기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon SageMaker HyperPod에서 탄력적 훈련 사용
탄력적 훈련은 컴퓨팅 리소스 가용성 및 워크로드 우선 순위에 따라 훈련 작업을 자동으로 확장하는 새로운 Amazon SageMaker HyperPod 기능입니다. 탄력적 훈련 작업은 모델 훈련에 필요한 최소 컴퓨팅 리소스로 시작하고 다양한 노드 구성(세계 크기)에서 자동 체크포인트 및 재개를 통해 동적으로 확장 또는 축소할 수 있습니다. 데이터 병렬 복제본 수를 자동으로 조정하여 조정을 수행합니다. 클러스터 사용률이 높은 기간에는 우선 순위가 높은 작업의 리소스 요청에 따라 탄력적 훈련 작업을 자동으로 축소하도록 구성하여 중요한 워크로드에 대한 컴퓨팅을 확보할 수 있습니다. 사용량이 적은 기간에 리소스가 확보되면 탄력적 훈련 작업이 자동으로 스케일 업되어 훈련을 가속화한 다음 우선순위가 높은 워크로드에 리소스가 다시 필요할 때 스케일 다운합니다.
탄력적 훈련은 HyperPod 훈련 연산자를 기반으로 하며 다음 구성 요소를 통합합니다.
지원되는 프레임워크
-
분산 데이터 병렬(DDP) 및 완전 샤딩된 데이터 병렬(FSDP)을 사용하는 PyTorch
-
PyTorch 분산 체크포인트(DCP)
사전 조건
SageMaker HyperPod EKS 클러스터
Amazon EKS 오케스트레이션을 사용하는 실행 중인 SageMaker HyperPod 클러스터가 있어야 합니다. HyperPod EKS 클러스터 생성에 대한 자세한 내용은 다음을 참조하세요.
SageMaker HyperPod 훈련 운영자
Elastic Training은 훈련 운영자 v. 1.2 이상에서 지원됩니다.
훈련 연산자를 EKS 추가 기능으로 설치하려면 https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-eks-operator-install.html 참조하세요.
(권장) 작업 거버넌스 및 Kueue 설치 및 구성
탄력적 훈련을 통해 워크로드 우선 순위를 지정하려면 HyperPod 태스크 거버넌스를 통해 Kueue를 설치하고 구성하는 것이 좋습니다. Kueue는 멀티테넌트 훈련 환경에서 운영하는 데 필수적인 대기열, 우선 순위 지정, 그룹 스케줄링, 리소스 추적 및 정상적인 선점으로 더 강력한 워크로드 관리를 제공합니다.
-
그룹 예약은 훈련 작업의 모든 필수 포드가 함께 시작되도록 합니다. 이렇게 하면 일부 포드가 시작되고 다른 포드는 보류 상태로 유지되어 리소스가 낭비될 수 있는 상황을 방지할 수 있습니다.
-
간단한 선점으로 우선 순위가 낮은 탄력적 작업을 통해 우선 순위가 높은 워크로드에 리소스를 제공할 수 있습니다. 탄력적 작업은 강제로 제거되지 않고 정상적으로 축소되어 전체 클러스터 안정성을 개선할 수 있습니다.
다음 Kueue 구성 요소를 구성하는 것이 좋습니다.
-
상대적 작업 중요도를 정의하는 PriorityClasses
-
팀 또는 워크로드 전반의 글로벌 리소스 공유 및 할당량을 관리하기 위한 ClusterQueues
-
개별 네임스페이스에서 적절한 ClusterQueue LocalQueues
고급 설정을 위해 다음을 통합할 수도 있습니다.
-
여러 팀에서 리소스 사용량의 균형을 맞추는 공정 공유 정책
-
조직 SLAs 또는 비용 제어를 적용하기 위한 사용자 지정 선점 규칙
다음을 참조하세요.
(권장) 사용자 네임스페이스 및 리소스 할당량 설정
Amazon EKS에이 기능을 배포할 때는 팀 간에 격리, 리소스 공정성 및 운영 일관성을 보장하기 위해 일련의 기본 클러스터 수준 구성을 적용하는 것이 좋습니다.
네임스페이스 및 액세스 구성
각 팀 또는 프로젝트에 대해 별도의 네임스페이스를 사용하여 워크로드를 구성합니다. 이를 통해 세분화된 격리 및 거버넌스를 적용할 수 있습니다. 또한 개별 AWS IAM 사용자 또는 역할을 해당 네임스페이스와 연결하도록 IAM을 Kubernetes RBAC 매핑으로 구성하는 것이 좋습니다.
