As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Carregador de dados mapeado na memória
Outra sobrecarga de reinicialização decorre do carregamento de dados: o cluster de treinamento permanece ocioso enquanto o carregador de dados inicializa, baixa dados de sistemas de arquivos remotos e os processa em lotes.
Para resolver isso, apresentamos o carregador de dados mapeado em memória DataLoader (MMAP), que armazena em cache os lotes pré-buscados na memória persistente, garantindo que eles permaneçam disponíveis mesmo após uma reinicialização induzida por falhas. Essa abordagem elimina o tempo de configuração do carregador de dados e permite que o treinamento seja retomado imediatamente usando lotes em cache, enquanto o carregador de dados reinicializa e busca simultaneamente os dados subsequentes em segundo plano. O cache de dados reside em cada classificação que requer dados de treinamento e mantém dois tipos de lotes: lotes consumidos recentemente que foram usados para treinamento e lotes pré-buscados prontos para uso imediato.
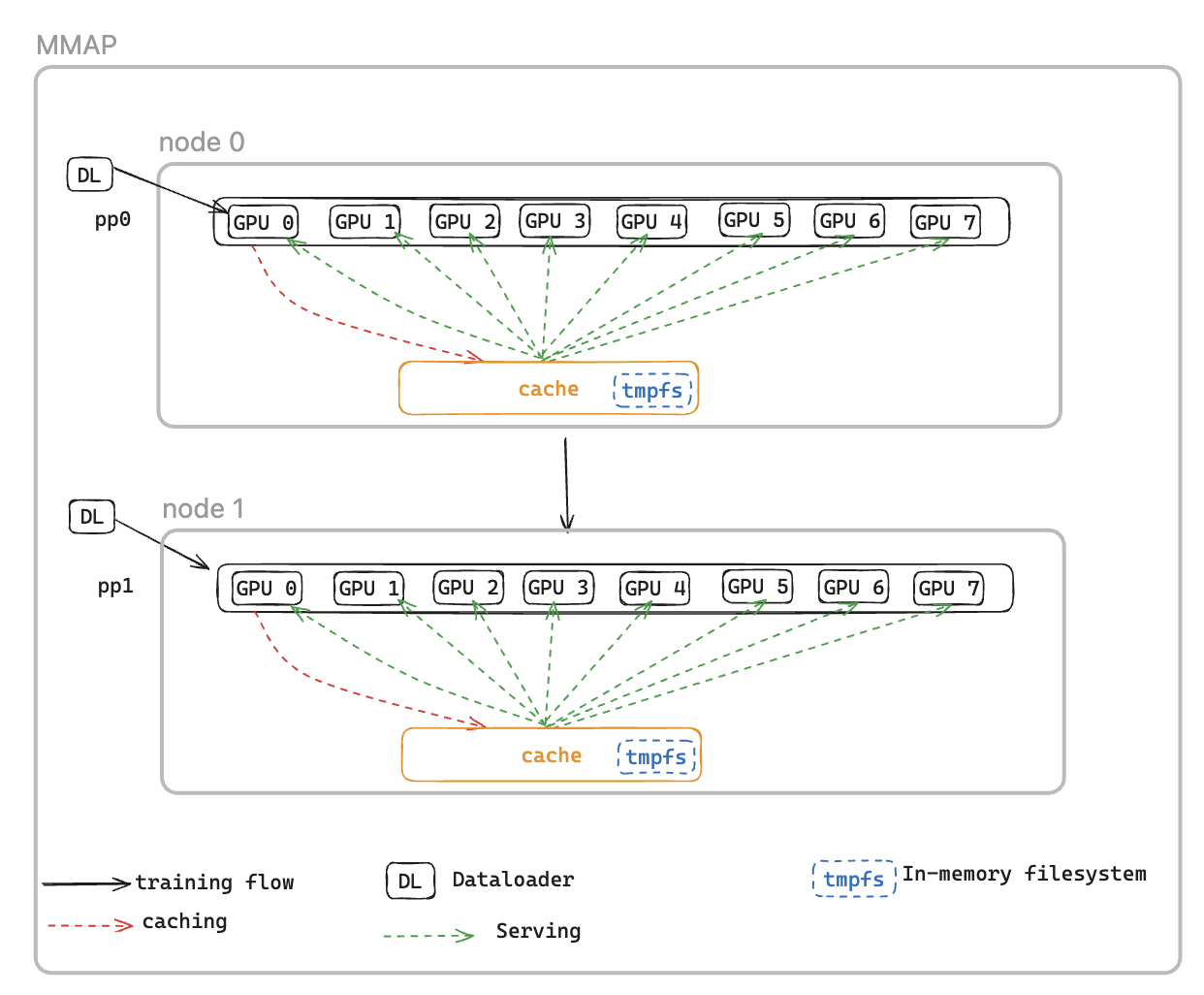
O dataloader MMAP oferece dois recursos a seguir:
Pré-busca de dados - busca e armazena em cache proativamente os dados gerados pelo dataloader
Cache persistente - armazena lotes consumidos e pré-buscados em um sistema de arquivos temporário que sobrevive à reinicialização do processo
Usando o cache, o trabalho de treinamento se beneficiará de:
Espaço de memória reduzido - aproveita a memória mapeada I/O para manter uma única cópia compartilhada dos dados na memória da CPU do host, eliminando cópias redundantes nos processos da GPU (por exemplo, reduz de 8 cópias para 1 em uma instância p5 com 8 GPUs)
Recuperação mais rápida - reduz o tempo médio de reinicialização (MTTR) ao permitir que o treinamento seja retomado imediatamente a partir dos lotes armazenados em cache, eliminando a espera pela reinicialização do carregador de dados e pela geração do primeiro lote
Configurações do MMAP
Para usar o MMAP, basta passar o módulo de dados original para MMAPDataModule
data_module=MMAPDataModule( data_module=MY_DATA_MODULE(...), mmap_config=CacheResumeMMAPConfig( cache_dir=self.cfg.mmap.cache_dir, checkpoint_frequency=self.cfg.mmap.checkpoint_frequency), )
CacheResumeMMAPConfig: os parâmetros do MMAP Dataloader controlam a localização do diretório de cache, os limites de tamanho e a delegação de busca de dados. Por padrão, somente a classificação TP 0 por nó busca dados da fonte, enquanto outras classificações no mesmo grupo de replicação de dados leem do cache compartilhado, eliminando transferências redundantes.
