기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon OpenSearch Service의 자동 의미 체계 보강
소개
Amazon OpenSearch Service는 word-to-word 일치(어휘 검색)를 사용하여 다른 기존 검색 엔진과 유사한 결과를 찾습니다. 이 접근 방식은 제품 코드 또는 모델 번호와 같은 특정 쿼리에 효과적이지만 사용자 의도를 이해하는 것이 중요해지는 추상 검색에 어려움을 겪습니다. 예를 들어 "Shoes for the Beach"를 검색하면 카탈로그 항목에서 "shoes", "beach", "for" 및 "the"라는 개별 단어와 일치하는 어휘 검색에서 정확한 검색어가 포함되지 않은 "내수성 샌달" 또는 "서핑"과 같은 관련 제품이 누락될 수 있습니다.
자동 의미 체계 강화는 키워드 일치와 검색의 컨텍스트적 의미를 모두 고려하여 이러한 제한을 해결합니다. 이 기능은 검색 의도를 이해하고 검색 관련성을 최대 20% 개선합니다. 인덱스의 텍스트 필드에 대해이 기능을 활성화하여 검색 결과를 개선합니다.
참고
자동 의미 체계 보강은 버전 2.19 이상을 실행하는 OpenSearch Service 도메인에 사용할 수 있습니다. 또한 OpenSearch 버전 2.19를 사용하는 도메인도 최신 서비스 소프트웨어 버전 업데이트 상태여야 합니다. 현재 퍼블릭 도메인에는 기능을 사용할 수 있으며 VPC 도메인은 지원되지 않습니다.
모델 세부 정보 및 성능 벤치마크
이 기능은 기본 모델을 노출하지 않고 백그라운드에서 기술적 복잡성을 처리하지만 간단한 모델 설명과 벤치마크 결과를 통해 투명성을 제공하여 중요한 워크로드의 기능 채택에 대해 정보에 입각한 결정을 내리는 데 도움이 됩니다.
자동 의미 체계 보강은 사용자 지정 미세 조정 없이 효과적으로 작동하는 서비스 관리형 사전 훈련된 희소 모델을 사용합니다. 모델은 지정한 필드를 분석하여 다양한 훈련 데이터에서 학습한 연결을 기반으로 희소 벡터로 확장합니다. 확장된 용어와 중요도 가중치는 효율적인 검색을 위해 네이티브 Lucene 인덱스 형식으로 저장됩니다. 데이터 수집 중에만 인코딩이 이루어지는 문서 전용 모드를
기능 개발 중 성능 검증에서는 평균 334자의 구절이 포함된 MS MARCO
-
영어 - 어휘 검색에 비해 관련성 20% 개선. 또한 P90 검색 지연 시간을 어휘 검색보다 7.7% 낮췄습니다(BM25는 26ms, 자동 의미 체계 보강은 24ms).
-
다국어 - 어휘 검색에 비해 105%의 관련성 개선, 어휘 검색에 비해 P90 검색 지연 시간이 38.4% 증가했습니다(BM25는 26ms, 자동 의미 체계 보강은 36ms).
각 워크로드의 고유한 특성을 고려하여 구현 결정을 내리기 전에 자체 벤치마킹 기준을 사용하여 개발 환경에서이 기능을 평가하는 것이 좋습니다.
지원되는 언어
이 기능은 영어를 지원합니다. 또한이 모델은 아랍어, 벵골어, 중국어, 핀란드어, 프랑스어, 힌디어, 인도네시아어, 일본어, 한국어, 페르시아어, 러시아어, 스페인어, 스와힐리어, 텔루구어도 지원합니다.
도메인에 대한 자동 의미 체계 보강 인덱스 설정
텍스트 필드에 대해 자동 의미 체계 보강이 활성화된 인덱스를 쉽게 설정할 수 있으며 새 인덱스 생성 중에 콘솔, APIs 및 CloudFormation 템플릿을 통해 관리할 수 있습니다. 기존 인덱스에 대해 활성화하려면 텍스트 필드에 대해 자동 의미 체계 보강이 활성화된 인덱스를 다시 생성해야 합니다.
