As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
# Etapa 4: preparar a saída do Amazon Comprehend para visualização de dados
Para preparar os resultados das tarefas de análise de sentimentos e entidades para criar visualizações de dados, você usa o AWS Glue e o Amazon Athena. Nesta etapa, você extrai os arquivos de resultados do Amazon Comprehend. Em seguida, você cria um *crawler* AWS Glue que explora seus dados e os cataloga automaticamente em tabelas no AWS Glue Data Catalog. Depois disso, você acessa e transforma essas tabelas usando Amazon Athena um serviço de consulta interativo e sem servidor. Quando você concluir essa etapa, seus resultados do Amazon Comprehend estarão limpos e prontos para visualização.
Para uma tarefa de detecção de entidades de PII, o arquivo de saída é um texto sem formatação, não um arquivo compactado. O nome do arquivo de saída é o mesmo do arquivo de entrada, com `.out` anexo no final. Não é necessária a etapa de extrair o arquivo de saída. Pule para [carregar os dados em um AWS Glue Data Catalog](#tutorial-reviews-tables-crawler).
**Topics**
+ [Pré-requisitos](#tutorial-reviews-tables-prereqs)
+ [Baixe a saída](#tutorial-reviews-tables-download)
+ [Extraia os arquivos de saída](#tutorial-reviews-tables-extract)
+ [Carregue os arquivos extraídos](#tutorial-reviews-tables-upload)
+ [Carregue os dados em um AWS Glue Data Catalog](#tutorial-reviews-tables-crawler)
+ [Prepare os dados para análise](#tutorial-reviews-tables-prep)
## Pré-requisitos
Antes de começar, conclua [Etapa 3: executando trabalhos de análise em documentos no Amazon S3](tutorial-reviews-analysis.md).
## Baixe a saída
O Amazon Comprehend usa compressão Gzip para compactar arquivos de saída e salvá-los como um arquivo tar. A maneira mais simples de extrair os arquivos de saída é baixar esses arquivos `output.tar.gz` localmente.
Nesta etapa, você baixará os arquivos de saída de sentimentos e entidades.
### Baixe os arquivos de saída (console)
Para encontrar os arquivos de saída para cada tarefa, retorne à tarefa de análise no console do Amazon Comprehend. A tarefa de análise fornece a localização do S3 para a saída, onde você pode baixar o arquivo de saída.
**Baixar os arquivos de saída (console)**
1. No console do [Amazon Comprehend](https://console.aws.amazon.com/comprehend/), no painel de navegação, retorne às **Tarefas de análise.**
1. Escolha sua tarefa de análise de sentimentos `reviews-sentiment-analysis`.
1. Em **Saída**, escolha o link exibido ao lado do **Local dos dados de saída**. Isso redireciona você para o arquivo de `output.tar.gz` em seu bucket do S3.
1. Na página **Visão geral** selecione **Fazer download**.
1. No seu computador, renomeie o arquivo como `sentiment-output.tar.gz`. Como todos os arquivos de saída têm o mesmo nome, isso ajuda você a acompanhar os arquivos de sentimentos e entidades.
1. Repita as etapas 1 a 4 para encontrar e baixar a saída da sua tarefa de `reviews-entities-analysis`. No seu computador, renomeie o arquivo como `entities-output.tar.gz`.
### Baixe os arquivos de saída (AWS CLI)
Para encontrar os arquivos de saída de cada tarefa, use o `JobId` da tarefa de análise para encontrar a localização da saída no S3. Em seguida, use o comando `cp` para baixar o arquivo de saída no seu computador.
**Baixar os arquivos de saída (AWS CLI)**
1. Para listar detalhes sobre sua tarefa de análise de sentimentos, execute o comando a seguir. Substitua o `{{sentiment-job-id}}` pelo sentimento `JobId` que você salvou.
