As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
In-process recuperação e treinamento sem controle
HyperPod o treinamento sem ponto de verificação usa redundância de modelo para permitir um treinamento tolerante a falhas. O princípio fundamental é que os estados do modelo e do otimizador sejam totalmente replicados em vários grupos de nós, com atualizações de peso e alterações de estado do otimizador replicadas de forma síncrona em cada grupo. Quando ocorre uma falha, as réplicas íntegras concluem suas etapas de otimização e transmitem os model/optimizer estados atualizados às réplicas em recuperação.
Essa abordagem baseada em redundância de modelos permite vários mecanismos de tratamento de falhas:
-
In-process recuperação: os processos permanecem ativos apesar das falhas, mantendo todos os estados do modelo e do otimizador na memória da GPU com os valores mais recentes
-
Tratamento eficiente de abortos: abortos controlados e limpeza de recursos para as operações afetadas
-
Reexecução do bloco de código: reexecutando somente os segmentos de código afetados em um Bloco de Re-executable Código (RCB)
-
Recuperação sem pontos de verificação sem perda do progresso do treinamento: como os processos persistem e os estados permanecem na memória, nenhum progresso do treinamento é perdido; quando ocorre uma falha, o treinamento é retomado a partir da etapa anterior, em vez de ser retomado a partir do último ponto de verificação salvo
Configurações sem pontos de verificação
Aqui está o trecho principal do treinamento sem pontos de verificação.
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank wait_rank() def main(): @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=PEFTCheckpointManager(enable_offload=True), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), ) def run_main(cfg, caller: Optional[HPCallWrapper] = None): ... trainer = Trainer( strategy=CheckpointlessMegatronStrategy(..., num_distributed_optimizer_instances=2), callbacks=[..., CheckpointlessCallback(...)], ) trainer.fresume = resume trainer._checkpoint_connector = CheckpointlessCompatibleConnector(trainer) trainer.wrapper = caller
wait_rank: Todas as classificações aguardarão as informações de classificação da HyperpodTrainingOperator infraestrutura.HPWrapper: invólucro de função Python que permite recursos de reinicialização para um bloco de Re-executable código (RCB). A implementação usa um gerenciador de contexto em vez de um decorador Python porque os decoradores não podem determinar o número de RCBs a serem monitorados em tempo de execução.CudaHealthCheck: garante que o contexto CUDA do processo atual esteja em um estado íntegro por meio da sincronização com a GPU. Usa o dispositivo especificado pela variável de ambiente LOCAL_RANK ou usa como padrão o dispositivo CUDA do thread principal se LOCAL_RANK não estiver definido.HPAgentK8sAPIFactory: essa API permite que o treinamento sem pontos de verificação consulte o status de treinamento de outros pods no cluster de treinamento do Kubernetes. Ele também fornece uma barreira em nível de infraestrutura que garante que todas as fileiras concluam com êxito as operações de abortamento e reinicialização antes de continuar.CheckpointManager: gerencia pontos de verificação na memória e recuperação ponto a ponto para tolerância a falhas sem pontos de verificação. Tem as seguintes responsabilidades principais:In-Memory Gerenciamento de pontos de verificação: salva e gerencia os pontos de verificação do NeMo modelo na memória para uma recuperação rápida sem disco I/O durante cenários de recuperação sem pontos de verificação.
Validação da viabilidade de recuperação: determina se a recuperação sem pontos de verificação é possível validando a consistência global das etapas, a integridade da classificação e a integridade do estado do modelo.
Peer-to-Peer Orquestração de recuperação: coordena a transferência de pontos de verificação entre classificações saudáveis e falhadas usando comunicação distribuída para recuperação rápida.
Gerenciamento de estado RNG: preserva e restaura estados geradores de números aleatórios em Python, NumPy PyTorch, e Megatron para recuperação determinística.
[Opcional] Descarga do ponto de verificação: descarregue no ponto de verificação da memória para a CPU se a GPU não tiver capacidade de memória suficiente.
PEFTCheckpointManager: Ele se estendeCheckpointManagermantendo os pesos do modelo básico para o ajuste fino do PEFT.CheckpointlessAbortManager: gerencia as operações de aborto em um thread em segundo plano quando um erro é encontrado. Por padrão, ele aborta TransformerEngine, Checkpointing TorchDistributed, e. DataLoader Os usuários podem registrar manipuladores de aborto personalizados conforme necessário. Após a conclusão do aborto, toda a comunicação deve ser interrompida e todos os processos e threads devem ser encerrados para evitar vazamentos de recursos.CheckpointlessFinalizeCleanup: manipula as operações finais de limpeza no encadeamento principal para componentes que não podem ser abortados ou limpos com segurança no encadeamento em segundo plano.CheckpointlessMegatronStrategy: Isso é herdado doMegatronStrategyde Nemo. Observe que o treinamento sem ponto de verificação requer pelo menos 2num_distributed_optimizer_instancespara que haja replicação do otimizador. A estratégia também cuida do registro de atributos essenciais e da inicialização do grupo de processos, por exemplo, sem root.CheckpointlessCallback: Retorno de chamada relâmpago que integra o NeMo treinamento ao sistema de tolerância a falhas do checkpointless training. Tem as seguintes responsabilidades principais:Gerenciamento do ciclo de vida da etapa de treinamento: monitora o progresso do treinamento e ParameterUpdateLock coordena a recuperação enable/disable sem pontos de verificação com base no estado do treinamento (primeira etapa versus etapas subsequentes).
Coordenação do estado do ponto de verificação: gerencia o ponto de verificação do modelo base PEFT na memória. saving/restoring
CheckpointlessCompatibleConnector: uma PTLCheckpointConnectorque tenta pré-carregar o arquivo do ponto de verificação na memória, com o caminho de origem determinado nesta prioridade:experimente a recuperação sem pontos de verificação
se o checkpointless retornar None, volte para parent.resume_start ()
Veja o exemplo
Conceitos
Esta seção apresenta conceitos de treinamento sem pontos de verificação. O treinamento Checkpointless na Amazon SageMaker HyperPod oferece suporte à recuperação em processo. Essa interface de API segue um formato semelhante às APIs NVRx.
Conceito - Re-Executable Bloco de código (RCB)
Quando ocorre uma falha, os processos íntegros permanecem ativos, mas uma parte do código deve ser executada novamente para recuperar os estados de treinamento e as pilhas de python. Um bloco Re-executable de código (RCB) é um segmento de código específico que é executado novamente durante a recuperação de falhas. No exemplo a seguir, o RCB abrange todo o script de treinamento (ou seja, tudo em main ()), o que significa que cada recuperação de falha reinicia o script de treinamento enquanto preserva o modelo na memória e os estados do otimizador.
