기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
메모리 매핑된 데이터 로더
또 다른 재시작 오버헤드는 데이터 로드에서 비롯됩니다. 즉, 데이터 로더가 초기화되고 원격 파일 시스템에서 데이터를 다운로드하여 배치로 처리하는 동안 훈련 클러스터는 유휴 상태로 유지됩니다.
이를 해결하기 위해 Memory Mapped DataLoader(MMAP) Dataloader를 소개합니다.이 Dataloader는 미리 가져온 배치를 영구 메모리에 캐싱하여 장애로 인한 재시작 후에도 계속 사용할 수 있도록 합니다. 이 접근 방식을 사용하면 데이터 로더 설정 시간을 없애고 캐시된 배치를 사용하여 훈련을 즉시 재개할 수 있으며, 데이터 로더는 동시에 백그라운드에서 후속 데이터를 다시 초기화하고 가져올 수 있습니다. 데이터 캐시는 훈련 데이터가 필요한 각 순위에 상주하며 최근 훈련에 사용된 배치와 즉시 사용할 수 있도록 미리 가져온 배치라는 두 가지 유형의 배치를 유지합니다.
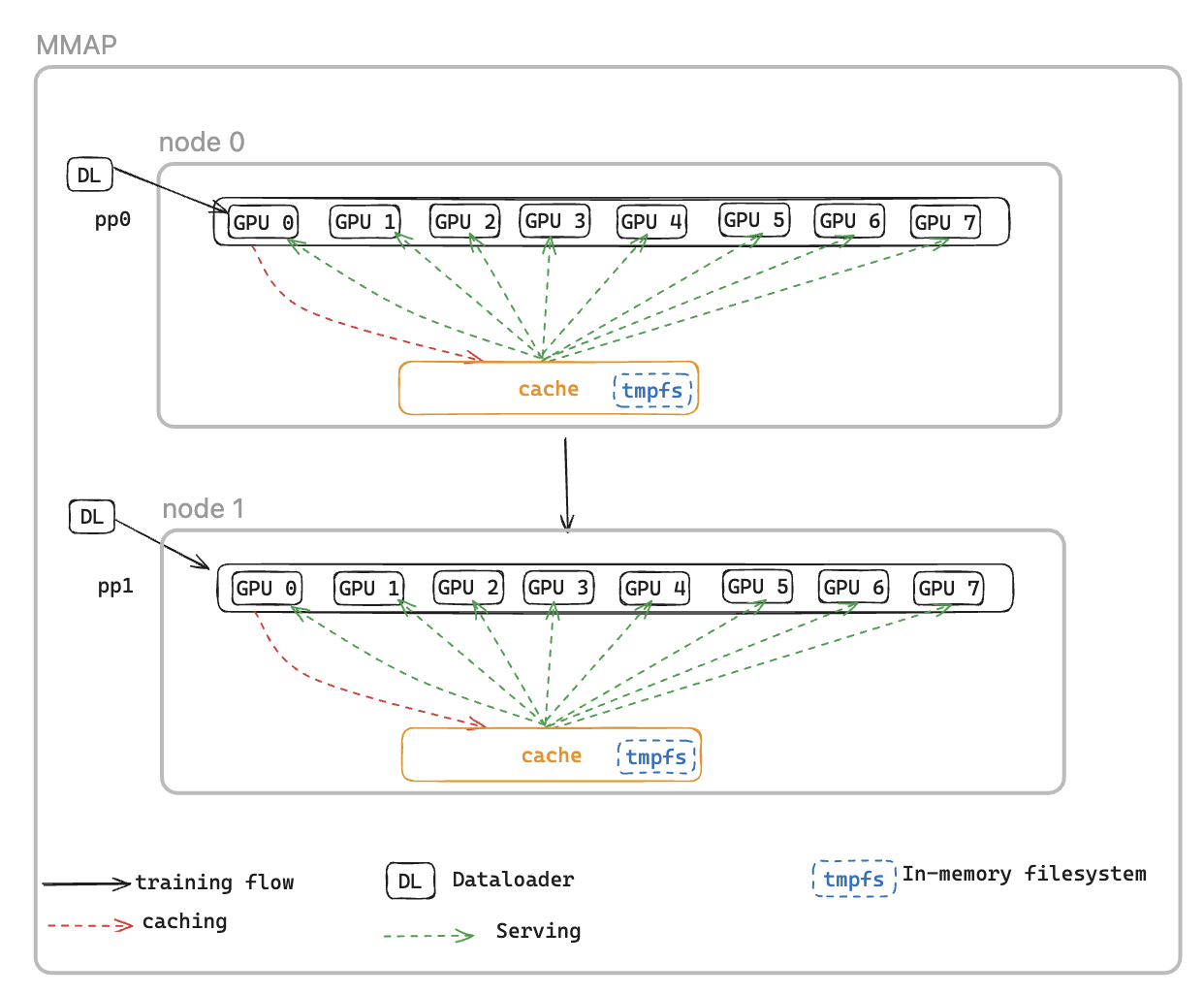
MMAP 데이터 로더는 다음 두 가지 기능을 제공합니다.
