本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
通过网络断开连接实现的 Kubernetes 容器故障转移
我们首先回顾一下在节点与 Kubernetes 控制平面之间网络断开连接期间影响 Kubernetes 行为的关键概念、组件和设置。EKS 符合上游 Kubernetes 标准,因此此处描述的所有 Kubernetes 概念、组件和设置都适用于 EKS 和 EKS 混合节点部署。
对 EKS 进行了一些改进,专门用于改善网络断开连接期间的 pod 故障转移行为,有关更多信息,请参阅上游 Kubernetes 存储库中的 GitHub 问题 #131294
概念
污点和容忍度:Kubernetes 中使用污点和容忍度来控制 Pod 在节点上的调度。节点生命周期控制器设置污点,表示节点不符合调度条件,或者应该驱逐这些节点上的 Pod。当由于网络断开连接而无法访问节点时,节点生命周期控制器会应用 node.kubernetes。 io/unreachable 带有 NoSchedule 效果的污点,如果满足某些条件,则会 NoExecute 产生效果。node.kubernetes。 io/unreachable 污点对应于 NodeCondition Ready being Unknown。用户可以在中指定应用程序级别对污点的容忍度。 PodSpec
-
NoSchedule: 除非有匹配的容忍度,否则不会在受污染的节点上调度新 Pod。已在节点上运行的 Pod 不会被驱逐出去。
-
NoExecute: 不容忍污点的 Pod 会立即被驱逐。容忍污点(未指定 TolerationSeconds)的 Pod 将永远保持绑定。容忍具有指定 TolerationSeconds 污点的 Pod 将在指定的时间内保持绑定。在这段时间过后,节点生命周期控制器会将 Pod 逐出节点。
节点租约:Kubernetes 使用 Lease API 将 kubelet 节点心跳传送到 Kubernetes API 服务器。对于每个节点,都有一个名称匹配的 Lease 对象。在内部,每个 kubelet 心跳都会更新 Lease 对象的 spec.renewTime 字段。Kubernetes 控制平面使用该字段的时间戳来确定节点的可用性。如果节点与 Kubernetes 控制平面断开连接,则它们无法为其租约更新 spec.renewTime,控制平面会将其解释为 Ready being Unknown。 NodeCondition
组件
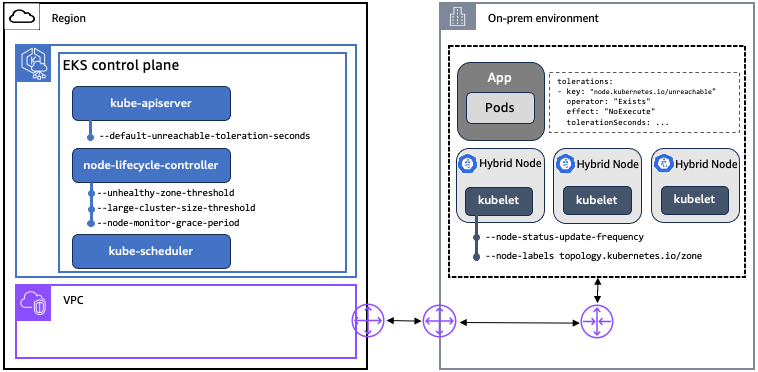
| 组件 | Sub-component | 说明 |
|---|---|---|
|
Kubernetes 控制平面 |
kube-api 服务器 |
API 服务器是 Kubernetes 控制平面的核心组件,用于公开 Kubernetes API。 |
|
Kubernetes 控制平面 |
节点生命周期控制器 |
kube控制器管理器运行的控制器之一。它负责检测和响应节点问题。 |
|
Kubernetes 控制平面 |
kube-scheduler |
一个控制平面组件,用于监视未分配节点的新创建的 Pod,并选择一个节点让它们运行。 |
|
Kubernetes 节点 |
kubelet |
在群集中的每个节点上运行的代理。kubelet 会监视 PodSpecs 并确保其中描述的容 PodSpecs 器运行良好。 |
配置设置
| 组件 | 设置 | 说明 | K8s 默认 | EKS 默认 | 可在 EKS 中配置 |
|---|---|---|---|---|---|
|
kube-api 服务器 |
默认无法达到的容差秒数 |
表示 |
300 |
300 |
否 |
|
节点生命周期控制器 |
节点监视器宽限期 |
节点在被标记为不健康之前可能没有响应的时间。必须是 kubelet 的 N 倍 |
40 |
40 |
否 |
|
节点生命周期控制器 |
大型集群大小阈值 |
节点生命周期控制器在驱逐逻辑中将集群视为大型集群的节点数量。 |
50 |
100000 |
否 |
|
节点生命周期控制器 |
不健康区域阈值 |
区域中必须处于 “未就绪” 状态才能将该区域视为不健康的节点的百分比。 |
55% |
55% |
否 |
|
kubelet |
节点状态更新频率 |
kubelet 向控制平面发布节点状态的频率。必须与节点生命周期控制 |
10 |
10 |
是 |
|
kubelet |
节点标签 |
在集群中注册节点时要添加的标签。 |
无 |
无 |
是 |
通过网络断开连接实现的 Kubernetes 容器故障转移
此处描述的行为假设 Pod 以默认设置的 Kubernetes 部署形式运行,并且 EKS 被用作 Kubernetes 提供者。根据您的环境、网络断开连接的类型、应用程序、依赖关系和群集配置,实际行为可能会有所不同。本指南中的内容已使用特定的应用程序、集群配置和插件子集进行了验证。强烈建议在进入生产环境之前,在自己的环境和自己的应用程序中测试行为。