주요 사례는 다음과 같습니다.
-
워크로드에 권한이 필요할 AWS 때 서비스 계정에 대한 IAM 역할(IRSA)을 사용하여 IAM 역할을 Kubernetes 서비스 계정에 매핑합니다. https://docs.aws.amazon.com/eks/latest/userguide/access-entries.html
-
RBAC 정책을 적용하여 사용자를 지정된 네임스페이스(예: 클러스터 전체 권한 대신
Role/RoleBinding)로만 제한합니다.
리소스 및 컴퓨팅 제약 조건
리소스 경합을 방지하고 팀 간에 공정한 일정을 잡으려면 네임스페이스 수준에서 할당량과 제한을 적용합니다.
-
집계 CPU, 메모리, 스토리지 및 객체 수(포드, PVCs, 서비스 등)를 제한하는 ResourceQuotas
-
LimitRanges는 기본 및 최대 포드당 또는 컨테이너당 CPU 및 메모리 제한을 적용합니다.
-
복원력 기대치를 정의하는 데 필요한 PodDisruptionBudgets(PDBs.
-
선택 사항: 사용자가 작업을 과다 제출하는 것을 방지하기 위한 네임스페이스 수준 대기열 제약 조건(예: 작업 거버넌스 또는 Kueue를 통해).
이러한 제약 조건은 클러스터 안정성을 유지하고 분산 훈련 워크로드에 대한 예측 가능한 일정을 지원하는 데 도움이 됩니다.
Auto Scaling
SageMaker HyperPod on EKS는 Karpenter를 통한 클러스터 자동 크기 조정을 지원합니다. Karpenter 또는 유사한 리소스 프로비저너를 탄력적 훈련과 함께 사용하면 탄력적 훈련 작업이 제출된 후 클러스터와 탄력적 훈련 작업이 자동으로 확장될 수 있습니다. 이는 탄력적 훈련 연산자가 복잡한 접근 방식을 취하기 때문에는 작업에 의해 설정된 최대 한도에 도달할 때까지 항상 사용 가능한 컴퓨팅 리소스보다 더 많은 리소스를 요청하기 때문입니다. 이는 탄력적 훈련 운영자가 노드 프로비저닝을 트리거할 수 있는 탄력적 작업 실행의 일부로 추가 리소스를 지속적으로 요청하기 때문에 발생합니다. Karpenter와 같은 지속적인 리소스 프로비저너는 컴퓨팅 클러스터를 확장하여 요청을 처리합니다.
이러한 스케일 업을 예측 가능하고 제어 가능하게 유지하려면 탄력적 훈련 작업이 생성되는 네임스페이스에서 네임스페이스 수준 ResourceQuotas를 구성하는 것이 좋습니다. ResourceQuotas는 작업이 요청할 수 있는 최대 리소스를 제한하여 정의된 제한 내에서 탄력적 동작을 허용하면서 무제한 클러스터 증가를 방지합니다.
예를 들어 8 ml.p5.48xlarge 인스턴스용 ResourceQuota의 형식은 다음과 같습니다.
apiVersion: v1 kind: ResourceQuota metadata: name: <quota-name> namespace: <namespace-name> spec: hard: nvidia.com/gpu: "64" vpc.amazonaws.com/efa: "256" requests.cpu: "1536" requests.memory: "5120Gi" limits.cpu: "1536" limits.memory: "5120Gi"
훈련 컨테이너 빌드
HyperPod 훈련 운영자는 HyperPod Elastic Agent python 패키지(https://www.piwheels.org/project/hyperpod-elastic-agent/hyperpodrun 시작하려면 탄력적 에이전트를 설치하고 torchrun 명령을 로 바꿔야 합니다. 자세한 내용은 다음을 참조하세요.
훈련 컨테이너의 예:
FROM ... ... RUN pip install hyperpod-elastic-agent ENTRYPOINT ["entrypoint.sh"] # entrypoint.sh ... hyperpodrun --nnodes=node_count --nproc-per-node=proc_count \ --rdzv-backend hyperpod \ # Optional ... # Other torchrun args # pre-traing arg_group --pre-train-script pre.sh --pre-train-args "pre_1 pre_2 pre_3" \ # post-train arg_group --post-train-script post.sh --post-train-args "post_1 post_2 post_3" \ training.py --script-args
훈련 코드 수정
SageMaker HyperPod는 Elastic Policy로 실행하도록 이미 구성된 레시피 세트를 제공합니다.
