기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
프로세스 중 복구 및 체크포인트 없는 훈련
HyperPod 체크포인트 없는 훈련은 모델 중복을 사용하여 내결함성 훈련을 활성화합니다. 핵심 원칙은 모델 및 옵티마이저 상태가 여러 노드 그룹에 완전히 복제되고 가중치 업데이트 및 옵티마이저 상태 변경이 각 그룹 내에 동기식으로 복제된다는 것입니다. 장애가 발생하면 정상 복제본은 옵티마이저 단계를 완료하고 업데이트된 모델/최적화기 상태를 복구 중인 복제본으로 전송합니다.
이 모델 중복 기반 접근 방식을 사용하면 다음과 같은 몇 가지 장애 처리 메커니즘을 사용할 수 있습니다.
-
프로세스 중 복구: 결함이 있더라도 프로세스가 활성 상태로 유지되어 GPU 메모리의 모든 모델 및 옵티마이저 상태를 최신 값으로 유지
-
정상적인 중단 처리: 영향을 받는 작업에 대한 제어된 중단 및 리소스 정리
-
코드 블록 재실행: 재실행 가능한 코드 블록(RCB) 내에서 영향을 받는 코드 세그먼트만 재실행
-
훈련 진행 상황 손실 없이 체크포인트 없는 복구: 프로세스가 지속되고 상태가 메모리에 남아 있으므로 훈련 진행 상황이 손실되지 않습니다. 장애가 발생하면 마지막으로 저장된 체크포인트에서 재개하는 대신 이전 단계에서 훈련이 재개됩니다.
체크포인트 없는 구성
다음은 체크포인트 없는 훈련의 핵심 코드 조각입니다.
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank wait_rank() def main(): @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=PEFTCheckpointManager(enable_offload=True), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), ) def run_main(cfg, caller: Optional[HPCallWrapper] = None): ... trainer = Trainer( strategy=CheckpointlessMegatronStrategy(..., num_distributed_optimizer_instances=2), callbacks=[..., CheckpointlessCallback(...)], ) trainer.fresume = resume trainer._checkpoint_connector = CheckpointlessCompatibleConnector(trainer) trainer.wrapper = caller
wait_rank: 모든 순위는 HyperpodTrainingOperator 인프라의 순위 정보를 기다립니다.HPWrapper: Re-executable Code Block(RCB)에 대한 재시작 기능을 활성화하는 Python 함수 래퍼입니다. 구현에서는 Python 데코레이터가 아닌 컨텍스트 관리자를 사용합니다. 데코레이터가 런타임 시 모니터링할 RCBs 수를 결정할 수 없기 때문입니다.CudaHealthCheck: GPU와 동기화하여 현재 프로세스의 CUDA 컨텍스트가 정상 상태인지 확인합니다. LOCAL_RANK 환경 변수에서 지정한 디바이스를 사용하거나 LOCAL_RANK가 설정되지 않은 경우 기본 스레드의 CUDA 디바이스로 설정됩니다.HPAgentK8sAPIFactory:이 API를 사용하면 체크포인트 없는 훈련이 Kubernetes 훈련 클러스터에 있는 다른 포드의 훈련 상태를 쿼리할 수 있습니다. 또한 계속하기 전에 모든 순위가 중단 및 재시작 작업을 성공적으로 완료하도록 인프라 수준 장벽을 제공합니다.CheckpointManager: 체크포인트 없는 내결함성을 위해 인 메모리 체크포인트 및 peer-to-peer 복구를 관리합니다. 여기에는 다음과 같은 핵심 책임이 있습니다.인 메모리 체크포인트 관리: 체크포인트 없는 복구 시나리오 중에 디스크 I/O 없이 빠르게 복구할 수 있도록 NeMo 모델 체크포인트를 메모리에 저장하고 관리합니다.
복구 가능성 검증: 글로벌 단계 일관성, 순위 상태 및 모델 상태 무결성을 검증하여 체크포인트 없는 복구가 가능한지 확인합니다.
Peer-to-Peer 복구 오케스트레이션: 빠른 복구를 위해 분산 통신을 사용하여 정상 순위와 실패한 순위 간의 체크포인트 전송을 조정합니다.
RNG 상태 관리: 결정적 복구를 위해 Python, NumPy, PyTorch 및 Megatron에서 난수 생성기 상태를 보존하고 복원합니다.
[선택 사항] 체크포인트 오프로드: GPU에 메모리 용량이 충분하지 않은 경우 메모리 체크포인트에서 CPU로 오프로드합니다.
PEFTCheckpointManager: PEFT 미세 조정을 위한 기본 모델 가중치를 유지CheckpointManager하여 확장합니다.CheckpointlessAbortManager: 오류가 발생할 때 백그라운드 스레드에서 중단 작업을 관리합니다. 기본적으로 TransformerEngine, Checkpointing, TorchDistributed 및 DataLoader를 중단합니다. 사용자는 필요에 따라 사용자 지정 중단 핸들러를 등록할 수 있습니다. 중단이 완료되면 모든 통신을 중단하고 리소스 누수를 방지하기 위해 모든 프로세스와 스레드를 종료해야 합니다.CheckpointlessFinalizeCleanup: 백그라운드 스레드에서 안전하게 중단하거나 정리할 수 없는 구성 요소에 대해 메인 스레드의 최종 정리 작업을 처리합니다.CheckpointlessMegatronStrategy:MegatronStrategyNemo의에서 상속됩니다. 옵티마이저 복제num_distributed_optimizer_instances가 이루어지도록 체크포인트 없는 훈련은 최소 2여야 합니다. 이 전략은 루트리스와 같은 필수 속성 등록 및 프로세스 그룹 초기화도 처리합니다.CheckpointlessCallback: NeMo 훈련을 체크포인트 없는 훈련의 내결함성 시스템과 통합하는 Lightning 콜백입니다. 여기에는 다음과 같은 핵심 책임이 있습니다.훈련 단계 수명 주기 관리: 훈련 진행 상황을 추적하고 ParameterUpdateLock과 조정하여 훈련 상태(첫 번째 단계 대 후속 단계)를 기반으로 체크포인트 없는 복구를 활성화/비활성화합니다.
체크포인트 상태 조정: 인 메모리 PEFT 기본 모델 체크포인트 저장/복원을 관리합니다.
CheckpointlessCompatibleConnector: 체크포인트 파일을 메모리에 미리 로드하려고 시도CheckpointConnector하는 PTL로, 소스 경로는이 우선 순위에 따라 결정됩니다.체크포인트 없는 복구 시도
체크포인트가 없음을 반환하는 경우 parent.resume_start()로 폴백합니다.
코드에 체크포인트 없는 훈련 기능을 추가하려면 예제
개념
이 섹션에서는 체크포인트 없는 훈련 개념을 소개합니다. Amazon SageMaker HyperPod에 대한 체크포인트 없는 훈련은 프로세스 중 복구를 지원합니다. 이 API 인터페이스는 NVRx APIs와 유사한 형식을 따릅니다.
개념 - Re-Executable Code Block(RCB)
장애가 발생하면 정상 프로세스가 활성 상태로 유지되지만 훈련 상태 및 python 스택을 복구하려면 코드의 일부를 다시 실행해야 합니다. Re-executable Code Block(RCB)은 장애 복구 중에 다시 실행되는 특정 코드 세그먼트입니다. 다음 예제에서 RCB는 전체 훈련 스크립트(예: main() 아래의 모든 항목)를 포함합니다. 즉, 각 장애 복구는 인 메모리 모델 및 옵티마이저 상태를 유지하면서 훈련 스크립트를 다시 시작합니다.