```
aws comprehend describe-sentiment-detection-job --job-id {{sentiment-job-id}}
```
Se perdeu o controle da sua `JobId`, execute o comando a seguir para listar todas as suas tarefas de sentimento e filtrá-las por nome.
```
aws comprehend list-sentiment-detection-jobs
--filter JobName="reviews-sentiment-analysis"
```
1. No objeto de `OutputDataConfig`, encontre o valor `S3Uri`. O valor `S3Uri` deve ser semelhante ao seguinte formato: `{{s3://amzn-s3-demo-bucket/.../output/output.tar.gz}}`. Copie esse valor para um editor de texto.
1. Para baixar o arquivo de saída de sentimentos no diretório local, execute o seguinte comando: Substitua o caminho do bucket do S3 pelo `S3Uri` copiado na etapa anterior. Substitua `{{path/}}` pelo caminho da pasta para seu diretório local. O nome do `sentiment-output.tar.gz` substitui o nome do arquivo original para ajudar você a acompanhar os arquivos de sentimentos e entidades.
```
aws s3 cp {{s3://amzn-s3-demo-bucket/.../output/output.tar.gz}}
{{path/}}sentiment-output.tar.gz
```
1. Para listar detalhes sobre sua tarefa de análise de entidades, execute o comando a seguir.
```
aws comprehend describe-entities-detection-job
--job-id {{entities-job-id}}
```
Se perdeu o controle da sua `JobId`, execute o comando a seguir para listar todas as suas tarefas de entidade e filtrá-las por nome.
```
aws comprehend list-entities-detection-jobs
--filter JobName="reviews-entities-analysis"
```
1. A partir do objeto de `OutputDataConfig` na descrição da tarefa de sua entidade, copie o valor do `S3Uri`.
1. Para baixar o arquivo de saída de entidades no diretório local, execute o seguinte comando. Substitua o caminho do bucket do S3 pelo `S3Uri` copiado na etapa anterior. Substitua `{{path/}}` pelo caminho da pasta para seu diretório local. O nome da `entities-output.tar.gz` substitui o nome do arquivo original.
```
aws s3 cp {{s3://amzn-s3-demo-bucket/.../output/output.tar.gz}}
{{path/}}entities-output.tar.gz
```
## Extraia os arquivos de saída
Antes de acessar os resultados do Amazon Comprehend, descompacte os arquivos de sentimentos e entidades. Use o sistema de arquivos local ou um terminal para descompactar os arquivos.
### Extraia os arquivos de saída (sistema de arquivos GUI)
Se você usa o macOS, clique duas vezes no arquivo no sistema de arquivos GUI para extrair o arquivo de saída.
Se você usa o Windows, é possível utilizar uma ferramenta de terceiros, como 7-Zip, para extrair os arquivos de saída no sistema de arquivos GUI. No Windows, você deve executar duas etapas para acessar o arquivo de saída. Primeiro, descompacte o arquivo e, em seguida, extraia-o
Renomeie o arquivo de sentimentos como `sentiment-output` e o arquivo de entidades como `entities-output` para distinguir entre os arquivos de saída.
### Extraia os arquivos de saída (terminal)
Se você usa Linux ou macOS, é possível utilizar seu terminal padrão. Se você usa o Windows, deve ter acesso a um Unix-style ambiente, como o Cygwin, para executar comandos tar.
Para extrair o arquivo de saída de sentimentos do arquivo de sentimentos, execute o comando a seguir em seu terminal local.
```
tar -xvf sentiment-output.tar.gz --transform 's,^,sentiment-,'
```
Observe que o parâmetro `--transform` adiciona o prefixo `sentiment-` ao arquivo de saída dentro do arquivo, renomeando o arquivo como `sentiment-output`. Isso permite distinguir entre os arquivos de saída de sentimentos e entidades e evitar a substituição.
Para extrair o arquivo de saída de entidades do arquivo de entidades, execute o comando a seguir em seu terminal local.