사용자 지정 PyTorch 훈련 스크립트에 대해 탄력적 훈련을 활성화하려면 훈련 루프를 약간 수정해야 합니다. 이 가이드에서는 훈련 작업이 컴퓨팅 리소스 가용성이 변경될 때 발생하는 탄력적 조정 이벤트에 응답하도록 하는 데 필요한 수정 사항을 안내합니다. 모든 탄력적 이벤트(예: 노드 사용 가능 또는 노드 선점) 중에 훈련 작업은 체크포인트를 저장하고 저장된 체크포인트에서 새 월드 구성으로 다시 시작하여 훈련을 재개하여 정상적인 종료를 조정하는 데 사용되는 탄력적 이벤트 신호를 수신합니다. 사용자 지정 훈련 스크립트를 사용하여 탄력적 훈련을 활성화하려면 다음을 수행해야 합니다.
탄력적 조정 이벤트 감지
훈련 루프에서 각 반복 중에 탄력적 이벤트를 확인합니다.
from hyperpod_elastic_agent.elastic_event_handler import elastic_event_detected def train_epoch(model, dataloader, optimizer, args): for batch_idx, batch_data in enumerate(dataloader): # Forward and backward pass loss = model(batch_data).loss loss.backward() optimizer.step() optimizer.zero_grad() # Handle checkpointing and elastic scaling should_checkpoint = (batch_idx + 1) % args.checkpoint_freq == 0 elastic_event = elastic_event_detected() # Save checkpoint if scaling-up or scaling down job if should_checkpoint or elastic_event: save_checkpoint(model, optimizer, scheduler, checkpoint_dir=args.checkpoint_dir, step=global_step) if elastic_event: print("Elastic scaling event detected. Checkpoint saved.") return
체크포인트 저장 및 체크포인트 로드 구현
참고: 모델 및 옵티마이저 상태를 저장하려면 PyTorch 분산 체크포인트(DCP)를 사용하는 것이 좋습니다. DCP는 월드 크기가 다른 체크포인트에서 재개할 수 있도록 지원되기 때문입니다. 다른 체크포인트 형식은 다른 월드 크기에서 체크포인트 로드를 지원하지 않을 수 있습니다.이 경우 동적 월드 크기 변경을 처리하기 위해 사용자 지정 로직을 구현해야 합니다.
import torch.distributed.checkpoint as dcp from torch.distributed.checkpoint.state_dict import get_state_dict, set_state_dict def save_checkpoint(model, optimizer, lr_scheduler, user_content, checkpoint_path): """Save checkpoint using DCP for elastic training.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler, **user_content } dcp.save( state_dict=state_dict, storage_writer=dcp.FileSystemWriter(checkpoint_path) ) def load_checkpoint(model, optimizer, lr_scheduler, checkpoint_path): """Load checkpoint using DCP with automatic resharding.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler } dcp.load( state_dict=state_dict, storage_reader=dcp.FileSystemReader(checkpoint_path) ) return model, optimizer, lr_scheduler
(선택 사항) 상태 저장 데이터 로더 사용
단일 에포크(즉, 전체 데이터 세트를 한 번만 전달)에 대해서만 훈련하는 경우 모델은 각 데이터 샘플을 한 번만 확인해야 합니다. 훈련 작업이 에포크 중반을 중지하고 다른 월드 크기로 재개되면 데이터 로더 상태가 지속되지 않으면 이전에 처리된 데이터 샘플이 반복됩니다. 상태 저장 데이터 로더는 데이터 로더의 위치를 저장하고 복원하여 이를 방지하므로 샘플을 재처리하지 않고도 탄력적 조정 이벤트에서 재개된 실행이 계속됩니다. state_dict() 및 load_state_dict() 메서드를 추가하는의 드롭인 대체물인 StatefulDataLoadertorch.utils.data.DataLoader하는 것이 좋습니다.
탄력적 훈련 작업 제출
HyperPod 훈련 연산자는 새 리소스 유형 -를 정의합니다hyperpodpytorchjob. 탄력적 훈련은이 리소스 유형을 확장하고 아래에 강조 표시된 필드를 추가합니다.
