기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
# 다중 모델 엔드포인트 생성
SageMaker AI 콘솔 또는를 사용하여 다중 모델 엔드포인트를 AWS SDK for Python (Boto) 생성할 수 있습니다. 콘솔을 통해 CPU 또는 GPU 지원 엔드포인트를 생성하려면 다음 섹션의 콘솔 절차를 참조하세요. 를 사용하여 다중 모델 엔드포인트를 생성하려면 다음 섹션의 CPU 또는 GPU 절차를 AWS SDK for Python (Boto)사용합니다. CPU 및 GPU 워크플로는 비슷하지만 컨테이너 요구 사항 등 몇 가지 차이점이 있습니다.
**Topics**
+ [다중 모델 엔드포인트 생성(콘솔)](#create-multi-model-endpoint-console)
+ [에서 CPUs를 사용하여 다중 모델 엔드포인트 생성 AWS SDK for Python (Boto3)](#create-multi-model-endpoint-sdk-cpu)
+ [에서 GPUs를 사용하여 다중 모델 엔드포인트 생성 AWS SDK for Python (Boto3)](#create-multi-model-endpoint-sdk-gpu)
## 다중 모델 엔드포인트 생성(콘솔)
콘솔을 통해 CPU 및 GPU 지원 다중 모델 엔드포인트를 모두 생성할 수 있습니다. 다음 절차에 따라 SageMaker AI 콘솔을 통해 다중 모델 엔드포인트를 만듭니다.
**다중 모델 엔드포인트를 생성하려면(콘솔)**
1. [https://console.aws.amazon.com/sagemaker/](https://console.aws.amazon.com/sagemaker/)에서 Amazon SageMaker AI 콘솔을 엽니다.
1. **모델**을 선택한 다음 **추론** 그룹에서 **모델 생성**을 선택합니다.
1. **모델 이름**에 이름을 입력합니다.
1. **IAM 역할**의 경우 `AmazonSageMakerFullAccess` IAM 정책이 연결된 IAM 역할을 선택하거나 생성합니다.
1. **Container definition(컨테이너 정의)** 섹션의 **모델 아티팩트 및 추론 이미지 옵션 제공**에 대해 **다중 모델 사용**를 선택합니다.
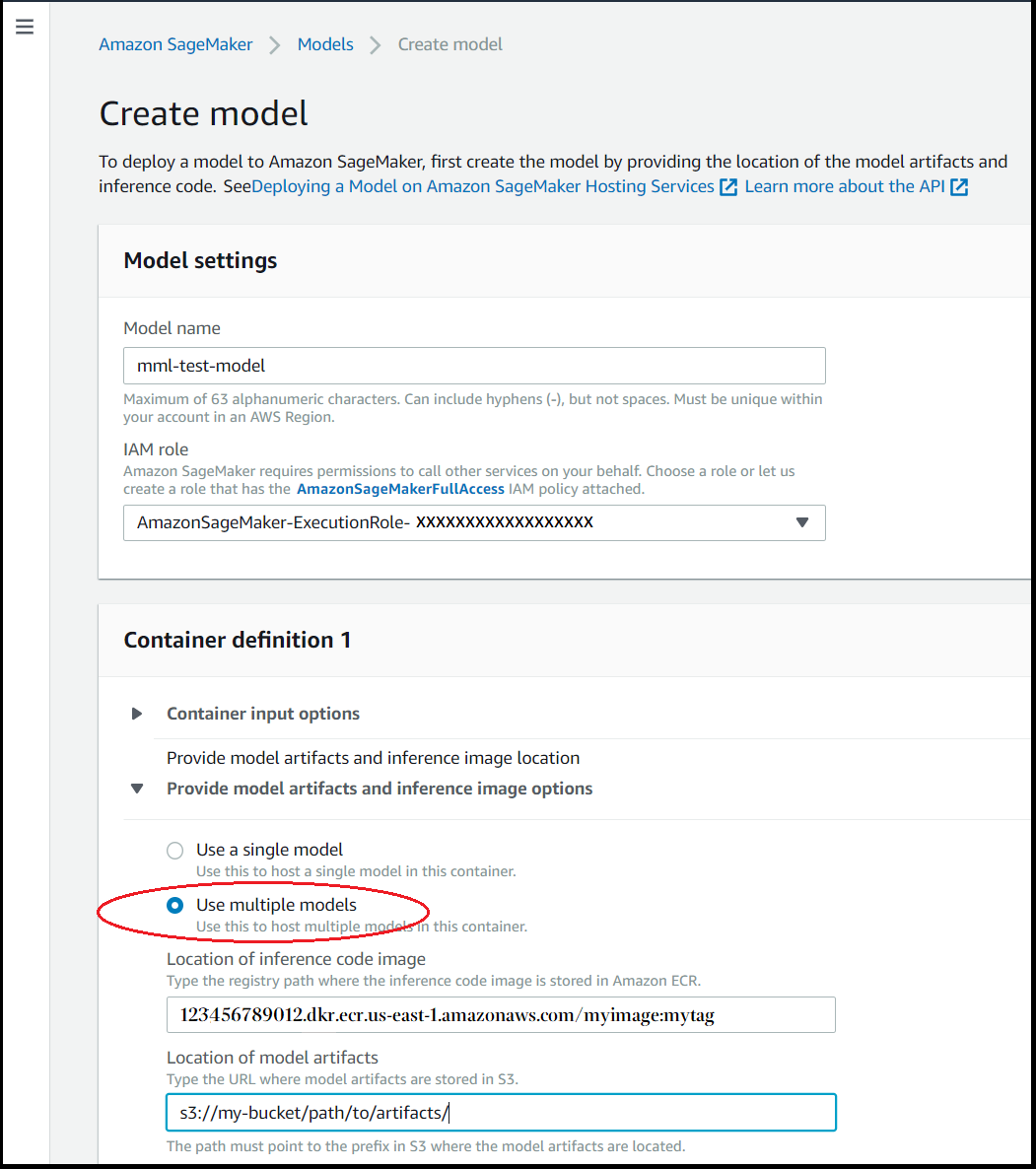
1. **추론 컨테이너 이미지**의 경우 원하는 컨테이너 이미지의 Amazon ECR 경로를 입력합니다.
