使用 Amazon S3 Files
主题
什么是 S3 Files?
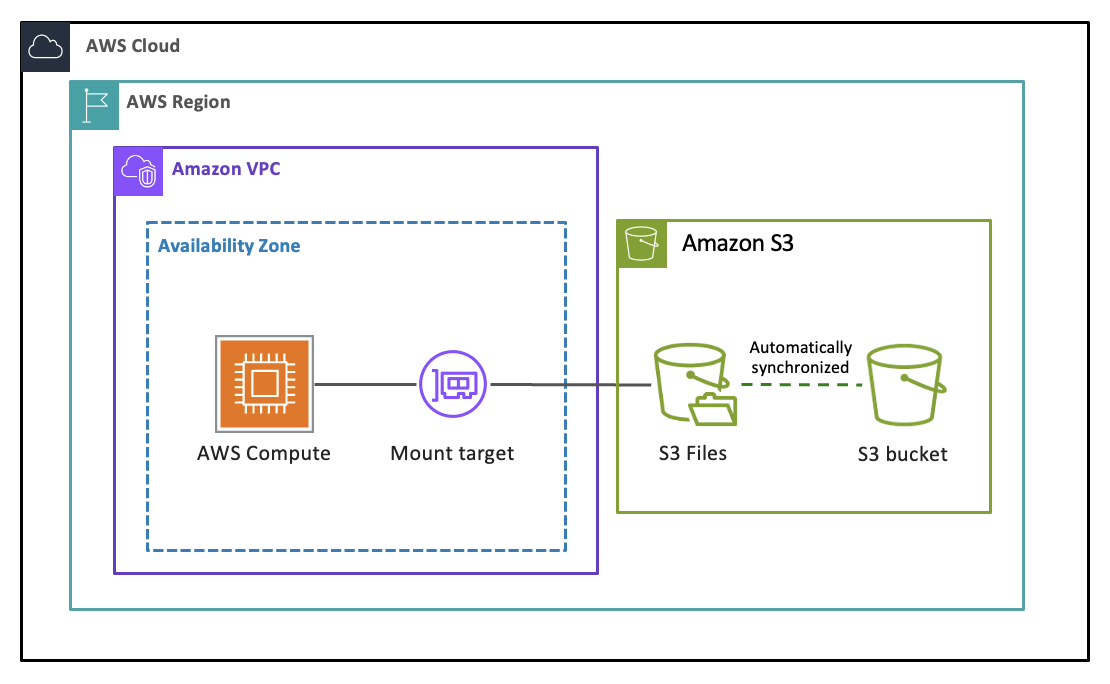
S3 Files 是一个共享文件系统,可将任何 AWS 计算资源与您在 Amazon S3 中的数据直接连接。它通过完整的文件系统语义和低延迟性能,以文件形式提供对所有 S3 数据的快速、直接访问,而无需您的数据离开 S3。每个基于文件的应用程序、代理和团队都可以使用它们已经依赖的工具,将您的 S3 数据作为文件系统进行访问和处理。S3 Files 使用 Amazon EFS 构建,为您提供了文件系统的性能和简单性,以及 S3 的可扩展性、持久性和成本效益。您可以使用文件和目录操作读取、写入和组织数据,而 S3 Files 则管理存储桶和文件系统之间更改的同步。
S3 Files 是如何工作的?
当您创建链接到 S3 存储桶或其中前缀的 S3 文件系统并将其挂载到计算资源(例如 EC2 实例或 Lambda 函数)上时,S3 Files 会首先以文件的形式呈现存储桶对象的可遍历视图。在浏览目录和打开的文件时,关联的元数据和内容会放置到文件系统的高性能存储中。当您读取文件时,S3 Files 会根据需要将文件内容加载到高性能存储中,而无需复制整个数据集。当您写入数据时,您的写入内容会进入高性能存储,然后同步回您的 S3 存储桶。S3 Files 代表您智能地将您的文件系统操作转换为高效的 S3 请求。许多读取操作会完全绕过文件系统,数据直接从 S3 提供。
您可以为加载到高性能存储的内容配置文件大小阈值(默认 <128 KiB),因为延迟对于小文件最为重要。在两种情况下,S3 Files 会直接从 S3 存储桶流式传输文件读取:当文件的数据未存储在文件系统的高性能存储中时,以及对于 >= 1 MiB 的大型读取(即使数据也驻留在文件系统的高性能存储中)。S3 存储桶针对高吞吐量进行了优化,而文件系统的高性能存储层则针对低延迟访问进行了优化。S3 Files 将小文件(默认情况下 < 128 KiB)的数据异步导入到文件系统的高性能存储,以便在后续读取时实现低延迟访问。最近修改但尚未同步到 S3 的数据始终从文件系统提供。有关更多信息,请参阅 自定义 S3 Files 的同步。
在可配置的时段(1 到 365 天,默认为 30 天)内未读取的数据会自动从高性能存储中过期。您的授权数据始终保留在 S3 中,后台同步可使文件系统和存储桶在两个方向上保持一致。有关更多信息,请参阅 了解同步的工作原理。
支持挂载 S3 文件系统的计算服务有 Amazon EC2、AWS Lambda、Amazon EKS 和 Amazon ECS。有关更多信息,请参阅 在计算资源上挂载 S3 存储桶。
您是 S3 Files 的新用户吗?