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 1 maxReplicas: 4 # Increment amount of pods in fixed-size groups # Amount of pods will be equal to minReplicas + N * replicaIncrementStep replicaIncrementStep: 1 # ... or Provide an exact amount of pods that required for training replicaDiscreteValues: [2,4,8] # How long traing operator wait job to save checkpoint and exit during # scaling events. Job will be force-stopped after this period of time gracefulShutdownTimeoutInSeconds: 600 # When scaling event is detected: # how long job controller waits before initiate scale-up. # Some delay can prevent from frequent scale-ups and scale-downs scalingTimeoutInSeconds: 60 # In case of faults, specify how long elastic training should wait for # recovery, before triggering a scale-down faultyScaleDownTimeoutInSeconds: 30 ... replicaSpecs: - name: pods replicas: 4 # Initial replica count maxReplicas: 8 # Max for this replica spec (should match elasticPolicy.maxReplicas) ...
kubectl 사용
이후 다음 명령을 사용하여 탄력적 훈련을 시작할 수 있습니다.
kubectl apply -f elastic-training-job.yaml
SageMaker 레시피 사용
탄력적 훈련 작업은 SageMaker HyperPod 레시피를 통해 시작할 수 있습니다
참고
Hyperpod 레시피에 SFO 및 DPO 작업을 위한 46개의 탄력적 레시피가 포함되어 있습니다. 사용자는 기존 정적 시작 관리자 스크립트를 기반으로 한 줄 변경으로 이러한 작업을 시작할 수 있습니다.
++recipes.elastic_policy.is_elastic=true
정적 레시피 외에도 탄력적 레시피는 다음 필드를 추가하여 탄력적 동작을 정의합니다.
탄력적 정책
elastic_policy 필드는 탄력적 훈련 작업에 대한 작업 수준 구성을 정의하며, 다음과 같은 구성이 있습니다.
-
is_elastic:bool-이 작업이 탄력적 작업인 경우 -
min_nodes:int- 탄력적 훈련에 사용되는 최소 노드 수 -
max_nodes:int- 탄력적 훈련에 사용되는 최대 노드 수 -
replica_increment_step:int- 고정 크기 그룹의 포드 양을 증가시킵니다.이 필드는 나중에scale_config정의하는에 상호 배타적입니다. -
use_graceful_shutdown:bool- 조정 이벤트 중에 정상적인 종료를 사용하는 경우 기본값은 입니다true. -
scaling_timeout:int- 제한 시간 전 조정 이벤트 중 초 단위의 대기 시간 -
graceful_shutdown_timeout:int- 정상 종료 대기 시간
다음은이 필드의 샘플 정의입니다. 레시피의 Hyperpod 레시피 리포지토리에서를 찾을 수도 있습니다. recipes_collection/recipes/fine-tuning/llama/llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.yaml
<static recipe> ... elastic_policy: is_elastic: true min_nodes: 1 max_nodes: 16 use_graceful_shutdown: true scaling_timeout: 600 graceful_shutdown_timeout: 600
규모 조정 구성
scale_config 필드는 각 특정 규모에서 재정의 구성을 정의합니다. 키-값 사전입니다. 여기서 key는 대상 규모를 나타내는 정수이고 value는 기본 레시피의 하위 집합입니다. <key> 규모에 따라 <value>를 사용하여 기본/정적 레시피의 특정 구성을 업데이트합니다. 다음은이 필드의 예를 보여줍니다.
scale_config: ... 2: trainer: num_nodes: 2 training_config: training_args: train_batch_size: 128 micro_train_batch_size: 8 learning_rate: 0.0004 3: trainer: num_nodes: 3 training_config: training_args: train_batch_size: 128 learning_rate: 0.0004 uneven_batch: use_uneven_batch: true num_dp_groups_with_small_batch_size: 16 small_local_batch_size: 5 large_local_batch_size: 6 ...
위의 구성은 규모 2 및 3에서 훈련 구성을 정의합니다. 두 경우 모두 학습률 4e-4, 배치 크기를 사용합니다128. 그러나 규모 2에서는 8micro_train_batch_size의를 사용하는 반면, 규모 3에서는 훈련 배치 크기를 3개의 노드로 균등하게 나눌 수 없으므로 고르지 않은 배치 크기를 사용합니다.
고르지 않은 배치 크기
글로벌 배치 크기를 순위 수로 균등하게 나눌 수 없는 경우 배치 분산 동작을 정의하는 필드입니다. 탄력적 훈련에만 국한되지는 않지만 더 세분화된 조정을 위한 인에이블러입니다.
-
use_uneven_batch:bool- 고르지 않은 배치 분포를 사용하는 경우 -
num_dp_groups_with_small_batch_size:int- 고르지 않은 배치 분포에서 일부 순위는 더 작은 로컬 배치 크기를 사용하고, 다른 순위는 더 큰 배치 크기를 사용합니다. 글로벌 배치 크기는와 같아야 합니다.small_local_batch_size * num_dp_groups_with_small_batch_size + (world_size-num_dp_groups_with_small_batch_size) * large_local_batch_size -
small_local_batch_size:int-이 값은 더 작은 로컬 배치 크기입니다. -
large_local_batch_size:int-이 값은 더 큰 로컬 배치 크기입니다.