```
tar -xvf entities-output.tar.gz --transform 's,^,entities-,'
```
O parâmetro `--transform` adiciona o prefixo `entities-` ao nome do arquivo de saída.
**dica**
Para economizar custos de armazenamento no Amazon S3, compacte os arquivos novamente com o Gzip antes de carregá-los. É importante descompactar e descompactar os arquivos originais porque não é AWS Glue possível ler automaticamente os dados de um arquivo tar. No entanto, AWS Glue pode ler arquivos no formato Gzip.
## Carregue os arquivos extraídos
Depois de extrair os arquivos, faça o upload deles no seu bucket. Você deve armazenar os arquivos de saída de sentimentos e entidades em pastas separadas AWS Glue para ler os dados corretamente. No seu bucket, crie uma pasta para os resultados dos sentimentos extraídos e uma segunda pasta para os resultados das entidades extraídas. É possível criar pastas com o console do Amazon S3 ou com o AWS CLI.
### Faça upload de arquivos extraídos para o Amazon S3 (console)
Em seu bucket do S3, crie uma pasta para o arquivo de resultados de sentimento extraído e uma pasta para o arquivo de resultados de entidades. Em seguida, faça o upload dos arquivos de resultados extraídos para suas respectivas pastas.
**Fazer o upload dos arquivos extraídos para o Amazon S3 (console)**
1. Abra o console do Amazon S3 em [https://console.aws.amazon.com/s3/](https://console.aws.amazon.com/s3/).
1. Em **Buckets**, escolha seu bucket e, em seguida, **Criar pasta**.
1. Para o novo nome da pasta, insira o `sentiment-results` e escolha **Salvar**. Essa pasta conterá o arquivo de saída do sentimento extraído.
1. Na guia **Visão geral** do seu bucket, na lista de conteúdos do bucket, escolha a nova pasta `sentiment-results`. Escolha **Carregar**.
1. Em **Adicionar arquivos**, escolha o arquivo de `sentiment-output` do seu computador local e selecione **Avançar**.
1. Deixe as opções de **Gerenciar usuários**, **Acesso para outros Conta da AWS** e **Gerenciar permissões públicas** como padrões. Escolha **Próximo**.
1. Em **Classe de armazenamento**, escolha **Padrão**. Deixe as opções de **Criptografia**, **Metadados** e **Tag** como padrões. Escolha **Próximo**.
1. Revise as opções de upload e escolha **Carregar**.
1. Repita as etapas 1 a 8 para criar uma pasta chamada `entities-results` e carregar o arquivo de `entities-output` nela.
### Faça o upload dos arquivos extraídos para o Amazon S3 (AWS CLI)
Crie uma pasta no seu bucket do S3 ao fazer o upload de um arquivo com o comando `cp`.
**Fazer o upload dos arquivos extraídos no Amazon S3 (AWS CLI)**
1. Crie uma pasta de sentimentos e envie seu arquivo de sentimentos para ela executando o comando a seguir. Substitua `{{path/}}` pelo caminho local para o arquivo de saída de sentimento extraído.
```
aws s3 cp {{path/}}sentiment-output s3://amzn-s3-demo-bucket/sentiment-results/
```
1. Crie uma pasta de saída de entidades e carregue seu arquivo de entidades nela executando o comando a seguir. Substitua `{{path/}}` pelo caminho local para o arquivo de saída de entidades extraído.
```
aws s3 cp {{path/}}entities-output s3://amzn-s3-demo-bucket/entities-results/
```
## Carregue os dados em um AWS Glue Data Catalog
Para colocar os resultados em um banco de dados, você pode usar um AWS Glue *rastreador*. Um AWS Glue *rastreador* verifica arquivos e descobre o esquema dos dados. Em seguida, ele organiza os dados em tabelas em um AWS Glue Data Catalog (um banco de dados com tecnologia sem servidor). Você pode criar um rastreador com o AWS Glue console ou o. AWS CLI
### Carregue os dados em um AWS Glue Data Catalog (console)
Crie um AWS Glue rastreador que `sentiment-results` escaneie suas pastas e `entities-results` pastas separadamente. Um novo perfil de IAM para o AWS Glue concede permissão ao crawler para acessar seu bucket do S3. Esse perfil do IAM é criado ao configurar o crawler.
