts.roleSessionName |
STS 工作階段名稱 | glue-dynamodb-sts-session |
dynamodb.sts.region |
STS 用戶端的區域 (適用於跨區域角色假設) | 與 region 選項相同 |