MLFlow에서 훈련 모니터링
하이퍼포드 레시피 작업은 MLFlow를 통한 관찰성을 지원합니다. 사용자는 레시피에서 MLFlow 구성을 지정할 수 있습니다.
training_config: mlflow: tracking_uri: "<local_file_path or MLflow server URL>" run_id: "<MLflow run ID>" experiment_name: "<MLflow experiment name, e.g. llama_exps>" run_name: "<run name, e.g. llama3.1_8b>"
이러한 구성은 해당 MLFlow 설정에
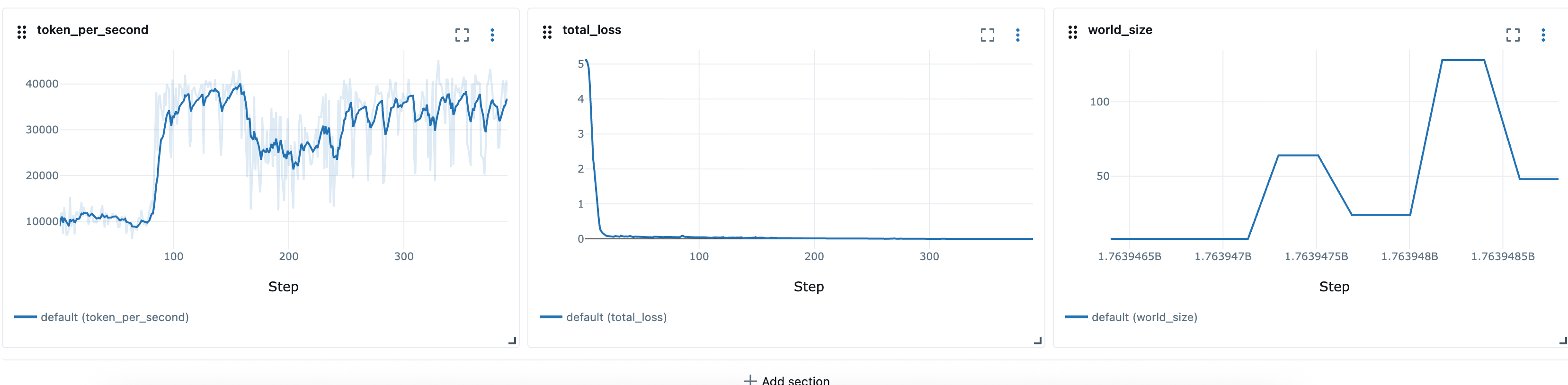
탄력적 레시피를 정의한 후와 같은 시작 관리자 스크립트launcher_scripts/llama/run_llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.sh를 사용하여 탄력적 훈련 작업을 시작할 수 있습니다. 이는 Hyperpod 레시피를 사용하여 정적 작업을 시작하는 것과 유사합니다.
참고
레시피 지원의 탄력적 훈련 작업은 최신 체크포인트에서 자동으로 재개되지만 기본적으로 재시작할 때마다 새 훈련 디렉터리가 생성됩니다. 마지막 체크포인트에서 올바르게 재개하려면 동일한 훈련 디렉터리를 재사용해야 합니다. 이 작업은를 설정하여 수행할 수 있습니다.
recipes.training_config.training_args.override_training_dir=true
사용 사례 예제 및 제한 사항
더 많은 리소스를 사용할 수 있을 때 스케일 업
클러스터에서 더 많은 리소스를 사용할 수 있게 되면(예: 다른 워크로드 완료) 이 이벤트 중에 훈련 컨트롤러는 훈련 작업을 자동으로 확장합니다. 이 동작은 아래에 설명되어 있습니다.
더 많은 리소스를 사용할 수 있는 상황을 시뮬레이션하기 위해 우선 순위가 높은 작업을 제출한 다음 우선 순위가 높은 작업을 삭제하여 리소스를 다시 릴리스할 수 있습니다.