Conceito - Controle de falhas
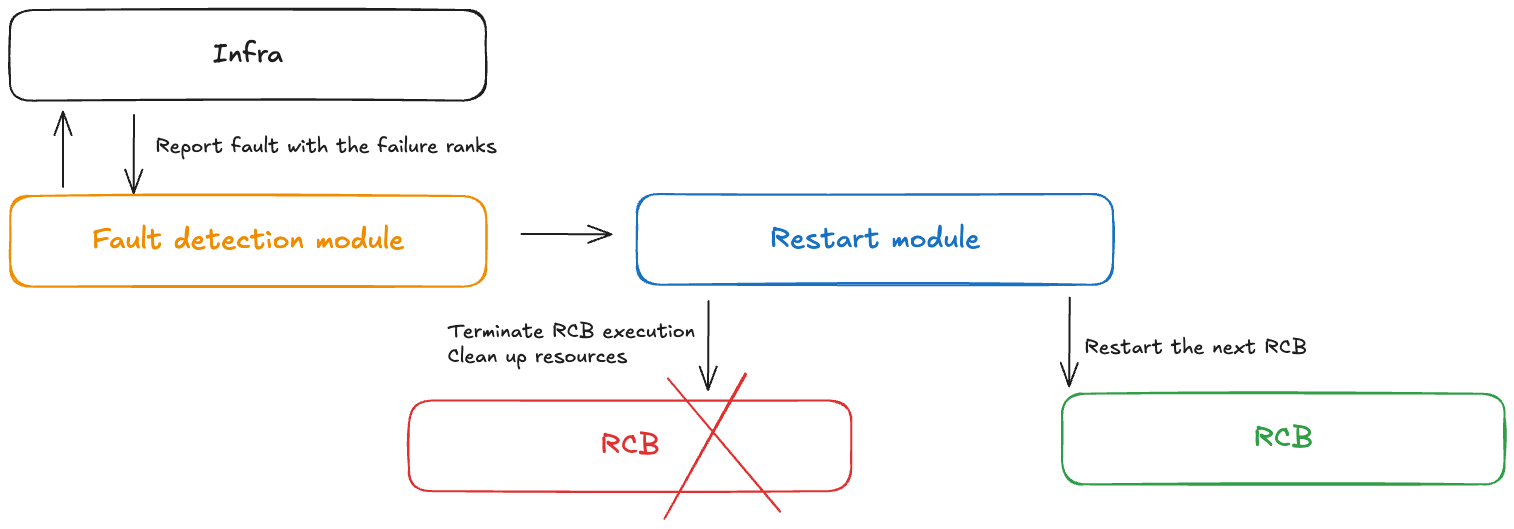
Um módulo controlador de falhas recebe notificações quando ocorrem falhas durante o treinamento sem ponto de verificação. Esse controlador de falhas inclui os seguintes componentes:
Módulo de detecção de falhas: recebe notificações de falhas de infraestrutura
APIs de definição de RCB: permite que os usuários definam o bloco de código reexecutável (RCB) em seu código
Módulo de reinicialização: encerra o RCB, limpa os recursos e reinicia o RCB
Conceito - Redundância do modelo
O treinamento de modelos grandes geralmente requer um tamanho paralelo de dados grande o suficiente para treinar modelos com eficiência. No paralelismo de dados tradicional, como PyTorch DDP e Horovod, o modelo é totalmente replicado. Técnicas mais avançadas de paralelismo de dados fragmentados, como o otimizador DeepSpeed ZeRO e o FSDP, também oferecem suporte ao modo de fragmentação híbrida, que permite fragmentar os model/optimizer estados dentro do grupo de fragmentação e replicar totalmente entre os grupos de replicação. NeMo também tem esse recurso de fragmentação híbrida por meio de um argumento num_distributed_optimizer_instances, que permite redundância.
No entanto, adicionar redundância indica que o modelo não será totalmente fragmentado em todo o cluster, resultando em maior uso da memória do dispositivo. A quantidade de memória redundante variará dependendo das técnicas específicas de fragmentação do modelo implementadas pelo usuário. Os pesos, gradientes e memória de ativação do modelo de baixa precisão não serão afetados, pois são fragmentados por meio do paralelismo do modelo. O modelo mestre de alta precisão weights/gradients e os estados do otimizador serão afetados. Adicionar uma réplica de modelo redundante aumenta o uso da memória do dispositivo em aproximadamente o equivalente ao tamanho de um ponto de verificação DCP.
A fragmentação híbrida divide os coletivos de todos os grupos de DP em coletivos relativamente menores. Anteriormente, havia uma redução na dispersão e uma coleta total em todo o grupo de DP. Após a fragmentação híbrida, a redução de dispersão é executada somente dentro de cada réplica do modelo, e haverá uma redução total nos grupos de réplicas do modelo. O all-gather também está sendo executado dentro de cada réplica do modelo. Como resultado, todo o volume de comunicação permanece praticamente inalterado, mas os coletivos estão trabalhando com grupos menores, então esperamos uma latência melhor.
Conceito - Tipos de falha e reinicialização
A tabela a seguir registra diferentes tipos de falhas e mecanismos de recuperação associados. O treinamento Checkpointless tenta primeiro a recuperação de falhas por meio de uma recuperação em processo, seguida por uma reinicialização em nível de processo. Ele volta para uma reinicialização no nível do trabalho somente no caso de uma falha catastrófica (por exemplo, vários nós falham ao mesmo tempo).
| Tipo de falha | Causa | Tipo de recuperação | Mecanismo de recuperação |
|---|---|---|---|
| In-process falha | Code-level erros, exceções | In-Process Recuperação (IPR) | Execute novamente o RCB dentro do processo existente; processos saudáveis permanecem ativos |
| Falha na reinicialização do processo | Contexto CUDA corrompido, processo encerrado | Reinício no nível do processo (PLR) | SageMaker HyperPod o operador de treinamento reinicia os processos; ignora a reinicialização do pod K8s |
| Falha na substituição do nó | Falha permanente node/GPU de hardware | Job Level Restart (JLR) | Substitua o nó com falha; reinicie todo o trabalho de treinamento |
Conceito - Proteção de bloqueio atômico para etapa otimizadora
A execução do modelo é dividida em três fases: propagação para frente, propagação para trás e etapa do otimizador. O comportamento de recuperação varia de acordo com o tempo de falha:
Forward/backward propagação: volte para o início da etapa de treinamento atual e transmita os estados do modelo para os nós de substituição
Etapa do otimizador: permitir que réplicas íntegras concluam a etapa de proteção bloqueada e, em seguida, transmita os estados atualizados do modelo para os nós de substituição
Essa estratégia garante que as atualizações concluídas do otimizador nunca sejam descartadas, ajudando a reduzir o tempo de recuperação de falhas.