GPU 모델의 경우 NVIDIA Triton 추론 서버가 지원하는 컨테이너를 사용해야 합니다. GPU 지원 엔드포인트에서 작동하는 컨테이너 이미지 목록은 [NVIDIA Triton 추론 컨테이너(SM 지원만 해당)](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#nvidia-triton-inference-containers-sm-support-only)를 참조하세요. NVIDIA Triton 추론 서버에 대한 자세한 내용은 [Use Triton Inference Server with SageMaker AI](https://docs.aws.amazon.com/sagemaker/latest/dg/triton.html)를 참조하세요.
1. **Create model**(모델 생성)을 선택합니다.
1. 단일 모델 엔드포인트와 마찬가지로 다중 모델 엔드포인트를 배포합니다. 지침은 [SageMaker AI 호스팅 서비스에 모델 배포](ex1-model-deployment.md#ex1-deploy-model) 섹션을 참조하세요.
## 에서 CPUs를 사용하여 다중 모델 엔드포인트 생성 AWS SDK for Python (Boto3)
다음 섹션을 사용하여 CPU 인스턴스로 지원되는 다중 모델 엔드포인트를 생성합니다. 단일 모델 엔드포인트를 만들 때와 마찬가지로 Amazon SageMaker AI [https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_model](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_model), [https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_endpoint_config](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_endpoint_config) 및 [https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_endpoint](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_endpoint) API를 사용하여 다중 모델 엔드포인트를 만듭니다. 단, 2가지 변경 사항이 있습니다. 모델 컨테이너를 정의할 때 새 `Mode` 파라미터 값인 `MultiModel`을 전달해야 합니다. 또한 단일 모델을 배포할 때와 마찬가지로 단일 모델 아티팩트에 대한 경로 대신 모델 아티팩트가 위치한 Amazon S3의 접두사를 지정하는 `ModelDataUrl` 필드로도 이 값을 전달해야 합니다.
