기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
DR 오케스트레이터 프레임워크 개요
DR Orchestrator Framework는 AWS 데이터베이스의 리전 간 DR을 오케스트레이션하고 자동화하는 원클릭 솔루션을 제공합니다. AWS Step Functions 및 AWS Lambda를 사용하여 장애 조치 및 장애 복구 중에 필요한 단계를 수행합니다. Step Functions 상태 시스템은 오케스트레이터 설계 내에서 의사 결정을 위한 기반을 제공합니다. 장애 조치 또는 장애 복구 작업을 수행하기 위한 API 작업은 상태 시스템 내에서 호출되는 Lambda 함수로 코딩됩니다. Lambda 함수는 AWS SDK for Python (Boto3)
DR Orchestrator Framework에는 장애 조치 및 장애 복구 단계에 해당하는 두 개의 기본 상태 시스템이 포함되어 있습니다.
Amazon RDS의 경우 장애 조치 단계에서는 리전 간 RDS 읽기 전용 복제본을 독립 실행형 DB 인스턴스로 승격합니다. Amazon Aurora의 경우 드물지만 예기치 않은 중단 중에 기본 리전이 다운되면 라이터 노드를 사용할 수 없습니다. 라이터 노드와 보조 클러스터 간의 복제가 중지됩니다. 글로벌 데이터베이스에서 보조 클러스터를 분리하고 독립 실행형 클러스터로 승격해야 합니다. 애플리케이션은 쓰기 트래픽을 연결하여 독립 실행형 클러스터로 전송할 수 있습니다. 이 동일한 프로세스를 사용하여 글로벌 데이터베이스의 기본 DB 클러스터를 보조 리전으로 전환할 수 있습니다. 다음과 같은 제어된 시나리오에는이 접근 방식을 사용합니다.
-
운영 유지 관리
-
계획된 운영 절차
-
Amazon ElastiCache(Redis OSS) 보조 클러스터를 새 기본 클러스터로 승격
장애 복구 단계에서는 라이브 기본 리전과 새 보조 리전 간에 데이터의 라이브 복제를 설정합니다.
DR Orchestrator는 데이터베이스에만 적용된다는 점을 이해하는 것이 중요합니다. 이러한 데이터베이스를 참조하고 동일한 리전에 있는 모든 애플리케이션에는 별도의 탠덤 장애 조치 솔루션이 필요할 수 있습니다. 데이터베이스가 보조 리전으로 장애 조치되면 새 데이터베이스 인스턴스에 연결하도록 애플리케이션을 업데이트해야 합니다. 새 데이터베이스 인스턴스는 데이터 소스 역할을 합니다.
장애 조치 프로세스
장애 조치를 수행하려면 DR Orchestrator FAILOVER 상태 시스템을 실행합니다. 이 단계에서는 보조 데이터베이스가 이미 보조 리전에 읽기 전용 복제본(Amazon RDS) 또는 보조 클러스터(Amazon Aurora)로 존재합니다. DR Orchestrator FAILOVER 상태 시스템을 실행하면 보조 데이터베이스가 기본 데이터베이스로 승격됩니다.
DR Orchestrator FAILOVER 아키텍처
다음 다이어그램은 DR Orchestrator를 사용할 때 Amazon Aurora에 대한 장애 조치 프로세스의 개념을 보여줍니다. Amazon Aurora와 Amazon ElastiCache는 동일한 워크플로를 사용하지만 상태 시스템과 Lambda 함수가 다릅니다.