개념 - 결함 제어
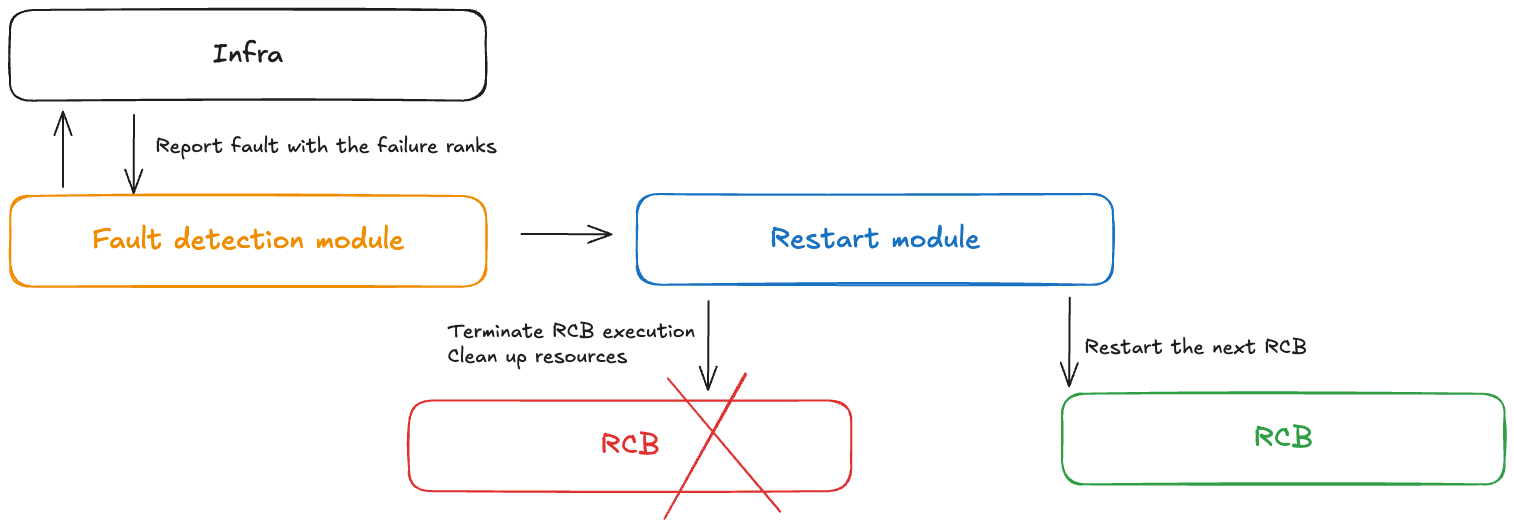
체크포인트 없는 훈련 중에 장애가 발생하면 오류 컨트롤러 모듈이 알림을 받습니다. 이 오류 컨트롤러에는 다음 구성 요소가 포함되어 있습니다.
결함 감지 모듈: 인프라 결함 알림을 수신합니다.
RCB 정의 APIs: 사용자가 코드에서 다시 실행 가능한 코드 블록(RCB)을 정의할 수 있습니다.
모듈 다시 시작: RCB를 종료하고, 리소스를 정리하고, RCB를 다시 시작합니다.
개념 - 모델 중복성
대규모 모델 훈련에는 일반적으로 모델을 효율적으로 훈련할 수 있을 만큼 충분히 큰 데이터 병렬 크기가 필요합니다. PyTorch DDP 및 Horovod와 같은 기존 데이터 병렬 처리에서는 모델이 완전히 복제됩니다. DeepSpeed ZeRO 옵티마이저 및 FSDP와 같은 고급 샤딩된 데이터 병렬 처리 기법은 하이브리드 샤딩 모드도 지원하므로 샤딩 그룹 내에서 모델/최적화기 상태를 샤딩하고 복제 그룹 간에 완전히 복제할 수 있습니다. 또한 NeMo에는 중복성을 허용하는 인수 num_distributed_optimizer_instances를 통한이 하이브리드 샤딩 기능이 있습니다.
그러나 중복성을 추가하면 모델이 전체 클러스터에 완전히 샤딩되지 않아 디바이스 메모리 사용량이 늘어납니다. 중복 메모리의 양은 사용자가 구현한 특정 모델 샤딩 기법에 따라 달라집니다. 저정밀도 모델 가중치, 그라데이션 및 활성화 메모리는 모델 병렬 처리를 통해 샤딩되므로 영향을 받지 않습니다. 고정밀도 마스터 모델 가중치/그라데이션 및 옵티마이저 상태가 영향을 받습니다. 중복 모델 복제본을 하나 추가하면 디바이스 메모리 사용량이 DCP 체크포인트 크기 하나와 거의 동일합니다.
하이브리드 샤딩은 전체 DP 그룹의 집합체를 비교적 작은 집합체로 나눕니다. 이전에는 전체 DP 그룹에 걸쳐 감소 분산 및 전체 수집이 있었습니다. 하이브리드 샤딩 후 감소 산란은 각 모델 복제본 내에서만 실행되며 모델 복제본 그룹 간에 모두 감소합니다. 전체 수집은 각 모델 복제본 내에서도 실행됩니다. 따라서 전체 통신 볼륨은 거의 변경되지 않지만 집합체는 더 작은 그룹으로 실행되므로 지연 시간이 길어질 것으로 예상됩니다.
개념 - 실패 및 재시작 유형
다음 표에는 다양한 장애 유형과 관련 복구 메커니즘이 기록되어 있습니다. 체크포인트 없는 훈련은 먼저 프로세스 중 복구를 통해 장애 복구를 시도한 다음 프로세스 수준을 다시 시작합니다. 치명적인 장애(예: 여러 노드가 동시에 실패)가 발생한 경우에만 작업 수준 재시작으로 돌아갑니다.