**Para carregar os dados em um AWS Glue Data Catalog (console)**
1. Certifique-se de que você esteja em uma região que ofereça suporte AWS Glue. Se estiver em outra região, na barra de navegação, escolha uma região compatível no **Seletor de regiões**. Para obter uma lista das regiões que oferecem suporte AWS Glue, consulte a [Tabela de regiões](https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/) no *Guia Global de Infraestrutura*.
1. Abra o AWS Glue console em [https://console.aws.amazon.com/glue/](https://console.aws.amazon.com/glue/).
1. No painel de navegação, escolha **Crawlers** e **Adicionar crawler**.
1. Em **Nome do crawler**, digite `comprehend-analysis-crawler` e escolha **Próximo**.
1. Em **Tipo de fonte do crawler**, escolha **Armazenamentos de dados** e **Próximo**.
1. Em **Adicionar um armazenamento de dados**, faça o seguinte:
1. Em **Escolher um armazenamento de dados**, escolha **S3**.
1. Deixe **Conexão** em branco.
1. Na opção **Rastrear dados em**, escolha **Caminho especificado em minha conta**.
1. Em **Incluir caminho**, insira o caminho do S3 completo da pasta de saída de sentimentos: `s3://amzn-s3-demo-bucket/sentiment-results`.
1. Escolha **Próximo**.
1. Em **Adicionar outro armazenamento de dados**, escolha **Sim** e **Próximo**. Repita a Etapa 6, mas insira o caminho do S3 completo da pasta de saída das entidades: `s3://amzn-s3-demo-bucket/entities-results`.
1. Em **Adicionar outro armazenamento de dados**, escolha **Não** e **Próximo**.
1. Em **Perfil do IAM**, siga um destes procedimentos:
1. Escolha **Criar um perfil do IAM**.
1. Para a **Perfil do IAM**, insira `glue-access-role` e **Próximo**.
1. Em **Criar uma programação para esse crawler**, escolha **Executar sob demanda** e **Próximo**.
1. Na página **Configurar a saída do crawler**, faça o seguinte:
1. Em **Base de dados**, selecione **Adicionar banco de dados**.
1. Em **Nome do banco de dados**, insira `comprehend-results`. Esse banco de dados armazenará suas tabelas de saída do Amazon Comprehend.
1. Deixe as outras opções em suas configurações padrão e escolha **Próximo**.
1. Revise as informações do crawler e escolha **Concluir**.
1. No console Glue, em **Crawlers**, escolha `comprehend-analysis-crawler` e **Executar crawler**. A conclusão do crawler pode levar alguns minutos.
### Carregue os dados em um AWS Glue Data Catalog (AWS CLI)
Crie uma função do IAM para AWS Glue que forneça permissão para acessar seu bucket do S3. Em seguida, crie um banco de dados no AWS Glue Data Catalog. Por fim, crie e execute um crawler que carrega seus dados em tabelas no banco de dados.
**Para carregar os dados em um AWS Glue Data Catalog (AWS CLI)**
1. Para criar uma função do IAM para AWS Glue, faça o seguinte:
1. Salve a política de confiança a seguir como um documento JSON chamado `glue-trust-policy.json` em seu computador.
------
#### [ JSON ]
****
```
{
"Version":"2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "glue.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
```
------
1. Para criar um perfil do IAM, execute o comando a seguir. Substitua `{{path/}}` pelo caminho do seu computador local até o documento JSON.