콘솔 환경 - AWS 콘솔을 사용하면 자동 의미 체계 보강 필드를 사용하여 인덱스를 쉽게 생성할 수 있습니다. 도메인을 선택하면 콘솔 상단에 인덱스 생성 버튼이 표시됩니다. 인덱스 생성 버튼을 클릭하면 자동 의미 체계 보강 필드를 정의하는 옵션이 표시됩니다. 하나의 인덱스에서 영어 및 다국어에 대한 자동 의미 체계 보강과 어휘 필드의 조합을 사용할 수 있습니다.
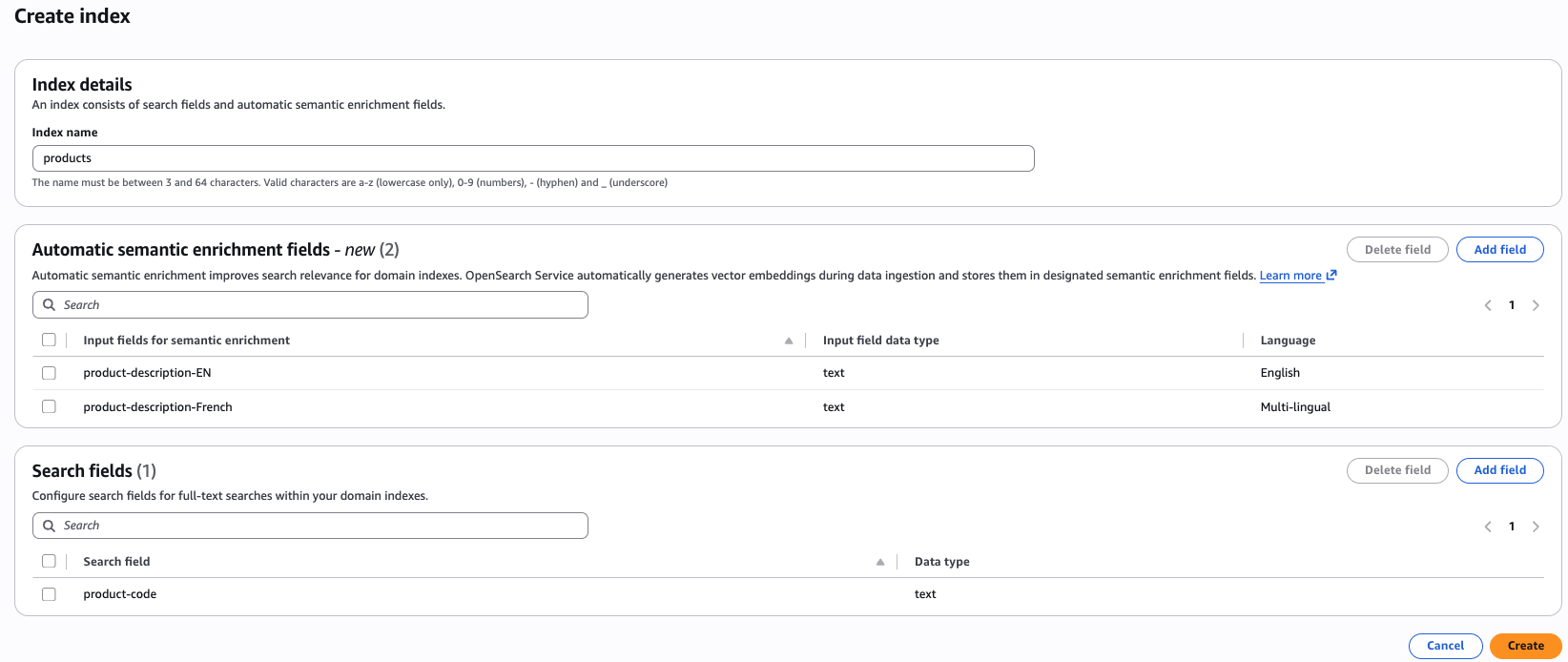
API 경험 - AWS 명령줄 인터페이스(AWS CLI)를 사용하여 자동 의미 체계 보강 인덱스를 생성하려면 create-index 명령을 사용합니다.