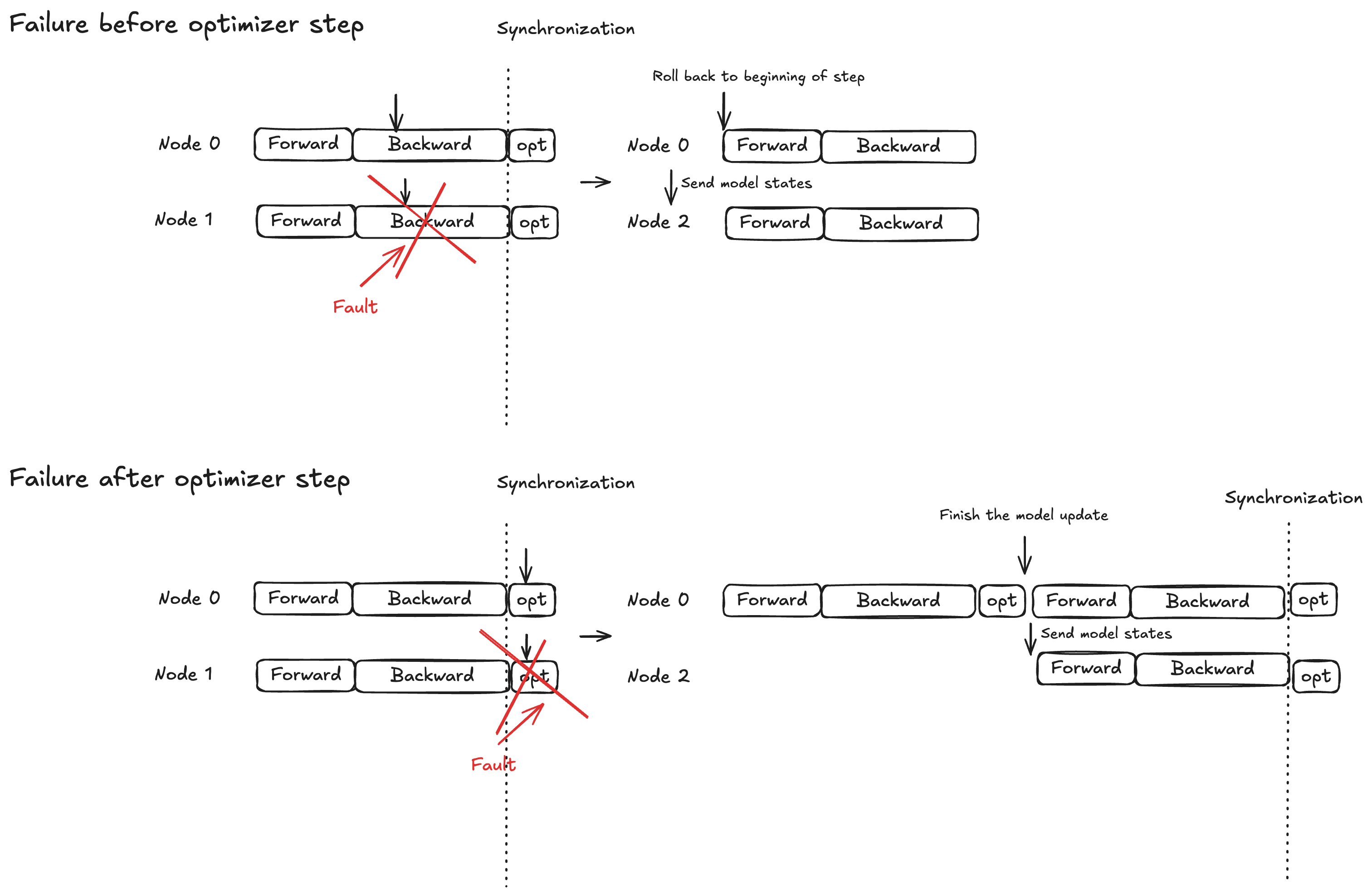
Diagrama de fluxo de treinamento sem pontos de verificação
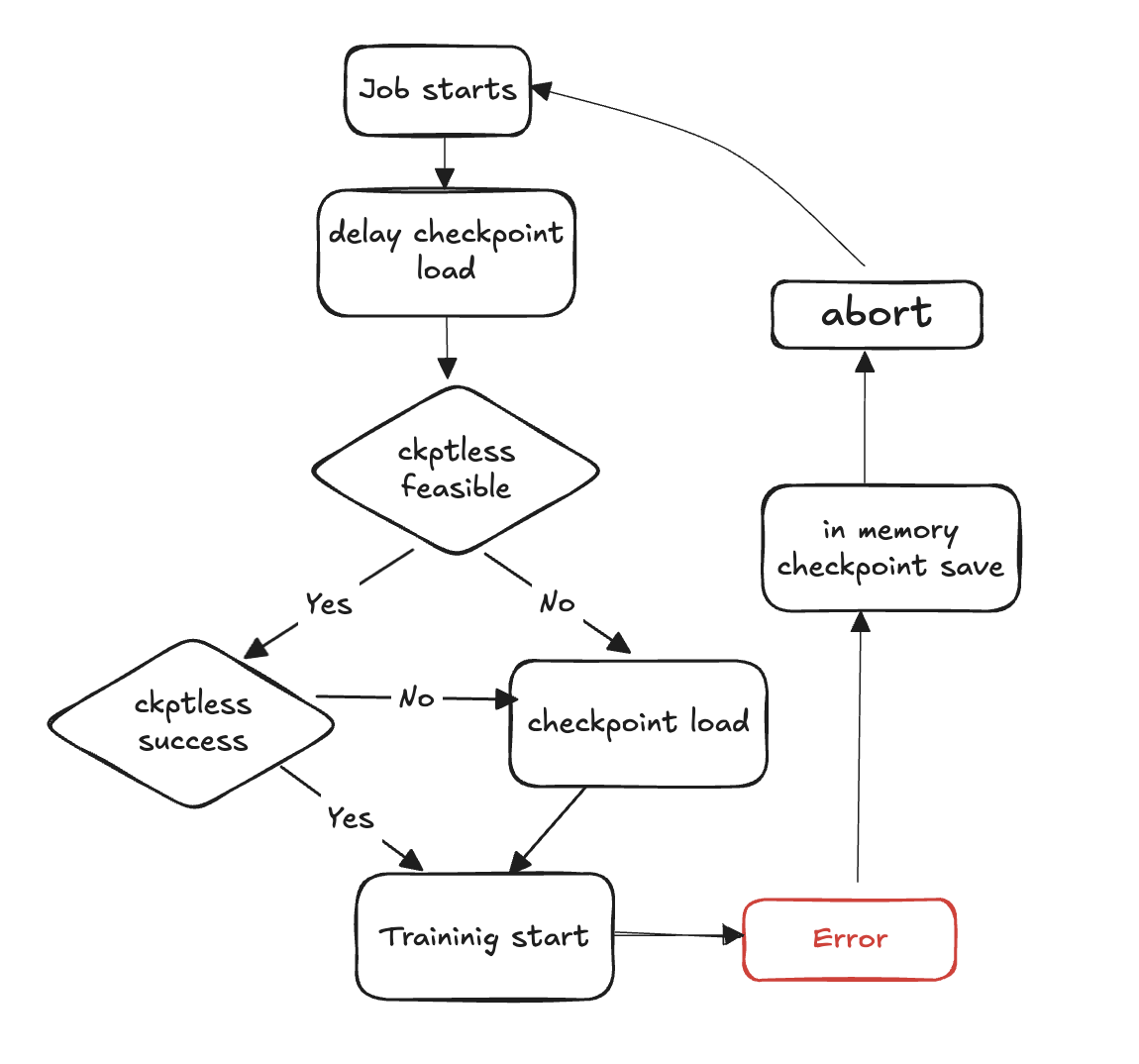
As etapas a seguir descrevem a detecção de falhas e o processo de recuperação sem pontos de verificação:
Início do ciclo de treinamento
A falha ocorre
Avalie a viabilidade de um currículo sem pontos de verificação
Verifique se é possível fazer um currículo sem pontos de verificação
Se possível, tente retomar o checkpoint sem precisar
Se a retomada falhar, volte para o ponto de verificação de carregamento a partir do armazenamento
Se a retomada for bem-sucedida, o treinamento continuará a partir do estado recuperado
Se não for viável, volte para o ponto de verificação carregando do armazenamento
Limpe os recursos - aborte todos os grupos de processos e back-ends e libere recursos em preparação para a reinicialização.
