As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Documentação do conhecimento institucional usando entradas de voz por meio do Amazon Bedrock e do Amazon Transcribe
Praveen Kumar Jeyarajan, Jundong Qiao, Rajiv Upadhyay e Megan Wu, Amazon Web Services
Resumo
Capturar o conhecimento institucional é fundamental para garantir o sucesso e a resiliência organizacional. O conhecimento institucional representa a sabedoria coletiva, as percepções e as experiências acumuladas pelos colaboradores ao longo do tempo, frequentemente de forma tácita e transmitidas informalmente. Essa riqueza de informações abrange abordagens únicas, práticas recomendadas e soluções para problemas complexos que podem não estar documentados em outros locais. Ao formalizar e documentar esse conhecimento, as empresas podem preservar a memória institucional, promover a inovação, aprimorar os processos de tomada de decisão e acelerar a curva de aprendizado dos novos colaboradores. Além disso, essa prática promove a colaboração, capacita os indivíduos e cultiva uma cultura de melhoria contínua. Por fim, aproveitar o conhecimento institucional ajuda as empresas a usar seu bem mais valioso, a inteligência coletiva de sua força de trabalho, para enfrentar desafios, impulsionar o crescimento e manter a vantagem competitiva em ambientes de negócios dinâmicos.
Esse padrão explica como capturar o conhecimento institucional por meio de gravações de voz de colaboradores experientes. Ele usa o Amazon Transcribe e o Amazon Bedrock para documentação e verificação sistemáticas. Ao documentar esse conhecimento informal, você pode preservá-lo e compartilhá-lo com as futuras gerações de colaboradores. Essa iniciativa contribui para a excelência operacional e aprimora a eficácia dos programas de treinamento, incorporando o conhecimento prático adquirido por meio da experiência direta.
Pré-requisitos e limitações
Pré-requisitos
Uma conta AWS ativa
Docker, instalado
AWS Cloud Development Kit (AWS CDK), na versão 2.114.1 ou em versões posteriores, instalado e inicializado nas regiões da AWS
us-east-1ouus-west-2Kit de Ferramentas CDK da AWS, na versão 2.114.1 ou em versões posteriores, instalado
AWS Command Line Interface (AWS CLI), instalada e configurada
Python, versão 3.12 ou versões posteriores, instalado
Permissões para criar recursos do Amazon Transcribe, do Amazon Bedrock, do Amazon Simple Storage Service (Amazon S3) e do AWS Lambda
Limitações
Essa solução é implantada em uma única conta da AWS.
Esta solução pode ser implantada somente nas regiões da AWS nas quais o Amazon Bedrock e o Amazon Transcribe estão disponíveis. Para obter informações sobre a disponibilidade, consulte a documentação do Amazon Bedrock e do Amazon Transcribe.
Os arquivos de áudio devem estar em um formato compatível com o Amazon Transcribe. Para obter uma lista dos formatos compatíveis, consulte Formatos de mídia na documentação Transcribe.
Versões do produto
AWS SDK para Python (Boto3), na versão 1.34.57 ou em versões posteriores
LangChain versão 0.1.12 ou posterior
Arquitetura
A arquitetura representa um fluxo de trabalho com tecnologia sem servidor na AWS. O AWS Step Functions realiza a orquestração de funções do Lambda para o processamento de áudio, análise de texto e geração de documentos. O diagrama apresentado a seguir ilustra o fluxo de trabalho do Step Functions, também conhecido como máquina de estado.