MMAPDataModule: Ele envolve o módulo de dados original e retorna o carregador de dados mmap para treinamento e validação.
Veja o exemplo
Referência de API
CacheResumeMMAPConfig
class hyperpod_checkpointless_training.dataloader.config.CacheResumeMMAPConfig( cache_dir='/dev/shm/pdl_cache', prefetch_length=10, val_prefetch_length=10, lookback_length=2, checkpoint_frequency=None, model_parallel_group=None, enable_batch_encryption=False)
Classe de configuração para a funcionalidade do carregador de dados mapeado na memória (MMAP) em treinamento sem ponto de verificação. HyperPod
Essa configuração permite o carregamento eficiente de dados com recursos de armazenamento em cache e pré-busca, permitindo que o treinamento seja retomado rapidamente após falhas, mantendo lotes de dados em cache em arquivos mapeados na memória.
Parâmetros
-
cache_dir (str, opcional) — Caminho do diretório para armazenar lotes de dados em cache. Padrão: “/dev/shm/pdl_cache”
-
prefetch_length (int, opcional) — Número de lotes a serem pré-buscados com antecedência durante o treinamento. Padrão: 10
-
val_prefetch_length (int, opcional) — Número de lotes a serem pré-buscados com antecedência durante a validação. Padrão: 10
-
lookback_length (int, opcional) — Número de lotes usados anteriormente para manter em cache para possível reutilização. Padrão: 2
-
checkpoint_frequency (int, opcional) — Frequência das etapas de checkpoint do modelo. Usado para otimização do desempenho do cache. Padrão: nenhum
-
model_parallel_group (object, optional) — Grupo de processos para paralelismo de modelos. Se Nenhum, será criado automaticamente. Padrão: nenhum
-
enable_batch_encryption (bool, optional) — Se a criptografia deve ser ativada para dados em lote em cache. Padrão: False
Métodos
create(dataloader_init_callable, parallel_state_util, step, is_data_loading_rank, create_model_parallel_group_callable, name='Train', is_val=False, cached_len=0)
Cria e retorna uma instância configurada do dataloader MMAP.
Parâmetros
-
dataloader_init_callable (Callable) — Função para inicializar o carregador de dados subjacente
-
parallel_state_util (object) — Utilitário para gerenciar o estado paralelo entre processos
-
step (int) — A etapa de dados a partir da qual continuar durante o treinamento
-
is_data_loading_rank (Callable) — Função que retorna True se a classificação atual deve carregar dados
-
create_model_parallel_group_callable (Callable) — Função para criar um grupo de processos paralelos do modelo
-
name (str, opcional) — Identificador de nome para o carregador de dados. Padrão: “Train”
-
is_val (bool, optional) — Se este é um carregador de dados de validação. Padrão: False
-
cached_len (int, opcional) — Tamanho dos dados em cache se forem retomados do cache existente. Padrão: 0
Retorna CacheResumePrefetchedDataLoader ou CacheResumeReadDataLoader — Instância configurada do carregador de dados MMAP
Aumenta ValueError se o parâmetro da etapa forNone.
Exemplo
from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig # Create configuration config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100, enable_batch_encryption=False ) # Create dataloader dataloader = config.create( dataloader_init_callable=my_dataloader_init, parallel_state_util=parallel_util, step=current_step, is_data_loading_rank=lambda: rank == 0, create_model_parallel_group_callable=create_mp_group, name="TrainingData" )
Observações
-
O diretório de cache deve ter espaço suficiente e I/O desempenho rápido (por exemplo,/dev/shm para armazenamento na memória).