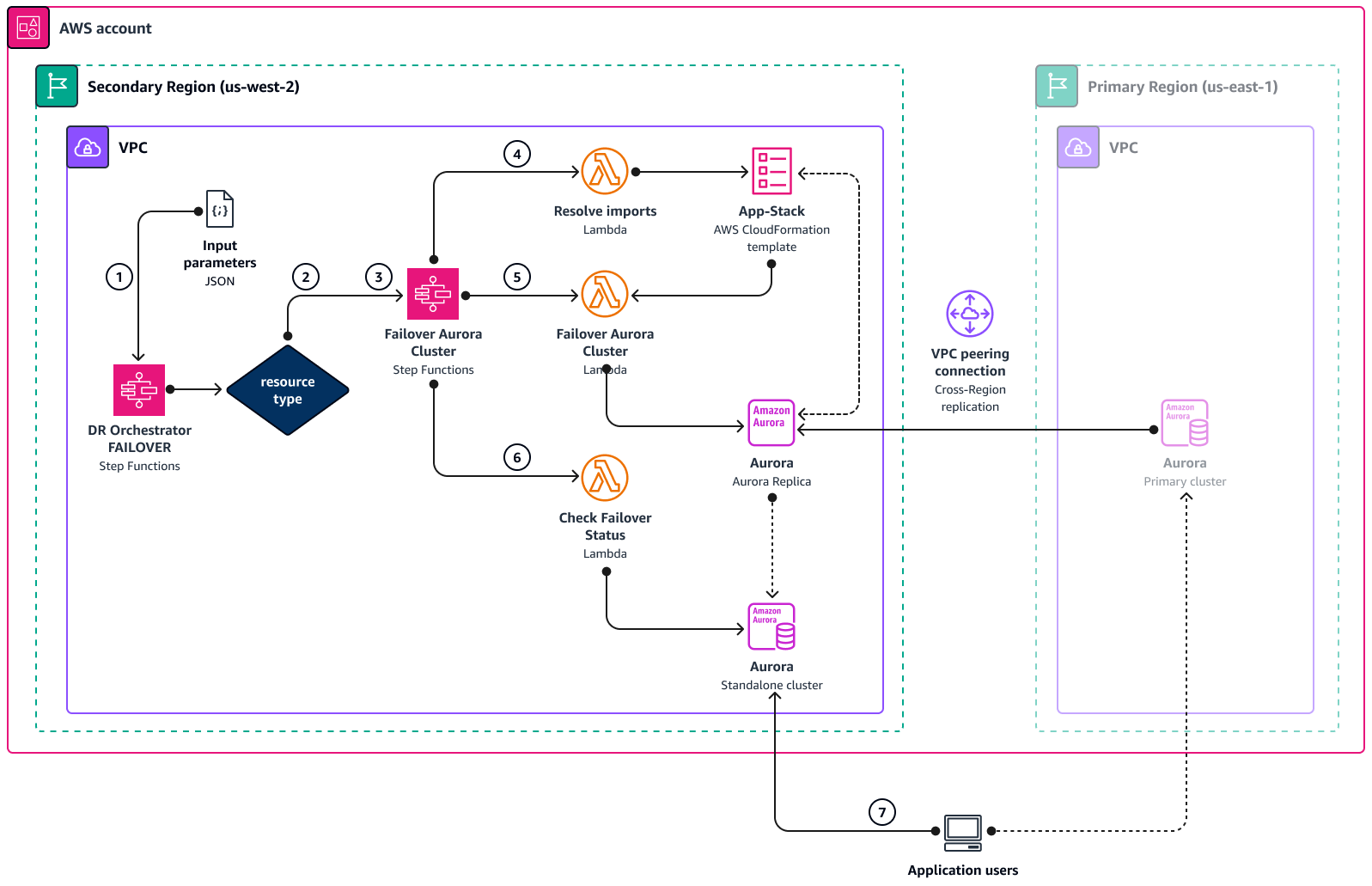
-
DR Orchestrator FAILOVER상태 시스템은 입력 JSON 파라미터를 읽습니다. -
상태 시스템은
resourceType파라미터를 기반으로 ,Failover Aurora Cluster또는Promote RDS Read Replica와 같은 다른 상태 시스템을 호출합니다Failover ElastiCache. 둘 이상의 리소스가 입력에 전달되면 이러한 상태 머신이 병렬로 실행됩니다. -
Failover Aurora Cluster상태 시스템은 다음 세 단계 각각에서 Lambda 함수를 호출합니다. -
Resolve importsLambda 함수는App-StackAWS CloudFormation 템플릿"! import <export-variable-name>"의 실제 값으로 확인됩니다. -
Lambda 함수는
Failover Aurora Cluster읽기 전용 복제본을 독립 실행형 DB 인스턴스로 승격합니다. -
Lambda 함수는
Check Failover Status승격된 DB 인스턴스의 상태를 확인합니다. 상태가 AVAILABLE이면 Lambda 함수는 성공 토큰을 호출 상태 시스템으로 다시 전송하고 완료합니다. -
애플리케이션을 이제 기본 데이터베이스인 DR 리전(
us-west-2)의 독립 실행형 데이터베이스로 리디렉션할 수 있습니다.