aws opensearch create-index \ --domain-name [domain_name] \ --index-name [index_name] \ --index-schema [index_body] \
다음 예제 index-schema에서 title_semantic 필드는 필드 유형이 텍스트로 설정되고 파라미터 semantic_enrichment가 ENABLED 상태로 설정됩니다. semantic_enrichment 파라미터를 설정하면 title_semantic 필드에서 자동 의미 체계 보강이 활성화됩니다. language_options 필드를 사용하여 영어 또는 다국어를 지정할 수 있습니다.
aws opensearch create-index \ --id XXXXXXXXX \ --index-name 'product-catalog' \ --index-schema '{ "mappings": { "properties": { "product_id": { "type": "keyword" }, "title_semantic": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } }, "title_non_semantic": { "type": "text" } } } }'
생성된 인덱스를 설명하려면 다음 명령을 사용합니다.
aws opensearch get-index \ --domain-name [domain_name] \ --index-name [index_name] \
기존 인덱스 업데이트
기존 인덱스를 업데이트하여 새 의미 체계 보강 필드를 추가하거나, 기존 필드에 의미 체계 보강을 활성화 또는 비활성화하거나, 의미 체계가 아닌 텍스트 필드를 추가할 수 있습니다. update-index 명령을 사용하고에서 변경하려는 필드만 제공합니다index-schema. 요청에 포함되지 않은 필드는 변경되지 않습니다.
참고
인덱스는 업데이트할 수 settings 없습니다. 요청에 settings 블록을 포함하면 작업이 검증 오류를 반환합니다. 인덱스 설정을 변경하려면 인덱스를 삭제하고 다시 생성해야 합니다.
를 사용하여 인덱스를 업데이트하려면 update-index 명령을 AWS CLI사용합니다.
aws opensearch update-index \ --domain-name [domain_name] \ --index-name [index_name] \ --index-schema [index_body]
새 의미 체계 보강 필드 추가
시맨틱 보강이 활성화된 새 text 필드를 기존 인덱스에 추가할 수 있습니다. 서비스는 필요한 ML 모델, 수집 파이프라인 및 검색 파이프라인을 자동으로 설정합니다. 업데이트 후 인덱싱된 새 문서는 자동으로 보강됩니다.
중요
기존 문서는 다시 채워지지 않습니다. 기존 문서에 의미 체계 보강 필드를 채우려면 업데이트 후 다시 수집해야 합니다. 다시 수집될 때까지 기존 문서는 새 필드에 대한 의미 검색의 이점을 얻지 못합니다.
aws opensearch update-index \ --domain-name my-domain \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "description": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } } } } }'
필드에서 의미 체계 보강 비활성화
현재 활성화된 필드에서 의미 체계 보강을 비활성화하려면를 status로 설정합니다DISABLED. 필드는 수집 및 검색 파이프라인에서 제거됩니다. 기본 텍스트 필드와 해당 임베딩 필드는 인덱스에 남아 있지만 더 이상 보강되지 않습니다.
aws opensearch update-index \ --domain-name my-domain \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "title_semantic": { "type": "text", "semantic_enrichment": { "status": "DISABLED" } } } } }'
업데이트 제한 사항
다음 작업은에서 지원되지 않으므로 인덱스를 삭제하고 다시 생성update-index해야 합니다.