데이터 미리 가져오기 - 데이터 로더에서 생성된 데이터를 사전에 가져오고 캐싱합니다.
영구 캐싱 - 프로세스 재시작 후에도 유지되는 임시 파일 시스템에 사용된 배치와 미리 가져온 배치를 모두 저장합니다.
캐시를 사용하면 훈련 작업의 이점을 누릴 수 있습니다.
메모리 공간 감소 - 메모리 매핑 I/O를 활용하여 호스트 CPU 메모리에서 데이터의 단일 공유 복사본을 유지 관리하여 GPU 프로세스 전반에서 중복 복사본을 제거합니다(예: GPUs가 8개인 p5 인스턴스에서 8개 복사본에서 1개로 감소).
더 빠른 복구 - 캐시된 배치에서 즉시 훈련을 재개하여 데이터 로더 재초기화 및 첫 번째 배치 생성에 대한 대기를 제거하여 평균 재시작 시간(MTTR)을 줄입니다.
MMAP 구성
MMAP를 사용하려면 원래 데이터 모듈을에 전달하기만 하면 됩니다. MMAPDataModule
data_module=MMAPDataModule( data_module=MY_DATA_MODULE(...), mmap_config=CacheResumeMMAPConfig( cache_dir=self.cfg.mmap.cache_dir, checkpoint_frequency=self.cfg.mmap.checkpoint_frequency), )
CacheResumeMMAPConfig: MMAP Dataloader 파라미터는 캐시 디렉터리 위치, 크기 제한 및 데이터 가져오기 위임을 제어합니다. 기본적으로 노드당 TP 순위 0만 소스에서 데이터를 가져오고, 동일한 데이터 복제 그룹의 다른 순위는 공유 캐시에서 읽어 중복 전송을 제거합니다.
MMAPDataModule: 원본 데이터 모듈을 래핑하고 훈련 및 검증을 위해 mmap 데이터 로더를 반환합니다.
MMAP 활성화 예제를
API 참조
CacheResumeMMAPConfig
class hyperpod_checkpointless_training.dataloader.config.CacheResumeMMAPConfig( cache_dir='/dev/shm/pdl_cache', prefetch_length=10, val_prefetch_length=10, lookback_length=2, checkpoint_frequency=None, model_parallel_group=None, enable_batch_encryption=False)
HyperPod 체크포인트 없는 훈련에서 캐시 재개 메모리 매핑(MMAP) 데이터 로더 기능을 위한 구성 클래스입니다.
이 구성을 사용하면 캐싱 및 미리 가져오기 기능을 사용하여 데이터를 효율적으로 로드할 수 있으므로 메모리 매핑 파일에 캐시된 데이터 배치를 유지하여 실패 후 훈련을 빠르게 재개할 수 있습니다.