장애 복구 프로세스
이전 기본 리전(us-east-1)이 다시 가동되면 다시 실패하여의 데이터베이스가 다시 기본 리전us-east-1이 될 수 있습니다. 장애 복구를 시작하려면 DR Orchestrator FAILBACK 상태 시스템을 실행합니다. 이름에서 알 수 있듯이이 상태 시스템은 새 기본 리전(us-west-2)의 변경 사항을 현재 보조 리전 역할을 하는 이전 기본 리전(us-east-1)으로 다시 복제하기 시작합니다.
두 리전 간에 복제가 설정되면 장애 복구를 시작할 수 있습니다. 페일백하고 원래 기본 리전(us-east-1)으로 돌아가려면 현재 보조 리전(us-east-1)에서 DR Orchestrator FAILOVER 상태 시스템을 실행하여 기본 리전으로 승격합니다.
DR Orchestrator FAILBACK 아키텍처
다음 다이어그램은 DR Orchestrator를 사용할 때 Amazon Aurora에 대한 페일백 프로세스의 개념을 보여줍니다.
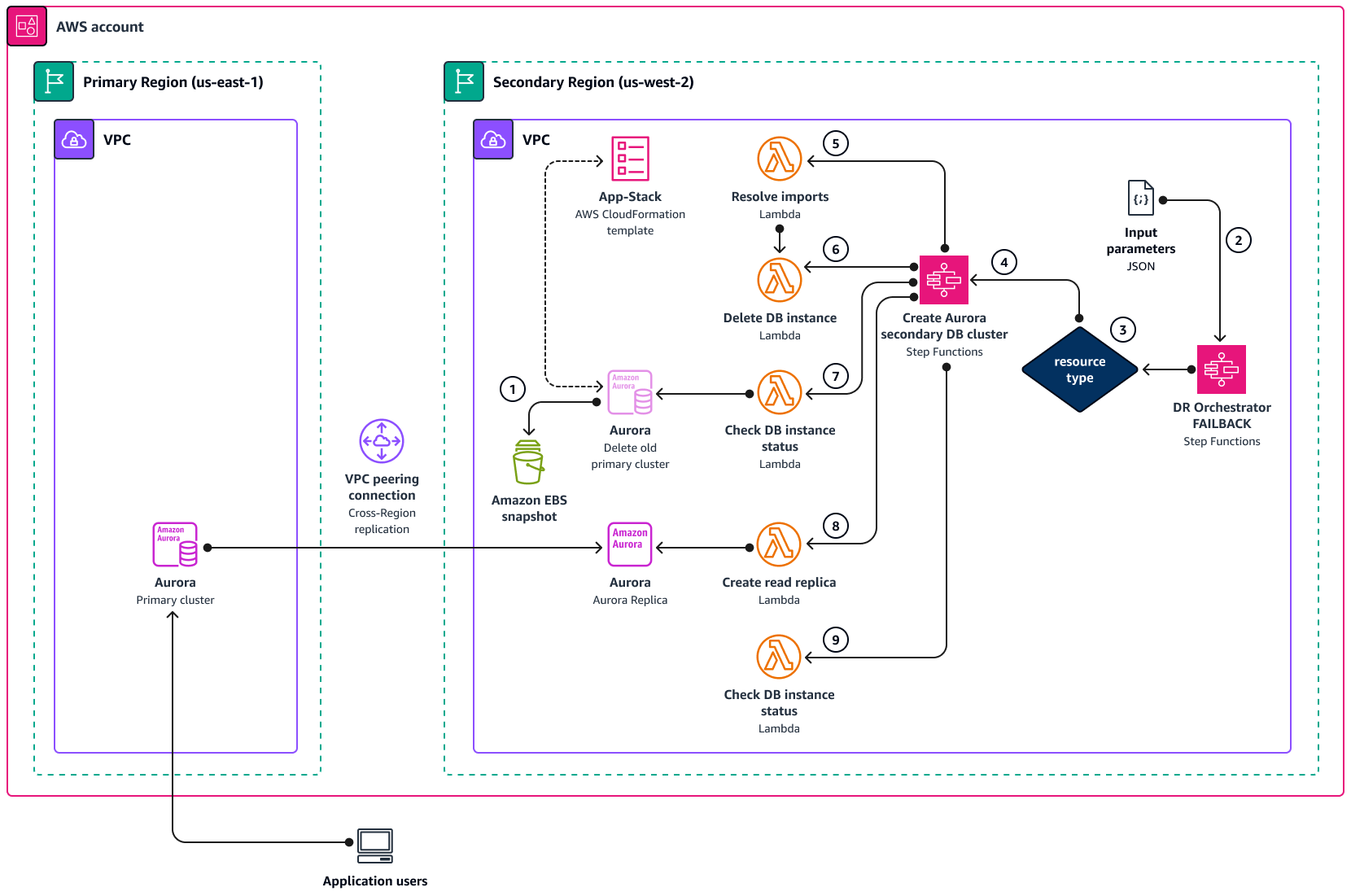
-
장애 복구를 시작하기 전에 근본 원인 분석(RCA)을 수행할 때 사용할 수동 DB 스냅샷을 생성합니다.
또한 이전 기본 리전()에서 Aurora 클러스터에
DeletionProtection대해를 비활성화합니다us-east-1. -
DR Orchestrator FAILBACK상태 시스템은 입력 JSON 파라미터를 읽습니다. -
를 기반으로