| 실패 유형 | 원인 | 복구 유형 | 복구 메커니즘 |
|---|---|---|---|
| 처리 중 실패 | 코드 수준 오류, 예외 | 프로세스 중 복구(IPR) | 기존 프로세스 내에서 RCB를 다시 실행합니다. 정상 프로세스는 활성 상태로 유지됩니다. |
| 프로세스 재시작 실패 | CUDA 컨텍스트 손상, 프로세스 종료 | 프로세스 수준 재시작(PLR) | SageMaker HyperPod 훈련 운영자가 프로세스를 다시 시작하고 K8s 포드 다시 시작을 건너뜁니다. |
| 노드 교체 실패 | 영구 노드/GPU 하드웨어 장애 | 작업 수준 재시작(JLR) | 실패한 노드 교체, 전체 훈련 작업 다시 시작 |
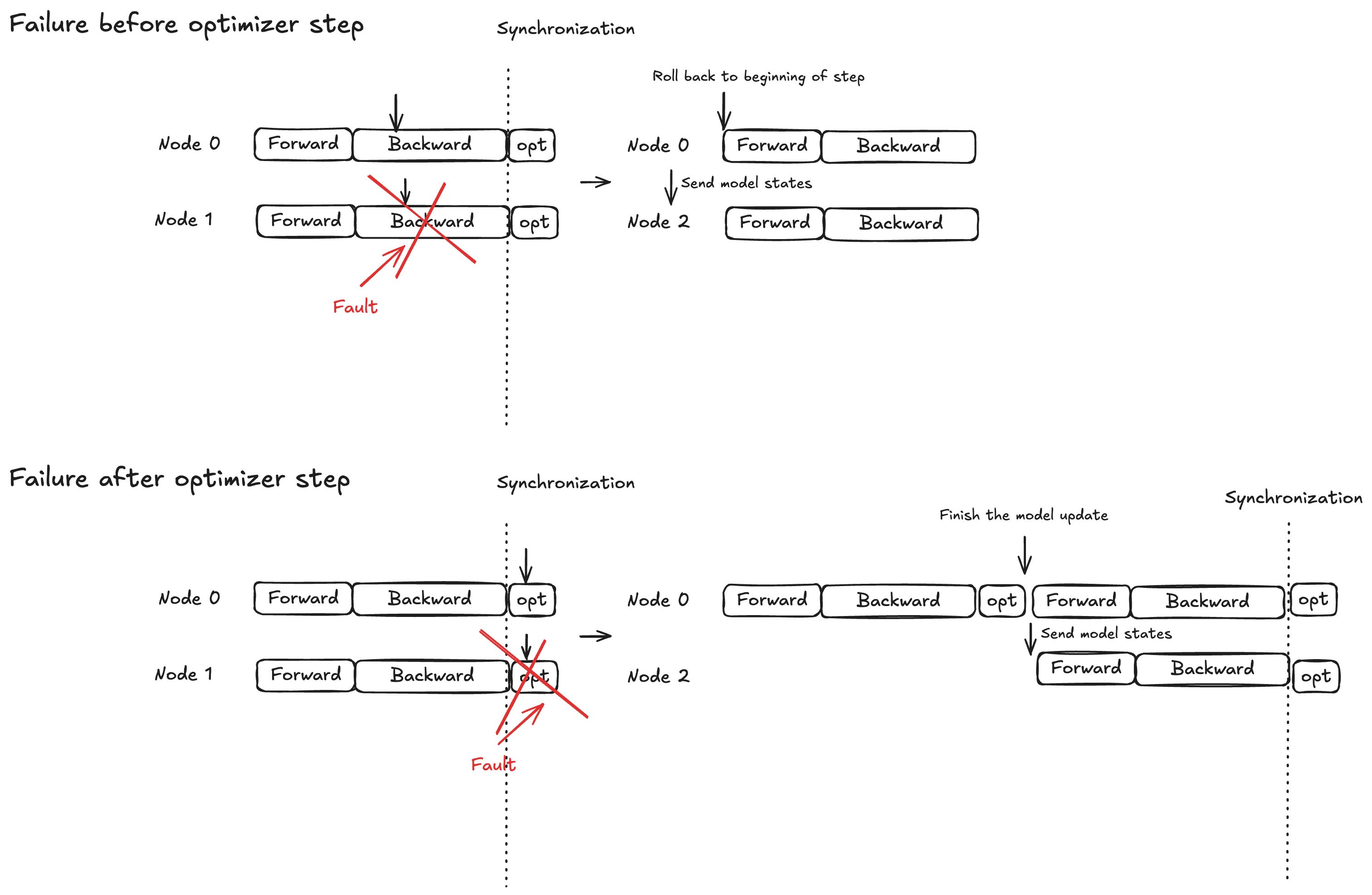
개념 - 옵티마이저 단계를 위한 원자 잠금 보호
모델 실행은 순방향 전파, 역방향 전파, 최적화 프로그램 단계의 세 단계로 나뉩니다. 복구 동작은 실패 타이밍에 따라 달라집니다.
순방향/역방향 전파: 현재 훈련 단계의 시작 부분으로 롤백하고 모델 상태를 대체 노드(들)로 브로드캐스트합니다.
옵티마이저 단계: 정상 복제본이 잠금 보호 상태에서 단계를 완료하도록 허용한 다음 업데이트된 모델 상태를 대체 노드(들)로 브로드캐스트합니다.
이 전략은 완료된 옵티마이저 업데이트가 폐기되지 않도록 하여 장애 복구 시간을 줄이는 데 도움이 됩니다.
체크포인트 없는 훈련 흐름도
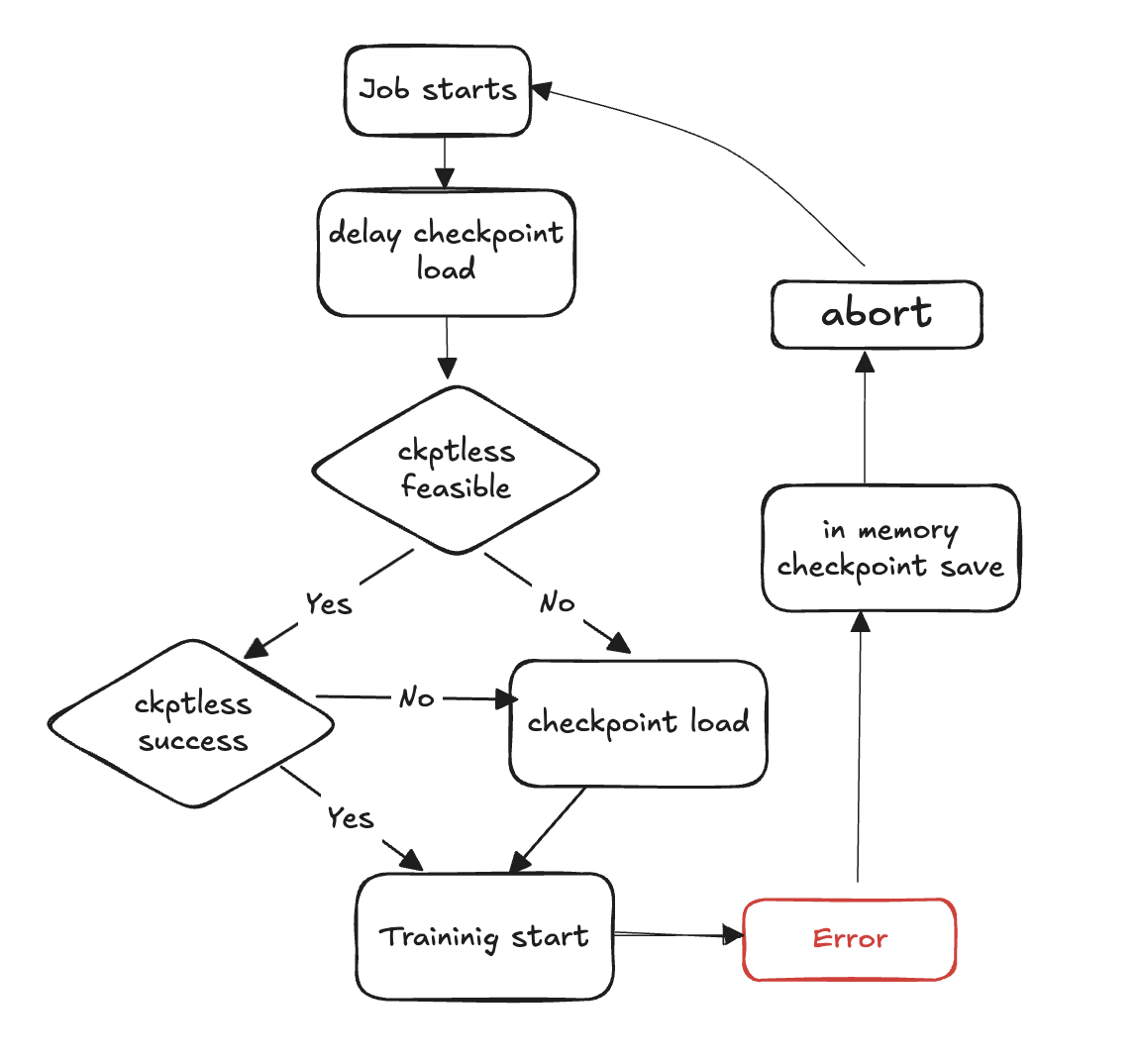
다음 단계에서는 장애 감지 및 체크포인트 없는 복구 프로세스를 간략하게 설명합니다.
훈련 루프 시작
결함 발생
체크포인트 없는 재개 가능성 평가
체크포인트 없는 재개를 수행할 수 있는지 확인
가능한 경우 체크포인트 없는 재개 시도
재개가 실패하면 스토리지에서 체크포인트 로드로 폴백합니다.
