本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
# 使用全域次要索引以支援 DynamoDB 中的具體化聚合查詢
快速變更的資料中維護接近即時彙總和索引鍵指標,對於企業來說變得越來越重要。例如,音樂庫可能想要近乎即時地展示其下載次數最多的歌曲,或者電子商務平台可能需要按類別顯示趨勢產品。
由於 DynamoDB 本身不支援諸如項目`SUM`或`COUNT`跨項目的彙總操作,因此在讀取時間運算這些值將需要掃描大量項目,這可能會很緩慢且昂貴。相反地,您可以在資料變更時*預先計算*彙總,並將結果儲存為資料表中的一般項目。此模式稱為*具體化彙總*。
**Topics**
+ [範例案例和存取模式](#bp-gsi-aggregation-scenario)
+ [為什麼要預先運算彙總](#bp-gsi-aggregation-why)
+ [資料表設計](#bp-gsi-aggregation-table-design)
+ [使用 Streams 和 彙總管道 AWS Lambda](#bp-gsi-aggregation-pipeline)
+ [稀疏 GSI 設計](#bp-gsi-aggregation-sparse-gsi)
+ [查詢 GSI](#bp-gsi-aggregation-querying)
+ [考量事項](#bp-gsi-aggregation-considerations)
## 範例案例和存取模式
考慮具有下列要求的音樂程式庫應用程式:
+ 應用程式會以大量 (每秒數千首) 記錄個別歌曲下載。
+ 使用者需要查看特定月份中下載最多的單位數毫秒延遲歌曲。
+ 應用程式也需要支援查詢,例如「本月前 10 首歌曲」和「特定月份下載的所有歌曲」。
掃描所有下載記錄的讀取時間運算下載計數在此規模下可能很昂貴。反之,您可以維護每次下載時更新的執行中計數,並以支援有效率查詢的方式存放。
## 為什麼要預先運算彙總
有數種運算彙總的方法。下表比較常見的替代方案,並說明為什麼 DynamoDB 中的具體化彙總通常最適合這種類型的使用案例。
| 方法 | 取捨 | 使用情況 |
| --- | --- | --- |
| 讀取時掃描和計數 | 需要讀取每個查詢的所有下載記錄。延遲會隨著資料量增加,並消耗大量的讀取容量。 | 僅適用於不考慮延遲的極小型資料集。 |
| 外部彙總存放區 (例如,Amazon ElastiCache) | 使用要管理的個別服務新增操作複雜性。DynamoDB 和快取之間需要同步邏輯。 | 當您需要低於一毫秒的讀取或超過簡單計數的複雜彙總邏輯時。 |
| 寫入時的應用程式層級彙總 | 將彙總邏輯耦合至寫入路徑。如果應用程式在記錄下載之後但在更新計數之前失敗,則彙總會變得不一致。 | 當您需要同步、高度一致的彙總時, 可以容忍增加的寫入延遲。 |
| 使用 Streams 和 Lambda 進行具體化彙總 | 將彙總與寫入路徑分離。彙總最終一致 (通常落後 秒)。新增 Lambda 調用成本。 | 當您需要近乎即時的低讀取延遲彙總,並且可以容忍最終一致性時。這是此頁面所述的方法。 |
具體化彙總方法可讓寫入路徑簡單 (只要記錄下載)、將彙總卸載至非同步程序,並將結果存放在 DynamoDB,可在 DynamoDB 中查詢單一位數毫秒延遲。
## 資料表設計
此設計使用具有兩個項目類型的單一資料表,它們共用相同的分割區索引鍵 (`songID`),但使用不同的排序索引鍵模式來區分它們:
+ **下載記錄** – 個別下載事件。排序索引鍵是 `DownloadID`(每次下載的唯一識別符)。
+ **每月彙總項目** – 每月每首歌曲的預先計算下載計數。排序索引鍵是`YYYY-MM`格式的月份 (例如 `2018-01`)。這些項目也包含執行中總數的`DownloadCount`屬性。
只有每月彙總項目包含 `Month` 屬性。此區別對於稍後描述的稀疏 GSI 設計很重要。
下圖顯示兩種項目類型的資料表配置:
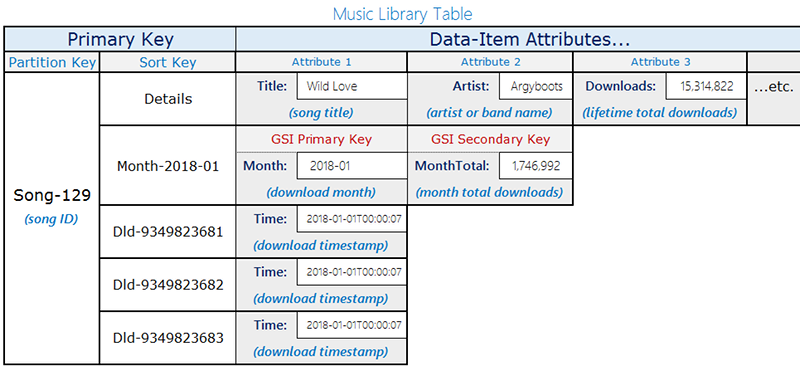
| 項目類型 | 分割區索引鍵 (songID) | 排序索引鍵 | 其他屬性 |
| --- | --- | --- | --- |
| 下載記錄 | song1 | download-abc123 | UserID, Timestamp |
| 每月彙總 | song1 | 2018-01 | Month=2018-01, DownloadCount=1,746,992 |
## 使用 Streams 和 彙總管道 AWS Lambda
彙總管道的運作方式如下:
1. 下載歌曲時,應用程式會使用 `Partition-Key=songID`和 將新項目寫入資料表`Sort-Key=DownloadID`。
1. DynamoDB Streams 會將此寫入擷取為串流記錄。
1. 連接至串流的 Lambda 函數會處理新記錄。它會識別 `songID`和目前月份,然後透過遞增 `DownloadCount` 屬性來更新對應的每月彙總項目。
1. 然後,更新的彙總項目可用於透過稀疏 GSI 進行查詢。
Lambda 函數使用具有 `ADD`表達式的 `UpdateItem`呼叫,以原子方式增加下載計數。這可避免read-modify-write競爭條件:
```
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('MusicLibrary')
def handler(event, context):
for record in event['Records']:
if record['eventName'] == 'INSERT':