resourceTypeDR Orchestrator FAILBACK상태 시스템은Create Aurora Secondary DB Cluster상태 시스템을 호출합니다. -
Create Aurora Secondary DB Cluster상태 시스템은 다음 5단계 각각에서 Lambda 함수를 호출합니다. -
Resolve importLambda 함수는App-StackCloudFormation 템플릿"! import <export-variable-name>"의 실제 값으로 확인됩니다. -
Delete DB InstanceLambda 함수는 이전 기본 인스턴스를 삭제합니다. -
Check DB instance statusLambda 함수는 DB가 삭제Delete DB Instance status될 때까지를 확인합니다. -
Create Read ReplicaLambda 함수는 새 기본 리전에 있는 DB 인스턴스에서 보조 리전에 읽기 전용 복제본을 생성합니다. -
Check DB instance statusLambda 함수는 읽기 전용 복제본 DB 인스턴스 상태를 확인합니다. 상태가 AVAILABLE이면 Lambda 함수는 성공 토큰을 호출 상태 시스템으로 다시 전송하고,이 시스템은 완료됩니다.
DR 오케스트레이터 장애 조치
기본 리전(us-east-1)이 다운되거나 운영 유지 관리와 같은 계획된 이벤트 중에 DR 이벤트에서 DR Orchestrator FAILOVER 상태 시스템을 사용합니다.
함수를 호출하여 단일 또는 여러 데이터베이스를 병렬로 장애 조치할 수 있습니다.