-
checkpoint_frequencyA configuração melhora o desempenho do cache ao alinhar o gerenciamento do cache com o ponto de verificação do modelo -
Para validação dataloaders (
is_val=True), a etapa é redefinida para 0 e a inicialização a frio é forçada -
Diferentes implementações de carregadores de dados são usadas com base no fato de a classificação atual ser responsável pelo carregamento de dados
MMAPDataModule
class hyperpod_checkpointless_training.dataloader.mmap_data_module.MMAPDataModule( data_module, mmap_config, parallel_state_util=MegatronParallelStateUtil(), is_data_loading_rank=None)
Um DataModule wrapper PyTorch Lightning que aplica recursos de carregamento de dados mapeados em memória (MMAP) aos treinamentos existentes para fins de verificação sem necessidade de verificação. DataModules
Essa classe agrupa um PyTorch Lightning existente DataModule e o aprimora com a funcionalidade MMAP, permitindo um armazenamento eficiente de dados em cache e uma recuperação rápida durante falhas de treinamento. Ele mantém a compatibilidade com a DataModule interface original enquanto adiciona recursos de treinamento sem pontos de verificação.
Parâmetros
- módulo de dados (pl. LightningDataModule)
O subjacente DataModule para embrulhar (por exemplo, LLMDataModule)
- mmap_config (MmapConfig)
O objeto de configuração MMAP que define o comportamento e os parâmetros de armazenamento em cache
parallel_state_util(MegatronParallelStateUtil, opcional)Utilitário para gerenciar estados paralelos em processos distribuídos. Padrão: MegatronParallelStateUtil ()
is_data_loading_rank(Pode ser chamado, opcional)Função que retorna True se a classificação atual precisar carregar dados. Se Nenhum, o padrão é parallel_state_util.is_tp_0. Padrão: nenhum
Atributos.
global_step(int)Etapa de treinamento global atual, usada para retomar a partir dos postos de controle
cached_train_dl_len(int)Tamanho em cache do carregador de dados de treinamento
cached_val_dl_len(int)Tamanho em cache do carregador de dados de validação
Métodos
setup(stage=None)
Configure o módulo de dados subjacente para o estágio de treinamento especificado.
stage(str, opcional)Estágio do treinamento ('ajuste', 'validação', 'teste' ou 'previsão'). Padrão: nenhum
train_dataloader()
Crie o treinamento DataLoader com a embalagem MMAP.
Retornos: DataLoader — MMAP-wrapped treinamento DataLoader com recursos de armazenamento em cache e pré-busca
val_dataloader()
Crie a validação DataLoader com o empacotamento MMAP.
Retorna: DataLoader — MMAP-wrapped validação DataLoader com recursos de armazenamento em cache
test_dataloader()
Crie o teste DataLoader se o módulo de dados subjacente o suportar.
Retorna: DataLoader ou Nenhum — Teste DataLoader do módulo de dados subjacente, ou Nenhum se não for suportado
predict_dataloader()
Crie a previsão DataLoader se o módulo de dados subjacente a suportar.
Retorna: DataLoader ou Nenhum — Preveja a DataLoader partir do módulo de dados subjacente, ou Nenhum se não for suportado
load_checkpoint(checkpoint)
Carregue as informações do ponto de verificação para retomar o treinamento a partir de uma etapa específica.
- ponto de verificação (ditado)
Dicionário de pontos de verificação contendo a chave 'global_step'
get_underlying_data_module()
Obtenha o módulo de dados empacotado subjacente.
Devoluções: pl. LightningDataModule — O módulo de dados original que foi empacotado
state_dict()
Obtenha o dicionário estadual do MMAP DataModule para pontos de verificação.
Retorna: dict — Dicionário contendo comprimentos de carregadores de dados em cache
load_state_dict(state_dict)
Carregue o dicionário de estado para restaurar o DataModule estado do MMAP.
state_dict(ditado)Dicionário de estado a ser carregado
Properties
data_sampler
Exponha o amostrador de dados do módulo de dados subjacente à estrutura. NeMo
Retorna: objeto ou Nenhum — O amostrador de dados do módulo de dados subjacente
Exemplo
from hyperpod_checkpointless_training.dataloader.mmap_data_module import MMAPDataModule from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig from my_project import MyLLMDataModule # Create MMAP configuration mmap_config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100 ) # Create original data module original_data_module = MyLLMDataModule( data_path="/path/to/data", batch_size=32 ) # Wrap with MMAP capabilities mmap_data_module = MMAPDataModule( data_module=original_data_module, mmap_config=mmap_config ) # Use in PyTorch Lightning Trainer trainer = pl.Trainer() trainer.fit(model, data=mmap_data_module) # Resume from checkpoint checkpoint = {"global_step": 1000} mmap_data_module.load_checkpoint(checkpoint)
Observações
O wrapper delega a maior parte do acesso aos atributos ao módulo de dados subjacente usando __getattr__
Somente as classificações de carregamento de dados realmente inicializam e usam o módulo de dados subjacente; outras classificações usam carregadores de dados falsos
Os comprimentos do carregador de dados em cache são mantidos para otimizar o desempenho durante a retomada do treinamento