Retomar o ciclo de treinamento - um novo ciclo de treinamento começa e o processo retorna à etapa 1.
Referência de API
wait_rank
hyperpod_checkpointless_training.inprocess.train_utils.wait_rank()
Espera e recupera as informações de classificação e, em seguida HyperPod, atualiza o ambiente atual do processo com variáveis de treinamento distribuídas.
Essa função obtém a atribuição correta de classificação e as variáveis de ambiente para treinamento distribuído. Ele garante que cada processo obtenha a configuração apropriada para sua função no trabalho de treinamento distribuído.
Parâmetros
Nenhum
Devoluções
Nenhum
Comportamento
Verificação do processo: ignora a execução se for chamada a partir de um subprocesso (só é executado em) MainProcess
Recuperação de ambiente: obtém variáveis de ambiente atuais
RANKeWORLD_SIZEa partir deHyperPod Comunicação: chamadas
hyperpod_wait_rank_info()para recuperar informações de classificação de HyperPodAtualização do ambiente: atualiza o ambiente de processo atual com variáveis de ambiente específicas do trabalhador recebidas de HyperPod
Variáveis de ambiente
A função lê as seguintes variáveis de ambiente:
RANK (int) — Classificação atual do processo (padrão: -1 se não estiver definido)
WORLD_SIZE (int) — Número total de processos na tarefa distribuída (padrão: 0 se não estiver definido)
Aumenta
AssertionError— Se a resposta de não HyperPod estiver no formato esperado ou se os campos obrigatórios estiverem ausentes
Exemplo
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank # Call before initializing distributed training wait_rank() # Now environment variables are properly set for this rank import torch.distributed as dist dist.init_process_group(backend='nccl')
Observações
Só é executado no processo principal; as chamadas do subprocesso são automaticamente ignoradas
A função bloqueia até HyperPod fornecer as informações de classificação
Embalagem HP
class hyperpod_checkpointless_training.inprocess.wrap.HPWrapper( *, abort=Compose(HPAbortTorchDistributed()), finalize=None, health_check=None, hp_api_factory=None, abort_timeout=None, enabled=True, trace_file_path=None, async_raise_before_abort=True, early_abort_communicator=False, checkpoint_manager=None, check_memory_status=True)
Invólucro de funções Python que permite os recursos de reinicialização de um bloco de Re-executable código (RCB) em um treinamento sem pontos de verificação. HyperPod
Esse invólucro fornece tolerância a falhas e recursos de recuperação automática monitorando a execução do treinamento e coordenando as reinicializações em processos distribuídos quando ocorrem falhas. Ele usa uma abordagem de gerenciador de contexto em vez de um decorador para manter os recursos globais durante todo o ciclo de vida do treinamento.
Parâmetros
abort (Abort, opcional) — aborta a execução de forma assíncrona quando falhas são detectadas. Padrão:
Compose(HPAbortTorchDistributed())finalize (Finalize, opcional) — Rank-local finaliza o manipulador executado durante a reinicialização. Padrão:
Nonehealth_check (HealthCheck, opcional) — verificação de Rank-local integridade executada durante a reinicialização. Padrão:
Nonehp_api_factory (Callable, optional) — Função de fábrica para criar uma API com a qual interagir. HyperPod HyperPod Padrão:
Noneabort_timeout (float, optional) — Tempo limite para abortar a chamada no thread de controle de falhas. Padrão:
Noneativado (bool, opcional) — Ativa a funcionalidade do wrapper. Quando
False, o invólucro se torna uma passagem. Padrão:Truetrace_file_path (str, opcional) — Caminho para o arquivo de rastreamento para criação de perfil. VizTracer Padrão:
Noneasync_raise_before_abort (bool, opcional) — Ative o aumento antes do aborto no thread de controle de falhas. Padrão:
Trueearly_abort_communicator (bool, opcional) — Aborta o comunicador () antes de abortar o carregador de dados. NCCL/Gloo Padrão:
Falsecheckpoint_manager (Qualquer, opcional) — Gerenciador para lidar com pontos de verificação durante a recuperação. Padrão:
Nonecheck_memory_status (bool, opcional) — Ative a verificação e o registro do status da memória. Padrão:
True
Métodos
def __call__(self, fn)
Envolve uma função para ativar os recursos de reinicialização.
Parâmetros:
fn (Callable) — A função a ser concluída com recursos de reinicialização
Devoluções:
Chamável — Função embrulhada com recursos de reinicialização ou função original se desativada
Exemplo
from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager from hyperpod_checkpointless_training.nemo_plugins.patches import patch_megatron_optimizer from hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector import CheckpointlessCompatibleConnector from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=CheckpointManager(enable_offload=False), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), )def training_function(): # Your training code here pass
Observações
O invólucro
torch.distributedprecisa estar disponívelQuando
enabled=False, o invólucro se torna uma passagem e retorna a função original inalteradaO invólucro mantém recursos globais, como segmentos de monitoramento em todo o ciclo de vida do treinamento
Suporta a VizTracer criação de perfil quando
trace_file_pathé fornecidoIntegra-se ao tratamento HyperPod coordenado de falhas em treinamentos distribuídos
HPCallWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPCallWrapper(wrapper)
Monitora e gerencia o estado de um Bloco de Código de Reinicialização (RCB) durante a execução.
Essa classe trata do ciclo de vida da execução do RCB, incluindo detecção de falhas, coordenação com outras classificações para reinicializações e operações de limpeza. Ele gerencia a sincronização distribuída e garante uma recuperação consistente em todos os processos de treinamento.
Parâmetros
wrapper (HPWrapper) — O wrapper principal contendo configurações globais de recuperação em processo
Atributos.
step_upon_restart (int) — Contador que rastreia as etapas desde a última reinicialização, usado para determinar a estratégia de reinicialização
Métodos
def initialize_barrier()
Aguarde a sincronização da HyperPod barreira após encontrar uma exceção do RCB.
def start_hp_fault_handling_thread()
Inicie a rosca de tratamento de falhas para monitorar e coordenar falhas.
def handle_fn_exception(call_ex)
Processe exceções da função de execução ou do RCB.
Parâmetros:
call_ex (Exception) — Exceção da função de monitoramento
def restart(term_ex)
Execute o manipulador de reinicialização, incluindo finalização, coleta de lixo e verificações de saúde.
Parâmetros:
term_ex (RankShouldRestart) — Exceção de rescisão que aciona a reinicialização
def launch(fn, *a, **kw)
Execute o RCB com o tratamento adequado de exceções.
Parâmetros:
fn (Callable) — Função a ser executada
a — Argumentos da função
kw — Argumentos da palavra-chave da função
def run(fn, a, kw)
Loop de execução principal que lida com reinicializações e sincronização de barreiras.
Parâmetros:
fn (Callable) — Função a ser executada
a — Argumentos da função
kw — Argumentos da palavra-chave da função
def shutdown()
Desligue as linhas de tratamento e monitoramento de falhas.
