신규 고객은 Amazon Forecast를 더 이상 사용할 수 없습니다. Amazon Forecast의 기존 고객은 평소와 같이 서비스를 계속 사용할 수 있습니다. [자세히 알아보기](https://aws.amazon.com/blogs/machine-learning/transition-your-amazon-forecast-usage-to-amazon-sagemaker-canvas/)
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
# DeepAR\+ 알고리즘
Amazon Forecast DeepAR\+는 반복 신경망(RNN)을 사용하여 스칼라(1차원) 시계열을 예상하는 지도 학습 알고리즘입니다. Autoregressive Integrated Moving Average(ARIMA) 또는 Exponential Smoothing(ETS)과 같은 기존 예측 메서드는 각 시계열에 하나의 모델만이 맞고, 해당 모델을 사용하여 시계열의 미래를 추론합니다. 그러나 많은 애플리케이션에서 일련의 횡단적 단위에 걸쳐 비슷한 시계열이 많이 있습니다. 이러한 시계열 그룹화에는 다양한 제품, 서버 로드 및 웹 페이지에 대한 요청이 필요합니다. 이러한 경우 단일 모델을 모든 시계열과 결합하여 교육하는 것이 이득이 될 수 있습니다. DeepAR\+는 이러한 접근 방법을 사용합니다. 데이터 세트에 수백 개의 기능 시계열이 포함되어 있는 경우, DeepAR\+ 알고리즘이 표준 ARIMA 및 ETS 방법보다 우수합니다. 또한 교육을 받은 모델과 유사한 새 시계열에 대해 예상을 발생하기 위해 교육받은 모델을 사용할 수도 있습니다.
**Python 노트북**
DeepAR\+ 알고리즘 사용에 대한 단계별 지침은 [DeepAR\+ 시작하기](https://github.com/aws-samples/amazon-forecast-samples/blob/master/notebooks/advanced/Getting_started_with_DeepAR%2B/Getting_started_with_DeepAR%2B.ipynb)를 참조하세요.
**Topics**
+ [DeepAR\+ 작동 방법](#aws-forecast-recipe-deeparplus-how-it-works)
+ [DeepAR\+ 하이퍼파라미터](#aws-forecast-recipe-deeparplus-hyperparameters)
+ [DeepAR\+ 모델 튜닝](#aws-forecast-recipe-deeparplus-tune-model)
## DeepAR\+ 작동 방법
교육 과정에서 DeepAR\+는 교육 데이터 세트 및 선택 테스트 데이터 세트를 사용합니다. 테스트 데이터 세트를 사용하여 교육받은 모델을 평가합니다. 일반적으로 교육 및 테스트 데이터 세트에는 동일한 시계열 집합이 포함될 필요가 없습니다. 주어진 훈련 세트에 대해 훈련된 모델을 사용하여 훈련 세트에서 미래의 시계열 및 기타 시계열에 대한 예상을 생성할 수 있습니다. 교육 및 테스트 데이터 세트는 모두 바람직하게는 하나 이상의 대상 시계열로 구성됩니다. 선택적으로 특성 시계열 벡터 및 범주형 특성 벡터와 연결할 수 있습니다(자세한 내용은 *SageMaker AI 개발자 안내서*의 [DeepAR 입력/출력 인터페이스](https://docs.aws.amazon.com/sagemaker/latest/dg/deepar.html#deepar-inputoutput) 참조). 다음 예제는 `i`로 색인화된 교육 데이터 세트의 요소에 대해 어떻게 작용하는지 보여줍니다. 교육 데이터 세트는 대상 시계열, `zi,t` 및 두 개의 연결된 기능 시계열, `xi,1,t` 및 `xi,2,t`으로 구성됩니다.
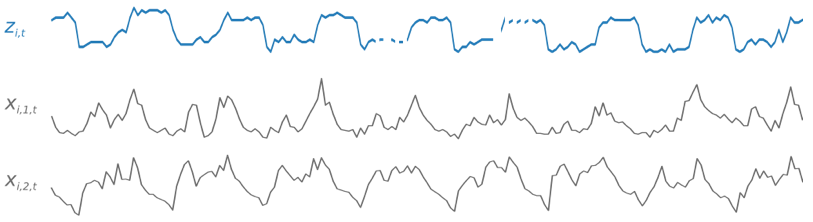
대상 시계열에 누락된 값이 있을 수 있습니다(시계열의 중단으로 그래프에 표시됨). DeepAR\+는 향후에 알려지는 기능 시계열만 지원합니다. 이렇게 하면 상반되는 'what-if'시나리오를 실행할 수 있습니다. 예를 들어, '제품의 가격을 어떤 식으로든 변경하면 어떻게 됩니까?'
