Amazon Forecast 不再提供給新客戶。Amazon Forecast 的現有客戶可以繼續正常使用服務。[進一步了解」](https://aws.amazon.com/blogs/machine-learning/transition-your-amazon-forecast-usage-to-amazon-sagemaker-canvas/)
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
# DeepAR\+ 演算法
Amazon Forecast DeepAR\+ 是一種監督式學習演算法,利用遞歸神經網路 (RNNs) 來預測純量 (單一維度) 時間序列。古典的預測方法,例如整合移動平均自回歸模型 (ARIMA) 或指數平滑法 (ETS),針對每個個別的時間序列採用單一模型,然後使用該模型來推算未來的時間序列。但是在許多應用程式中,您在一組橫截面單位會有許多類似的時間序列。這些時間序列分組需要不同的產品、伺服器負載和網頁請求。在這種情況下,針對所有時間序列,來聯合訓練單一模型,可以帶來效益。DeepAR\+ 採用此方法。當您的資料集包含數百個特徵時間序列,DeepAR\+ 演算法優於標準 ARIMA 和 ETS 方法。您也可以使用訓練模型來對類似其已訓練過的新時間序列產生預測。
**Python 筆記本**
如需使用 DeepAR\+ step-by-step指南,請參閱 [ DeepAR\+ 入門](https://github.com/aws-samples/amazon-forecast-samples/blob/master/notebooks/advanced/Getting_started_with_DeepAR%2B/Getting_started_with_DeepAR%2B.ipynb)。
**Topics**
+ [DeepAR\+ 運作方式](#aws-forecast-recipe-deeparplus-how-it-works)
+ [DeepAR\+ 超參數](#aws-forecast-recipe-deeparplus-hyperparameters)
+ [調校 DeepAR\+ 模型](#aws-forecast-recipe-deeparplus-tune-model)
## DeepAR\+ 運作方式
在訓練期間,DeepAR\+ 使用訓練資料集和選用的測試資料集。它使用測試資料集來評估訓練模型。一般而言,訓練和測試資料集不必包含相同的時間序列。您可以使用對指定訓練集進行訓練的模型,對訓練集中時間序列的未來以及其他時間序列產生預測。訓練和測試資料集都包含 (最好不只一個) 目標時間序列。或者,它們可以與特徵時間序列的向量和分類特徵的向量相關聯 (如需詳細資訊,請參閱 *SageMaker AI 開發人員指南*中的 [DeepAR 輸入/輸出界面](https://docs.aws.amazon.com/sagemaker/latest/dg/deepar.html#deepar-inputoutput))。以下範例顯示其對於依據 `i` 編製索引之訓練資料集元素的運作方式。訓練資料集包含目標時間序列 `zi,t`,以及兩個關聯特徵時間序列 `xi,1,t` 和 `xi,2,t`。
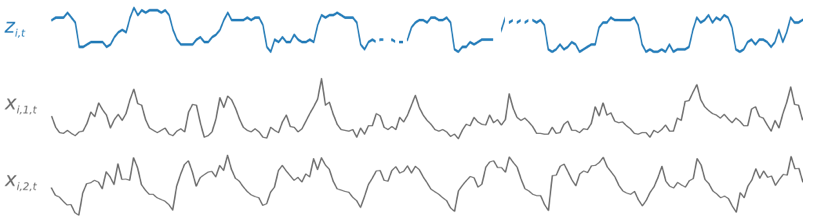
目標時間序列可能包含遺漏值 (在圖中以時間序列的中斷點表示)。DeepAR\+ 僅支援未來已知的特徵時間序列。這可讓您執行反事實的「what-if」案例。例如,「如果我以某種方式變更產品的價格,會發生什麼事?」
每個目標時間序列也可以與多個分類特徵建立關聯。您可以使用這些來編碼時間序列屬於特定群組。使用類別特徵可讓模型了解這些分組的典型行為,以提高準確性。模型透過學習每個群組的內嵌向量 (用於擷取群組中所有時間序列的共通屬性) 來實作這件事。
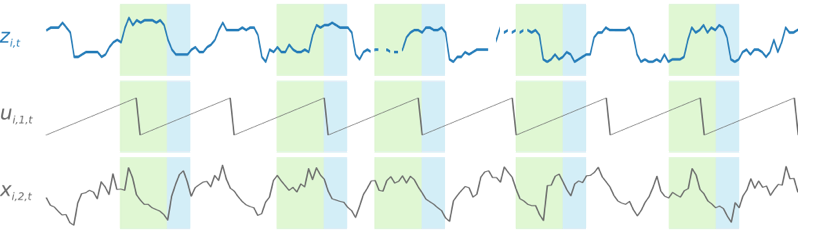
為了促進學習時間相依模式,例如週末的尖峰值,DeepAR\+ 會根據時間序列精細程度自動建立特徵時間序列。例如,DeepAR\+ 會以每週時間序列的頻率,建立兩個特徵時間序列 (一個月的某一天和一年的某一天)。它會使用這些衍生特徵時間序列搭配您在訓練和推論期間提供的自訂特徵時間序列。以下範例顯示兩個衍生時間序列特徵:`ui,1,t` 代表一天中小時,而 `ui,2,t` 代表星期幾。

DeepAR\+ 會根據資料頻率和訓練資料的大小,自動包含這些特徵時間序列。下表列出可針對每個支援的基本時間頻率衍生的特徵。
****
| 時間序列的頻率 | 衍生特徵 |
| --- | --- |