Observações
Lida automaticamente com
RankShouldRestartexceções para uma recuperação coordenadaGerencia rastreamento de memória e abortos, coleta de lixo durante reinicializações
Suporta estratégias de recuperação em processo e de PLR (Process-Level reinício) com base no tempo de falha
CudaHealthCheck
class hyperpod_checkpointless_training.inprocess.health_check.CudaHealthCheck(timeout=datetime.timedelta(seconds=30))
Garante que o contexto CUDA do processo atual esteja em um estado saudável durante a recuperação do treinamento sem pontos de verificação.
Essa verificação de integridade é sincronizada com a GPU para verificar se o contexto CUDA não está corrompido após uma falha no treinamento. Ele executa operações de sincronização da GPU para detectar quaisquer problemas que possam impedir a retomada bem-sucedida do treinamento. A verificação de integridade é executada depois que os grupos distribuídos são destruídos e a finalização é concluída.
Parâmetros
timeout (datetime.timedelta, opcional) — Duração do tempo limite para operações de sincronização da GPU. Padrão:
datetime.timedelta(seconds=30)
Métodos
__call__(state, train_ex=None)
Execute a verificação de integridade do CUDA para verificar a integridade do contexto da GPU.
Parâmetros:
state (HPState) — HyperPod Estado atual contendo informações classificadas e distribuídas
train_ex (Exceção, opcional) — A exceção de treinamento original que acionou a reinicialização. Padrão:
None
Devoluções:
tuple — Uma tupla contendo
(state, train_ex)inalterado se a verificação de saúde for aprovada
Aumenta:
TimeoutError— Se a sincronização da GPU atingir o tempo limite, indicando um contexto CUDA potencialmente corrompido
Preservação do estado: retorna o estado original e a exceção inalterados se todas as verificações forem aprovadas
Exemplo
import datetime from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # Create CUDA health check with custom timeout cuda_health_check = CudaHealthCheck( timeout=datetime.timedelta(seconds=60) ) # Use with HPWrapper for fault-tolerant training @HPWrapper( health_check=cuda_health_check, enabled=True ) def training_function(): # Your training code here pass
Observações
Usa segmentação para implementar proteção de tempo limite para sincronização de GPU
Projetado para detectar contextos CUDA corrompidos que poderiam impedir a retomada bem-sucedida do treinamento
Deve ser usado como parte do pipeline de tolerância a falhas em cenários de treinamento distribuído
HPAgentK8sAPIFactory
class hyperpod_checkpointless_training.inprocess.train_utils.HPAgentK8sAPIFactory()
Classe de fábrica para criar instâncias HPAgentK8SAPI que se comunicam com HyperPod a infraestrutura para coordenação de treinamento distribuído.
Essa fábrica fornece uma maneira padronizada de criar e configurar objetos HPAgentK8SAPI que lidam com a comunicação entre os processos de treinamento e o plano de controle. HyperPod Ele encapsula a criação do cliente de soquete subjacente e da instância da API, garantindo uma configuração consistente em diferentes partes do sistema de treinamento.
Métodos
__call__()
Crie e retorne uma instância HPAgentK8SAPI configurada para comunicação. HyperPod
Devoluções:
HPAgentK8SAPI — Instância de API configurada para comunicação com a infraestrutura HyperPod
Exemplo
from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck # Create the factory hp_api_factory = HPAgentK8sAPIFactory() # Use with HPWrapper for fault-tolerant training hp_wrapper = HPWrapper( hp_api_factory=hp_api_factory, health_check=CudaHealthCheck(), abort_timeout=60.0, enabled=True ) @hp_wrapper def training_function(): # Your distributed training code here pass
Observações
Projetado para funcionar perfeitamente com a Kubernetes-based infraestrutura HyperPod da. É essencial para o tratamento e a recuperação coordenados de falhas em cenários de treinamento distribuído
CheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.CheckpointManager( enable_checksum=False, enable_offload=False)
Gerencia pontos de verificação na memória e recuperação ponto a ponto para tolerância a falhas sem pontos de verificação em treinamentos distribuídos.
Essa classe fornece a principal funcionalidade para treinamento HyperPod sem pontos de verificação, gerenciando pontos de verificação de NeMo modelos na memória, validando a viabilidade de recuperação e orquestrando a transferência de pontos de verificação ponto a ponto entre classificações saudáveis e fracassadas. Ele elimina a necessidade de disco I/O durante a recuperação, reduzindo significativamente o tempo médio de recuperação (MTTR).
Parâmetros
enable_checksum (bool, opcional) — Ative a validação da soma de verificação do estado do modelo para verificações de integridade durante a recuperação. Padrão:
Falseenable_offload (bool, opcional) — Ative o descarregamento do ponto de verificação da GPU para a memória da CPU para reduzir o uso da memória da GPU. Padrão:
False
Atributos.
global_step (int ou None) — Etapa de treinamento atual associada ao ponto de verificação salvo
rng_states (list ou None) — Estados geradores de números aleatórios armazenados para recuperação determinística
checksum_manager (MemoryChecksumManager) — Gerenciador para validação da soma de verificação do estado do modelo
parameter_update_lock (ParameterUpdateLock) — Bloqueio para coordenar atualizações de parâmetros durante a recuperação
Métodos
save_checkpoint(trainer)
Salve o ponto de verificação do NeMo modelo na memória para uma possível recuperação sem ponto de verificação.
Parâmetros:
trainer (Pytorch_lightning.trainer) — instância do Lightning trainer PyTorch
Observações:
Chamado por CheckpointlessCallback no final do lote ou durante o tratamento de exceções
Cria pontos de recuperação sem I/O sobrecarga de disco
Armazena estados completos do modelo, do otimizador e do agendador
delete_checkpoint()
Exclua o ponto de verificação na memória e execute as operações de limpeza.
Observações:
Limpa dados do ponto de verificação, estados RNG e tensores em cache
Executa a coleta de lixo e a limpeza do cache CUDA
Chamado após uma recuperação bem-sucedida ou quando o ponto de verificação não é mais necessário
try_checkpointless_load(trainer)
Tente uma recuperação sem pontos de verificação carregando o estado das classificações dos pares.
Parâmetros:
trainer (Pytorch_lightning.trainer) — instância do Lightning trainer PyTorch
Devoluções:
dict ou None — Ponto de verificação restaurado se for bem-sucedido, Nenhum se for necessário retornar ao disco
Observações:
Principal ponto de entrada para recuperação sem pontos de verificação
Valida a viabilidade da recuperação antes de tentar a transferência P2P
Sempre limpa os pontos de verificação na memória após a tentativa de recuperação
checkpointless_recovery_feasible(trainer, include_checksum_verification=True)
Determine se a recuperação sem ponto de verificação é possível para o cenário de falha atual.
Parâmetros:
trainer (Pytorch_lightning.trainer) — instância do Lightning trainer PyTorch
include_checksum_verification (bool, opcional) — Se a validação da soma de verificação deve ser incluída. Padrão:
True
Devoluções:
bool — Verdadeiro se a recuperação sem ponto de verificação for viável, falso caso contrário
Critérios de validação:
Consistência global de etapas em níveis saudáveis
Réplicas saudáveis suficientes disponíveis para recuperação
Integridade da soma de verificação do estado do modelo (se ativada)
store_rng_states()
Armazene todos os estados do gerador de números aleatórios para recuperação determinística.