각 대상 시계열은 여러 가지 범주 요인(feature)과 연결될 수 있습니다. 이들을 사용하여 시계열이 특정 그룹에 속한다고 인코딩할 수 있습니다. 범주 기능을 사용하면 모델에서 그룹화에 대한 일반적인 행동을 학습할 수 있으므로 정확성이 향상됩니다. 모델은 그룹의 모든 시계열의 공통 속성을 포착하는 각 그룹에 대한 임베딩 벡터를 학습하여 이를 구현합니다.
주말의 스파이크와 같이 시간 의존적인 패턴을 쉽게 학습할 수 있도록 DeepAR\+는 시계열 세부 수준을 기반으로 기능 시계열을 자동으로 생성합니다. 예를 들어, DeepAR\+는 주간 시계열 빈도로 두 개의 기능 시계열(월중 날짜 및 연중 날짜)을 생성합니다. 이 파생된 기능 시계열을 교육 및 추론 중에 제공하는 사용자 지정 기능 시계열과 함께 사용합니다. 다음 예제는 두 개의 파생 시계열 기능을 보여줍니다. `ui,1,t`은 시간을 나타내고 `ui,2,t`는 요일을 나타냅니다.

DeepAR\+는 데이터 빈도 및 교육 데이터의 크기를 기반으로 이러한 기능 시계열을 자동으로 포함합니다. 다음 표는 지원되는 기본 시간 주기마다 파생될 수 있는 기능을 나열합니다.
****
| 시계열의 빈도 | 파생 요인(feature) |
| --- | --- |
| 분 | minute-of-hour, hour-of-day, day-of-week, day-of-month, day-of-year |
| 시간 | hour-of-day, day-of-week, day-of-month, day-of-year |
| 일 | day-of-week, day-of-month, day-of-year |
| 주 | week-of-month, week-of-year |
| 월 | month-of-year |
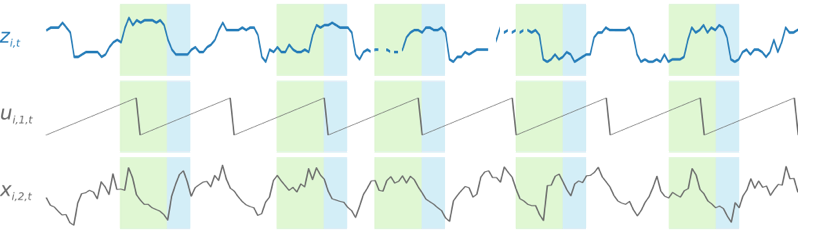
DeepAR\+ 모델은 교육 데이터 세트의 각 시계열에서 여러 교육 예제를 무작위로 샘플링하여 교육합니다. 각 훈련 예제는 미리 정의된 길이가 고정된 한 쌍의 인접 컨텍스트 및 예상 창으로 구성됩니다. `context_length` 하이퍼파라미터는 과거 네트워크에서 확인 가능한 거리를 제어하며, `ForecastHorizon` 파라미터는 향후 예상할 수 있는 범위를 제어합니다. 교육 도중 Amazon Forecast는 지정된 예상 길이보다 짧은 시계열로 교육 데이터 세트의 요소를 무시합니다. 다음 예제에서는 요소 `i`에서 가져온 12시간의 컨텍스트 길이(녹색으로 강조 표시)와 6시간의 예상 길이(파란색으로 강조 표시)를 갖는 5개의 샘플을 보여줍니다. 간략하게 하기 위해 기능 시계열 `xi,1,t`과 `ui,2,t`를 제외했습니다.
