As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
GitHub repositórios
Para iniciar um trabalho de treinamento, você utiliza arquivos de dois GitHub repositórios distintos:
Esses repositórios contêm componentes essenciais para iniciar, gerenciar e personalizar os processos de treinamento de grandes modelos de linguagem (LLM). Você usa os scripts dos repositórios para configurar e executar tarefas de treinamento para seus LLMs.
HyperPod repositório de receitas
Use o repositório de SageMaker HyperPod receitas
-
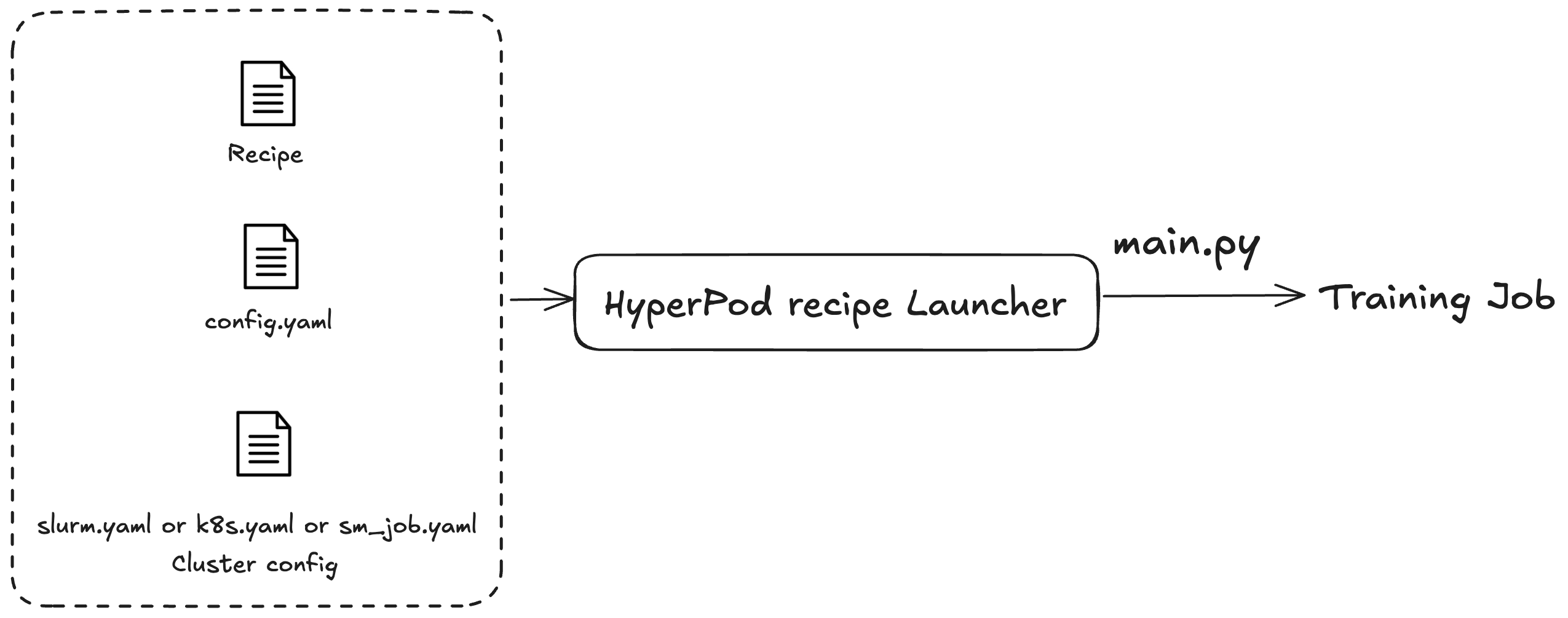
main.py: esse arquivo serve como o ponto de entrada principal para iniciar o processo de envio de um trabalho de treinamento para um cluster ou um trabalho de SageMaker treinamento. -
launcher_scripts: esse diretório contém uma coleção de scripts comumente usados, projetados para facilitar o processo de treinamento de vários grandes modelos de linguagem (LLMs). -
recipes_collection: essa pasta contém uma compilação de fórmulas predefinidas de LLM fornecidas pelos desenvolvedores. Os usuários podem utilizar essas fórmulas com seus próprios dados personalizados para treinar modelos de LLM adaptados às suas necessidades específicas.
Você usa as SageMaker HyperPod receitas para iniciar trabalhos de treinamento ou de ajuste fino. Independentemente do cluster que você está usando, o processo de envio da tarefa é o mesmo. Por exemplo, você pode usar o mesmo script para enviar um trabalho a um cluster do Slurm ou do Kubernetes. O inicializador envia uma tarefa de treinamento com base em três arquivos de configuração:
-
Configuração geral (
config.yaml): inclui configurações comuns, como os parâmetros padrão ou variáveis de ambiente usadas na tarefa de treinamento. -
Configuração de cluster (cluster): para tarefas de treinamento que usam somente clusters. Se você estiver enviando uma tarefa de treinamento a um cluster do Kubernetes, talvez seja necessário especificar informações como volume, rótulo ou política de reinicialização. Para clusters do Slurm, talvez seja necessário especificar o nome da tarefa do Slurm. Todos os parâmetros estão relacionados ao cluster específico que você está usando.
-
Fórmula (fórmulas): as fórmulas contêm as configurações da tarefa de treinamento, como tipos de modelo, grau de fragmentação ou caminhos do conjunto de dados. Por exemplo, você pode especificar o Llama como seu modelo de treinamento e treiná-lo usando técnicas de paralelismo de dados ou de modelos, como paralelismo de dados totalmente fragmentados (FSDP) em oito máquinas. Você também pode especificar diferentes frequências ou caminhos de pontos de verificação para a tarefa de treinamento.
Depois de especificar uma fórmula, você executa o script do inicializador por meio do ponto de entrada main.py para especificar uma tarefa de treinamento completa em um cluster com base nas configurações. Para cada fórmula usada, há scripts de shell associados localizados na pasta launch_scripts. Esses exemplos orientam você a enviar e iniciar tarefas de treinamento. A figura a seguir ilustra como um lançador de SageMaker HyperPod receitas envia um trabalho de treinamento para um cluster com base no anterior. Atualmente, o lançador de SageMaker HyperPod receitas é construído sobre o Nvidia NeMo Framework Launcher. Para obter mais informações, consulte o Guia do NeMo Launcher
HyperPod repositório de adaptadores de receitas
O adaptador SageMaker HyperPod de treinamento é uma estrutura de treinamento. Você pode usá-lo para gerenciar todo o ciclo de vida de suas tarefas de treinamento. Use o adaptador para distribuir o pré-treinamento ou o ajuste fino de seus modelos em várias máquinas. O adaptador usa diferentes técnicas de paralelismo para distribuir o treinamento. Ele também lida com a implementação e o gerenciamento do salvamento de pontos de verificação. Consulte mais detalhes em Configurações avançadas.
Use o repositório do adaptador de SageMaker HyperPod receita
-
src: Esse diretório contém a implementação do treinamento do Large-scale Language Model (LLM), abrangendo vários recursos, como paralelismo de modelos, treinamento de precisão mista e gerenciamento de pontos de verificação. -
examples: esta pasta fornece uma coleção de exemplos que demonstram como criar um ponto de entrada para treinar um LLM, servindo como um guia prático para os usuários.
