本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
研究计算的云爆发
美国一所 R1 级(博士类大学:研究活动非常高)研究机构的研究计算团队多年来一直使用 Slurm 调度器运行本地高性能计算(HPC)集群。除了几周的计划维护外,集群的利用率为 80-95%,且大部分队列均为满载。
该机构的研究活动不断增长,这给容量和能力都带来了挑战。一些备受瞩目的研究人员总是在某些队列中执行长时间模拟,这增加了其他用户的等待时间。新聘用的教师需要进行大量的天气模拟,以构建一种新颖的人工智能和机器学习(AI/ML)模型进行天气预报,但其所需容量超出了可用容量。研究计算小组还收到了更多关于提供用于训练机器学习模型的最新图形处理单元 (GPUs) 的请求。即使有了购买新机架的资金 GPUs,该团队也需要等待几个月才能获得扩大数据中心机架空间的批准。
许多研究人员不愿删除旧数据,因此本地存储容量也面临挑战。我们需要一种更具可扩展性的长期存储方案,以腾出宝贵的本地高性能存储。
云通过混合计算和存储解决方案来应对这些挑战,当本地容量不足时,您可以将研究计算爆发到云。以下架构图展示使用 AWS ParallelCluster
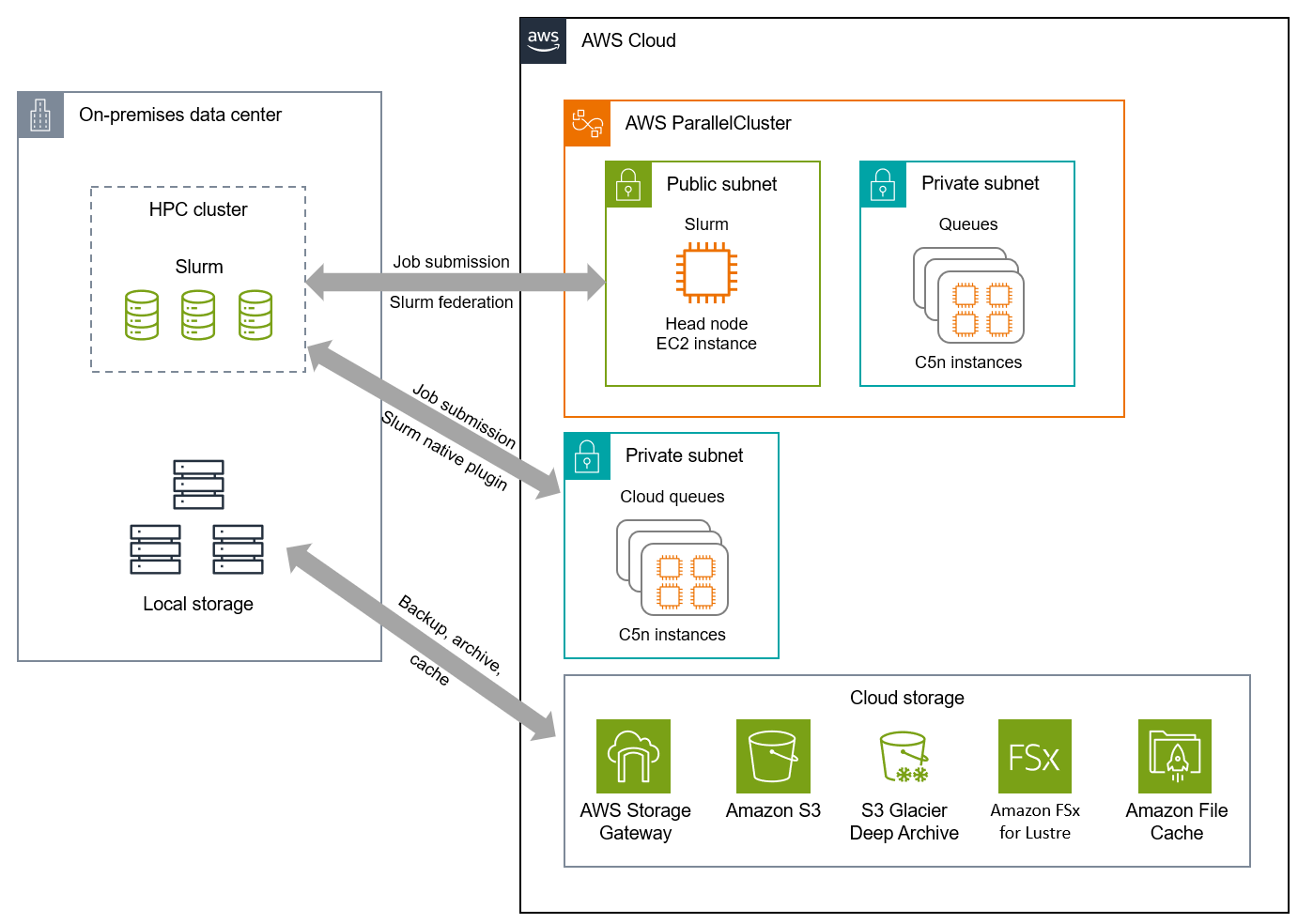
此架构遵循以下建议:
-
选择主要战略云提供商。此架构使用一个主要云提供商,以避免受到最小共同点方法的限制。这样,该机构就可以利用主要云提供商提供的创新以及原生计算和存储服务。研究计算团队可以专注于优化主要云提供商所提供环境中的工作负载,而不是如何在不同的云环境中工作。
-
为每个云服务提供商制定安全和治理要求。此架构中使用的每种服务和工具均可进行配置,以满足研究计算团队的安全和治理要求,包括私有连接、传输中和静态数据加密、活动日志记录等。
-
在切实可行的情况下,尽可能采用云原生托管服务。此架构能够使用托管存储和计算服务以及工具来简化集群管理。这样,研究计算团队无需自行管理集群或底层基础设施,这些工作往往复杂且耗时。
-
在现有本地投资激励继续使用时,实施混合架构。此架构使机构能够继续使用其本地资源,并利用云来增加容量和按需扩展计算能力。借助云,机构可以调整计算类型的适合大小,以实现最大性价比;并使用最新技术来促进创新,而无需对额外的本地硬件进行大量前期投资。