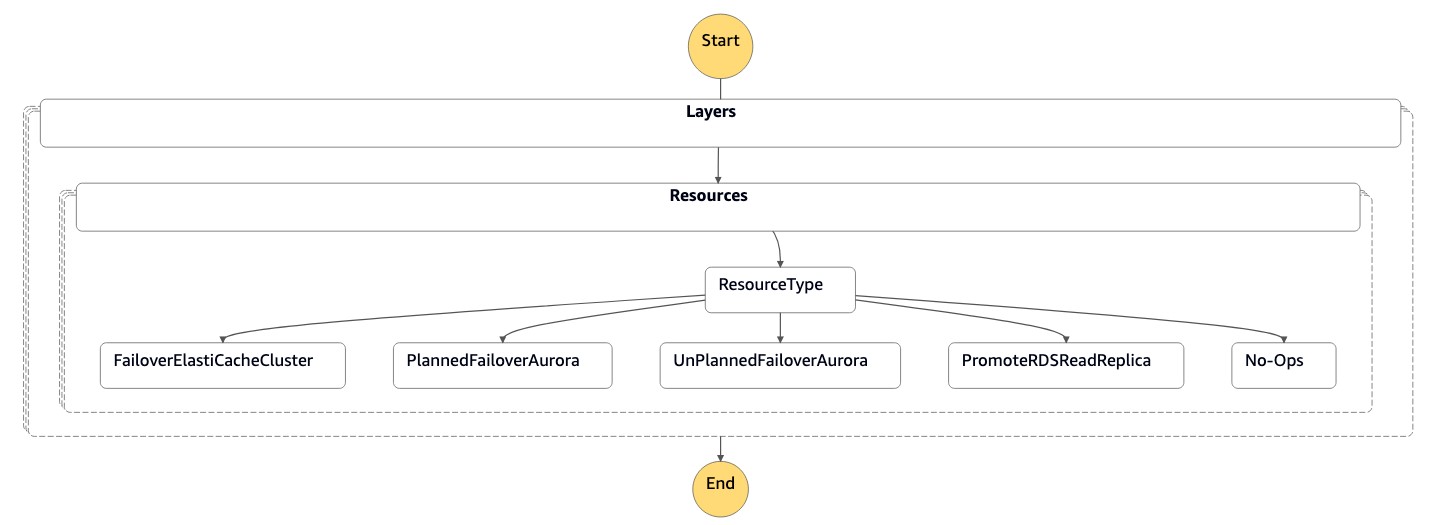
상태 시스템은 다음 코드와 같이 JSON 형식의 파라미터를 수락합니다.
{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "PromoteRDSReadReplica", "resourceName": "Promote RDS MySQL Read Replica", "parameters": { "RDSInstanceIdentifier": "!Import rds-mysql-instance-identifier", "TargetClusterIdentifier": "!Import rds-mysql-instance-global-arn" } }, { "resourceType": "FailoverElastiCacheCluster", "resourceName": "Failover ElastiCache Cluster", "parameters": { "GlobalReplicationGroupId": "!Import demo-redis-cluster-global-replication-group-id", "TargetRegion": "!Import demo-redis-cluster-target-region", "TargetReplicationGroupId": "!Import demo-redis-cluster-target-replication-group-id" } } ] } ] }
파라미터 세부 정보
다음 표에는 DR Orchestrator FAILOVER 상태 시스템에서 사용하는 파라미터가 나와 있습니다.