SageMaker AI를 사용하여 여러 XGBoost 모델을 엔드포인트에 배포하는 샘플 노트북에 대한 내용은 [다중 모델 엔드포인트 XGBoost 샘플 노트북](https://sagemaker-examples.readthedocs.io/en/latest/advanced_functionality/multi_model_xgboost_home_value/xgboost_multi_model_endpoint_home_value.html)을 참조하세요.
다음 절차에서는 CPU 지원 다중 모델 엔드포인트를 생성하기 위해 해당 샘플에서 사용되는 주요 단계를 간략하게 설명합니다.
**모델을 배포하려면(AWS SDK for Python(Boto 3))**
1. 다중 모델 엔드포인트 배포를 지원하는 이미지가 포함된 컨테이너를 가져오세요. 다중 모델 엔드포인트를 지원하는 기본 제공 알고리즘 및 프레임워크 컨테이너 목록은 [다중 모델 엔드포인트용으로 지원되는 알고리즘, 프레임워크, 인스턴스](multi-model-support.md) 섹션을 참조하세요. 이 예제에서는 [K-Nearest Neighbors(k-NN) 알고리즘](k-nearest-neighbors.md) 기본 제공 알고리즘을 사용합니다. [SageMaker Python SDK](https://sagemaker.readthedocs.io/en/stable/v2.html) 유틸리티 함수 `image_uris.retrieve()`를 호출하여 K-Nearest Neighbors 기본 제공 알고리즘 이미지의 주소를 가져옵니다.
```
import sagemaker
region = sagemaker_session.boto_region_name
image = sagemaker.image_uris.retrieve("knn",region=region)
container = {
'Image': image,
'ModelDataUrl': 's3://{{}}/{{}}',
'Mode': 'MultiModel'
}
```
1. AWS SDK for Python (Boto3) SageMaker AI 클라이언트를 가져와이 컨테이너를 사용하는 모델을 생성합니다.
```
import boto3
sagemaker_client = boto3.client('sagemaker')
response = sagemaker_client.create_model(
ModelName = {{''}},
ExecutionRoleArn = role,
Containers = [container])
```
1. (선택 사항) 직렬 추론 파이프라인을 사용하는 경우 파이프라인에 포함할 추가 컨테이너를 가져와서 `CreateModel`의 `Containers` 인수에 포함시킵니다.
```
preprocessor_container = {
'Image': '{{}}.dkr.ecr.{{}}.amazonaws.com/{{}}:{{}}'
}
multi_model_container = {
'Image': '{{}}.dkr.ecr.{{}}.amazonaws.com/{{}}:{{}}',
'ModelDataUrl': 's3://{{}}/{{}}',
'Mode': 'MultiModel'
}
response = sagemaker_client.create_model(
ModelName = {{''}},
ExecutionRoleArn = role,
Containers = [preprocessor_container, multi_model_container]
)
```
**참고**
직렬 추론 파이프라인에서는 다중 모델 지원 엔드포인트를 하나만 사용할 수 있습니다.
1. (선택 사항) 사용 사례에서 모델 캐싱의 이점을 누리지 못할 경우 `MultiModelConfig` 파라미터의 `ModelCacheSetting` 필드 값을 `Disabled`로 설정하고 `create_model`에 대한 호출의 `Container` 인수에 포함하세요. `ModelCacheSetting` 필드의 값은 기본적으로 `Enabled`입니다.