Observações:
Captura os estados RNG do Python NumPy, PyTorch CPU/GPU, e do Megatron
Essencial para manter o determinismo do treinamento após a recuperação
load_rng_states()
Restaure todos os estados de RNG para a continuação da recuperação determinística.
Observações:
Restaura todos os estados RNG armazenados anteriormente
Garante que o treinamento continue com sequências aleatórias idênticas
maybe_offload_checkpoint()
Descarregue o ponto de verificação da GPU para a memória da CPU se o descarregamento estiver ativado.
Observações:
Reduz o uso da memória da GPU para modelos grandes
Só é executado se
enable_offload=TrueMantém a acessibilidade do ponto de verificação para recuperação
Exemplo
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=CheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
Validação: verifica a integridade do ponto de verificação usando somas de verificação (se habilitado)
Observações
Usa primitivas de comunicação distribuída para uma transferência P2P eficiente
Lida automaticamente com conversões de tensor dtype e posicionamento de dispositivos
MemoryChecksumManager— Lida com a validação da integridade do estado do modelo
PEFTCheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.PEFTCheckpointManager( *args, **kwargs)
Gerencia pontos de verificação para PEFT (Parameter-Efficient Fine-Tuning) com base separada e manuseio de adaptador para recuperação otimizada sem pontos de verificação.
Esse gerenciador de pontos de verificação especializado se estende CheckpointManager para otimizar os fluxos de trabalho de PEFT separando os pesos do modelo básico dos parâmetros do adaptador.
Parâmetros
Herda todos os parâmetros de CheckpointManager:
enable_checksum (bool, opcional) — Habilita a validação da soma de verificação do estado do modelo. Padrão:
Falseenable_offload (bool, opcional) — Ativa o descarregamento do ponto de verificação para a memória da CPU. Padrão:
False
Atributos adicionais
params_to_save (set) — Conjunto de nomes de parâmetros que devem ser salvos como parâmetros do adaptador
base_model_weights (dict ou None) — Pesos do modelo base em cache, salvos uma vez e reutilizados
base_model_keys_to_extract (list ou None) — Chaves para extrair tensores do modelo básico durante a transferência P2P
Métodos
maybe_save_base_model(trainer)
Salve os pesos do modelo básico uma vez, filtrando os parâmetros do adaptador.
Parâmetros:
trainer (Pytorch_lightning.trainer) — instância do Lightning trainer PyTorch
Observações:
Salva apenas os pesos do modelo básico na primeira chamada; as chamadas subsequentes são autônomas
Filtra os parâmetros do adaptador para armazenar somente pesos congelados do modelo básico
Os pesos do modelo básico são preservados em várias sessões de treinamento
save_checkpoint(trainer)
Salve o ponto de verificação do modelo do adaptador NeMo PEFT na memória para uma possível recuperação sem ponto de verificação.
Parâmetros:
trainer (Pytorch_lightning.trainer) — instância do Lightning trainer PyTorch
Observações:
Chama automaticamente
maybe_save_base_model()se o modelo base ainda não foi salvoFiltra o ponto de verificação para incluir somente os parâmetros do adaptador e o estado de treinamento
Reduz significativamente o tamanho do ponto de verificação em comparação com os pontos de verificação do modelo completo
try_base_model_checkpointless_load(trainer)
Tente a recuperação sem pontos de verificação de pesos do modelo base PEFT carregando o estado de classificações de pares.
Parâmetros:
trainer (Pytorch_lightning.trainer) — instância do Lightning trainer PyTorch
Devoluções:
dict ou None — Ponto de verificação do modelo básico restaurado se for bem-sucedido, Nenhum se for necessário
Observações:
Usado durante a inicialização do modelo para recuperar os pesos básicos do modelo
Não limpa os pesos do modelo básico após a recuperação (preserva para reutilização)
Otimizado para cenários de recuperação somente com pesos do modelo
try_checkpointless_load(trainer)
Tente a recuperação sem pontos de verificação dos pesos do adaptador PEFT carregando o estado das classificações de pares.
Parâmetros:
trainer (Pytorch_lightning.trainer) — instância do Lightning trainer PyTorch
Devoluções:
dict ou None — Ponto de verificação do adaptador restaurado se for bem-sucedido, Nenhum se for necessário um fallback
Observações:
Recupera somente parâmetros do adaptador, estados do otimizador e agendadores
Carrega automaticamente os estados do otimizador e do agendador após uma recuperação bem-sucedida
Limpa os pontos de verificação do adaptador após a tentativa de recuperação
is_adapter_key(key)
Verifique se a chave de ditado de estado pertence aos parâmetros do adaptador.
Parâmetros:
key (str ou tuple) — Chave de ditado de estado a ser verificada
Devoluções:
bool — Verdadeiro se a chave for o parâmetro do adaptador, Falso se o parâmetro do modelo base
Lógica de detecção:
Verifica se a chave está
params_to_savedefinidaIdentifica chaves contendo “.adapter”. substring
Identifica chaves que terminam com “.adapters”
Para chaves de tupla, verifica se o parâmetro requer gradientes
maybe_offload_checkpoint()
Transfira os pesos do modelo básico da GPU para a memória da CPU.
Observações:
Estende o método principal para lidar com a descarga de peso do modelo básico
Os pesos dos adaptadores geralmente são pequenos e não precisam ser descarregados
Define o sinalizador interno para rastrear o estado de descarga
Observações
Projetado especificamente para Parameter-Efficient Fine-Tuning cenários (LoRa, adaptadores, etc.)
Lida automaticamente com a separação dos parâmetros do modelo básico e do adaptador
Exemplo
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import PEFTCheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=PEFTCheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
CheckpointlessAbortManager
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessAbortManager()
Classe de fábrica para criar e gerenciar composições de componentes de aborto para tolerância a falhas sem pontos de verificação.
Essa classe de utilitário fornece métodos estáticos para criar, personalizar e gerenciar composições de componentes de aborto usadas durante o tratamento de falhas em um treinamento sem pontos de HyperPod verificação. Ele simplifica a configuração de sequências de aborto que lidam com a limpeza de componentes de treinamento distribuídos, carregadores de dados e recursos específicos da estrutura durante a recuperação de falhas.
Parâmetros
Nenhum (todos os métodos são estáticos)
Métodos estáticos
get_default_checkpointless_abort()
Obtenha a instância padrão de composição de aborto contendo todos os componentes de aborto padrão.
Devoluções:
Compose — Instância padrão de aborto composta com todos os componentes de abortamento
Componentes padrão:
AbortTransformerEngine() — Limpa os recursos TransformerEngine
HPCheckpointingAbort() — Lida com a limpeza do sistema de pontos de verificação
HPAbortTorchDistributed() — Aborta operações PyTorch distribuídas
HPDataLoaderAbort() — Pára e limpa os carregadores de dados
create_custom_abort(abort_instances)
Crie uma composição de aborto personalizada somente com as instâncias de aborto especificadas.
Parâmetros:
abort_instances (Abort) — Número variável de instâncias de aborto a serem incluídas na composição
Devoluções:
Compose — Nova instância de aborto composta contendo somente os componentes especificados
Aumenta:
ValueError— Se nenhuma instância de aborto for fornecida
override_abort(abort_compose, abort_type, new_abort)
Substitua um componente de aborto específico em uma instância do Compose por um novo componente.