# Submit a high-priority job on your cluster. As a result of this command # resources will not be available for elastic training kubectl apply -f high_prioriy_job.yaml # Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Wait for training to start.... # Delete high priority job. This command will make additional resources available for # elastic training kubectl delete -f high_prioriy_job.yaml # Observe the scale-up of elastic job
예상 동작:
-
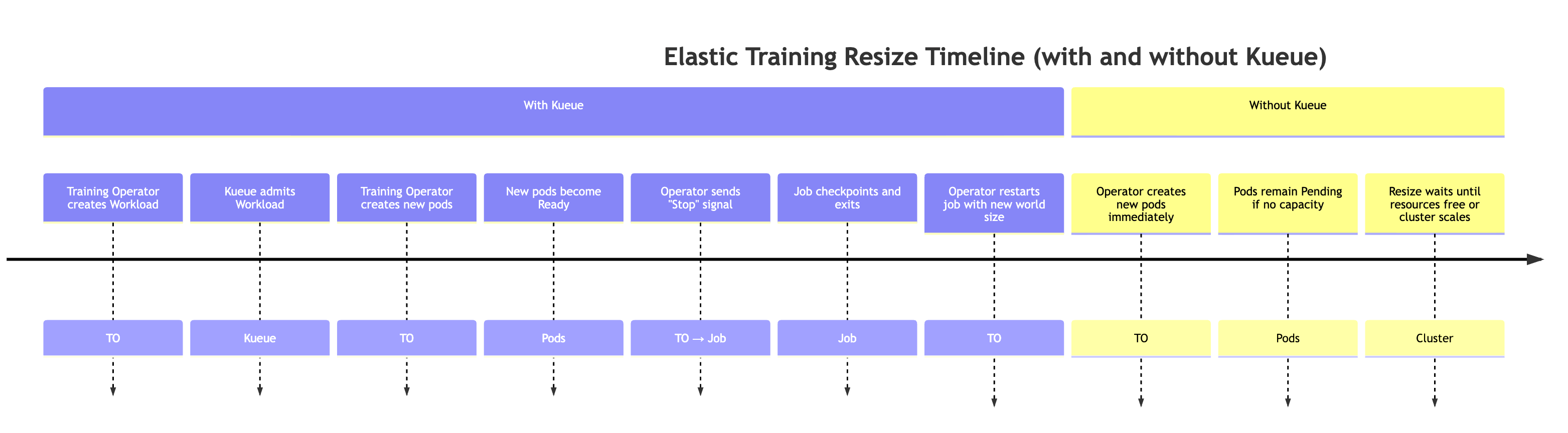
훈련 운영자는 Kueue 워크로드 생성 탄력적 훈련 작업이 월드 크기 변경을 요청하면 훈련 운영자는 새 리소스 요구 사항을 나타내는 추가 Kueue 워크로드 객체를 생성합니다.
-
Kueue는 워크로드 Kueue가 사용 가능한 리소스, 우선순위 및 대기열 정책을 기반으로 요청을 평가함을 승인합니다. 승인되면 워크로드가 승인됩니다.
-
훈련 운영자는 추가 포드를 생성합니다. 승인 시 운영자는 새 세계 크기에 도달하는 데 필요한 추가 포드를 시작합니다.
-
새 포드가 준비되면 훈련 운영자는 훈련 스크립트에 특수 탄력적 이벤트 신호를 보냅니다.
-
훈련 작업은 정상 종료를 준비하기 위해 체크포인트를 수행합니다. 훈련 프로세스는 elastic_event_detected() 함수를 호출하여 탄력적 이벤트 신호를 주기적으로 확인합니다. 감지되면 체크포인트가 시작됩니다. 체크포인트가 성공적으로 완료되면 훈련 프로세스가 완전히 종료됩니다.
-
훈련 운영자는 새 월드 크기로 작업을 다시 시작합니다. 운영자는 모든 프로세스가 종료될 때까지 기다린 다음 업데이트된 월드 크기와 최신 체크포인트를 사용하여 훈련 작업을 다시 시작합니다.
참고: Kueue를 사용하지 않으면 훈련 연산자는 처음 두 단계를 건너뜁니다. 새 월드 크기에 필요한 추가 포드를 즉시 생성하려고 시도합니다. 클러스터에서 충분한 리소스를 사용할 수 없는 경우 용량을 사용할 수 있을 때까지 이러한 포드는 보류 중 상태로 유지됩니다.
우선 순위가 높은 작업에 의한 선점
우선순위가 높은 작업에 리소스가 필요한 경우 탄력적 작업을 자동으로 축소할 수 있습니다. 이 동작을 시뮬레이션하려면 훈련 시작부터 우선순위가 높은 작업을 제출하고 선점 동작을 관찰하는 것보다 사용 가능한 최대 리소스 수를 사용하는 탄력적 훈련 작업을 제출할 수 있습니다.
# Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Submit a high-priority job on your cluster. As a result of this command # some amount of resources will be kubectl apply -f high_prioriy_job.yaml # Observe scale-down behaviour
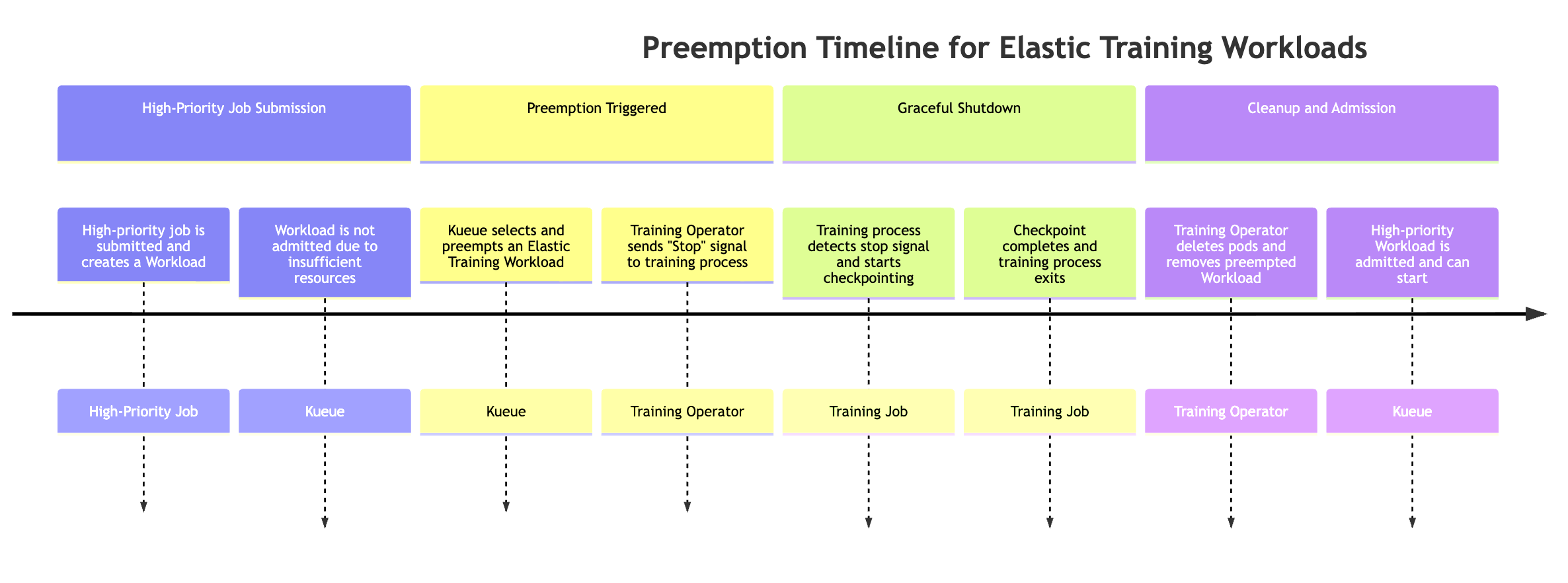
우선 순위가 높은 작업에 리소스가 필요한 경우 Kueue는 우선 순위가 낮은 Elastic Training 워크로드를 선점할 수 있습니다(Elastic Training 작업과 연결된 워크로드 객체가 2개 이상일 수 있음). 선점 프로세스는 다음 순서를 따릅니다.
-
우선 순위가 높은 작업이 제출되었습니다. 작업은 새 Kueue 워크로드를 생성하지만 클러스터 리소스가 부족하여 워크로드를 허용할 수 없습니다.
-
Kueue는 Elastic Training 작업의 워크로드 Elastic 작업 중 하나를 선점합니다. Elastic 작업에는 활성 워크로드가 여러 개 있을 수 있습니다(세계 크기 구성당 하나). Kueue는 우선 순위 및 대기열 정책에 따라 선점할 하나를 선택합니다.
-
훈련 운영자는 탄력적 이벤트 신호를 보냅니다. 선점이 트리거되면 훈련 운영자는 실행 중인 훈련 프로세스를 정상적으로 중지하도록 알립니다.
-
훈련 프로세스는 체크포인트를 수행합니다. 훈련 작업은 주기적으로 탄력적 이벤트 신호를 확인합니다. 감지되면 종료하기 전에 진행 상황을 보존하기 위해 조정된 체크포인트를 시작합니다.
-
훈련 운영자는 포드와 워크로드를 정리합니다. 운영자는 체크포인트 완료를 기다린 다음 선점된 워크로드의 일부인 훈련 포드를 삭제합니다. 또한 Kueue에서 해당 워크로드 객체를 제거합니다.
-
우선 순위가 높은 워크로드가 승인됩니다. 리소스가 확보되면 Kueue는 우선 순위가 높은 작업을 허용하여 실행을 시작할 수 있습니다.