재개에 성공하면 복구된 상태에서 훈련이 계속됩니다.
불가능한 경우 스토리지에서 체크포인트 로드로 돌아갑니다.
리소스 정리 - 재시작을 준비하기 위해 모든 프로세스 그룹과 백엔드 및 무료 리소스를 중단합니다.
훈련 루프 재개 - 새 훈련 루프가 시작되고 프로세스가 1단계로 돌아갑니다.
API 참조
wait_rank
hyperpod_checkpointless_training.inprocess.train_utils.wait_rank()
HyperPod에서 순위 정보를 대기하고 검색한 다음 현재 프로세스 환경을 분산 훈련 변수로 업데이트합니다.
이 함수는 분산 훈련을 위한 올바른 순위 할당 및 환경 변수를 가져옵니다. 이를 통해 각 프로세스가 분산 훈련 작업에서 역할에 적합한 구성을 얻을 수 있습니다.
파라미터
없음
반환
없음
동작
프로세스 확인: 하위 프로세스에서 호출된 경우 실행 건너뛰기(MainProcess에서만 실행됨)
환경 검색: 환경 변수
WORLD_SIZE에서 현재RANK및를 가져옵니다.HyperPod 통신: HyperPod에서 순위 정보를 검색
hyperpod_wait_rank_info()하기 위한 호출환경 업데이트: HyperPod에서 받은 작업자별 환경 변수로 현재 프로세스 환경을 업데이트합니다.
환경 변수
함수는 다음 환경 변수를 읽습니다.
RANK(int) - 현재 프로세스 순위(기본값: 설정되지 않은 경우 -1)
GLOBAL_SIZE(int) - 분산 작업의 총 프로세스 수(기본값: 설정되지 않은 경우 0)
상승
AssertionError - HyperPod의 응답이 예상 형식이 아니거나 필수 필드가 누락된 경우
예제
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank # Call before initializing distributed training wait_rank() # Now environment variables are properly set for this rank import torch.distributed as dist dist.init_process_group(backend='nccl')
참고
기본 프로세스에서만 실행되며 하위 프로세스 호출은 자동으로 건너뜁니다.
함수는 HyperPod가 순위 정보를 제공할 때까지 차단합니다.
HPWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPWrapper( *, abort=Compose(HPAbortTorchDistributed()), finalize=None, health_check=None, hp_api_factory=None, abort_timeout=None, enabled=True, trace_file_path=None, async_raise_before_abort=True, early_abort_communicator=False, checkpoint_manager=None, check_memory_status=True)
HyperPod 체크포인트 없는 훈련에서 Re-executable Code Block(RCB)에 대한 재시작 기능을 활성화하는 Python 함수 래퍼입니다.
이 래퍼는 훈련 실행을 모니터링하고 장애 발생 시 분산 프로세스에서 재시작을 조정하여 내결함성 및 자동 복구 기능을 제공합니다. 데코레이터가 아닌 컨텍스트 관리자 접근 방식을 사용하여 훈련 수명 주기 동안 글로벌 리소스를 유지합니다.
파라미터
중단(중단, 선택 사항) - 실패가 감지되면 실행을 비동기적으로 중단합니다. 기본값:
Compose(HPAbortTorchDistributed())finalize(최종화, 선택 사항) - 재시작 중에 실행된 순위-로컬 최종화 핸들러입니다. 기본값:
Nonehealth_check(HealthCheck, 선택 사항) - 다시 시작하는 동안 실행된 순위-로컬 상태 확인입니다. 기본값:
Nonehp_api_factory(통화 가능, 선택 사항) - HyperPod와 상호 작용할 HyperPod API를 생성하는 팩토리 함수입니다. 기본값:
Noneabort_timeout(부동 소수점, 선택 사항) - 오류 제어 스레드의 중단 호출 제한 시간입니다. 기본값:
Noneenabled(bool, 선택 사항) - 래퍼 기능을 활성화합니다. 이면 래퍼
False가 패스스루가 됩니다. 기본값:Truetrace_file_path(str, 선택 사항) - VizTracer 프로파일링을 위한 추적 파일의 경로입니다. 기본값:
Noneasync_raise_before_abort(bool, 선택 사항) - 오류 제어 스레드에서 중단되기 전에 상승을 활성화합니다. 기본값:
Trueearly_abort_communicator(bool, 선택 사항) - 데이터 로더를 중단하기 전에 통신기(NCCL/Gloo)를 중단합니다. 기본값:
Falsecheckpoint_manager(모든, 선택 사항) - 복구 중 체크포인트를 처리하기 위한 관리자입니다. 기본값:
Nonecheck_memory_status(bool, 선택 사항) - 메모리 상태 확인 및 로깅을 활성화합니다. 기본값:
True
메서드
def __call__(self, fn)
함수를 래핑하여 재시작 기능을 활성화합니다.
파라미터:
fn(통화 가능) - 재시작 기능으로 래핑하는 함수
다음을 반환합니다.
호출 가능 - 재시작 기능이 있는 래핑된 함수 또는 비활성화된 경우 원래 함수
예제
from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager from hyperpod_checkpointless_training.nemo_plugins.patches import patch_megatron_optimizer from hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector import CheckpointlessCompatibleConnector from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=CheckpointManager(enable_offload=False), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), )def training_function(): # Your training code here pass
참고
래퍼를 사용할 수 있어야
torch.distributed합니다.enabled=False인 경우 래퍼는 패스스루가 되고 변경되지 않은 원래 함수를 반환합니다.래퍼는 훈련 수명 주기 동안 스레드 모니터링과 같은 글로벌 리소스를 유지합니다.
가
trace_file_path제공될 때 VizTracer 프로파일링 지원분산 훈련 전반에 걸쳐 조정된 장애 처리를 위해 HyperPod와 통합
HPCallWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPCallWrapper(wrapper)
실행 중에 Restart Code Block(RCB)의 상태를 모니터링하고 관리합니다.
이 클래스는 장애 감지, 재시작을 위한 다른 순위와의 조정, 정리 작업을 포함하여 RCB 실행의 수명 주기를 처리합니다. 분산 동기화를 관리하고 모든 훈련 프로세스에서 일관된 복구를 보장합니다.
파라미터
래퍼(HPWrapper) - 글로벌 프로세스 중 복구 설정이 포함된 상위 래퍼
속성
step_upon_restart(int) - 재시작 전략을 결정하는 데 사용되는 마지막 재시작 이후 단계를 추적하는 카운터
메서드
def initialize_barrier()
RCB에서 예외가 발생한 후 HyperPod 장벽 동기화를 기다립니다.
def start_hp_fault_handling_thread()
장애 모니터링 및 조정을 위해 장애 처리 스레드를 시작합니다.
def handle_fn_exception(call_ex)
실행 함수 또는 RCB의 예외를 처리합니다.
파라미터:
call_ex(예외) - 모니터링 함수의 예외
def restart(term_ex)
마무리, 가비지 수집 및 상태 확인을 포함하여 재시작 핸들러를 실행합니다.
파라미터:
term_ex(RankShouldRestart) - 재시작을 트리거하는 종료 예외
def launch(fn, *a, **kw)
적절한 예외 처리로 RCB를 실행합니다.
파라미터:
fn(통화 가능) - 실행할 함수
a - 함수 인수
kw - 함수 키워드 인수
def run(fn, a, kw)
재시작 및 장벽 동기화를 처리하는 기본 실행 루프입니다.
파라미터:
fn(통화 가능) - 실행할 함수
a - 함수 인수
kw - 함수 키워드 인수
def shutdown()
장애 처리 및 모니터링 스레드를 종료합니다.