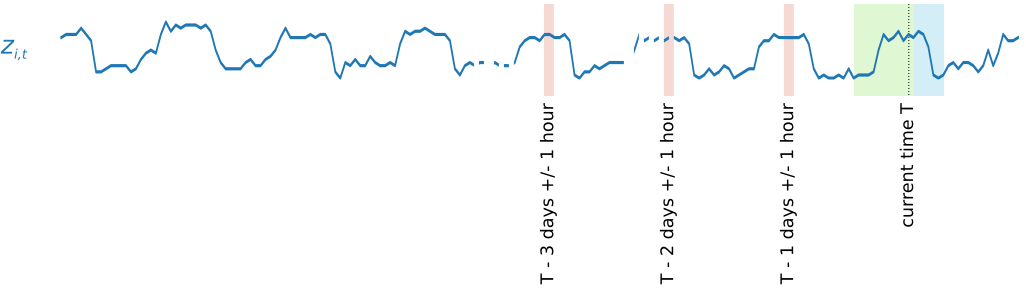
계절성 패턴을 캡처하기 위해 DeepAR\+은 대상 시계열에서 지연된 값(기간을 지난)을 자동으로 공급합니다. 시간별 빈도로 채취된 표본을 사용한 이 예제에서는 각 시간 지수 `t = T`에 대해 모델이 과거(분홍색으로 강조 표시)에 약 1, 2, 3일 동안 발생했던 `zi,t` 값을 노출합니다.
추론을 위해 교육된 모델은 교육 중에 사용되었을 수도 있고 사용되지 않았을 수도 있는 대상 시계열을 입력으로 받아 다음 `ForecastHorizon` 값에 대한 확률 분포를 예상합니다. DeepAR\+가 전체 데이터 세트에 대해 교육을 받았기 때문에 이 예상에는 비슷한 시계열의 학습 패턴이 고려됩니다.
DeepAR의 수학에 대한 자세한 정보는 코넬대학교 도서관 웹사이트의 [DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks](https://arxiv.org/abs/1704.04110)를 참조하십시오.
## DeepAR\+ 하이퍼파라미터
다음 표에는 DeepAR\+ 알고리즘에 사용할 수 있는 하이퍼파라미터가 나열되어 있습니다. 볼드 처리된 파라미터가 하이퍼파라미터 최적화(HPO)에 참여할 수 있습니다.
| 파라미터 이름 | 설명 |
| --- | --- |
| context\_length | 예상하기 전에 모델이 읽는 시간 지점의 수입니다. 이 파라미터의 값은 `ForecastHorizon`과 동일해야 합니다. 모델은 또한 대상으로부터 시차가 발생한 입력을 수신하기 때문에 `context_length`는 일반적인 계절성보다 작을 수 있습니다. 예를 들어 일별 시계열은 연도별 계절성을 보유할 수 있습니다. 모델은 자동으로 1년의 시차를 포함시키기 때문에 컨텍스트 길이는 1년보다 짧을 수 있습니다. 모델이 고르는 시차 값은 시계열의 빈도에 따라 다릅니다. 예를 들어 일별 빈도의 시차 값은 1주, 2주, 3주, 4주 및 1년입니다.[See the AWS documentation website for more details](http://docs.aws.amazon.com/ko_kr/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| epochs | 훈련 데이터의 최대 전달 횟수입니다. 최적값은 데이터의 크기와 학습률에 따라 다릅니다. 더 나은 결과를 얻으려면 작은 데이터 세트와 낮은 학습률에 더 많은 epoch가 필요합니다.[See the AWS documentation website for more details](http://docs.aws.amazon.com/ko_kr/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| learning\_rate | 훈련에 사용되는 학습률.[See the AWS documentation website for more details](http://docs.aws.amazon.com/ko_kr/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| learning\_rate\_decay | 학습률이 감소하는 속도입니다. 최대한 학습 속도가 `max_learning_rate_decays`번 줄어들고 교육이 중단됩니다. 이 파라미터는 `max_learning_rate_decays`가 0보다 큰 경우에만 사용됩니다.[See the AWS documentation website for more details](http://docs.aws.amazon.com/ko_kr/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| likelihood | 모델은 확률론적 예측을 생성하고, 분포의 분위를 제공하고 샘플을 반환할 수 있습니다. 데이터에 따라 불확실성 추정에 사용할 적절한 가능도(노이즈 모델)를 선택합니다.