선점으로 인해 전체 훈련 작업이 일시 중지될 수 있으며, 이는 모든 워크플로에 바람직하지 않을 수 있습니다. 탄력적 조정을 허용하면서 전체 작업 일시 중지를 방지하기 위해 고객은 두 replicaSpec 섹션을 정의하여 동일한 훈련 작업 내에서 두 가지 우선 순위 수준을 구성할 수 있습니다.
-
일반 또는 우선 순위가 높은 기본(고정) replicaSpec
-
훈련 작업을 계속 실행하는 데 필요한 최소 필수 복제본 수를 포함합니다.
-
더 높은 PriorityClass를 사용하여 이러한 복제본이 선점되지 않도록 합니다.
-
클러스터에 리소스 부담이 있는 경우에도 기준 진행 상황을 유지합니다.
-
-
우선 순위가 낮은 탄력적(확장 가능한) replicaSpec
-
탄력적 조정 중에 추가 컴퓨팅을 제공하는 추가 선택적 복제본을 포함합니다.
-
더 낮은 PriorityClass를 사용하면 우선 순위가 높은 작업에 리소스가 필요할 때 Kueue가 이러한 복제본을 선점할 수 있습니다.
-
코어 훈련이 중단 없이 계속되는 동안 탄력적 부분만 회수되도록 합니다.
-
이 구성을 사용하면 탄력적 용량만 회수되는 부분 선점이 가능하여 다중 테넌트 환경에서 여전히 공정한 리소스 공유를 지원하면서 훈련 연속성을 유지할 수 있습니다. 예제:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 2 maxReplicas: 8 replicaIncrementStep: 2 ... replicaSpecs: - name: base replicas: 2 template: spec: priorityClassName: high-priority # set high-priority to avoid evictions ... - name: elastic replicas: 0 maxReplicas: 6 template: spec: priorityClassName: low-priority. # Set low-priority for elastic part ...
포드 제거, 포드 충돌 및 하드웨어 성능 저하 처리:
HyperPod 훈련 운영자에는 예기치 않게 중단될 때 훈련 프로세스를 복구하는 기본 제공 메커니즘이 포함되어 있습니다. 중단은 훈련 코드 장애, 포드 제거, 노드 장애, 하드웨어 성능 저하 및 기타 런타임 문제와 같은 다양한 이유로 발생할 수 있습니다.
이 경우 운영자는 영향을 받는 포드를 자동으로 다시 생성하고 최신 체크포인트에서 훈련을 재개하려고 시도합니다. 예를 들어 예비 용량 부족으로 인해 복구가 즉시 불가능한 경우 운영자는 일시적으로 월드 크기를 줄이고 탄력적 훈련 작업을 축소하여 진행 상황을 계속할 수 있습니다.
탄력적 훈련 작업이 충돌하거나 복제본이 손실되면 시스템은 다음과 같이 동작합니다.
-
복구 단계(스페어 노드 사용) 훈련 컨트롤러는
faultyScaleDownTimeoutInSeconds리소스를 사용할 수 있을 때까지 대기하고 스페어 용량으로 포드를 재배포하여 장애가 발생한 복제본을 복구하려고 시도합니다. -
탄력적 스케일 다운 제한 시간 내에 복구할 수 없는 경우 훈련 운영자는 작업을 더 작은 월드 크기로 스케일 다운합니다(작업의 탄력적 정책에서 허용하는 경우). 그러면 더 적은 수의 복제본으로 훈련이 재개됩니다.
-
탄력적 스케일 업 추가 리소스를 다시 사용할 수 있게 되면 운영자는 원하는 월드 크기로 훈련 작업을 자동으로 다시 스케일 업합니다.
이 메커니즘을 사용하면 리소스 부담이나 부분 인프라 장애 발생 시에도 훈련을 계속하면서 탄력적 규모 조정을 활용할 수 있습니다.
다른 HyperPod 기능과 함께 탄력적 훈련 사용
탄력적 훈련은 현재 체크포인트 없는 훈련 기능, HyperPod 관리형 계층형 체크포인트 또는 스팟 인스턴스를 지원하지 않습니다.
참고
당사는 필수 서비스 가용성을 제공하기 위해 일상적인 집계 및 익명화된 특정 운영 지표를 수집합니다. 이러한 지표의 생성은 완전히 자동화되며 기본 모델 훈련 워크로드에 대한 인적 검토가 필요하지 않습니다. 이러한 지표는 작업 및 조정 작업, 리소스 관리 및 필수 서비스 기능과 관련이 있습니다.