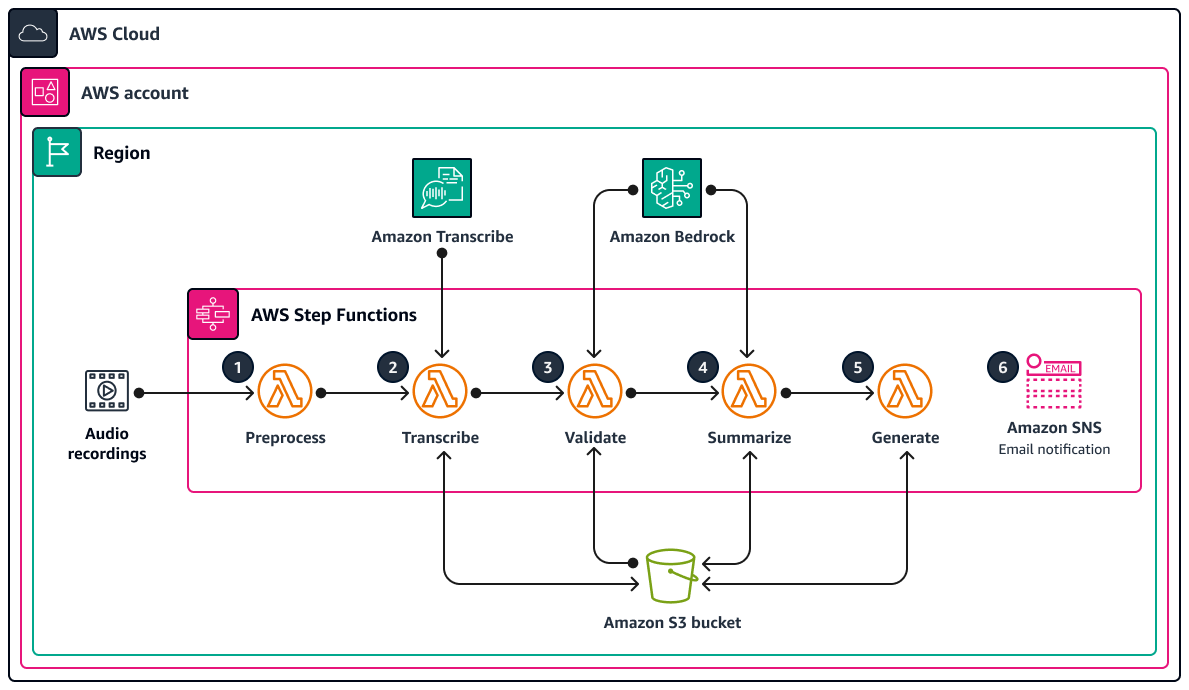
Cada etapa da máquina de estado é executada por uma função do Lambda distinta. A seguir, apresentamos as etapas que fazem parte do processo de geração de documentos:
A função do Lambda
preprocessvalida a entrada transferida para o Step Functions e lista todos os arquivos de áudio presentes no caminho da pasta URI do Amazon S3 fornecido. As funções do Lambda subsequentes no fluxo de trabalho usam a lista de arquivos para validar, resumir e gerar o documento.A função do Lambda
transcribeusa o Amazon Transcribe para converter arquivos de áudio em transcrições de texto Essa função do Lambda é responsável por iniciar o processo de transcrição e transformar com precisão a fala em texto, que será armazenado para processamento posterior.A função do Lambda
validateanalisa as transcrições de texto, verificando a relevância das respostas em relação às perguntas iniciais. Ao usar um grande modelo de linguagem (LLM) por meio do Amazon Bedrock, as respostas são identificadas e distinguidas no tópico de respostas fora de contexto.A função do Lambda
summarizeusa o Amazon Bedrock para gerar um resumo coerente e conciso das respostas pertinentes ao contexto.A função do Lambda
generateorganiza os resumos em um documento bem estruturado. Essa função pode formatar o documento de acordo com modelos definidos previamente e incluir qualquer conteúdo ou dado adicional necessário.Se alguma das funções do Lambda falhar, você receberá uma notificação por e-mail do Amazon Simple Notification Service (Amazon SNS).
Durante todo esse processo, o AWS Step Functions garante que cada função do Lambda seja iniciada na sequência correta. Esta máquina de estado conta com capacidade de processamento paralelo para aumentar a eficiência. Um bucket do Amazon S3 funciona como o repositório central de armazenamento, apoiando o fluxo de trabalho ao gerenciar os diversos formatos de mídia e os documentos envolvidos.
Ferramentas
Serviços da AWS
O Amazon Bedrock é um serviço totalmente gerenciado que disponibiliza modelos básicos de alto desempenho (FMs) das principais startups de IA e da Amazon para seu uso por meio de uma API unificada.
O AWS Lambda é um serviço de computação que ajuda você a executar código sem exigir provisionamento ou gerenciamento de servidores. Ele executa o código somente quando necessário e dimensiona automaticamente, assim, você paga apenas pelo tempo de computação usado.
O Amazon Simple Notification Service (Amazon SNS) ajuda você a coordenar e gerenciar a troca de mensagens entre publicadores e clientes, incluindo servidores web e endereços de e-mail.
