As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
# O que é o Amazon Data Firehose?
O Amazon Data Firehose é um serviço totalmente gerenciado para fornecer [dados de streaming](https://aws.amazon.com/streaming-data/) em tempo real para destinos como Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon Service, Amazon Serverless, Splunk OpenSearch , Apache Iceberg Tables e qualquer endpoint HTTP personalizado ou endpoints HTTP de propriedade de provedores de OpenSearch serviços terceirizados compatíveis, incluindo LogicMonitor Datadog, Dynatrace, Moneberg MongoDB, New Relic, Coralogix e Elastic. Com o Amazon Data Firehose, você não precisa escrever aplicações nem gerenciar recursos. Você configura os produtores de dados para enviar dados ao Amazon Data Firehose e ele entrega automaticamente os dados ao destino especificado. Você também pode configurar o Amazon Data Firehose para transformar os dados antes de entregá-los.
Para obter mais informações sobre soluções de AWS big data, consulte [Big Data on AWS](https://aws.amazon.com/big-data/). Para obter mais informações sobre as soluções de dados em streaming da AWS , consulte [O que são dados em streaming?](https://aws.amazon.com/streaming-data/)
## Noções básicas dos principais conceitos
Ao começar a usar o Amazon Data Firehose, pode ser vantajoso compreender os conceitos a seguir.
**Fluxo do Firehose**
A entidade subjacente do Amazon Data Firehose. Você usa o Amazon Data Firehose criando um fluxo do Firehose e enviando dados a ele. Para obter mais informações, consulte [Tutorial: Criação de um fluxo do Firehose a partir do console](basic-create.md) e [Envio de dados a um fluxo do Firehose](basic-write.md).
**Registro**
Os dados de interesse que seu produtor de dados envia para um fluxo do Firehose. Um registro pode ter até 1.000 KB.
**Produtor de dados**
Os produtores enviam registros para os fluxos do Firehose. Por exemplo, um servidor Web que envia dados de log para um fluxo do Firehose é um produtor de dados. Você também pode configurar o fluxo do Firehose para ler automaticamente os dados de um fluxo de dados existente do Kinesis e carregá-lo nos destinos. Para obter mais informações, consulte [Envio de dados a um fluxo do Firehose](basic-write.md).
**Tamanho e intervalo de buffer**
O Amazon Data Firehose armazena os dados de streaming recebidos em um determinado tamanho ou por um determinado período de tempo antes de entregá-los aos destinos. **Buffer Size**está dentro MBs e **Buffer Interval** está em segundos.
## Noções básicas sobre o fluxo de dados no Amazon Data Firehose
Para destinos do Amazon S3, os dados em streaming são entregues no bucket do S3. Se a transformação de dados estiver habilitada, você também poderá fazer backup dos dados da fonte em outro bucket do Amazon S3.
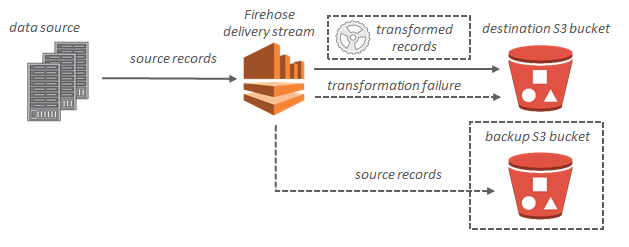
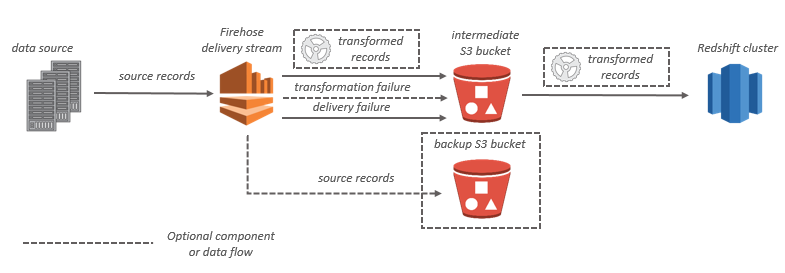
Para os destinos do Amazon Redshift, os dados em streaming são entregues primeiro no bucket do S3. Depois, o Amazon Data Firehose emite um comando **COPY** do Amazon Redshift para carregar os dados do bucket do S3 no cluster provisionado do Amazon Redshift. Se a transformação de dados estiver habilitada, você também poderá fazer backup dos dados da fonte em outro bucket do Amazon S3.
Para destinos OpenSearch de serviço, os dados de streaming são entregues ao seu cluster de OpenSearch serviços e, opcionalmente, podem ser copiados para seu bucket do S3 simultaneamente.
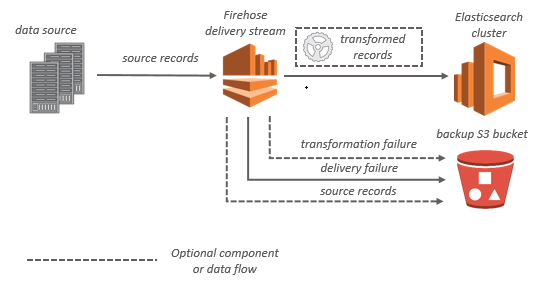
Para destinos do Splunk, os dados em streaming são entregues ao Splunk e eles podem ser submetidos a backup no bucket do S3 simultaneamente, se você desejar.
