本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
# AWS 无尘室机器学习
AWS Clean Rooms ML 允许两个或多个参与方在其数据上运行机器学习模型,而无需彼此共享数据。该服务提供增强隐私的控件,使数据所有者能够安全地保护自己的数据和模型 IP。您可以使用 AWS 创作模型或自带自定义模型。
有关其工作方式的更详细说明,请参阅[Cross-account 工作](ml-behaviors.md#ml-behaviors-cross-account-jobs)。
有关 Clean Rooms 机器学习模型功能的更多信息,请参阅以下主题。
**Topics**
+ [AWS Clean Rooms 机器学习术语](#ml-terminology)
+ [AWS Clean Rooms ML 如何与 AWS 模型配合使用](#ml-how-it-works)
+ [AWS Clean Rooms ML 如何使用自定义模型](#custML-how-it-works)
+ [AWS Clean Rooms ML 中的模型](aws-models.md)
+ [Clean Rooms ML 中的自定义模型](custom-models.md)
## AWS Clean Rooms 机器学习术语
使用 Clean Rooms ML 时,了解以下术语非常重要:
+ *训练数据提供者* - 贡献训练数据、创建和配置相似模型并将该相似模型与一个协作关联的一方。
+ *种子数据提供者* - 贡献种子数据、生成相似细分并导出其相似细分的一方。
+ *训练数据* - 训练数据提供者的数据,用于生成相似模型。训练数据用于测量用户行为的相似性。
训练数据必须包含用户 ID、项目 ID 和时间戳列。(可选)训练数据可以包含其他交互作为数值或分类特征。举例而言,交互可以是观看的视频、购买的物品或阅读的文章列表。
+ *种子数据* - 种子数据提供者的数据,用于创建相似细分。种子数据可以直接提供,也可以来自 AWS Clean Rooms 查询结果。相似细分输出是训练数据中与种子用户最相似的一组用户。
+ *相似模型* - 训练数据的机器学习模型,用于在其他数据集中查找相似用户。
在使用 API 时,*受众模型* 术语等同于相似模型。例如,您可以使用 [CreateAudienceModel](https://docs.aws.amazon.com/cleanrooms-ml/latest/APIReference/API_CreateAudienceModel.html)API 创建外观相似的模型。
+ *相似细分* - 是与种子数据最相似的训练数据子集。
使用 API 时,您可以使用 API 创建外观相似的[StartAudienceGenerationJob](https://docs.aws.amazon.com/cleanrooms-ml/latest/APIReference/API_StartAudienceGenerationJob.html)区段。
训练数据提供者的数据绝不会与种子数据提供者共享,并且种子数据提供者的数据绝不会与训练数据提供者共享。相似细分输出与训练数据提供者共享,但绝不会与种子数据提供者共享。
## AWS Clean Rooms ML 如何与 AWS 模型配合使用
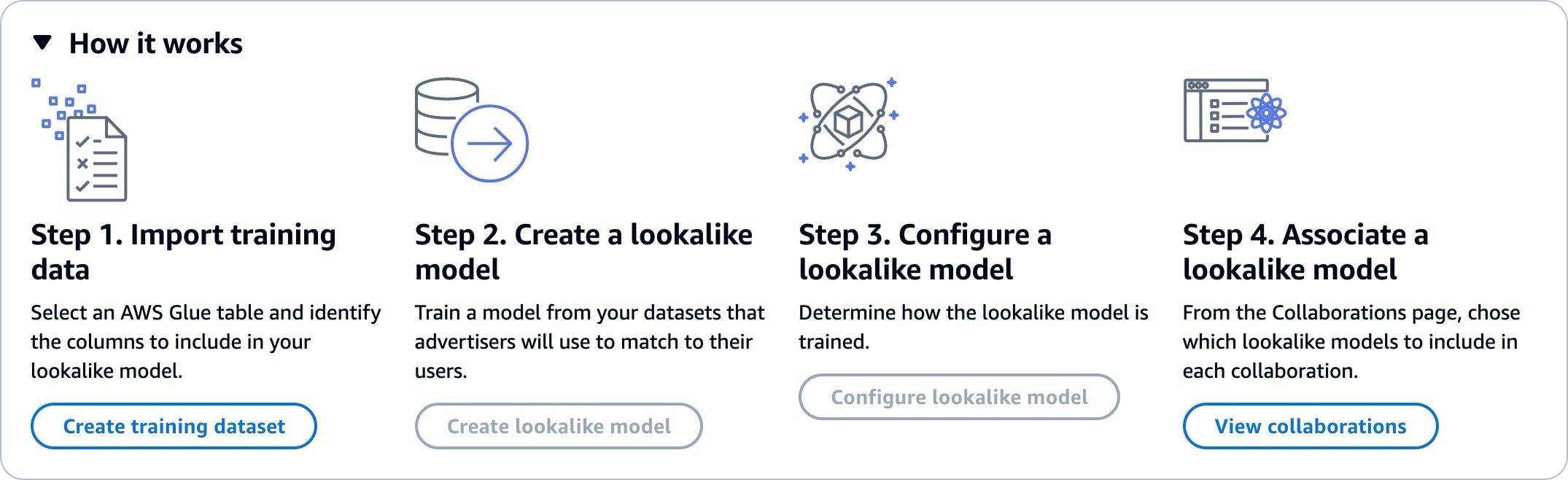
使用相似模型需要两方,即训练数据提供者和种子数据提供者,按顺序合作,将他们的数据整合到协作中 AWS Clean Rooms 。以下是训练数据提供者必须先完成的工作流程:
1. 训练数据提供者的数据必须存储在用户-项目交互 AWS Glue 的数据目录表中。训练数据必须至少包含用户 ID 列、交互 ID 列和时间戳列。
1. 训练数据提供者向注册训练数据 AWS Clean Rooms。
1. 训练数据提供者创建一个相似模型,可以将其与多个种子数据提供者共享。相似模型是一种深度神经网络,训练时间可能长达 24 小时。它不会自动重新训练,我们建议您每周重新训练一次。
1. 训练数据提供者配置相似模型,包括是否共享相关性指标以及输出细分的 Amazon S3 位置。训练数据提供者可以通过单个相似模型创建多个配置的相似模型。
1. 训练数据提供者将配置的受众模型关联到与某个种子数据提供者共享的协作。
以下是种子数据提供者接下来必须完成的工作流程:
1. 种子数据提供者的数据可以存储在 Amazon S3 存储桶中,也可以来自查询结果。
1. 种子数据提供者开启与训练数据提供者共享的协作。
1. 种子数据提供者从协作页面的“Clean Rooms ML”选项卡中创建一个相似细分。
1. 种子数据提供者可以评估相关性指标(如果已共享),并导出相似细分以在 AWS Clean Rooms外部使用。