```
aws iam create-role --role-name glue-access-role
--assume-role-policy-document file://{{path/}}glue-trust-policy.json
```
1. Quando AWS CLI listar o Amazon Resource Number (ARN) para a nova função, copie e salve-o em um editor de texto.
1. Salve a seguinte política do IAM como um documento JSON chamado `glue-access-policy.json` em seu computador. A política concede AWS Glue permissão para rastrear suas pastas de resultados.
------
#### [ JSON ]
****
```
{
"Version":"2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::amzn-s3-demo-bucket/sentiment-results*",
"arn:aws:s3:::amzn-s3-demo-bucket/entities-results*"
]
}
]
}
```
------
1. Para criar uma política do IAM, execute o comando a seguir. Substitua `{{path/}}` pelo caminho do seu computador local até o documento JSON.
```
aws iam create-policy --policy-name glue-access-policy
--policy-document file://{{path/}}glue-access-policy.json
```
1. Quando AWS CLI listar o ARN da política de acesso, copie e salve em um editor de texto.
1. Anexe a nova política ao perfil do IAM executando o comando a seguir. Substitua `{{policy-arn}}` pelo ARN da política do IAM anotado na etapa anterior.
```
aws iam attach-role-policy --policy-arn {{policy-arn}}
--role-name glue-access-role
```
1. Anexe a política AWS gerenciada `AWSGlueServiceRole` à sua função do IAM executando o comando a seguir.
```
aws iam attach-role-policy --policy-arn
arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole
--role-name glue-access-role
```
1. Crie um AWS Glue banco de dados executando o comando a seguir.
```
aws glue create-database
--database-input Name="comprehend-results"
```
1. Crie um novo AWS Glue rastreador executando o comando a seguir. `{{glue-iam-role-arn}}`Substitua pelo ARN da sua AWS Glue função do IAM.
```
aws glue create-crawler
--name comprehend-analysis-crawler
--role {{glue-iam-role-arn}}
--targets S3Targets=[
{Path="s3://amzn-s3-demo-bucket/sentiment-results"},
{Path="s3://amzn-s3-demo-bucket/entities-results"}]
--database-name comprehend-results
```
1. Inicie o crawler executando o comando a seguir:
```
aws glue start-crawler --name comprehend-analysis-crawler
```
A conclusão do crawler pode levar alguns minutos.
## Prepare os dados para análise
Agora você tem um banco de dados preenchido com os resultados do Amazon Comprehend. No entanto, os resultados estão aninhados. Para desaninhá-los, você executa algumas instruções SQL em Amazon Athena. Amazon Athena é um serviço de consulta interativo que facilita a análise de dados no Amazon S3 usando SQL padrão. Como o Athena é uma tecnologia sem servidor, não há infraestrutura para configurar ou gerenciar, e ele usa um modelo de preços de pagamento por consulta. Nesta etapa, você cria novas tabelas de dados limpos que podem ser usadas para análise e visualização. Você usa o console do Athena para prepará-los.
**Preparar os dados**
1. Abra o console do Athena em [https://console.aws.amazon.com/athena/](https://console.aws.amazon.com/athena/home).
1. No editor de consultas, escolha **Configurações** e escolha **Gerenciar**.
1. Em **Localização dos resultados da consulta**, insira `s3://amzn-s3-demo-bucket/query-results/`. Isso cria uma nova pasta chamada `query-results` em seu bucket que armazena a saída das Amazon Athena consultas que você executa. Escolha **Salvar**.
1. No editor de consultas, escolha **Editor**.
1. Em **Banco de dados**, escolha o AWS Glue banco de dados `comprehend-results` que você criou.
1. Na seção **Tabelas**, haverá duas tabelas chamadas `sentiment_results` e `entities_results`. Visualize as tabelas para garantir que o crawler tenha carregado os dados. Nas opções de cada tabela (os três pontos ao lado do nome da tabela), escolha **Visualizar tabela**. Uma consulta curta é executada automaticamente. Verifique o painel **Resultados** para garantir que as tabelas contenham dados.