참고
조정된 복구에 대한
RankShouldRestart예외를 자동으로 처리메모리 추적 및 중단, 재시작 중 가비지 수집을 관리합니다.
실패 타이밍을 기반으로 프로세스 중 복구 및 PLR(프로세스 수준 재시작) 전략을 모두 지원합니다.
CudaHealthCheck
class hyperpod_checkpointless_training.inprocess.health_check.CudaHealthCheck(timeout=datetime.timedelta(seconds=30))
체크포인트 없는 훈련 복구 중에 현재 프로세스의 CUDA 컨텍스트가 정상 상태인지 확인합니다.
이 상태 확인은 GPU와 동기화되어 훈련 실패 후 CUDA 컨텍스트가 손상되지 않았는지 확인합니다. GPU 동기화 작업을 수행하여 성공적인 훈련 재개를 방해할 수 있는 문제를 감지합니다. 상태 확인은 분산 그룹이 파괴되고 완료가 완료된 후 실행됩니다.
파라미터
timeout(datetime.timedelta, 선택 사항) - GPU 동기화 작업의 제한 시간입니다. 기본값:
datetime.timedelta(seconds=30)
메서드
__call__(state, train_ex=None)
CUDA 상태 확인을 실행하여 GPU 컨텍스트 무결성을 확인합니다.
파라미터:
state(HPState) - 순위 및 분산 정보를 포함하는 현재 HyperPod 상태
train_ex(예외, 선택 사항) - 재시작을 트리거한 원래 훈련 예외입니다. 기본값:
None
다음을 반환합니다.
튜플 - 상태 확인이 통과할 경우
(state, train_ex)변경되지 않은이 포함된 튜플
상승:
TimeoutError – GPU 동기화 시간이 초과되어 잠재적으로 손상된 CUDA 컨텍스트를 나타내는 경우
상태 보존: 모든 검사가 통과하면 원래 상태와 예외를 변경 없이 반환합니다.
예제
import datetime from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # Create CUDA health check with custom timeout cuda_health_check = CudaHealthCheck( timeout=datetime.timedelta(seconds=60) ) # Use with HPWrapper for fault-tolerant training @HPWrapper( health_check=cuda_health_check, enabled=True ) def training_function(): # Your training code here pass
참고
스레드를 사용하여 GPU 동기화에 대한 제한 시간 보호를 구현합니다.
성공적인 훈련 재개를 방해할 수 있는 손상된 CUDA 컨텍스트를 감지하도록 설계됨
분산 훈련 시나리오에서 내결함성 파이프라인의 일부로 사용해야 합니다.
HPAgentK8sAPIFactory
class hyperpod_checkpointless_training.inprocess.train_utils.HPAgentK8sAPIFactory()
분산 훈련 조정을 위해 HyperPod 인프라와 통신하는 HPAgentK8sAPI 인스턴스를 생성하기 위한 팩토리 클래스입니다.
이 팩토리는 훈련 프로세스와 HyperPod 컨트롤 플레인 간의 통신을 처리하는 HPAgentK8sAPI 객체를 생성하고 구성하는 표준화된 방법을 제공합니다. 기본 소켓 클라이언트 및 API 인스턴스의 생성을 캡슐화하여 훈련 시스템의 여러 부분에서 일관된 구성을 보장합니다.
메서드
__call__()
HyperPod 통신을 위해 구성된 HPAgentK8sAPI 인스턴스를 생성하고 반환합니다.
다음을 반환합니다.
HPAgentK8sAPI - HyperPod 인프라와 통신하도록 구성된 API 인스턴스
예제
from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck # Create the factory hp_api_factory = HPAgentK8sAPIFactory() # Use with HPWrapper for fault-tolerant training hp_wrapper = HPWrapper( hp_api_factory=hp_api_factory, health_check=CudaHealthCheck(), abort_timeout=60.0, enabled=True ) @hp_wrapper def training_function(): # Your distributed training code here pass
참고
HyperPod의 Kubernetes 기반 인프라와 원활하게 작동하도록 설계되었습니다. 분산 훈련 시나리오에서 조정된 장애 처리 및 복구에 필수적입니다.
CheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.CheckpointManager( enable_checksum=False, enable_offload=False)
분산 훈련에서 체크포인트 없는 내결함성을 위한 인 메모리 체크포인트 및 peer-to-peer 복구를 관리합니다.
이 클래스는 메모리에서 NeMo 모델 체크포인트를 관리하고, 복구 타당성을 검증하고, 정상 순위와 실패한 순위 간의 peer-to-peer 체크포인트 전송을 오케스트레이션하여 HyperPod 체크포인트리스 훈련을 위한 핵심 기능을 제공합니다. 복구 중에 디스크 I/O가 필요하지 않으므로 평균 복구 시간(MTTR)이 크게 줄어듭니다.
파라미터
enable_checksum(bool, 선택 사항) - 복구 중 무결성 검사에 대한 모델 상태 체크섬 검증을 활성화합니다. 기본값:
Falseenable_offload(bool, 선택 사항) - GPU 메모리 사용량을 줄이기 위해 GPU에서 CPU 메모리로 체크포인트 오프로드를 활성화합니다. 기본값:
False
속성
global_step(int 또는 None) - 저장된 체크포인트와 연결된 현재 훈련 단계
rng_states(목록 또는 없음) - 결정적 복구를 위해 저장된 난수 생성기 상태
checksum_manager(MemoryChecksumManager) – 모델 상태 체크섬 검증을 위한 관리자
parameter_update_lock(ParameterUpdateLock) - 복구 중 파라미터 업데이트를 조정하기 위한 잠금
메서드
save_checkpoint(trainer)
잠재적인 체크포인트 없는 복구를 위해 NeMo 모델 체크포인트를 메모리에 저장합니다.
파라미터:
트레이너(pytorch_lightning.Trainer) – PyTorch Lightning 트레이너 인스턴스
참고:
배치 종료 시 또는 예외 처리 중에 CheckpointlessCallback에서 호출
디스크 I/O 오버헤드 없이 복구 시점 생성
전체 모델, 최적화 프로그램 및 스케줄러 상태를 저장합니다.
delete_checkpoint()
인 메모리 체크포인트를 삭제하고 정리 작업을 수행합니다.
참고:
체크포인트 데이터, RNG 상태 및 캐시된 텐서를 지웁니다.
가비지 수집 및 CUDA 캐시 정리 수행
복구 성공 후 또는 체크포인트가 더 이상 필요하지 않을 때 호출됩니다.
try_checkpointless_load(trainer)
피어 순위에서 상태를 로드하여 체크포인트 없는 복구를 시도합니다.
파라미터:
트레이너(pytorch_lightning.Trainer) – PyTorch Lightning 트레이너 인스턴스
다음을 반환합니다.
dict 또는 None - 성공한 경우 체크포인트를 복원하고, 디스크로 대체해야 하는 경우 없음
참고:
체크포인트 없는 복구를 위한 기본 진입점
P2P 전송을 시도하기 전에 복구 가능성을 검증합니다.
복구 시도 후 항상 인 메모리 체크포인트 정리
checkpointless_recovery_feasible(trainer, include_checksum_verification=True)
현재 장애 시나리오에서 체크포인트 없는 복구가 가능한지 확인합니다.
파라미터:
트레이너(pytorch_lightning.Trainer) – PyTorch Lightning 트레이너 인스턴스
include_checksum_verification(bool, 선택 사항) - 체크섬 검증을 포함할지 여부입니다. 기본값:
True
다음을 반환합니다.
bool - 체크포인트 없는 복구가 가능한 경우 True, 그렇지 않으면 False
검증 기준:
정상 순위에서의 글로벌 단계 일관성
복구에 사용할 수 있는 충분한 정상 복제본
모델 상태 체크섬 무결성(활성화된 경우)
store_rng_states()
결정적 복구를 위해 모든 난수 생성기 상태를 저장합니다.