如果您是首次使用 S3 Files 的用户,请使用 S3 控制台或 AWS CLI 按照教程:开始使用 S3 Files创建第一个 S3 文件系统。
重要概念
整个 S3 Files 文档中使用了下面的术语:
- 文件系统:
与 S3 存储桶关联的共享文件系统。
- 高性能存储
文件系统中的低延迟存储层,其中存放着活跃使用的文件数据和元数据。S3 Files 自动管理此存储,在您访问文件时将数据复制到该存储,并移除未在可配置的到期窗口内读取的数据。您需要为驻留在高性能存储上的数据支付存储费率。
- 同步
S3 Files 使您的工作数据集保持活跃状态并且您的更改在文件系统和 S3 存储桶之间保持一致的过程。导入会将数据从 S3 存储桶复制到文件系统。将您通过文件系统所做的副本更改导出回 S3 存储桶。S3 Files 会自动执行双向同步。
- 挂载目标
挂载目标提供对您的 VPC 中单个可用区内文件系统的网络访问。要从计算资源访问文件系统,您需要至少一个挂载目标,并且每个可用区最多可以创建一个挂载目标。
- 访问点
接入点是文件系统的特定于应用程序的入口点,它简化了对共享数据集进行大规模数据访问的管理。您可以使用接入点对通过接入点发出的所有文件系统请求强制执行用户身份和权限。使用 AWS 管理控制台创建文件系统时,S3 Files 会自动为该文件系统创建一个接入点。
功能
- 无需完整数据复制即可实现高性能
S3 Files 仅将您的活跃工作集(而不是整个数据集)复制到文件系统的高性能存储上,从而实现低延迟的文件访问。高性能存储以亚毫秒到个位数毫秒的延迟提供频繁访问的小文件。大型读取直接从 S3 流式传输,总吞吐量高达每秒数 TB。这意味着您可以获得交互式工作负载的文件系统性能和流式传输工作负载的 S3 吞吐量,而无需为存储或导入未使用的数据或无法从低延迟中受益的数据付费。有关更多信息,请参阅 性能规格。
- 智能读取路由
S3 Files 自动将读取请求路由到最适合它们的存储层(S3 文件系统或 S3 存储桶),同时保持完整的文件系统语义,包括一致性、锁定和 POSIX 权限。可以从高性能存储中对活跃使用的文件进行少量的随机读取,以实现低延迟。对不在文件系统上的数据的大量顺序读取和读取直接从 S3 存储桶提供,以实现高吞吐量,而不收取文件系统数据费用。
- 自动同步
S3 Files 会自动使您的文件系统和 S3 存储桶在两个方向上保持一致。您通过文件系统所做的更改将复制回您的 S3 存储桶,而直接对 S3 存储桶所做的更改将反映在文件系统的视图中。您可以自定义同步行为,包括导入哪些数据以及这些数据在文件系统中停留多长时间。有关更多信息,请参阅 了解同步的工作原理。
- 可扩展的性能
S3 Files 会自动扩展吞吐量和 IOPS 以匹配您的工作负载活动。您不需要预调配或管理性能容量,只需为您使用的容量付费。
- 区域耐久性
写入高性能存储层的数据具有与 Amazon S3 相同的持久性。它在同一 AWS 区域内的多个地理上分开的可用区中以冗余方式存储数据,为您的数据提供高持久性和可用性。
- 加密:
S3 Files 使用 TLS 加密所有传输中数据,并使用 AWS KMS 密钥加密所有静态数据。您可以使用 AWS 拥有的密钥(默认)或您自己的客户自主管理型密钥。有关更多信息,请参阅 加密。
- 文件系统语义
S3 Files 支持 NFS 版本 4.2 和 4.1 协议。它提供文件系统访问语义,如写后读数据一致性、文件锁定和 POSIX 权限。
如何对 S3 Files 计费?
您需要为驻留在高性能存储上的部分活跃数据支付存储费率,并为读取和写入文件系统的高性能存储支付文件系统访问费用。在两种情况下,S3 Files 会直接从 S3 存储桶流式传输文件读取:当文件的数据未存储在文件系统的高性能存储中时,以及对于 >= 1 MiB 的大型读取(即使数据也驻留在文件系统的高性能存储中)。S3 存储桶针对高吞吐量进行了优化,而文件系统的高性能存储层则针对低延迟访问进行了优化。S3 Files 将小文件(默认情况下 < 128 KiB)的数据异步导入到文件系统的高性能存储,以便在后续读取时实现低延迟访问。这些读取仅产生标准的 S3 GET 请求费用,而不收取文件系统访问费用。文件系统访问费用适用于同步操作:将数据导入文件系统会产生写入费用,而将更改导出回 S3 会产生读取费用。有关更多信息,请参阅 如何计量 S3 Files。有关当前定价,请参阅 S3 Files 定价页面