Parâmetros:
abort_compose (Compose) — A instância original do Compose a ser modificada
abort_type (type) — O tipo de componente de aborto a ser substituído (por exemplo,)
HPCheckpointingAbortnew_abort (Abort) — A nova instância de aborto a ser usada como substituta
Devoluções:
Compose — Nova instância do Compose com o componente especificado substituído
Aumenta:
ValueError— Se abort_compose não tiver o atributo 'instances'
Exemplo
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager # The strategy automatically integrates with HPWrapper @HPWrapper( abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), health_check=CudaHealthCheck(), finalize=CheckpointlessFinalizeCleanup(), enabled=True ) def training_function(): trainer.fit(...)
Observações
As configurações personalizadas permitem um controle preciso sobre o comportamento de limpeza
As operações de aborto são essenciais para a limpeza adequada dos recursos durante a recuperação de falhas
CheckpointlessFinalizeCleanup
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessFinalizeCleanup()
Executa uma limpeza abrangente após a detecção de falhas para se preparar para a recuperação em processo durante o treinamento sem pontos de verificação.
Esse manipulador de finalização executa operações de limpeza específicas da estrutura, incluindo Megatron/TransformerEngine aborto, limpeza de DDP, recarregamento de módulos e limpeza de memória, destruindo referências de componentes de treinamento. Ele garante que o ambiente de treinamento seja redefinido adequadamente para uma recuperação bem-sucedida do processo sem exigir o encerramento total do processo.
Parâmetros
Nenhum
Atributos.
trainer (pytorch_lightning.trainer ou None) — Referência à instância do Lightning trainer PyTorch
Métodos
__call__(*a, **kw)
Execute operações de limpeza abrangentes para a preparação da recuperação durante o processo.
Parâmetros:
a — Argumentos posicionais variáveis (herdados da interface Finalize)
kw — Argumentos de palavras-chave variáveis (herdados da interface Finalize)
Operações de limpeza:
Limpeza do Megatron Framework — Chamadas
abort_megatron()para limpar recursos Megatron-specificTransformerEngine Limpeza — Chamadas
abort_te()para limpar recursos TransformerEngineRoPe Cleanup — Solicita
cleanup_rope()a limpeza dos recursos de incorporação da posição rotativaLimpeza de DDP — Chamadas
cleanup_ddp()para limpar recursos DistributedDataParallelRecarregamento de módulo — Chamadas
reload_megatron_and_te()para recarregar módulos da estruturaLimpeza do módulo Lightning — opcionalmente limpa o módulo Lightning para reduzir a memória da GPU
Limpeza de memória — Destrói as referências dos componentes de treinamento para liberar memória
register_attributes(trainer)
Registre a instância do treinador para uso durante as operações de limpeza.
Parâmetros:
trainer (Pytorch_lightning.trainer) — Instância do Lightning trainer para registrar PyTorch
Integração com CheckpointlessCallback
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( ... finalize=CheckpointlessFinalizeCleanup(), ) def training_function(): trainer.fit(...)
Observações
As operações de limpeza são executadas em uma ordem específica para evitar problemas de dependência
A limpeza da memória usa a introspecção da coleta de lixo para encontrar objetos alvo
Todas as operações de limpeza foram projetadas para serem idempotentes e seguras de serem repetidas.
CheckpointlessMegatronStrategy
class hyperpod_checkpointless_training.nemo_plugins.megatron_strategy.CheckpointlessMegatronStrategy(*args, **kwargs)
NeMo Estratégia Megatron com recursos integrados de recuperação sem pontos de verificação para treinamento distribuído tolerante a falhas.
Observe que o treinamento sem ponto de verificação requer pelo menos 2 num_distributed_optimizer_instances para que haja replicação do otimizador. A estratégia também cuida do registro de atributos essenciais e da inicialização do grupo de processos.
Parâmetros
Herda todos os parâmetros de MegatronStrategy:
Parâmetros de NeMo MegatronStrategy inicialização padrão
Opções de configuração de treinamento distribuído
Configurações de paralelismo do modelo
Atributos.
base_store (torch.distributed.TcpStore ou None) — Armazenamento distribuído para coordenação de grupos de processos
Métodos
setup(trainer)
Inicialize a estratégia e registre os componentes de tolerância a falhas com o treinador.
Parâmetros:
trainer (Pytorch_lightning.trainer) — instância do Lightning trainer PyTorch
Operações de configuração:
Configuração dos pais — MegatronStrategy Configuração dos pais de chamadas
Registro de injeção de falhas — registra HPFaultInjectionCallback ganchos, se presentes
Finalizar o registro — Registra o treinador com os responsáveis pela finalização da limpeza
Registro de aborto — registra o treinador com manipuladores de aborto que o apoiam
setup_distributed()
Inicialize o grupo de processos usando TCPStore com prefixo ou conexão sem raiz.
load_model_state_dict(checkpoint, strict=True)
Carregue o ditado de estado do modelo com compatibilidade de recuperação sem pontos de verificação.
Parâmetros:
checkpoint (Mapping [str, Any]) — Dicionário de pontos de verificação contendo o estado do modelo
strict (bool, opcional) — Se a correspondência de chaves do ditado de estado deve ser rigorosamente aplicada. Padrão:
True
get_wrapper()
Obtenha a HPCallWrapper instância para coordenação de tolerância a falhas.
Devoluções:
HPCallWrapper— A instância do invólucro conectada ao treinador para tolerância a falhas
is_peft()
Verifique se o PEFT (Parameter-Efficient Fine-Tuning) está ativado na configuração de treinamento verificando os retornos de chamada do PEFT
Devoluções:
bool — Verdadeiro se o retorno de chamada PEFT estiver presente, Falso caso contrário
teardown()
Substitua a desmontagem nativa PyTorch do Lightning para delegar a limpeza aos manipuladores de abortamento.
Exemplo
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( checkpoint_manager=checkpoint_manager, enabled=True ) def training_function(): trainer = pl.Trainer(strategy=CheckpointlessMegatronStrategy()) trainer.fit(model, datamodule)
CheckpointlessCallback
class hyperpod_checkpointless_training.nemo_plugins.callbacks.CheckpointlessCallback( enable_inprocess=False, enable_checkpointless=False, enable_checksum=False, clean_tensor_hook=False, clean_lightning_module=False)
Retorno de chamada relâmpago que integra o NeMo treinamento ao sistema de tolerância a falhas do checkpointless training.
Esse retorno de chamada gerencia o rastreamento de etapas, o salvamento de pontos de verificação e a coordenação de atualização de parâmetros para recursos de recuperação em processo. Ele serve como o principal ponto de integração entre os ciclos de treinamento do PyTorch Lightning e os mecanismos de treinamento HyperPod sem pontos de verificação, coordenando as operações de tolerância a falhas em todo o ciclo de vida do treinamento.