참고:
Python, NumPy, PyTorch CPU/GPU 및 Megatron RNG 상태 캡처
복구 후 훈련 결정성을 유지하는 데 필수
load_rng_states()
결정적 복구 지속을 위해 모든 RNG 상태를 복원합니다.
참고:
이전에 저장된 모든 RNG 상태를 복원합니다.
동일한 무작위 시퀀스로 훈련이 계속되도록 보장
maybe_offload_checkpoint()
오프로드가 활성화된 경우 GPU에서 CPU 메모리로 체크포인트를 오프로드합니다.
참고:
대규모 모델의 GPU 메모리 사용량 감소
다음 경우에만 실행됩니다.
enable_offload=True복구를 위한 체크포인트 접근성 유지
예제
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=CheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
검증: 체크섬을 사용하여 체크포인트 무결성을 확인합니다(활성화된 경우).
참고
효율적인 P2P 전송을 위해 분산 통신 프리미티브 사용
텐서 유형 변환 및 디바이스 배치 자동 처리
MemoryChecksumManager - 모델 상태 무결성 검증을 처리합니다.
PEFTCheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.PEFTCheckpointManager( *args, **kwargs)
최적화된 체크포인트 없는 복구를 위해 별도의 기본 및 어댑터 처리로 PEFT(Parameter-Efficient Fine-Tuning)에 대한 체크포인트를 관리합니다.
이 특수 체크포인트 관리자는 어댑터 파라미터와 기본 모델 가중치를 분리하여 CheckpointManager를 확장하여 PEFT 워크플로를 최적화합니다.
파라미터
CheckpointManager에서 모든 파라미터를 상속합니다.
enable_checksum(bool, 선택 사항) - 모델 상태 체크섬 검증을 활성화합니다. 기본값:
Falseenable_offload(bool, 선택 사항) - CPU 메모리로 체크포인트 오프로드를 활성화합니다. 기본값:
False
추가 속성
params_to_save(set) - 어댑터 파라미터로 저장해야 하는 파라미터 이름 세트
base_model_weights(dict 또는 None) - 캐싱된 기본 모델 가중치, 한 번 저장되고 재사용됨
base_model_keys_to_extract(목록 또는 없음) - P2P 전송 중에 기본 모델 텐서를 추출하기 위한 키
메서드
maybe_save_base_model(trainer)
어댑터 파라미터를 필터링하여 기본 모델 가중치를 한 번 저장합니다.
파라미터:
트레이너(pytorch_lightning.Trainer) – PyTorch Lightning 트레이너 인스턴스
참고:
첫 번째 호출 시에만 기본 모델 가중치를 저장하며, 후속 호출은 no-ops입니다.
어댑터 파라미터를 필터링하여 동결된 기본 모델 가중치만 저장합니다.
기본 모델 가중치는 여러 훈련 세션에서 보존됩니다.
save_checkpoint(trainer)
잠재적인 체크포인트 없는 복구를 위해 NeMo PEFT 어댑터 모델 체크포인트를 메모리에 저장합니다.
파라미터:
트레이너(pytorch_lightning.Trainer) – PyTorch Lightning 트레이너 인스턴스
참고:
기본 모델이 아직 저장되지 않은
maybe_save_base_model()경우 자동으로 호출어댑터 파라미터 및 훈련 상태만 포함하도록 체크포인트를 필터링합니다.
전체 모델 체크포인트에 비해 체크포인트 크기 대폭 감소
try_base_model_checkpointless_load(trainer)
피어 순위에서 상태를 로드하여 PEFT 기본 모델 가중치 체크포인트 없는 복구를 시도합니다.
파라미터:
트레이너(pytorch_lightning.Trainer) – PyTorch Lightning 트레이너 인스턴스
다음을 반환합니다.
dict 또는 None - 성공한 경우 기본 모델 체크포인트를 복원하고, 대체가 필요한 경우 없음
참고:
모델 초기화 중에 기본 모델 가중치를 복구하는 데 사용됩니다.
복구 후 기본 모델 가중치를 정리하지 않음(재사용 방지)
model-weights-only 복구 시나리오에 최적화
try_checkpointless_load(trainer)
피어 순위에서 상태를 로드하여 PEFT 어댑터 가중치 체크포인트 없는 복구를 시도합니다.
파라미터:
트레이너(pytorch_lightning.Trainer) – PyTorch Lightning 트레이너 인스턴스
다음을 반환합니다.
dict 또는 None - 성공한 경우 복원된 어댑터 체크포인트, 대체가 필요한 경우 없음
참고:
어댑터 파라미터, 최적화 프로그램 상태 및 스케줄러만 복구합니다.
복구 성공 후 옵티마이저 및 스케줄러 상태를 자동으로 로드합니다.
복구 시도 후 어댑터 체크포인트를 정리합니다.
is_adapter_key(key)
상태 지정 키가 어댑터 파라미터에 속하는지 확인합니다.
파라미터:
키(str 또는 튜플) - 확인할 상태 지정 키
다음을 반환합니다.
bool - 키가 어댑터 파라미터인 경우 True, 기본 모델 파라미터인 경우 False
탐지 로직:
키가
params_to_save설정되어 있는지 확인합니다.".adapter"가 포함된 키를 식별합니다. substring
".adapters"로 끝나는 키를 식별합니다.
튜플 키의 경우 파라미터에 그라데이션이 필요한지 확인합니다.
maybe_offload_checkpoint()
GPU에서 CPU 메모리로 기본 모델 가중치를 오프로드합니다.
참고:
기본 모델 가중치 오프로드 처리를 위해 상위 메서드 확장
어댑터 가중치는 일반적으로 작으며 오프로드할 필요가 없습니다.
오프로드 상태를 추적하도록 내부 플래그를 설정합니다.
참고
파라미터 효율성 미세 조정 시나리오(LoRA, 어댑터 등)를 위해 특별히 설계됨
기본 모델 및 어댑터 파라미터의 분리를 자동으로 처리
예제
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import PEFTCheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=PEFTCheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
CheckpointlessAbortManager
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessAbortManager()
체크포인트 없는 내결함성을 위해 중단 구성 요소 구성을 생성하고 관리하기 위한 팩토리 클래스입니다.
이 유틸리티 클래스는 HyperPod 체크포인트 없는 훈련에서 장애 처리 중에 사용되는 중단 구성 요소 구성을 생성, 사용자 지정 및 관리하는 정적 방법을 제공합니다. 장애 복구 중에 분산 훈련 구성 요소, 데이터 로더 및 프레임워크별 리소스의 정리를 처리하는 중단 시퀀스의 구성을 간소화합니다.
파라미터
없음(모든 메서드가 정적임)
정적 메서드
get_default_checkpointless_abort()
모든 표준 중단 구성 요소가 포함된 기본 중단 구성 인스턴스를 가져옵니다.
다음을 반환합니다.
Compose - 모든 중단 구성 요소가 포함된 기본 구성 중단 인스턴스
기본 구성 요소:
AbortTransformerEngine() - TransformerEngine 리소스를 정리합니다.
HPCheckpointingAbort() - 체크포인트 시스템 정리를 처리합니다.
HPAbortTorchDistributed() - PyTorch 분산 작업을 중단합니다.
HPDataLoaderAbort() - 데이터 로더를 중지하고 정리합니다.
create_custom_abort(abort_instances)
지정된 중단 인스턴스만 사용하여 사용자 지정 중단 구성을 생성합니다.
파라미터:
abort_instances(중단) - compose에 포함할 중단 인스턴스의 가변 수
다음을 반환합니다.