new_image = record['dynamodb']['NewImage']
song_id = new_image['songID']['S']
# Derive the month from the download timestamp
timestamp = new_image['Timestamp']['S']
month = timestamp[:7] # Extract YYYY-MM
table.update_item(
Key={
'songID': song_id,
'SK': month
},
UpdateExpression='ADD DownloadCount :inc SET #m = :month',
ExpressionAttributeNames={
'#m': 'Month'
},
ExpressionAttributeValues={
':inc': 1,
':month': month
}
)
```
**注意**
如果 Lambda 執行在寫入更新的彙總值後失敗,可能會重試串流記錄。由於`ADD`操作會在每次執行時遞增計數,因此針對相同的下載,重試會多次遞增計數,讓您擁有*近似*值。對於大多數分析和排行榜使用案例,這個小範圍的錯誤是可接受的。如果您需要確切的計數,請考慮新增冪等性邏輯,例如,使用檢查特定 是否已`DownloadID`處理的條件表達式。
## 稀疏 GSI 設計
若要有效率地查詢彙總結果,請使用下列索引鍵結構描述建立全域次要索引:
+ **GSI 分割區索引鍵:**`Month`(字串)
+ **GSI 排序索引鍵:**`DownloadCount`(數字)
此 GSI 是*稀疏的*,因為只有每月彙總項目包含 `Month` 屬性。個別下載記錄沒有此屬性,因此它們會自動從索引中排除。這表示 GSI 僅包含預先計算的彙總項目,這是資料表中項目總數的一小部分。
稀疏 GSI 提供兩個主要優點:
+ **成本較低** – 由於只有彙總項目會複寫至索引,相較於包含資料表中每個項目的索引,您所使用的寫入容量和儲存體會大幅降低。
+ **更快速的查詢** – 索引僅包含您需要查詢的資料,因此讀取效率高,並傳回具有單一位數毫秒延遲的結果。
如需稀疏索引如何運作的詳細資訊,請參閱 [利用疏鬆索引](bp-indexes-general-sparse-indexes.md)。
## 查詢 GSI
設置稀疏 GSI 後,您可以有效地回答多種類型的查詢:
**取得特定月份下載次數最多的歌曲:**
```
aws dynamodb query \
--table-name "MusicLibrary" \
--index-name "MonthDownloadsIndex" \
--key-condition-expression "#m = :month" \
--expression-attribute-names '{"#m": "Month"}' \
--expression-attribute-values '{":month": {"S": "2018-01"}}' \
--scan-index-forward false \
--limit 1
```
設定 `ScanIndexForward` 依`DownloadCount`遞減順序`false`排序結果,並僅`Limit=1`傳回最熱門的歌曲。
**取得指定月份的前 10 首歌曲:**
```
aws dynamodb query \
--table-name "MusicLibrary" \
--index-name "MonthDownloadsIndex" \
--key-condition-expression "#m = :month" \
--expression-attribute-names '{"#m": "Month"}' \
--expression-attribute-values '{":month": {"S": "2018-01"}}' \
--scan-index-forward false \
--limit 10
```
**取得指定月份下載的所有歌曲 **(依下載計數排序):
```
aws dynamodb query \
--table-name "MusicLibrary" \
--index-name "MonthDownloadsIndex" \
--key-condition-expression "#m = :month" \
--expression-attribute-names '{"#m": "Month"}' \
--expression-attribute-values '{":month": {"S": "2018-01"}}' \
--scan-index-forward false
```
## 考量事項
實作此模式時,請記住下列事項:
+ **最終一致性** – 彙總值會透過 DynamoDB Streams 和 Lambda 以非同步方式更新。要記錄的下載與要更新的彙總之間,通常會有幾秒鐘的延遲。這表示 GSI 反映近乎即時的資料,而不是即時資料。
+ **Lambda 並行** – 如果您的資料表具有高寫入量,則多個 Lambda 調用可能會嘗試同時更新相同的彙總項目。原子`ADD`操作可安全地處理此情況,但您應該監控 Lambda 並行和限流指標,以確保您的函數可以跟上串流。
+ **GSI 寫入容量** – 由於稀疏 GSI 僅包含彙總項目,因此需要的寫入容量遠低於基礎資料表。不過,您仍應佈建足夠的容量 (或使用隨需模式) 來處理彙總更新的速率。
+ **約略計數** – 如前所述,Lambda 重試可能會導致計數稍微過度計數。對於需要確切計數的使用案例,請在 Lambda 函數中實作冪等性檢查。