O Amazon Simple Storage Service (Amazon S3) é um serviço de armazenamento de objetos baseado na nuvem que ajuda você a armazenar, proteger e recuperar qualquer quantidade de dados.
O AWS Step Functions é um serviço de orquestração com tecnologia sem servidor que permite combinar funções do AWS Lambda e outros serviços da AWS para criar aplicações essenciais aos negócios.
O Amazon Transcribe é um serviço de reconhecimento de fala automático que emprega modelos de machine learning para converter áudio em texto.
Outras ferramentas
LangChain
é uma estrutura para o desenvolvimento de aplicativos que são alimentados por grandes modelos de linguagem (LLMs).
Repositório de código
O código desse padrão está disponível no GitHub genai-knowledge-capture
O repositório de código contém os seguintes arquivos e pastas:
Pasta
assets: os recursos estáticos da solução, como o diagrama da arquitetura e o conjunto de dados públicoPasta
code/lambdas: o código Python para todas as funções do LambdaPasta
code/lambdas/generate: o código Python que gera um documento com base nos dados resumidos no bucket do S3Pasta
code/lambdas/preprocess: o código Python que processa as entradas para a máquina de estado do Step FunctionsPasta
code/lambdas/summarize: o código Python que resume os dados transcritos usando o serviço Amazon BedrockPasta
code/lambdas/transcribe: o código Python que converte dados de fala (arquivo de áudio) em texto usando o Amazon TranscribePasta
code/lambdas/validate: o código Python que valida se todas as respostas se referem ao mesmo tópico
code/code_stack.py: o arquivo Python do constructo do AWS CDK usado para criar recursos da AWSapp.py: o arquivo Python da aplicação do AWS CDK usada para implantar recursos da AWS na conta da AWS de destinorequirements.txt: a lista de todas as dependências do Python que devem ser instaladas para o AWS CDKcdk.json: o arquivo de entrada que fornece os valores necessários para criar recursos
Práticas recomendadas
O exemplo de código fornecido é apenas para fins proof-of-concept (PoC) ou piloto. Se você pretende implantar a solução para a produção, siga as seguintes práticas recomendadas:
Habilitar o registro em log de acesso do Amazon S3
Habilitar os logs de fluxo da VPC
Épicos
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Exporte variáveis para a conta e para a região da AWS. | Para fornecer credenciais da AWS ao AWS CDK usando variáveis de ambiente, execute os comandos apresentados a seguir.
| AWS DevOps, DevOps engenheiro |
Configure o perfil nomeado da AWS CLI. | Para configurar o perfil nomeado da AWS CLI para a conta, siga as instruções apresentadas em Configurações do arquivo de configuração e credenciais. | AWS DevOps, DevOps engenheiro |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Clone o repositório na sua estação de trabalho local. | Para clonar o genai-knowledge-capture
| AWS DevOps, DevOps engenheiro |
(Opcional) Substitua os arquivos de áudio. | Para personalizar a aplicação de amostra e incorporar seus próprios dados, faça o seguinte:
| AWS DevOps, DevOps engenheiro |
Configure o ambiente virtual do Python. | Para ativar o ambiente virtual do Python, execute os comandos a seguir.
| AWS DevOps, DevOps engenheiro |
Sintetize o código do AWS CDK. | Para converter o código em uma configuração de CloudFormation pilha da AWS, execute o comando a seguir.
| AWS DevOps, DevOps engenheiro |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Providencie o acesso ao modelo de base. | Habilite o acesso ao modelo Anthropic Claude 3 Sonnet para a sua conta da AWS. Para obter instruções, consulte Adicionar acesso ao modelo na documentação do Bedrock. | AWS DevOps |
Implante recursos na conta. | Para implantar recursos na conta da AWS usando o AWS CDK, faça o seguinte:
| AWS DevOps, DevOps engenheiro |
Assine o tópico do Amazon SNS. | Para se tornar assinante do tópico do Amazon SNS a fim de receber notificações, faça o seguinte:
| AWS geral |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Execute uma máquina de estado. |
| Desenvolvedor de aplicativos, AWS geral |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Remova os recursos da AWS. | Após testar a solução, limpe os recursos:
| AWS DevOps, DevOps engenheiro |
Recursos relacionados
Documentação da AWS
Recursos do Amazon Bedrock:
Recursos do AWS CDK:
Recursos do AWS Step Functions:
Outros recursos