```
container = {
'Image': image,
'ModelDataUrl': 's3://{{}}/{{}}',
'Mode': 'MultiModel'
'MultiModelConfig': {
// Default value is 'Enabled'
'ModelCacheSetting': 'Disabled'
}
}
response = sagemaker_client.create_model(
ModelName = {{''}},
ExecutionRoleArn = role,
Containers = [container]
)
```
1. 모델에 대한 다중 모델 엔드포인트를 구성합니다. 최소 두 개의 인스턴스로 엔드포인트를 구성하는 것이 좋습니다. 이렇게 하면 SageMaker AI가 모델에서 여러 가용 영역에 걸쳐 고가용성 예측 세트를 제공할 수 있습니다.
```
response = sagemaker_client.create_endpoint_config(
EndpointConfigName = {{''}},
ProductionVariants=[
{
'InstanceType': 'ml.m4.xlarge',
'InitialInstanceCount': 2,
'InitialVariantWeight': 1,
'ModelName': {{''}},
'VariantName': 'AllTraffic'
}
]
)
```
**참고**
직렬 추론 파이프라인에서는 다중 모델 지원 엔드포인트를 하나만 사용할 수 있습니다.
1. `EndpointName` 및 `EndpointConfigName` 파라미터를 사용하여 다중 모델 엔드포인트를 생성합니다.
```
response = sagemaker_client.create_endpoint(
EndpointName = {{''}},
EndpointConfigName = {{''}})
```
## 에서 GPUs를 사용하여 다중 모델 엔드포인트 생성 AWS SDK for Python (Boto3)
다음 섹션을 사용하여 CPU 지원 다중 모델 엔드포인트를 생성합니다. 단일 모델 엔드포인트를 만들 때와 마찬가지로 Amazon SageMaker AI [https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_model](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_model), [https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_endpoint_config](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_endpoint_config) 및 [https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_endpoint](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html#SageMaker.Client.create_endpoint) API를 사용하여 다중 모델 엔드포인트를 만듭니다. 단, 여러 가지 변경 사항이 있습니다. 모델 컨테이너를 정의할 때 새 `Mode` 파라미터 값인 `MultiModel`을 전달해야 합니다. 또한 단일 모델을 배포할 때와 마찬가지로 단일 모델 아티팩트에 대한 경로 대신 모델 아티팩트가 위치한 Amazon S3의 접두사를 지정하는 `ModelDataUrl` 필드로도 이 값을 전달해야 합니다. GPU 지원 다중 모델 엔드포인트의 경우 GPU 인스턴스에서 실행하도록 최적화된 NVIDIA Triton 추론 서버가 포함된 컨테이너도 사용해야 합니다. GPU 지원 엔드포인트에서 작동하는 컨테이너 이미지 목록은 [NVIDIA Triton 추론 컨테이너(SM 지원만 해당)](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#nvidia-triton-inference-containers-sm-support-only)를 참조하세요.
GPU로 지원되는 다중 모델 엔드포인트를 만드는 방법을 보여주는 예시 노트북은 [Amazon SageMaker 다중 모델 엔드포인트를 사용하여 GPU에서 여러 딥 러닝 모델 실행](https://github.com/aws/amazon-sagemaker-examples/blob/main/multi-model-endpoints/mme-on-gpu/cv/resnet50_mme_with_gpu.ipynb)을 참조하세요.
다음 절차에서는 GPU 지원 다중 모델 엔드포인트를 생성하는 주요 단계를 간략하게 설명합니다.