파라미터
-
cache_dir(str, 선택 사항) - 캐시된 데이터 배치를 저장하기 위한 디렉터리 경로입니다. 기본값: "/dev/shm/pdl_cache"
-
prefetch_length(int, 선택 사항) - 훈련 중에 미리 가져올 배치 수입니다. 기본값: 10
-
val_prefetch_length(int, 선택 사항) - 검증 중에 미리 가져올 배치 수입니다. 기본값: 10
-
lookback_length(int, 선택 사항) - 재사용 가능성을 위해 캐시에 유지할 이전에 사용된 배치 수입니다. 기본값: 2
-
checkpoint_frequency(int, 선택 사항) - 모델 체크포인트 단계의 빈도입니다. 캐시 성능 최적화에 사용됩니다. 기본값: None
-
model_parallel_group(객체, 선택 사항) - 모델 병렬 처리를 위한 프로세스 그룹입니다. 없는 경우가 자동으로 생성됩니다. 기본값: None
-
enable_batch_encryption(bool, 선택 사항) - 캐시된 배치 데이터에 대한 암호화를 활성화할지 여부입니다. 기본값: False
메서드
create(dataloader_init_callable, parallel_state_util, step, is_data_loading_rank, create_model_parallel_group_callable, name='Train', is_val=False, cached_len=0)
구성된 MMAP 데이터 로더 인스턴스를 생성하고 반환합니다.
파라미터
-
dataloader_init_callable(통화 가능) - 기본 데이터 로더를 초기화하는 함수
-
parallel_state_util(객체) - 프로세스 간 병렬 상태를 관리하기 위한 유틸리티
-
단계(int) - 훈련 중에 재개할 데이터 단계입니다.
-
is_data_loading_rank(통화 가능) - 현재 순위가 데이터를 로드해야 하는 경우 True를 반환하는 함수
-
create_model_parallel_group_callable(통화 가능) - 모델 병렬 프로세스 그룹을 생성하는 함수
-
name(str, 선택 사항) - 데이터 로더의 이름 식별자입니다. 기본값: "Train"
-
is_val(bool, 선택 사항) - 검증 데이터 로더인지 여부입니다. 기본값: False
-
cached_len(int, 선택 사항) - 기존 캐시에서 재개하는 경우 캐시된 데이터의 길이입니다. 기본값: 0
CacheResumePrefetchedDataLoader 또는 반환 CacheResumeReadDataLoader- 구성된 MMAP 데이터 로더 인스턴스
단계 파라미터가 인 ValueError 경우가 발생합니다None.
예제
from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig # Create configuration config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100, enable_batch_encryption=False ) # Create dataloader dataloader = config.create( dataloader_init_callable=my_dataloader_init, parallel_state_util=parallel_util, step=current_step, is_data_loading_rank=lambda: rank == 0, create_model_parallel_group_callable=create_mp_group, name="TrainingData" )
참고
-
캐시 디렉터리에는 충분한 공간과 빠른 I/O 성능이 있어야 합니다(예: 인 메모리 스토리지의 경우 /dev/shm).
-
를 설정하면 모델 체크포인트에 맞게 캐시 관리를 조정하여 캐시 성능이
checkpoint_frequency향상됩니다. -
검증 데이터 로더(
is_val=True)의 경우 단계가 0으로 재설정되고 콜드 스타트가 강제됩니다. -
현재 순위가 데이터 로드를 담당하는지 여부에 따라 다양한 데이터 로더 구현이 사용됩니다.
MMAPDataModule
class hyperpod_checkpointless_training.dataloader.mmap_data_module.MMAPDataModule( data_module, mmap_config, parallel_state_util=MegatronParallelStateUtil(), is_data_loading_rank=None)
체크포인트 없는 훈련을 위해 기존 DataModules에 메모리 매핑(MMAP) 데이터 로드 기능을 적용하는 PyTorch Lightning DataModules.
이 클래스는 기존 PyTorch Lightning DataModule을 래핑하고 MMAP 기능으로 개선하여 훈련 실패 시 효율적인 데이터 캐싱과 빠른 복구를 지원합니다. 체크포인트 없는 훈련 기능을 추가하면서 원래 DataModule 인터페이스와의 호환성을 유지합니다.