## AWS Clean Rooms ML 如何使用自定义模型
借助 Clean Rooms ML,协作成员可以使用存储在 Amazon ECR 中的 dockerized 自定义模型算法来共同分析他们的数据。为此,*模型提供者*必须创建图像并将其存储在 Amazon ECR 中。按照 [Amazon Elastic Container Registry 用户指南](https://docs.aws.amazon.com/AmazonECR/latest/userguide/)中的步骤创建包含自定义 ML 模型的私有存储库。
协作中的任何成员都可以成为*模型提供者*,前提是他们拥有正确的权限。协作的所有成员都可以向模型贡献训练数据、推理数据或两者兼而有之。在本指南中,提供数据的成员被称为*数据提供者*。创建协作的成员是协作创建*者*,该成员可以是*模型提供者,也可以是*数据提供**者之一,或者两者兼而有之。
在最高级别,以下是执行自定义 ML 建模必须完成的步骤:
1. 协作创建者创建协作并为每个成员分配适当的成员能力和付款配置。协作创建者必须在此步骤中将成员接收模型输出或接收推理结果的能力分配给相应的成员,因为协作创建后无法对其进行更新。有关更多信息,请参阅 [在 AWS Clean Rooms ML 中创建和加入合作](create-custom-ml-collaboration.md)。
1. 模型提供者配置其容器化机器学习模型并将其与协作关联,并确保为导出的数据设置隐私约束。有关更多信息,请参阅 [在 AWS Clean Rooms ML 中配置模型算法](configure-model-algorithm.md)。
1. 数据提供者将其数据贡献给合作,并确保其隐私需求得到具体说明。数据提供者必须允许模型访问其数据。有关更多信息,请参阅[在 AWS Clean Rooms ML 中贡献训练数据](custom-model-training-data.md)和[在 AWS Clean Rooms ML 中关联配置的模型算法](associate-model-algorithm.md)。
1. 协作成员创建 ML 配置,该配置定义了模型工件或推理结果的导出位置。
1. 协作成员创建一个 ML 输入通道,为训练容器或推理容器提供输入。机器学习输入通道是一个查询,用于定义要在模型算法的上下文中使用的数据。
1. 协作成员使用 ML 输入通道和配置的模型算法调用模型训练。有关更多信息,请参阅 [在 AWS Clean Rooms ML 中创建经过训练的模型](create-trained-model.md)。
1. (可选)模型训练器调用模型导出作业,并将模型工件发送到模型结果接收器。只有具有有效 ML 配置且成员能够接收模型输出的成员才能接收模型工件。有关更多信息,请参阅 [从 AWS Clean Rooms ML 中导出模型工件](export-model-artifacts.md)。
1. (可选)协作成员使用 ML 输入通道、经过训练的模型 ARN 和推理配置的模型算法调用模型推理。推理结果将发送到推理输出接收器。只有具有有效 ML 配置且成员能够接收推理输出的成员才能接收推理结果。
以下是*模型提供者*必须完成的步骤:
1. 创建与 A SageMaker I 兼容的 Amazon ECR docker 镜像。Clean Rooms ML 仅支持与 SageMaker AI 兼容的 docker 镜像。
1. 创建与 SageMaker AI 兼容的 docker 镜像后,将该镜像推送到 Amazon ECR。按照 [Amazon 弹性容器注册表用户指南](https://docs.aws.amazon.com/AmazonECR/latest/userguide/)中的说明创建容器训练镜像。
1. 配置模型算法以在 Clean Rooms ML 中使用。
1. 提供 Amazon ECR 存储库链接和配置模型算法所需的所有参数。
1. 提供服务访问角色,允许 Clean Rooms ML 访问 Amazon ECR 存储库。
1. 将配置的模型算法与协作关联。这包括提供隐私政策,该政策定义了对容器日志、故障日志、 CloudWatch 指标的控制以及对可以从容器结果中导出多少数据的限制。
以下是*数据提供者*为与自定义 ML 模型协作而必须完成的步骤:
1. 使用自定义分析规则配置现有 AWS Glue 表。这允许一组特定的预先批准的查询或预先批准的账户使用您的数据。
1. 将您配置的表与协作关联,并提供可以访问您的 AWS Glue 表格的服务访问角色。
1. 向表中@@ [添加协作分析规则](add-collaboration-analysis-rule.md),允许配置的模型算法关联访问配置的表。
1. 在 Clean Rooms ML 中关联和配置模型和数据后,能够运行查询的成员提供 SQL 查询并选择要使用的模型算法。
模型训练完成后,该成员启动模型训练工件或推理结果的导出。这些工件或结果将发送给能够接收经过训练的模型输出的成员。结果接收器必须`MachineLearningConfiguration`先对其进行配置,然后才能接收模型输出。