**dica**
Se as tabelas não tiverem dados, tente verificar as pastas em seu bucket do S3. Certifique-se de haver uma pasta para resultados de entidades e uma pasta para resultados de sentimentos. Em seguida, tente executar um novo AWS Glue rastreador.
1. Para desaninhar a tabela de `sentiment_results`, insira a seguinte consulta no **Editor de consultas** e escolha **Executar**.
```
CREATE TABLE sentiment_results_final AS
SELECT file, line, sentiment,
sentimentscore.mixed AS mixed,
sentimentscore.negative AS negative,
sentimentscore.neutral AS neutral,
sentimentscore.positive AS positive
FROM sentiment_results
```
1. Para começar a desaninhar a tabela de entidades, insira a consulta a seguir no **Editor de consultas** e escolha **Executar**.
```
CREATE TABLE entities_results_1 AS
SELECT file, line, nested FROM entities_results
CROSS JOIN UNNEST(entities) as t(nested)
```
1. Para concluir o desaninhamento da tabela de entidades, insira a consulta a seguir no **Editor de consultas** e escolha **Executar consulta**.
```
CREATE TABLE entities_results_final AS
SELECT file, line,
nested.beginoffset AS beginoffset,
nested.endoffset AS endoffset,
nested.score AS score,
nested.text AS entity,
nested.type AS category
FROM entities_results_1
```
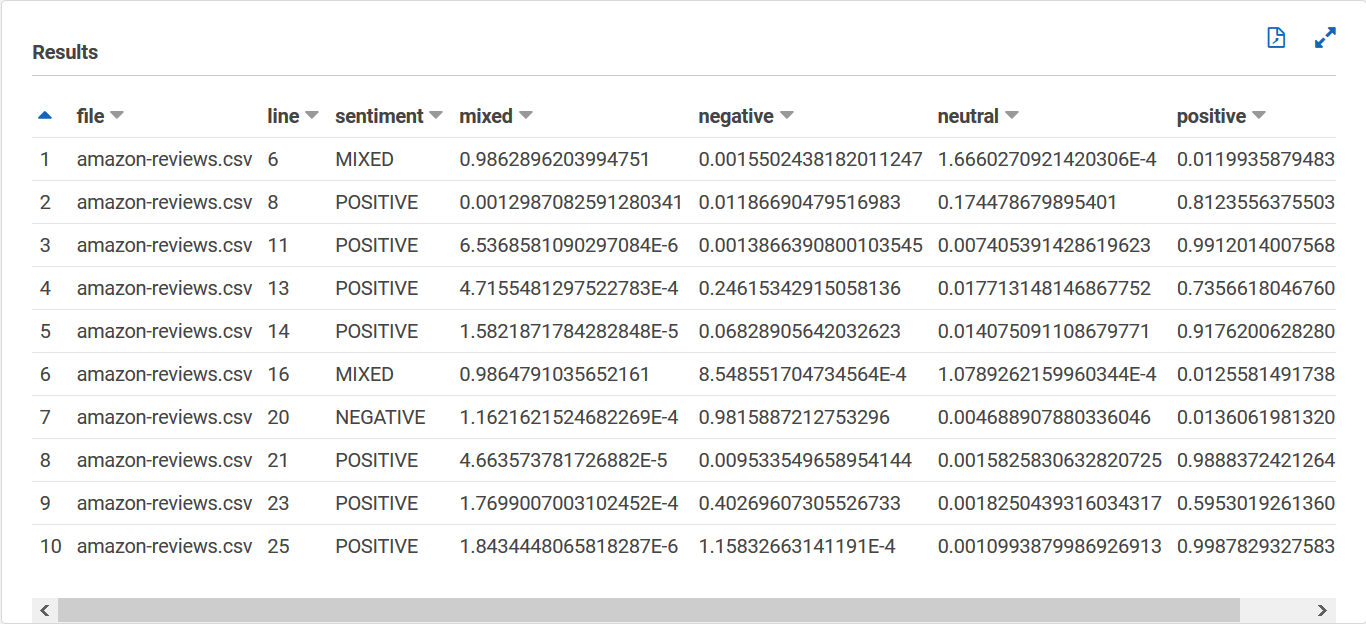
Sua tabela de `sentiment_results_final` deve ter a aparência a seguir, com colunas denominadas **arquivo**, **linha**, **sentimento**, **mista**, **negativa**, **neutra** e **positiva**. A tabela deve ter um valor por célula. A coluna de **sentimentos** descreve o sentimento geral mais provável de uma avaliação específica. As colunas **mista**, **negativa**, **neutra** e **positiva** dão pontuações para cada tipo de sentimento.
