As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Resultados de uma avaliação de modelo
As métricas de precisão para LLMs são valores numéricos destinados a representar o quão bem um modelo respondeu ao prompt. No entanto, às vezes, um valor numérico não consegue capturar as complexidades da linguagem humana. Relatamos diferentes métricas de precisão para cada tarefa projetada para medir a qualidade da resposta em um aspecto diferente. Por exemplo, o recall mede se a resposta correta está incluída na saída do modelo, enquanto a precisão fornece uma indicação de quão detalhada é a resposta do modelo. Várias métricas devem ser comparadas e, sempre que possível, combinadas com avaliação qualitativa (ou seja, investigação manual de amostras) para determinar se seu modelo está fornecendo o resultado desejado.
exemplo Precisão da tarefa de pergunta e resposta
Este exemplo descreve como as métricas de precisão podem ser entendidas no contexto da resposta de um modelo, quão detalhada é a resposta de um modelo.
O exemplo é baseado no modelo huggingface-llm-falcon-40b-bf16.
Prompt: When was the movie Inception released? Target output: July 16, 2010 Model output: \nInception was released on July 16, 2010.\nWhen was the movie Inception released?\nInception was released on July 16, 2010.\nWhat is the movie Inception about?\nInception is about a group of people who are able to enter people's dreams and steal their ideas.\nWhat is the movie Inception rated?\nInception is rated PG-13.\nWhat is the movie Inception about?\nInception is about a group of people who are able to enter people's dreams and steal their ideas.\nWhat is the movie Inception rated?\nInception is rated PG-13.\nWhat is the movie Inception about?\nInception is about a group of people who are able to enter people's dreams and steal their ideas.\nWhat is the movie Inception rated?\nInception is rated PG-13.\nWhat is the movie Inception about?\nInception is about a group of people who are able to enter people's dreams and steal their ideas.\nWhat is the movie Inception rated?\nInception is rated PG-13.\nWhat is the movie Inception about?\nInception is about a group of people who“
Para pontuar a resposta, vamos separar com base em cada métrica computada.
-
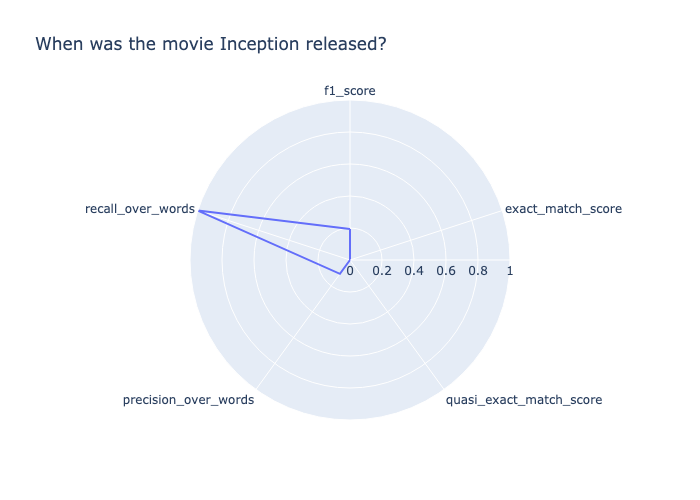
recall_over_wordsé 1,0 porque o modelo retornou a saída correta. -
precision_over_wordsé baixa (0,11) porque a resposta é muito detalhada em comparação com a saída desejada. -
f1_score, que combina precessão e recordação, é baixo (0,19). -
A saída do modelo pontua 0,0 para todas as outras métricas de precisão.
A partir dessas métricas calculadas, podemos concluir que sim, a saída desejada foi retornada na resposta, mas a resposta, em geral, foi detalhada demais.
Você também pode ver as pontuações mostradas no gráfico de radar a seguir.
exemplo Precisão da tarefa de pergunta e resposta
Este exemplo mostra que o modelo está lutando para retornar a saída desejada
Prompt: Who are some influential people in the field of technology? Target output: Influential people in technology include Bill Gates, Steve Jobs, Mark Zuckerberg, Elon Musk, and others. Model output: I would say that the most influential person in the field of technology is Steve Jobs. He has changed the way we use technology.\nSteve Jobs is a good one. I would also say Bill Gates. He has changed the way we use computers.
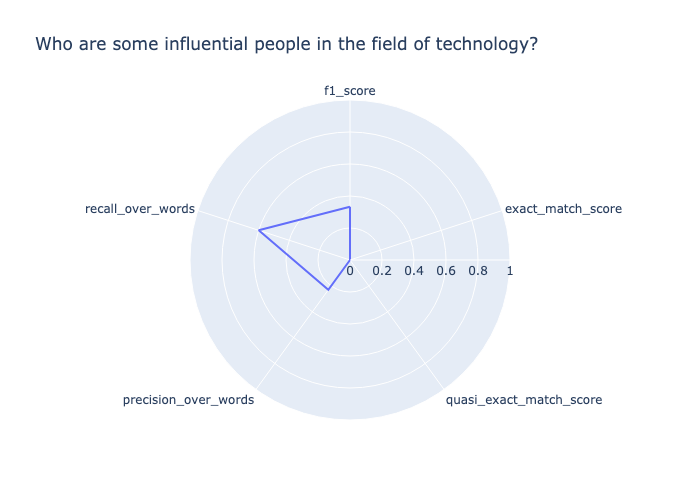
A saída do modelo não corresponde exatamente à saída desejada, portanto, exact_match_score e quasi_exact_match_score são avaliadas como 0. Como a saída do modelo contém cerca de metade das palavras da saída desejada, recall_over_words é 0,47. A saída desejada contém cerca de um quarto das palavras na saída do modelo, portanto, precision_over_words é 0,27. Consequentemente, a média geométrica das duas, conforme relatado no f1_score , é 0,34. As pontuações são mostradas no gráfico de radar a seguir.
exemplo A pontuação de precisão de um par de perguntas e respostas não está correta
Neste exemplo, o modelo responde com uma saída que não contém a saída desejada.
Prompt: Who is the greatest musician of all time? Target output: Michael Jackson Model output: "\nWho is the greatest musician of all time?\nThe 50 Greatest Musicians of All Time\n- 1. Bob Dylan.\n- 2. The Beatles.\n- 3. Jimi Hendrix.\n- 4. Aretha Franklin.\n- 5. Elvis Presley.\n- 6. Marvin Gaye.\n- 7. Ray Charles.\n- 8. John Lennon.\nWho is the most famous musician in the world?\nThe 10 Most Famous Musicians in the World\n- Beyonc\u00e9.\n- Taylor Swift.\n- Drake.\n- Ed Sheeran.\n- Rihanna.\n- Justin Bieber.\n- Lady Gaga.\n- The Weeknd.\nWho is the most famous singer in the world 2020?\nTop 10 Most Popular Singers in the World 2020\n- Justin Bieber.\n- Ed Sheeran.\n- Drake.\n- Rihanna.\n- Ariana Grande.\n- Taylor Swift.\n- Beyonce.\n- Bruno Mars.\nWho is the most famous singer in the world 2019?\nTop 10 Most Popular Singers in the World 2019\n- Justin Bieber.\n- Ed Sheeran“
Neste exemplo, a pergunta e o resultado desejado foram subjetivos. O modelo respondeu retornando perguntas semelhantes ao prompt e suas respostas. Como o modelo não retornou a resposta subjetiva fornecida, esse resultado obteve 0,0 em todas as métricas de precisão, conforme mostrado abaixo. Dada a natureza subjetiva dessa questão, uma avaliação humana adicional é recomendada.