当节点和 Kubernetes 控制平面之间出现网络断开连接时,每个断开连接的节点上的 kubelet 将无法与 Kubernetes 控制平面通信。因此,在恢复连接之前,kubelet 无法驱逐这些节点上的 pod。这意味着,假设没有其他故障导致它们关闭,则在网络断开连接之前在这些节点上运行的 Pod 将在断开连接期间继续运行。总而言之,在节点与 Kubernetes 控制平面之间的网络断开连接期间,你可以实现静态稳定性,但是在恢复连接之前,你无法对节点或工作负载执行变更操作。
根据网络断开的性质,有五种主要场景会产生不同的 pod 故障转移行为。在所有情况下,一旦节点重新连接到 Kubernetes 控制平面,集群就会恢复健康,无需操作员干预。以下场景概述了基于我们的观察结果的预期结果,但这些结果可能不适用于所有可能的应用程序和集群配置。
场景 1:集群完全中断
预期结果:无法访问的节点上的 Pod 不会被驱逐并继续在这些节点上运行。
集群完全中断意味着集群中的所有节点都与 Kubernetes 控制平面断开连接。在这种情况下,控制平面上的节点生命周期控制器检测到集群中的所有节点都无法访问并取消任何 pod 驱逐。
在断开连接Not Ready期间,集群管理员将看到所有带有状态的节点。Pod 状态不会改变,在断开连接和后续重新连接期间,也不会在任何节点上调度新的 Pod。
场景 2:整个区域中断
预期结果:无法访问的节点上的 Pod 不会被驱逐并继续在这些节点上运行。
整个区域中断意味着该区域中的所有节点都与 Kubernetes 控制平面断开连接。在这种情况下,控制平面上的节点生命周期控制器检测到该区域中的所有节点都无法访问并取消任何 pod 驱逐。
在断开连接Not Ready期间,集群管理员将看到所有带有状态的节点。Pod 状态不会改变,在断开连接和后续重新连接期间,也不会在任何节点上调度新的 Pod。
场景 3:多数区域中断
预期结果:无法访问的节点上的 Pod 不会被驱逐并继续在这些节点上运行。
多数区域中断意味着给定区域中的大多数节点都与 Kubernetes 控制平面断开连接。Kubernetes 中的区域由具有相同标签的节点定义。topology.kubernetes.io/zone如果集群中未定义任何区域,则大多数中断意味着整个集群中的大多数节点都已断开连接。默认情况下,多数由节点生命周期控制器定义,在 Kubernetes 和 EK unhealthy-zone-threshold S 中均设置为 55%。由于在 EKS 中设置large-cluster-size-threshold为 100,000,因此如果一个区域中有 55% 或更多的节点无法访问,Pod 驱逐将被取消(假设大多数集群远小于 100,000 个节点)。
在断开连接Not Ready期间,集群管理员将看到区域中的大多数节点都处于状态状态,但是 Pod 的状态不会改变,也不会在其他节点上重新调度。
请注意,上述行为仅适用于大于三个节点的集群。在三个或更少节点的集群中,无法访问的节点上的 Pod 会被安排驱逐,而新 Pod 则被调度到健康的节点上。
在测试过程中,我们偶尔会观察到,在网络断开连接期间,Pod 会被逐出一个无法访问的节点,即使该区域的大多数节点都无法访问。我们仍在调查 Kubernetes 节点生命周期控制器中可能存在的竞争条件作为这种行为的原因。
情景 4:少数族裔区域中断
预期结果:Pod 被逐出无法访问的节点,而新 Pod 被调度到可用的符合条件的节点上。
少量中断意味着区域中与 Kubernetes 控制平面断开连接的节点比例较小。如果集群中未定义任何区域,则少数中断意味着整个集群中的少数节点已断开连接。如前所述,少数由节点生命周期控制器的unhealthy-zone-threshold设置来定义,默认情况下为55%。在这种情况下,如果网络断开的持续时间超过default-unreachable-toleration-seconds(5 分钟)和node-monitor-grace-period(40 秒),并且一个区域中只有不到 55% 的节点无法访问,则新 Pod 将调度到健康的节点上,而无法访问的节点上的 Pod 则被标记为驱逐。
集群管理员将看到在运行正常的节点上创建的新 Pod,断开连接的节点上的 pod 将显示为Terminating。请记住,尽管断开连接的节点上的 Pod 具有Terminating状态,但在节点重新连接到 Kubernetes 控制平面之前,它们不会被完全驱逐。
场景 5:网络中断期间节点重启
预期结果:无法访问的节点上的 Pod 要等到节点重新连接到 Kubernetes 控制平面后才会启动。Pod 故障转移遵循场景 1-3 中描述的逻辑,具体取决于无法访问的节点的数量。
在网络中断期间重启节点意味着在网络断开连接的同时,节点上发生了另一次故障(例如电源循环、内存不足事件或其他问题)。如果 kubelet 也已重新启动,则网络断开连接开始时在该节点上运行的 Pod 不会在断开连接期间自动重启。kubelet 在启动时会查询 Kubernetes API 服务器,以了解它应该运行哪些 pod。如果 kubelet 由于网络断开连接而无法访问 API 服务器,则无法检索启动 pod 所需的信息。
在这种情况下,不能使用本地故障排除工具(例如 crictl CLI)来手动启动 pod,这是 “漏洞” 措施。Kubernetes 通常会移除失败的 pod 并创建新的 pod,而不是重启现有 pod(详情参见 containerd 存储库中的