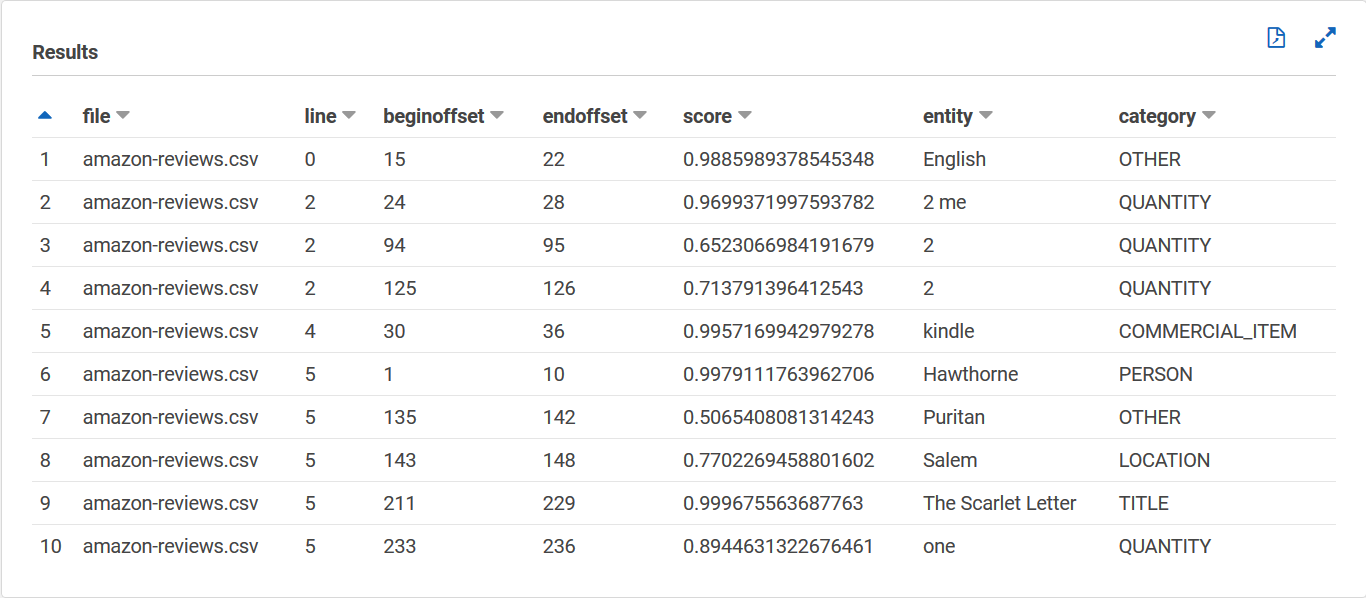
Sua tabela de `entities_results_final` deve ter a aparência a seguir, com colunas chamadas **arquivo**, **linha**, **beginoffset, **endoffset****, **pontuação**, **entidade** e **categoria**. A tabela deve ter um valor por célula. A coluna de **pontuação** indica a confiança do Amazon Comprehend na **entidade** detectada. A **categoria** indica que tipo de entidade o Comprehend detectou.
Agora que tem os resultados do Amazon Comprehend carregados em tabelas, você pode visualizar e extrair insights significativos dos dados.