Compose - 지정된 구성 요소만 포함하는 새로 구성된 중단 인스턴스
상승:
ValueError - 중단 인스턴스가 제공되지 않은 경우
override_abort(abort_compose, abort_type, new_abort)
Compose 인스턴스의 특정 중단 구성 요소를 새 구성 요소로 바꿉니다.
파라미터:
abort_compose(Compose) - 수정할 원래 Compose 인스턴스입니다.
abort_type(유형) - 교체할 중단 구성 요소의 유형(예:
HPCheckpointingAbort)new_abort(중단) - 대체로 사용할 새 중단 인스턴스
다음을 반환합니다.
Compose - 지정된 구성 요소가 교체된 새 Compose 인스턴스
상승:
ValueError – abort_compose에 'instances' 속성이 없는 경우
예제
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager # The strategy automatically integrates with HPWrapper @HPWrapper( abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), health_check=CudaHealthCheck(), finalize=CheckpointlessFinalizeCleanup(), enabled=True ) def training_function(): trainer.fit(...)
참고
사용자 지정 구성을 통해 정리 동작을 미세 조정할 수 있습니다.
중단 작업은 장애 복구 중 적절한 리소스 정리에 중요합니다.
CheckpointlessFinalizeCleanup
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessFinalizeCleanup()
장애 감지 후 포괄적인 정리를 수행하여 체크포인트 없는 훈련 중에 프로세스 중 복구를 준비합니다.
이 마무리 핸들러는 훈련 구성 요소 참조를 삭제하여 Megatron/TransformerEngine 중단, DDP 정리, 모듈 다시 로드 및 메모리 정리를 포함한 프레임워크별 정리 작업을 실행합니다. 이를 통해 전체 프로세스 종료 없이 성공적인 프로세스 중 복구를 위해 훈련 환경을 올바르게 재설정할 수 있습니다.
파라미터
없음
속성
트레이너(pytorch_lightning.Trainer 또는 없음) - PyTorch Lightning 트레이너 인스턴스에 대한 참조
메서드
__call__(*a, **kw)
프로세스 중 복구 준비를 위해 포괄적인 정리 작업을 실행합니다.
파라미터:
a - 가변 위치 인수(최종 인터페이스에서 상속됨)
kw - 변수 키워드 인수(최종 인터페이스에서 상속됨)
정리 작업:
Megatron 프레임워크 정리 - Megatron별 리소스를 정리
abort_megatron()하기 위한 호출TransformerEngine 정리 - TransformerEngine 리소스를 정리
abort_te()하기 위한 호출RoPE 정리 - 리소스를 임베딩하는 회전 위치를 정리
cleanup_rope()하기 위한 호출DDP 정리 - DistributedDataParallel 리소스를 정리
cleanup_ddp()하기 위한 호출모듈 다시 로드 - 프레임워크 모듈을 다시 로드
reload_megatron_and_te()하기 위한 호출번개 모듈 정리 - 선택적으로 번개 모듈을 지워 GPU 메모리를 줄입니다.
메모리 정리 - 여유 메모리에 대한 훈련 구성 요소 참조를 폐기합니다.
register_attributes(trainer)
정리 작업 중에 사용할 트레이너 인스턴스를 등록합니다.
파라미터:
트레이너(pytorch_lightning.Trainer) - 등록할 PyTorch Lightning 트레이너 인스턴스
CheckpointlessCallback과 통합
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( ... finalize=CheckpointlessFinalizeCleanup(), ) def training_function(): trainer.fit(...)
참고
정리 작업은 종속성 문제를 방지하기 위해 특정 순서로 실행됩니다.
메모리 정리는 가비지 수집 내부 검사를 사용하여 대상 객체를 찾습니다.
모든 정리 작업은 멱등적이고 안전하게 재시도할 수 있도록 설계되었습니다.
CheckpointlessMegatronStrategy
class hyperpod_checkpointless_training.nemo_plugins.megatron_strategy.CheckpointlessMegatronStrategy(*args, **kwargs)
내결함성 분산 훈련을 위한 통합 체크포인트 없는 복구 기능을 갖춘 NeMo Megatron 전략입니다.
옵티마이저 복제num_distributed_optimizer_instances가 이루어지도록 체크포인트 없는 훈련은 최소 2여야 합니다. 또한이 전략은 필수 속성 등록 및 프로세스 그룹 초기화를 처리합니다.
파라미터
MegatronStrategy에서 모든 파라미터를 상속합니다.
표준 NeMo MegatronStrategy 초기화 파라미터
분산 훈련 구성 옵션
모델 병렬 처리 설정
속성
base_store(torch.distributed.TCPStore 또는 None) - 프로세스 그룹 조정을 위한 분산 저장소
메서드
setup(trainer)
전략을 초기화하고 내결함성 구성 요소를 트레이너에게 등록합니다.
파라미터:
트레이너(pytorch_lightning.Trainer) – PyTorch Lightning 트레이너 인스턴스
설정 작업:
상위 설정 - 상위 MegatronStrategy 설정을 호출합니다.
결함 주입 등록 - 있는 경우 HPFaultInjectionCallback 후크를 등록합니다.
등록 완료 - 정리 핸들러를 완료하도록 트레이너를 등록합니다.
중단 등록 - 이를 지원하는 중단 핸들러에 트레이너를 등록합니다.
setup_distributed()
접두사 또는 루트 없는 연결이 있는 TCPStore를 사용하여 프로세스 그룹을 초기화합니다.
load_model_state_dict(checkpoint, strict=True)
로드 모델 상태는 체크포인트 없는 복구 호환성을 갖습니다.
파라미터:
체크포인트(Mapping[str, Any]) - 모델 상태가 포함된 체크포인트 사전
strict(bool, 선택 사항) - 상태 지정 키 일치를 엄격하게 적용할지 여부입니다. 기본값:
True
get_wrapper()
내결함성 조정을 위해 HPCallWrapper 인스턴스를 가져옵니다.
다음을 반환합니다.
HPCallWrapper - 내결함성을 위해 트레이너에 연결된 래퍼 인스턴스
is_peft()
PEFT 콜백을 확인하여 훈련 구성에서 PEFT(Parameter-Efficient Fine-Tuning)가 활성화되어 있는지 확인
다음을 반환합니다.
bool - PEFT 콜백이 있는 경우 True, 그렇지 않으면 False
teardown()
PyTorch Lightning 네이티브 해체를 재정의하여 정리를 중단 핸들러에 위임합니다.
예제
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( checkpoint_manager=checkpoint_manager, enabled=True ) def training_function(): trainer = pl.Trainer(strategy=CheckpointlessMegatronStrategy()) trainer.fit(model, datamodule)
CheckpointlessCallback
class hyperpod_checkpointless_training.nemo_plugins.callbacks.CheckpointlessCallback( enable_inprocess=False, enable_checkpointless=False, enable_checksum=False, clean_tensor_hook=False, clean_lightning_module=False)
NeMo 훈련을 체크포인트 없는 훈련의 내결함성 시스템과 통합하는 조명 콜백입니다.
이 콜백은 프로세스 중 복구 기능을 위한 단계 추적, 체크포인트 저장 및 파라미터 업데이트 조정을 관리합니다. PyTorch Lightning 훈련 루프와 HyperPod 체크포인트 없는 훈련 메커니즘 간의 기본 통합 지점 역할을 하여 훈련 수명 주기 전반에 걸쳐 내결함성 작업을 조정합니다.