-
현재 의미 체계 보강이 활성화된 필드에서를 변경합니다
language_options. 먼저 필드를 비활성화한 다음 새 언어 옵션으로 다시 활성화합니다. -
중첩 필드 업데이트. 의미 체계 보강은 최상위
text필드에서만 지원됩니다. -
인덱스 업데이트
settings.
참고
인덱스에 자동 의미 체계 보강으로 생성되지 않은 사용자 지정 수집 또는 검색 파이프라인이 있는 경우 업데이트 작업이 차단됩니다. 의미 체계 보강 필드를 추가하기 전에 사용자 지정 파이프라인을 제거합니다.
데이터 수집 및 검색
자동 의미 체계 보강이 활성화된 인덱스를 생성하면이 기능은 데이터 수집 프로세스 중에 자동으로 작동하므로 추가 구성이 필요하지 않습니다.
데이터 수집: 인덱스에 문서를 추가하면 시스템이 자동으로 다음을 수행합니다.
-
의미 체계 보강을 위해 지정한 텍스트 필드를 분석합니다.
-
OpenSearch Service 관리형 스파스 모델을 사용하여 의미 체계 인코딩 생성
-
이러한 보강된 표현을 원본 데이터와 함께 저장합니다.
이 프로세스는 OpenSearch의 기본 제공 ML 커넥터와 수집 파이프라인을 사용하며, 이는 백그라운드에서 자동으로 생성 및 관리됩니다.
검색: 의미 체계 보강 데이터는 이미 인덱싱되어 있으므로 ML 모델을 다시 호출하지 않고도 쿼리가 효율적으로 실행됩니다. 즉, 추가 검색 지연 시간 오버헤드 없이 검색 관련성을 개선할 수 있습니다.
자동 시맨틱 보강에 대한 권한 구성
자동 의미 체계 보강을 사용하여 인덱스를 생성하기 전에 필요한 권한을 구성해야 합니다. 이 섹션에서는 다양한 인덱스 작업에 필요한 권한과 AWS Identity and Access Management (IAM) 및 세분화된 액세스 제어 시나리오 모두에 대해 설정하는 방법을 설명합니다.
IAM 권한
자동 의미 체계 보강 작업에 필요한 IAM 권한은 다음과 같습니다. 이러한 권한은 수행하려는 특정 인덱스 작업에 따라 달라집니다.
CreateIndex API 권한
자동 의미 체계 보강으로 인덱스를 생성하려면 다음 IAM 권한이 필요합니다.
-
es:CreateIndex- 의미 체계 보강 기능을 사용하여 인덱스를 생성합니다. -
es:ESHttpHead- HEAD 요청을 수행하여 인덱스 존재 여부를 확인합니다. -
es:ESHttpPut- 인덱스 생성을 위한 PUT 요청을 수행합니다. -
es:ESHttpPost- 인덱스 작업에 대한 POST 요청을 수행합니다.
UpdateIndex API 권한
자동 의미 체계 보강으로 기존 인덱스를 업데이트하려면 다음 IAM 권한이 필요합니다.
-
es:UpdateIndex- 인덱스 설정 및 매핑을 업데이트합니다. -
es:ESHttpPut- 인덱스 업데이트에 대한 PUT 요청을 수행합니다. -
es:ESHttpGet- GET 요청을 수행하여 인덱스 정보를 검색합니다. -
es:ESHttpPost- 인덱스 작업에 대한 POST 요청을 수행합니다.
GetIndex API 권한
자동 의미 체계 보강을 사용하여 인덱스에 대한 정보를 검색하려면 다음 IAM 권한이 필요합니다.
-
es:GetIndex- 인덱스 정보 및 설정을 검색합니다. -
es:ESHttpGet- GET 요청을 수행하여 인덱스 데이터를 검색합니다.
DeleteIndex API 권한
자동 의미 체계 보강을 사용하여 인덱스를 삭제하려면 다음 IAM 권한이 필요합니다.
