本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 CloudWatch 異常偵測
當您針對指標啟用異常偵測時,CloudWatch 會套用統計和機器學習演算法。這些演算法會在使用者介入程度最低的情況下,持續分析系統和應用程式的指標、判斷正常基準以及表面異常情況。
演算法會產生異常偵測模型。模型會產生預期值範圍,代表正常指標行為。
您可以使用 AWS 管理主控台 AWS CLI CloudFormation、 或 AWS SDK 啟用異常偵測。您可以在 提供的指標上啟用異常偵測 AWS ,也可以在自訂指標上啟用異常偵測。在設定為 CloudWatch 跨帳戶可觀測性監控帳戶的帳戶中,除了監控帳戶中的指標之外,您還可以針對來源帳戶中的指標,建立極端值偵測器。
您可以透過兩種方式來使用預期值的模型:
建立以指標預期值為基礎的異常偵測警示。這些類型的警示沒有用於判斷警示狀態的靜態臨界值。相反地,它們會根據異常偵測模型,將指標值與預期值進行比較。
您可以選擇警示觸發時機是在指標值超過預期值範圍、低於範圍,或者兩者同時發生時。
如需詳細資訊,請參閱根據異常偵測建立 CloudWatch 警示。
檢視指標資料圖表時,將預期值以區帶形式覆蓋到圖表上。這樣可以清楚地看出圖表中哪些值超出正常範圍。如需詳細資訊,請參閱建立圖形。
您也可以使用含
ANOMALY_DETECTION_BAND指標數學函數的GetMetricDataAPI 請求來擷取模型範圍的上下限值。如需詳細資訊,請參閱 GetMetricData。
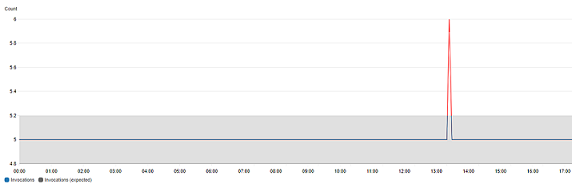
在具有異常偵測的圖表中,預期值的範圍顯示為灰色區帶。如果指標的實際值超出此區帶,則在該時間內會顯示為紅色。
異常偵測演算法會考慮指標的季節性和趨勢變化。季節性變化可能是每小時、每日或每週,如下列範例所示。
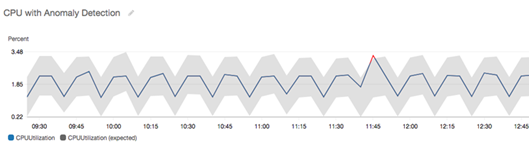
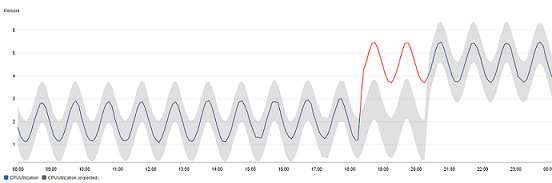
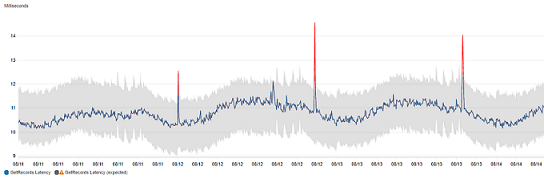
較長範圍的趨勢可能是向下或向上。
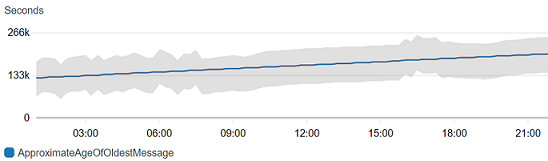
異常偵測也適用於具有扁平模式的指標。
CloudWatch 異常偵測的運作方式
當您啟用指標的異常偵測,CloudWatch 會將機器學習演算法套用到指標過去資料來建立指標預期值的模型。模型會評估指標的趨勢以及每小時、每日和每週模式。演算法可以最多兩週的指標資料為目標,但即使指標沒有完整兩週的資料,您仍可以對指標啟用異常偵測。
您可以指定異常偵測臨界值,CloudWatch 會搭配模型一起使用該臨界值,以決定指標的「正常」值範圍。較高的異常偵測臨界值會產生較厚的「正常」值範圍。
機器學習模型是指標和統計資料所特有的。例如,如果您使用 AVG 統計資料來啟用指標的異常偵測,此模型就是 AVG 統計資料所特有的。
當 CloudWatch 為來自 AWS 服務的許多常用指標建立模型時,可確保頻帶不會超出邏輯值。例如,EC2 執行個體的 MemoryUtilization 頻段將維持在 0 至 100 之間,而追蹤 CloudFront Requests 的頻段 (該區間值不可為負數) 永遠不會低於零。
建立模型後,CloudWatch 異常偵測會持續評估模型並對模型進行調整,從而確保模型盡可能精確。這包括重新訓練模型,以在指標隨時間變化或突然變更時對其進行調整,並包含預測器,可改善季節性、尖峰或稀疏的指標模型。
對指標啟用異常偵測後,您可以選擇排除指標的指定時段,避免這些時段被用於模型的訓練。如此一來,您就可以排除部署或其他不尋常事件,避免這些事件被用於模型的訓練,確保建立的模型是最準確的。
對警示使用異常偵測模型會在 AWS 您的帳戶產生費用。如需詳細資訊,請參閱 Amazon CloudWatch 定價
指標數學上的異常偵測