| 分鐘 | 小時中的分鐘、一天的幾時、星期幾、月中的日、年中的日 |
| 小時 | 一天的幾時、星期幾、月中的日、年中的日 |
| 天 | 星期幾、月中的日、年中的日 |
| 週 | week-of-month、week-of-year |
| 月 | 年中的月 |
DeepAR\+ 模型透過從訓練資料集的每個時間序列隨機取樣數個訓練範例來接受訓練。每個訓練範例都包括一對相鄰內容和具有固定預先定義長度的預測視窗。`context_length` 超參數控制網路可以看到多遠的過去,而 `ForecastHorizon` 參數控制可對多遠的未來進行預測。在訓練期間,Amazon Forecast 會忽略訓練資料集內時間序列短於指定預測長度的元素。以下範例顯示從元素 `i` 提取的五個範例,其文本內容長度 (以綠色醒目顯示) 為 12 小時、預測長度 (以藍色醒目顯示) 為 6 小時。為求簡潔,我們排除了特徵時間序列 `xi,1,t` 和 `ui,2,t`。
為了擷取季節性模式,DeepAR\+ 也會從目標時間序列自動傳送延遲 (過去期間) 值。在我們每小時取樣一次的範例中,對於每個時間索引 `t = T`,模型會公開 `zi,t` 值 (發生在過去大約一天、兩天和三天,以粉紅色醒目顯示)。
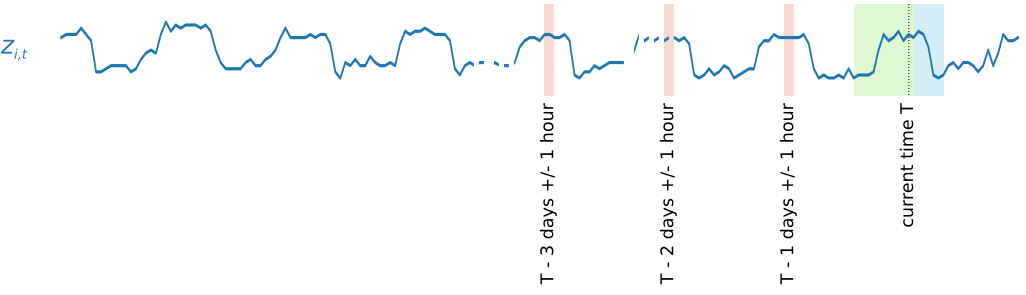
進行推論時,訓練過的模型會接受目標時間序列做為輸入 (這些時間序列在訓練時不一定使用過),並預測下一個 `ForecastHorizon` 值的概率分佈。由於 DeepAR\+ 是以整個資料集進行訓練,因此預測會將來自類似時間序列的學會模式列入考慮。
如需 DeepAR\+ 背後數學的相關資訊,請參閱康乃爾大學圖書館網站上的 [DeepAR:利用遞歸神經網路來進行機率預測](https://arxiv.org/abs/1704.04110)。
## DeepAR\+ 超參數
下表列出您可用於 DeepAR\+ 演算法中的超參數。粗體參數會參與超參數最佳化 (HPO)。
| 參數名稱 | Description |
| --- | --- |
| context\_length | 模型在進行預測之前所讀取時間點的數量。此參數的值應和 `ForecastHorizon` 大致相同。模型也會從目標接收到延遲的輸入,因此 `context_length` 可能會比典型的季節週期小上許多。例如,每日時間序列可以有每年季節性。模型會自動包含一年的延遲年,因此內容的長度可能會比一年短。模型所選擇的延遲值,取決於時間序列的頻率。例如,每日頻率的延遲值為:前一週、2 週、3 週、4 週和一年。[See the AWS documentation website for more details](http://docs.aws.amazon.com/zh_tw/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| epochs | 針對培訓資料的最高傳遞次數。最佳值取決於您的資料大小和學習速率。較小的資料集和較低的學習率都需要更多 epoch,才能獲得良好的結果。[See the AWS documentation website for more details](http://docs.aws.amazon.com/zh_tw/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| learning\_rate | 在訓練中所使用的學習率。[See the AWS documentation website for more details](http://docs.aws.amazon.com/zh_tw/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| learning\_rate\_decay | 學習率下降的速率。學習率最多可降低 `max_learning_rate_decays` 次,接著訓練停止。只有在 `max_learning_rate_decays` 大於 0 時,才會使用此參數。[See the AWS documentation website for more details](http://docs.aws.amazon.com/zh_tw/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| likelihood | 此模型會產生機率預測,並可提供分佈的分位數並傳回樣本。根據您的資料,選擇適合用來估計不確定性的可能性 (雜訊模型)。