파라미터
- data_module(pl.LightningDataModule)
래핑할 기본 DataModule(예: LLMDataModule)
- mmap_config(MMAPConfig)
캐싱 동작 및 파라미터를 정의하는 MMAP 구성 객체
parallel_state_util(MegatronParallelStateUtil, 선택 사항)분산 프로세스에서 병렬 상태를 관리하기 위한 유틸리티입니다. 기본값: MegatronParallelStateUtil()
is_data_loading_rank(통화 가능, 선택 사항)현재 순위가 데이터를 로드해야 하는 경우 True를 반환하는 함수입니다. 없음인 경우 기본값은 parallel_state_util.is_tp_0입니다. 기본값: None
속성
global_step(int)체크포인트에서 재개하는 데 사용되는 현재 글로벌 훈련 단계
cached_train_dl_len(int)훈련 데이터 로더의 캐시 길이
cached_val_dl_len(int)검증 데이터 로더의 캐시 길이
메서드
setup(stage=None)
지정된 훈련 단계에 대한 기본 데이터 모듈을 설정합니다.
stage(str, 선택 사항)훈련 단계('적합', '검증', '테스트' 또는 '예측'). 기본값: None
train_dataloader()
MMAP 래핑을 사용하여 훈련 DataLoader를 생성합니다.
반환: DataLoader – 캐싱 및 미리 가져오기 기능이 있는 MMAP 래핑 훈련 DataLoader
val_dataloader()
MMAP 래핑을 사용하여 검증 DataLoader를 생성합니다.
반환: DataLoader – 캐싱 기능이 있는 MMAP 래핑된 검증 DataLoader
test_dataloader()
기본 데이터 모듈이 지원하는 경우 테스트 DataLoader를 생성합니다.
반환: DataLoader 또는 없음 - 기본 데이터 모듈에서 DataLoader를 테스트하거나 지원되지 않는 경우 없음을 반환합니다.
predict_dataloader()
기본 데이터 모듈이 지원하는 경우 예측 DataLoader를 생성합니다.
반환: DataLoader 또는 없음 - 기본 데이터 모듈에서 DataLoader를 예측하거나 지원되지 않는 경우 없음을 반환합니다. DataLoader
load_checkpoint(checkpoint)
체크포인트 정보를 로드하여 특정 단계에서 훈련을 재개합니다.
- 체크포인트(dict)
'global_step' 키가 포함된 체크포인트 사전
get_underlying_data_module()
기본 래핑된 데이터 모듈을 가져옵니다.
반환: pl.LightningDataModule – 래핑된 원래 데이터 모듈
state_dict()
체크포인트를 위해 MMAP DataModule의 상태 사전을 가져옵니다.
반환: dict – 캐시된 데이터 로더 길이를 포함하는 사전
load_state_dict(state_dict)
상태 사전을 로드하여 MMAP DataModule 상태를 복원합니다.
state_dict(dict)로드할 상태 사전
속성
data_sampler
기본 데이터 모듈의 데이터 샘플러를 NeMo 프레임워크에 노출합니다.
반환: 객체 또는 없음 - 기본 데이터 모듈의 데이터 샘플러
예제
from hyperpod_checkpointless_training.dataloader.mmap_data_module import MMAPDataModule from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig from my_project import MyLLMDataModule # Create MMAP configuration mmap_config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100 ) # Create original data module original_data_module = MyLLMDataModule( data_path="/path/to/data", batch_size=32 ) # Wrap with MMAP capabilities mmap_data_module = MMAPDataModule( data_module=original_data_module, mmap_config=mmap_config ) # Use in PyTorch Lightning Trainer trainer = pl.Trainer() trainer.fit(model, data=mmap_data_module) # Resume from checkpoint checkpoint = {"global_step": 1000} mmap_data_module.load_checkpoint(checkpoint)
참고
래퍼는 __getattr__를 사용하여 기본 데이터 모듈에 대한 대부분의 속성 액세스를 위임합니다.
데이터 로드 순위만 실제로 기본 데이터 모듈을 초기화하고 사용합니다. 다른 순위는 가짜 데이터 로더를 사용합니다.
캐시된 데이터 로더 길이를 유지하여 훈련 재개 중에 성능을 최적화합니다.