파라미터
enable_inprocess(bool, 선택 사항) - 프로세스 내 복구 기능을 활성화합니다. 기본값:
Falseenable_checkpointless(bool, 선택 사항) - 체크포인트 없는 복구를 활성화합니다( 필요
enable_inprocess=True). 기본값:Falseenable_checksum(bool, 선택 사항) - 모델 상태 체크섬 검증을 활성화합니다( 필수
enable_checkpointless=True). 기본값:Falseclean_tensor_hook(부울, 선택 사항) - 정리(비용이 많이 드는 작업) 중에 모든 GPU 텐서에서 텐서 후크를 지웁니다. 기본값:
Falseclean_lightning_module(bool, 선택 사항) - Lightning 모듈 정리를 활성화하여 다시 시작할 때마다 GPU 메모리를 확보합니다. 기본값:
False
속성
try_adapter_checkpointless(bool) - 어댑터 체크포인트 없는 복원을 시도했는지 추적하는 플래그
메서드
get_wrapper_from_trainer(trainer)
내결함성 조정을 위해 트레이너로부터 HPCallWrapper 인스턴스를 가져옵니다.
파라미터:
트레이너(pytorch_lightning.Trainer) – PyTorch Lightning 트레이너 인스턴스
다음을 반환합니다.
HPCallWrapper - 내결함성 작업을 위한 래퍼 인스턴스
on_train_batch_start(trainer, pl_module, batch, batch_idx, *args, **kwargs)
단계 추적 및 복구를 관리하기 위해 각 훈련 배치가 시작될 때 호출됩니다.
파라미터:
트레이너(pytorch_lightning.Trainer) – PyTorch Lightning 트레이너 인스턴스
pl_module(pytorch_lightning.LightningModule) – 훈련 중인 조명 모듈
배치 - 현재 훈련 배치 데이터
batch_idx(int) - 현재 배치의 인덱스
args - 추가 위치 인수
kwargs - 추가 키워드 인수
on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx)
각 훈련 배치가 끝날 때 파라미터 업데이트 잠금을 해제합니다.
파라미터:
트레이너(pytorch_lightning.Trainer) – PyTorch Lightning 트레이너 인스턴스
pl_module(pytorch_lightning.LightningModule) – 훈련 중인 조명 모듈
출력(STEP_OUTPUT) - 훈련 단계 출력
배치(임의) - 현재 훈련 배치 데이터
batch_idx(int) - 현재 배치의 인덱스
참고:
잠금 해제 타이밍은 파라미터 업데이트가 완료된 후 체크포인트 없는 복구를 진행할 수 있도록 보장합니다.
enable_inprocess및가 모두 True인 경우에만 실행enable_checkpointless됩니다.
get_peft_callback(trainer)
강사의 콜백 목록에서 PEFT 콜백을 검색합니다.
파라미터:
트레이너(pytorch_lightning.Trainer) – PyTorch Lightning 트레이너 인스턴스
다음을 반환합니다.
PEFT 또는 없음 - 찾은 경우 PEFT 콜백 인스턴스, 그렇지 않으면 없음
_try_adapter_checkpointless_restore(trainer, params_to_save)
PEFT 어댑터 파라미터에 대한 체크포인트 없는 복원을 시도합니다.
파라미터:
트레이너(pytorch_lightning.Trainer) – PyTorch Lightning 트레이너 인스턴스
params_to_save(set) - 어댑터 파라미터로 저장할 파라미터 이름 세트
참고:
훈련 세션당 한 번만 실행(
tried_adapter_checkpointless플래그로 제어됨)어댑터 파라미터 정보로 체크포인트 관리자를 구성합니다.
예제
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager import pytorch_lightning as pl # Create checkpoint manager checkpoint_manager = CheckpointManager( enable_checksum=True, enable_offload=True ) # Create checkpointless callback with full fault tolerance checkpointless_callback = CheckpointlessCallback( enable_inprocess=True, enable_checkpointless=True, enable_checksum=True, clean_tensor_hook=True, clean_lightning_module=True ) # Use with PyTorch Lightning trainer trainer = pl.Trainer( callbacks=[checkpointless_callback], strategy=CheckpointlessMegatronStrategy() ) # Training with fault tolerance trainer.fit(model, datamodule=data_module)
메모리 관리
clean_tensor_hook: 정리 중에 텐서 후크를 제거합니다(비용이 높지만 철저함).
clean_lightning_module: 다시 시작하는 동안 Lightning 모듈 GPU 메모리 확보
두 옵션 모두 장애 복구 중에 메모리 공간을 줄이는 데 도움이 됩니다.
스레드 세이프 파라미터 업데이트 추적을 위해 ParameterUpdateLock과 조정
CheckpointlessCompatibleConnector
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector.CheckpointlessCompatibleConnector()
체크포인트 없는 복구를 기존 디스크 기반 체크포인트 로드와 통합하는 PyTorch Lightning 체크포인트 커넥터입니다.
이 커넥터는 PyTorch Lightning의를 확장_CheckpointConnector하여 체크포인트 없는 복구와 표준 체크포인트 복원 간의 원활한 통합을 제공합니다. 체크포인트 없는 복구를 먼저 시도한 다음 체크포인트 없는 복구가 불가능하거나 실패할 경우 디스크 기반 체크포인트 로드로 돌아갑니다.
파라미터
_CheckpointConnector에서 모든 파라미터를 상속합니다.
메서드
resume_start(checkpoint_path=None)
체크포인트 없는 복구 우선 순위로 체크포인트를 사전 로드하려고 시도합니다.
파라미터:
checkpoint_path(str 또는 None, 선택 사항) - 폴백을 위한 디스크 체크포인트 경로입니다. 기본값:
None
resume_end()
체크포인트 로드 프로세스를 완료하고 로드 후 작업을 수행합니다.
참고
체크포인트 없는 복구 지원을 통해 PyTorch Lightning의 내부
_CheckpointConnector클래스 확장표준 PyTorch Lightning 체크포인트 워크플로와의 완전한 호환성 유지
CheckpointlessAutoResume
class hyperpod_checkpointless_training.nemo_plugins.resume.CheckpointlessAutoResume()
지연된 설정으로 NeMo의 AutoResume을 확장하여 체크포인트 경로 확인 전에 체크포인트 없는 복구 검증을 활성화합니다.
이 클래스는 기존 디스크 기반 체크포인트 로드로 돌아가기 전에 체크포인트 없는 복구 검증을 수행할 수 있는 2단계 초기화 전략을 구현합니다. 조기 체크포인트 경로 확인을 방지하기 위해 조건부로 AutoResume 설정을 지연시켜 CheckpointManager가 먼저 체크포인트 없는 peer-to-peer 복구가 가능한지 검증할 수 있도록 합니다.
파라미터
AutoResume에서 모든 파라미터를 상속합니다.
메서드
setup(trainer, model=None, force_setup=False)
체크포인트 없는 복구 검증을 활성화하려면 AutoResume 설정을 조건부로 지연시킵니다.
파라미터:
트레이너(pytorch_lightning.Trainer 또는 lightning.fabric.Fabric) – PyTorch Lightning 트레이너 또는 Fabric 인스턴스
model(선택 사항) - 설정을 위한 모델 인스턴스입니다. 기본값:
Noneforce_setup(bool, 선택 사항) - True인 경우 지연을 우회하고 AutoResume 설정을 즉시 실행합니다. 기본값:
False
예제
from hyperpod_checkpointless_training.nemo_plugins.resume import CheckpointlessAutoResume from hyperpod_checkpointless_training.nemo_plugins.megatron_strategy import CheckpointlessMegatronStrategy import pytorch_lightning as pl # Create trainer with checkpointless auto-resume trainer = pl.Trainer( strategy=CheckpointlessMegatronStrategy(), resume=CheckpointlessAutoResume() )
참고
체크포인트 없는 복구를 활성화하기 위한 지연 메커니즘으로 NeMo의 AutoResume 클래스 확장
완전한 복구 워크플로를
CheckpointlessCompatibleConnector위해와 함께 작동