-
es:DeleteIndex- 인덱스와 해당 의미 체계 보강 구성 요소를 삭제합니다. -
es:ESHttpDelete- 인덱스 제거를 위한 DELETE 요청을 수행합니다.
샘플 IAM 정책
다음 샘플 자격 증명 기반 액세스 정책은 사용자가 자동 의미 체계 보강으로 인덱스를 관리하는 데 필요한 권한을 제공합니다.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowSemanticEnrichmentIndexOperations", "Effect": "Allow", "Action": [ "es:CreateIndex", "es:UpdateIndex", "es:GetIndex", "es:DeleteIndex", "es:ESHttpHead", "es:ESHttpGet", "es:ESHttpPut", "es:ESHttpPost", "es:ESHttpDelete" ], "Resource": "arn:aws:es:aws-region:111122223333:domain/domain-name" } ] }
aws-region, 111122223333 및 domain-name을 특정 값으로 바꿉니다. 리소스 ARN에서 특정 인덱스 패턴을 지정하여 액세스를 추가로 제한할 수 있습니다.
세분화된 액세스 제어 권한
Amazon OpenSearch Service 도메인에 세분화된 액세스 제어가 활성화된 경우 IAM 권한 이외의 추가 권한이 필요합니다. 각 인덱스 작업에 다음 권한이 필요합니다.
CreateIndex API 권한
세분화된 액세스 제어가 활성화된 경우 자동 의미 체계 보강으로 인덱스를 생성하려면 다음과 같은 추가 권한이 필요합니다.
-
indices:admin/create- 인덱스 작업을 생성합니다. -
indices:admin/mapping/put- 인덱스 매핑을 생성하고 업데이트합니다. -
cluster:admin/opensearch/ml/create_connector- 의미 체계 처리를 위한 기계 학습 커넥터를 생성합니다. -
cluster:admin/opensearch/ml/register_model- 의미 체계 보강을 위해 기계 학습 모델을 등록합니다. -
cluster:admin/ingest/pipeline/put- 데이터 처리를 위한 수집 파이프라인을 생성합니다. -
cluster:admin/search/pipeline/put- 쿼리 처리를 위한 검색 파이프라인을 생성합니다.
UpdateIndex API 권한
세분화된 액세스 제어가 활성화되면 자동 의미 체계 보강으로 인덱스를 업데이트하려면 다음과 같은 추가 권한이 필요합니다.
-
indices:admin/get- 인덱스 정보를 검색합니다. -
indices:admin/settings/update- 인덱스 설정을 업데이트합니다. -
indices:admin/mapping/put- 인덱스 매핑을 업데이트합니다. -
cluster:admin/opensearch/ml/create_connector- 기계 학습 커넥터를 생성합니다. -
cluster:admin/opensearch/ml/register_model- 기계 학습 모델을 등록합니다. -
cluster:admin/ingest/pipeline/put- 수집 파이프라인을 생성합니다. -
cluster:admin/search/pipeline/put- 검색 파이프라인을 생성합니다. -
cluster:admin/ingest/pipeline/get- 수집 파이프라인 정보를 검색합니다. -
cluster:admin/search/pipeline/get- 검색 파이프라인 정보를 검색합니다.
GetIndex API 권한
세분화된 액세스 제어가 활성화된 경우 자동 의미 체계 보강을 사용하여 인덱스에 대한 정보를 검색하려면 다음과 같은 추가 권한이 필요합니다.
-
indices:admin/get- 인덱스 정보를 검색합니다. -
cluster:admin/ingest/pipeline/get- 수집 파이프라인 정보를 검색합니다. -
cluster:admin/search/pipeline/get- 검색 파이프라인 정보를 검색합니다.
DeleteIndex API 권한
세분화된 액세스 제어가 활성화된 경우 자동 의미 체계 보강을 사용하여 인덱스를 삭제하려면 다음과 같은 추가 권한이 필요합니다.