Parâmetros
enable_inprocess (bool, opcional) — Ative os recursos de recuperação em processo. Padrão:
Falseenable_checkpointless (bool, opcional) — Habilita a recuperação sem ponto de verificação (obrigatório).
enable_inprocess=TruePadrão:Falseenable_checksum (bool, opcional) — Habilita a validação da soma de verificação do estado do modelo (obrigatório).
enable_checkpointless=TruePadrão:Falseclean_tensor_hook (bool, opcional) — Limpe os ganchos tensores de todos os tensores da GPU durante a limpeza (operação cara). Padrão:
Falseclean_lightning_module (bool, opcional) — Ative a limpeza do módulo Lightning para liberar memória da GPU após cada reinicialização. Padrão:
False
Atributos.
tried_adapter_checkpointless (bool) — Sinalize para rastrear se a restauração sem ponto de verificação do adaptador foi tentada
Métodos
get_wrapper_from_trainer(trainer)
Obtenha a HPCallWrapper instância do treinador para coordenação da tolerância a falhas.
Parâmetros:
trainer (Pytorch_lightning.trainer) — instância do Lightning trainer PyTorch
Devoluções:
HPCallWrapper— A instância de invólucro para operações de tolerância a falhas
on_train_batch_start(trainer, pl_module, batch, batch_idx, *args, **kwargs)
Chamado no início de cada lote de treinamento para gerenciar o rastreamento e a recuperação de etapas.
Parâmetros:
trainer (Pytorch_lightning.trainer) — instância do Lightning trainer PyTorch
pl_module (pytorch_lightning). LightningModule) — Módulo Lightning sendo treinado
batch — Dados atuais do lote de treinamento
batch_idx (int) — Índice do lote atual
args — Argumentos posicionais adicionais
kwargs — Argumentos adicionais de palavras-chave
on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx)
Libere o bloqueio de atualização de parâmetros no final de cada lote de treinamento.
Parâmetros:
trainer (Pytorch_lightning.trainer) — instância do Lightning trainer PyTorch
pl_module (pytorch_lightning). LightningModule) — Módulo Lightning sendo treinado
saídas (STEP_OUTPUT) — Saídas da etapa de treinamento
lote (Qualquer) — Dados atuais do lote de treinamento
batch_idx (int) — Índice do lote atual
Observações:
O tempo de liberação do bloqueio garante que a recuperação sem pontos de verificação possa prosseguir após a conclusão das atualizações dos parâmetros
Só é executado quando ambos
enable_inprocessenable_checkpointlesssão verdadeiros
get_peft_callback(trainer)
Recupere o retorno de chamada PEFT da lista de retorno de chamada do treinador.
Parâmetros:
trainer (Pytorch_lightning.trainer) — instância do Lightning trainer PyTorch
Devoluções:
PEFT ou Nenhuma — Instância de retorno de chamada PEFT se encontrada, Nenhuma caso contrário
_try_adapter_checkpointless_restore(trainer, params_to_save)
Tente fazer uma restauração inútil dos parâmetros do adaptador PEFT.
Parâmetros:
trainer (Pytorch_lightning.trainer) — instância do Lightning trainer PyTorch
params_to_save (set) — Conjunto de nomes de parâmetros para salvar como parâmetros do adaptador
Observações:
Só é executado uma vez por sessão de treinamento (controlado por
tried_adapter_checkpointlessbandeira)Configura o gerenciador de pontos de verificação com informações de parâmetros do adaptador
Exemplo
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager import pytorch_lightning as pl # Create checkpoint manager checkpoint_manager = CheckpointManager( enable_checksum=True, enable_offload=True ) # Create checkpointless callback with full fault tolerance checkpointless_callback = CheckpointlessCallback( enable_inprocess=True, enable_checkpointless=True, enable_checksum=True, clean_tensor_hook=True, clean_lightning_module=True ) # Use with PyTorch Lightning trainer trainer = pl.Trainer( callbacks=[checkpointless_callback], strategy=CheckpointlessMegatronStrategy() ) # Training with fault tolerance trainer.fit(model, datamodule=data_module)
Gerenciamento de memória
clean_tensor_hook: remove os ganchos do tensor durante a limpeza (caro, mas completo)
clean_lightning_module: libera a memória da GPU do módulo Lightning durante as reinicializações
Ambas as opções ajudam a reduzir o consumo de memória durante a recuperação de falhas
Coordena com ParameterUpdateLock para rastreamento seguro de atualizações de parâmetros
CheckpointlessCompatibleConnector
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector.CheckpointlessCompatibleConnector()
PyTorch Conector de ponto de verificação Lightning que integra a recuperação sem ponto de verificação com o carregamento tradicional de pontos de verificação baseado em disco.
Esse conector estende o PyTorch Lightning _CheckpointConnector para fornecer uma integração perfeita entre a recuperação sem ponto de verificação e a restauração padrão do ponto de verificação. Ele tenta primeiro a recuperação sem ponto de verificação e, em seguida, volta para o carregamento do ponto de verificação baseado em disco se a recuperação sem ponto de verificação não for viável ou falhar.
Parâmetros
Herda todos os parâmetros de _ CheckpointConnector
Métodos
resume_start(checkpoint_path=None)
Tente pré-carregar o ponto de verificação com prioridade de recuperação sem ponto de verificação.
Parâmetros:
checkpoint_path (str ou None, opcional) — Caminho para o ponto de verificação do disco para fallback. Padrão:
None
resume_end()
Conclua o processo de carregamento do ponto de verificação e execute as operações de pós-carregamento.
Observações
Estende a
_CheckpointConnectorclasse interna do PyTorch Lightning com suporte de recuperação sem pontos de verificaçãoMantém total compatibilidade com os fluxos de trabalho padrão do PyTorch Lightning checkpoint
CheckpointlessAutoResume
class hyperpod_checkpointless_training.nemo_plugins.resume.CheckpointlessAutoResume()
Estende-se NeMo AutoResume com configuração atrasada para permitir a validação de recuperação sem ponto de verificação antes da resolução do caminho do ponto de verificação.
Essa classe implementa uma estratégia de inicialização em duas fases que permite que a validação da recuperação sem ponto de verificação ocorra antes de retornar ao carregamento tradicional do ponto de verificação baseado em disco. Ele atrasa condicionalmente a AutoResume configuração para evitar a resolução prematura do caminho do ponto de verificação, permitindo primeiro validar se a recuperação ponto CheckpointManager a ponto sem ponto de verificação é viável.
Parâmetros
Herda todos os parâmetros de AutoResume
Métodos
setup(trainer, model=None, force_setup=False)
Adie condicionalmente a AutoResume configuração para permitir a validação de recuperação sem pontos de verificação.
Parâmetros:
trainer (pytorch_lightning.trainer ou lightning.fabric.fabric) — Lightning trainer ou instância do Fabric PyTorch
model (opcional) — Instância do modelo para configuração. Padrão:
Noneforce_setup (bool, opcional) — Se verdadeiro, ignore o atraso e execute a configuração imediatamente. AutoResume Padrão:
False
Exemplo
from hyperpod_checkpointless_training.nemo_plugins.resume import CheckpointlessAutoResume from hyperpod_checkpointless_training.nemo_plugins.megatron_strategy import CheckpointlessMegatronStrategy import pytorch_lightning as pl # Create trainer with checkpointless auto-resume trainer = pl.Trainer( strategy=CheckpointlessMegatronStrategy(), resume=CheckpointlessAutoResume() )
Observações
AutoResume Classe NeMo da Extends com mecanismo de atraso para permitir uma recuperação sem pontos de verificação
Funciona em conjunto com
CheckpointlessCompatibleConnectorpara um fluxo de trabalho de recuperação completo
