As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Expansão na nuvem para computação de pesquisa
O grupo de computação de pesquisa de uma instituição de pesquisa R1 (Doctoral Universities – Very High Research Activity) nos EUA já executava clusters de computação de alta performance (HPC) on-premises com o agendador Slurm há muitos anos. Com exceção de algumas semanas de manutenção programada, os clusters estavam funcionando com uma taxa de utilização de 80 a 95%, com a maioria das filas cheias.
O número crescente de atividades de pesquisa na instituição introduziu desafios de capacidade e capacitação. Alguns pesquisadores de alto nível estavam sempre realizando simulações de longa duração em determinadas filas, o que aumentava o tempo de espera de outros usuários. O corpo docente recém-contratado precisou executar um grande número de simulações climáticas para criar um novo modelo de inteligência artificial e machine learning (IA/ML) para previsão do tempo, mas exigia mais capacidade do que a disponível. O grupo de pesquisa em computação também estava recebendo mais solicitações para as unidades de processamento gráfico (GPUs) mais recentes para treinar modelos de aprendizado de máquina. Mesmo com o financiamento para novos GPUs, a equipe precisaria esperar meses para obter aprovação para expandir o espaço de rack no data center.
Muitos pesquisadores não estavam dispostos a excluir dados antigos, então a capacidade de armazenamento local também era um desafio. Era necessária uma opção de armazenamento mais escalável e de longo prazo para liberar armazenamento valioso e de alta performance on-premises.
A nuvem aborda esses desafios com soluções híbridas de computação e armazenamento que permitem que você expanda a computação de pesquisa para a nuvem quando a capacidade on-premises não é suficiente. O diagrama de arquitetura a seguir ilustra algumas abordagens de expansão de computação e armazenamento, usando ferramentas como AWS ParallelCluster
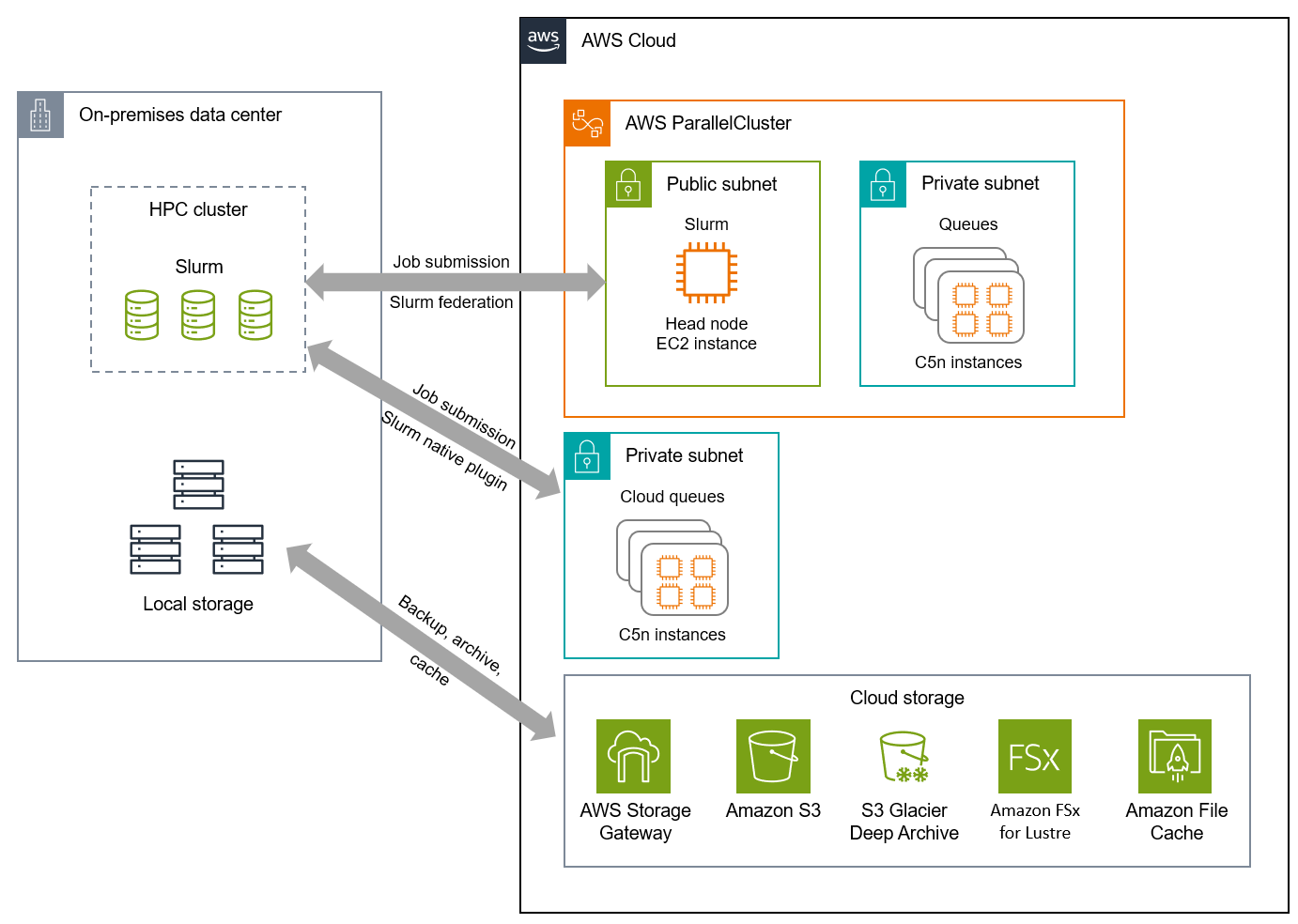
Essa arquitetura segue estas recomendações:
-
Selecione um provedor de nuvem primário e estratégico.Essa arquitetura usa um provedor de nuvem primário para evitar ser restringida pela abordagem do mínimo denominador comum. Dessa forma, a instituição pode aproveitar a inovação e os serviços nativos de computação e armazenamento que o provedor de nuvem primário oferece. A equipe de computação de pesquisa pode se concentrar na otimização das workloads no ambiente fornecido pelo provedor de nuvem primário, e não em como trabalhar em diferentes ambientes de nuvem.
-
Estabeleça requisitos de segurança e governança para cada provedor de serviços de nuvem.Cada serviço e ferramenta usados nessa arquitetura podem ser configurados para atender aos requisitos de segurança e governança da equipe de computação de pesquisa, incluindo conectividade privada, criptografia de dados em trânsito e em repouso, registro em log de atividades e muito mais.
-
Adote serviços gerenciados nativos da nuvem sempre que for possível e prático. Essa arquitetura fornece a capacidade de usar serviços gerenciados de armazenamento e computação, bem como ferramentas para simplificar o gerenciamento de clusters. Dessa forma, a equipe de computação de pesquisa não precisa se preocupar com o gerenciamento de clusters ou da infraestrutura subjacente por conta própria, o que pode ser complexo e demorado.
-
Implemente arquiteturas híbridas quando os investimentos on-premises existentes justificarem o uso contínuo. Essa arquitetura permite que a instituição continue usando seus recursos on-premises e aproveite a nuvem para aumentar a capacidade e expandir a capacidade de computação sob demanda. Com a nuvem, a instituição pode dimensionar corretamente o tipo de computação para maximizar o preço-performance e acessar a tecnologia mais recente para promover a inovação sem um grande investimento inicial em hardware on-premises adicional.