-
indices:admin/delete- 인덱스 작업을 삭제합니다.
쿼리 재작성
자동 의미 체계 보강은 쿼리 수정 없이 기존 “일치” 쿼리를 의미 체계 검색 쿼리로 자동 변환합니다. 일치 쿼리가 복합 쿼리의 일부인 경우 시스템은 쿼리 구조를 통과하고 일치 쿼리를 찾아 신경 스파스 쿼리로 바꿉니다. 현재이 기능은 독립 실행형 쿼리든 복합 쿼리의 일부이든 관계없이 “일치” 쿼리 교체만 지원합니다. “multi_match”는 지원되지 않습니다. 또한이 기능은 중첩된 일치 쿼리를 대체하기 위해 모든 복합 쿼리를 지원합니다. 복합 쿼리에는 부울, 부스팅, constant_score, dis_max, function_score 및 하이브리드가 포함됩니다.
자동 의미 체계 보강의 제한 사항
자동 의미 체계 검색은 영화 제목, 제품 설명, 리뷰 및 요약과 같은 자연어 콘텐츠가 포함된 중small-to-medium 규모의 필드에 적용할 때 가장 효과적입니다. 의미 체계 검색은 대부분의 사용 사례에 대한 관련성을 향상시키지만 특정 시나리오에는 최적화되지 않을 수 있습니다. 특정 사용 사례에 대해 자동 의미 체계 보강을 구현할지 여부를 결정할 때는 다음 제한 사항을 고려하세요.
-
매우 긴 문서 - 현재 희소 모델은 영어에 대해 각 문서의 처음 8,192개 토큰만 처리합니다. 다국어 문서의 경우 토큰은 512개입니다. 긴 문서의 경우 완전한 콘텐츠 처리를 위해 문서 청킹을 구현하는 것이 좋습니다.
-
로그 분석 워크로드 - 의미 체계 보강은 인덱스 크기를 크게 증가시키므로 일반적으로 정확히 일치하면 충분할 수 있는 로그 분석에 필요하지 않을 수 있습니다. 추가 의미 체계 컨텍스트는 증가된 스토리지 요구 사항을 정당화할 만큼 로그 검색 효과를 개선하는 경우는 거의 없습니다.
-
자동 의미 체계 보강은 파생 소스 기능과 호환되지 않습니다.
-
조절 - 인덱싱 추론 요청은 현재 OpenSearch Service 도메인에 대해 200TPS로 제한됩니다. 이는 소프트 제한입니다. 더 높은 제한은 AWS Support에 문의하세요.
가격 책정
Amazon OpenSearch Service는 인덱싱 시 희소 벡터 생성 중에 사용된 OpenSearch 컴퓨팅 유닛(OCUs)을 기반으로 자동 의미 체계 보강 요금을 청구합니다. 자동 의미 체계 보강을 활성화한 텍스트 필드에 대한 인덱싱 중 실제 사용량에 대해서만 요금이 부과됩니다. 하나의 의미 체계 검색 OCU는 영어 콘텐츠에 대해 1,110만 개의 토큰을 처리할 수 있습니다. 24억 개의 토큰을 처리하려면 약 216개의 의미 체계 검색 OCU 시간(24억 / 1,110만)이 필요합니다. 시맨틱 검색 OCU 시간당 가격이 0.24 USD인 경우 자동 시맨틱 검색을 위한 10GB 데이터 처리 비용은 51 USD(216 OCU 시간 x 0.24 USD/OCU 시간)입니다. 검색 작업 중 또는 데이터 스토리지에 대한 추가 의미 체계 검색 OCU 요금은 없습니다.
Amazon CloudWatch 지표를 사용하여이 소비를 모니터링할 수 있습니다SemanticSearchOCU. 모델 토큰 제한, OCU당 볼륨 처리량 및 샘플 계산 예제에 대한 자세한 내용은 OpenSearch Service Pricing