指標數學上的異常偵測是一項功能,您可使用此功能根據輸出指標數學表達式建立異常偵測警示。您可以使用這些表達式來建立可視化異常偵測頻段的圖形。此功能支援基本算術函數、比較和邏輯運算子,以及大多數其他函數。如需不受支援之函數的相關資訊,請參閱《Amazon CloudWatch 使用者指南》中的使用指標數學。
您可以根據指標數學表達式建立異常偵測模型,類似於建立異常偵測模型的方式。從 CloudWatch 主控台,您可以將異常偵測套用至指標數學表達式,並選取異常偵測作為這些表達式的閾值類型。
注意
只能在最新版的指標使用者介面中啟用和編輯指標數學的異常偵測。在新版介面中根據指標數學表達式建立異常偵測器時,您可以在舊版中進行檢視,但無法編輯。
如需如何建立、編輯和刪除異常偵測和指標數學的警示和模型的相關資訊,請參閱下列各節:
您也可以使用具有 PutAnomalyDetector、DeleteAnomalyDetector 和 DescribeAnomalyDetectors 的 CloudWatch API,建立、刪除和探索基於指標數學表達式的異常偵測模型。如需這些 API 動作的相關資訊,請參閱 Amazon CloudWatch API 參考中的下列章節。
如需異常偵測警示計價方式的相關資訊,請參閱 Amazon CloudWatch 定價
使用 PromQL 進行異常偵測
您可以使用 quantile_over_time、 stddev_over_time和 等標準 PromQL 函數,為任何 Prometheus 相容指標建置異常偵測頻帶avg_over_time。此方法會計算基準,並新增或減去縮放的標準差,以定義符合您指標自然模式的上下邊界。
這適用於傳回浮點數的任何指標,例如 CPU 用量、請求延遲或錯誤計數。如需使用 OpenTelemetry 擷取指標的資訊,請參閱 OpenTelemetry。
定義上限和下限
若要定義指標的預期範圍,請使用時間範圍內的中位數或平均值來計算基準,然後新增和減去標準差的倍數。乘數控制敏感度 - 較高的值會產生更寬的頻帶,並減少誤報,而較低的值則捕捉較小的偏差。
下列範例使用 60 分鐘的時段和 3 的乘數,建立廣告請求指標的上限:
quantile_over_time(0.5, {"app.ads.ad_requests"}[60m] offset 1m) + 3 * stddev_over_time({"app.ads.ad_requests"}[60m] offset 1m)
下列範例會建立對應的下限。對於不能有負值的指標, clamp_min函數可防止下限變成負值:
clamp_min( quantile_over_time(0.5, {"app.ads.ad_requests"}[60m] offset 1m) - 3 * stddev_over_time({"app.ads.ad_requests"}[60m] offset 1m), 0)
您可以在 CloudWatch Query Studio 中將這兩個邊界繪製在一起,以視覺化指標的預期範圍。如需詳細資訊,請參閱在 Query Studio 中執行 PromQL 查詢。
偵測違規
若要偵測指標何時超出其預期範圍,請將兩個邊界合併為單一查詢。下列表達式只會傳回指標值超過上限或低於下限的資料點:
1 * {"app.ads.ad_requests"} > quantile_over_time(0.5, {"app.ads.ad_requests"}[60m] offset 1m) + 3 * stddev_over_time({"app.ads.ad_requests"}[60m] offset 1m) or 1 * {"app.ads.ad_requests"} < clamp_min( quantile_over_time(0.5, {"app.ads.ad_requests"}[60m] offset 1m) - 3 * stddev_over_time({"app.ads.ad_requests"}[60m] offset 1m), 0)
此查詢適用於多個標籤值,因此您可以在單一查詢中偵測整個機群的異常。您可以使用此表達式來建立 PromQL 警示,該警示會在任何時間序列超出預期範圍時觸發。如需詳細資訊,請參閱使用 PromQL 建立 CloudWatch 警示進行異常偵測。