유효값[See the AWS documentation website for more details](http://docs.aws.amazon.com/ko_kr/forecast/latest/dg/aws-forecast-recipe-deeparplus.html)[See the AWS documentation website for more details](http://docs.aws.amazon.com/ko_kr/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| max\_learning\_rate\_decays | 발생해야 하는 학습률 감소의 최대 수.[See the AWS documentation website for more details](http://docs.aws.amazon.com/ko_kr/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| num\_averaged\_models | DeepAR\+에서는 교육 궤적에서 여러 모델을 접할 수 있습니다. 각 모델에는 서로 다른 예측 강점과 약점이 있을 수 있습니다. DeepAR\+는 모델 행동을 평균화하여 모든 모델의 강점을 활용할 수 있습니다.[See the AWS documentation website for more details](http://docs.aws.amazon.com/ko_kr/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| num\_cells | RNN의 각 은닉층에서 사용할 셀의 수.[See the AWS documentation website for more details](http://docs.aws.amazon.com/ko_kr/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
| num\_layers | RNN의 은닉층 수.[See the AWS documentation website for more details](http://docs.aws.amazon.com/ko_kr/forecast/latest/dg/aws-forecast-recipe-deeparplus.html) |
## DeepAR\+ 모델 튜닝
Amazon Forecast DeepAR\+ 모델을 튜닝하려면 교육 프로세스 및 하드웨어 구성을 최적화하기 위해 다음 권장사항을 따르십시오.
### 프로세스 최적화 모범 사례
최상의 결과를 얻으려면 다음 권장 사항을 따르십시오.
+ 교육 및 테스트 데이터 세트를 분리할 때를 제외하고는 항상 교육 및 테스트의 경우 또한 추론을 위해 모델을 호출할 때 전체 시계열을 제공합니다. `context_length`을 설정한 방법에 관계없이 시계열을 나누지 않거나 그 중 일부만 제공합니다. 모델은 지연된 값 기능에 대해 `context_length`보다 더 뒤쪽의 데이터 포인트를 사용합니다.
+ 모델 튜닝의 경우 데이터 세트를 교육 및 테스트 데이터 세트로 분리할 수 있습니다. 일반적인 평가 시나리오에서는 교육에 사용된 것과 동일한 시계열을 사용하여 모델을 테스트해야 하지만 향후 교육 중에 표시된 마지막 시간이 표시된 직후 `ForecastHorizon` 시간을 표시해야 합니다. 이러한 기준을 충족하는 교육 및 테스트 데이터 세트를 생성하려면 전체 데이터 세트(모든 시계열)를 테스트 데이터 세트로 사용하고 각 시계열에서 마지막 `ForecastHorizon` 지점을 제거하여 교육을 받습니다. 이렇게 하면 교육 중 모델이 테스트 중에 평가되는 시점의 대상 값을 볼 수 없습니다. 테스트 단계에서 테스트 데이터 세트에 있는 각 시계열의 `ForecastHorizon` 지점이 보류되고 예측이 생성됩니다. 이후 예측은 마지막 `ForecastHorizon` 지점의 실제 값과 비교됩니다. 테스트 데이터 세트에서 시계열을 여러 번 반복하면서 더 복잡한 평가를 생성할 수 있지만 여러 종단점에서 잘라내어 평가할 수 있습니다. 이는 서로 다른 시점의 여러 예측에 대해 평균화된 정확도 지표를 산출합니다.
+ `ForecastHorizon`에 매우 큰 값(> 400)을 사용하면 모델이 느려지고 정확도가 떨어지므로 사용하지 마십시오. 앞으로 더 예측하기를 원한다면 더 높은 빈도로 집계하는 것을 고려하십시오. 예를 들어 `1min` 대신 `5min`을 사용하세요.
+ 시차 때문에, 모델은 `context_length`보다 더 뒤떨어져 보일 수 있습니다. 따라서 이 파라미터 큰 값으로 설정할 필요가 없습니다. 이 파라미터의 시작점은 `ForecastHorizon`과 동일한 값입니다.
+ DeepAR\+모델을 가능한 많은 시계열로 교육하십시오. 단일 시계열에서 교육된 DeepAR\+ 모델은 이미 잘 작동할 수도 있지만 ARIMA 또는 ETS와 같은 표준 예측 메서드가 더 정확할 수 있고 이 사용 사례에 더 맞게 조정될 수 있습니다. DeepAR\+는 데이터 세트에 수백 개의 기능 시계열이 포함되어 있을 때 표준 방법보다 뛰어난 성능을 내기 시작합니다. 현재 DeepAR\+에는 모든 교육 시계열에서 사용 가능한 총 관측 수가 최소 300개 이상 필요합니다.