**모델을 배포하려면(AWS SDK for Python(Boto 3))**
1. 컨테이너 이미지를 정의합니다. ResNet 모델에 대한 GPU 지원이 포함된 다중 모델 엔드포인트를 생성하려면 [NVIDIA Triton Server 이미지](https://docs.aws.amazon.com/sagemaker/latest/dg/triton.html)를 사용할 컨테이너를 정의하세요. 이 컨테이너는 다중 모델 엔드포인트를 지원하며 GPU 인스턴스에서 실행하도록 최적화되었습니다. [SageMaker AI Python SDK](https://sagemaker.readthedocs.io/en/stable/v2.html) 유틸리티 함수(`image_uris.retrieve()`)를 직접적으로 호출하여 이미지의 주소를 가져옵니다. 예제:
```
import sagemaker
region = sagemaker_session.boto_region_name
// Find the sagemaker-tritonserver image at
// https://github.com/aws/amazon-sagemaker-examples/blob/main/sagemaker-triton/resnet50/triton_resnet50.ipynb
// Find available tags at https://github.com/aws/deep-learning-containers/blob/master/available_images.md#nvidia-triton-inference-containers-sm-support-only
image = "{{}}.dkr.ecr.{{}}.amazonaws.com/sagemaker-tritonserver:{{}}".format(
account_id=account_id_map[region], region=region
)
container = {
'Image': image,
'ModelDataUrl': 's3://{{}}/{{}}',
'Mode': 'MultiModel',
"Environment": {"SAGEMAKER_TRITON_DEFAULT_MODEL_NAME": "resnet"},
}
```
1. AWS SDK for Python (Boto3) SageMaker AI 클라이언트를 가져와이 컨테이너를 사용하는 모델을 생성합니다.
```
import boto3
sagemaker_client = boto3.client('sagemaker')
response = sagemaker_client.create_model(
ModelName = {{''}},
ExecutionRoleArn = role,
Containers = [container])
```
1. (선택 사항) 직렬 추론 파이프라인을 사용하는 경우 파이프라인에 포함할 추가 컨테이너를 가져와서 `CreateModel`의 `Containers` 인수에 포함시킵니다.
```
preprocessor_container = {
'Image': '{{}}.dkr.ecr.{{}}.amazonaws.com/{{}}:{{}}'
}
multi_model_container = {
'Image': '{{}}.dkr.ecr.{{}}.amazonaws.com/{{}}:{{}}',
'ModelDataUrl': 's3://{{}}/{{}}',
'Mode': 'MultiModel'
}
response = sagemaker_client.create_model(
ModelName = {{''}},
ExecutionRoleArn = role,
Containers = [preprocessor_container, multi_model_container]
)
```
**참고**
직렬 추론 파이프라인에서는 다중 모델 지원 엔드포인트를 하나만 사용할 수 있습니다.
1. (선택 사항) 사용 사례에서 모델 캐싱의 이점을 누리지 못할 경우 `MultiModelConfig` 파라미터의 `ModelCacheSetting` 필드 값을 `Disabled`로 설정하고 `create_model`에 대한 호출의 `Container` 인수에 포함하세요. `ModelCacheSetting` 필드의 값은 기본적으로 `Enabled`입니다.
```
container = {
'Image': image,
'ModelDataUrl': 's3://{{}}/{{}}',
'Mode': 'MultiModel'
'MultiModelConfig': {
// Default value is 'Enabled'
'ModelCacheSetting': 'Disabled'
}
}
response = sagemaker_client.create_model(
ModelName = {{''}},
ExecutionRoleArn = role,
Containers = [container]
)
```
1. 모델에 대한 GPU 지원 인스턴스로 다중 모델 엔드포인트를 구성합니다. 고가용성과 더 높은 캐시 적중 수를 허용하려면 두 개 이상의 인스턴스로 엔드포인트를 구성하는 것이 좋습니다.
```
response = sagemaker_client.create_endpoint_config(
EndpointConfigName = {{''}},
ProductionVariants=[
{
'InstanceType': 'ml.g4dn.4xlarge',
'InitialInstanceCount': 2,
'InitialVariantWeight': 1,
'ModelName': {{''}},
'VariantName': 'AllTraffic'
}
]
)
```
1. `EndpointName` 및 `EndpointConfigName` 파라미터를 사용하여 다중 모델 엔드포인트를 생성합니다.
```
response = sagemaker_client.create_endpoint(
EndpointName = {{''}},
EndpointConfigName = {{''}})
```