有效值[See the AWS documentation website for more details](http://docs.aws.amazon.com/zh_tw/forecast/latest/dg/aws-forecast-recipe-deeparplus.html)[See the AWS documentation website for more details](http://docs.aws.amazon.com/zh_tw/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| max\_learning\_rate\_decays | 應發生的學習率降低數上限。[See the AWS documentation website for more details](http://docs.aws.amazon.com/zh_tw/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| num\_averaged\_models | 在 DeepAR\+ 中,訓練軌跡可以遇到多個模型。每個模型可能會有不同的預測優點和缺點。DeepAR\+ 可以平均模型行為,以利用所有模型的優點。[See the AWS documentation website for more details](http://docs.aws.amazon.com/zh_tw/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| num\_cells | 要在 RNN 的每個隱藏層中使用的單元數。[See the AWS documentation website for more details](http://docs.aws.amazon.com/zh_tw/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| num\_layers | RNN 中隱藏層的數量。[See the AWS documentation website for more details](http://docs.aws.amazon.com/zh_tw/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
## 調校 DeepAR\+ 模型
若要調校 Amazon Forecast DeepAR\+ 模型,請依照下列建議以最佳化訓練程序和硬體組態。
### 程序最佳化的最佳實務
為了獲得最佳結果,請遵循以下建議:
+ 除了分割訓練和測試資料集以外,一律提供整個時間序列用於訓練和測試,以及呼叫模型以進行推論時。無論您如何設定 `context_length`,都不要分割時間序列或只提供一部分。對於延遲值特徵,模型將使用比 `context_length` 更往前的資料點。
+ 對於模型調校,您可以將資料集分割成訓練和測試資料集。在典型評估案例中,您應該在用於訓練的相同時間序列上測試模型,但是使用訓練期間可見的最後一個時間點之後的未來 `ForecastHorizon` 時間點。若要建立滿足這些條件的訓練和測試資料集,請使用整個資料集 (所有時間序列) 做為測試資料集,並從每個時間序列移除最後的 `ForecastHorizon` 點以用於訓練。這樣,在訓練期間,模型就看不到測試期間它所評估時間點的目標值。在測試階段,會保留測試資料集中每個時間序列最後的 `ForecastHorizon` 點,並產生預測。接著,會將預測值與最後 `ForecastHorizon` 點的實際值進行比較。您可以多次重複測試資料集內的時間序列,但在不同的終點切斷它們,藉以建立更複雜的評估。這會產生從不同時間點的多個預測進行平均的準確性指標。
+ 避免對 `ForecastHorizon` 使用非常大的值 (> 400),因為這樣會使模型變慢而且較不準確。如果您想要進一步預測未來,請考慮彙總到更高的頻率。例如,使用 `5min` 代替 `1min`。
+ 由於延遲,模型可以比 `context_length` 看得更往前一點。因此,您不必將此參數設為大的值。此參數的良好起點是 `ForecastHorizon` 的相同值。
+ 使用盡可能多的時間序列來訓練 DeepAR\+ 模型。雖然在單一時間序列上訓練的 DeepAR\+ 模型可能已能良好運作,但標準預測方法 (例如 ARIMA 或 ETS) 可能更準確也更適合用於此使用案例。當您的資料集包含數百個特徵時間序列時,DeepAR\+ 會開始優於標準方法。目前,DeepAR\+ 要求所有訓練時間序列中可用的觀測總數至少為 300。