| 파라미터 이름 | 설명 | 예상 값 |
|---|---|---|
layer (필수: 숫자) |
처리 시퀀스입니다. 계층 2 리소스를 실행하기 전에 계층 1에 정의된 모든 리소스를 실행해야 합니다. | 1 또는 2 등 |
| 리소스(필수: 사전 배열) | 단일 계층 내의 모든 리소스는 병렬로 실행됩니다. |
|
resourceType (필수: 문자열) |
리소스를 식별할 리소스 유형 | PromoteRDSReadReplica 또는 FailoverElastiCacheCluster |
resourceName (선택 사항: 문자열) |
이러한 리소스가 속한 애플리케이션 포트폴리오를 식별하려면 | Promote RDS for MySQL Read Replica |
| 파라미터(필수: 사전 배열) | 데이터베이스 장애 조치 또는 장애 복구에 AWS 필요한 파라미터 목록 |
|
DR 오케스트레이터 장애 조치
이전 기본 리전(us-east-1)이 가동되면 DR 이벤트 후 DR Orchestrator FAILBACK 상태 시스템을 사용합니다. 새 기본 리전(us-west-2)의 이전 기본 리전에서 Amazon RDS에 대한 읽기 전용 복제본을 생성하여 DR 전략을 준수할 수 있습니다. 이 이벤트는 계획된 이벤트이므로 주말에 또는 사용량이 적은 업무 시간에 예상 가동 중지 시간으로이 활동을 예약할 수 있습니다.
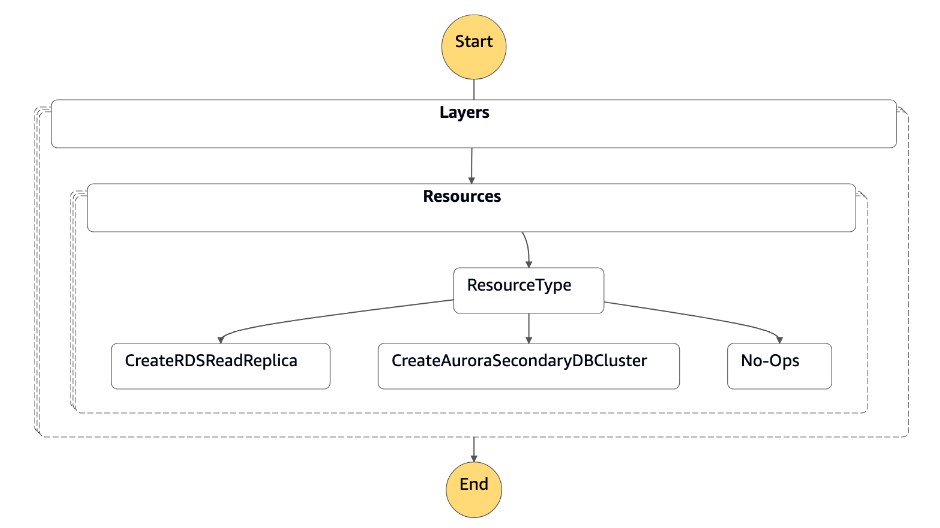
상태 시스템은 다음 코드와 같이 JSON 형식의 파라미터를 수락합니다.
{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "CreateRDSReadReplica", "resourceName": "Create RDS for MySQL Read Replica", "parameters": { "RDSInstanceIdentifier": "!Import rds-mysql-instance-identifier", "TargetClusterIdentifier": "!Import rds-mysql-instance-global-arn", "SourceRDSInstanceIdentifier": "!Import rds-mysql-instance-source-identifier", "SourceRegion": "!Import rds-mysql-instance-SourceRegion", "MultiAZ": "!Import rds-mysql-instance-MultiAZ", "DBInstanceClass": "!Import rds-mysql-instance-DBInstanceClass", "DBSubnetGroup": "!Import rds-mysql-instance-DBSubnetGroup", "DBSecurityGroup": "!Import rds-mysql-instance-DBSecurityGroup", "KmsKeyId": "!Import rds-mysql-instance-KmsKeyId", "BackupRetentionPeriod": "7", "MonitoringInterval": "60", "StorageEncrypted": "True", "EnableIAMDatabaseAuthentication": "True", "DeletionProtection": "True", "CopyTagsToSnapshot": "True", "AutoMinorVersionUpgrade": "True", "Port": "!Import rds-mysql-instance-DBPortNumber", "MonitoringRoleArn": "!Import rds-mysql-instance-RDSMonitoringRole" } } ] } ] }
