# DynamoDB에서 불만 관리 시스템 스키마 설계
## 불만 관리 시스템 비즈니스 사용 사례
DynamoDB는 불만 관리 시스템(또는 콜센터) 사용 사례에 적합한 데이터베이스입니다. 관련된 대부분의 액세스 패턴이 키-값 기반 트랜잭션 조회이기 때문입니다. 이 시나리오의 일반적인 액세스 패턴은 다음과 같습니다.
+ 불만 사항 생성 및 업데이트
+ 불만 사항 에스컬레이션
+ 불만 사항에 대한 의견 작성 및 읽기
+ 고객의 모든 불만 사항 접수
+ 에이전트의 모든 의견 가져오기 및 모든 에스컬레이션 가져오기
일부 의견에는 불만 사항 또는 해결 방법을 설명하는 첨부 파일이 있을 수 있습니다. 이러한 패턴은 모두 키-값 액세스 패턴이지만 불만 사항에 새 의견이 추가될 때 알림을 보내거나 분석 쿼리를 실행하여 주간 심각도(또는 에이전트 성과)별로 불만 사항 분포를 확인하는 등의 추가 요구 사항이 있을 수 있습니다. 수명 주기 관리 또는 규정 준수와 관련된 추가 요구 사항은 불만 사항을 기록한 지 3년이 지난 후에 불만 사항 데이터를 아카이빙하는 것입니다.
## 불만 관리 시스템 아키텍처 다이어그램
다음 다이어그램은 불만 관리 시스템의 아키텍처 다이어그램입니다. 이 다이어그램은 불만 관리 시스템에서 사용하는 다양한 AWS 서비스 통합을 보여니다.

나중에 DynamoDB 데이터 모델링 섹션에서 다루게 될 키-값 트랜잭션 액세스 패턴 외에도 세 가지 비트랜잭션 요구 사항이 있습니다. 위의 아키텍처 다이어그램은 다음 세 가지 워크플로로 나눌 수 있습니다.
1. 불만 사항에 새 의견이 추가되면 알림 보내기
1. 주간 데이터에 대한 분석 쿼리 실행
1. 3년 이상 경과된 데이터 아카이빙
각각에 대해 좀더 자세히 살펴보겠습니다.
**불만 사항에 새 의견이 추가되면 알림 보내기**
아래 워크플로를 사용하여 이 요구 사항을 달성할 수 있습니다.

[DynamoDB Streams](Streams.md)는 DynamoDB 테이블에 대한 모든 쓰기 작업을 기록하는 변경 데이터 캡처 메커니즘입니다. 이러한 변경 사항의 일부 또는 전부를 트리거하도록 Lambda 함수를 구성할 수 있습니다. 사용 사례와 관련이 없는 이벤트를 필터링하도록 Lambda 트리거에 [이벤트 필터](https://docs.aws.amazon.com/lambda/latest/dg/invocation-eventfiltering.html)를 구성할 수 있습니다. 이 경우 필터를 사용하여 새 의견이 추가된 경우에만 Lambda를 트리거하고 [AWS Secrets Manager](https://docs.aws.amazon.com/secretsmanager/latest/userguide/intro.html) 또는 기타 보안 인증 정보 스토어에서 가져올 수 있는 관련 이메일 ID로 알림을 보낼 수 있습니다.
**주간 데이터에 대한 분석 쿼리 실행**
DynamoDB는 주로 온라인 트랜잭션 처리(OLTP)에 중점을 둔 워크로드에 적합합니다. 분석 요구 사항이 있는 다른 10%\~20% 액세스 패턴의 경우, DynamoDB 테이블의 실시간 트래픽에 영향을 주지 않고 관리형 [Amazon S3로 내보내기](S3DataExport.HowItWorks.md) 기능을 사용하여 데이터를 S3으로 내보낼 수 있습니다. 아래에서 이 워크플로를 살펴보세요.

[Amazon EventBridge](https://docs.aws.amazon.com/eventbridge/latest/userguide/eb-what-is)를 사용하면 일정에 따라 AWS Lambda를 트리거할 수 있습니다. 이를 통해 Lambda 호출이 주기적으로 발생하도록 cron 표현식을 구성할 수 있습니다. Lambda는 `ExportToS3` API를 호출하고 DynamoDB 데이터를 S3에 저장할 수 있습니다. 그런 다음 [Amazon Athena](https://docs.aws.amazon.com/athena/latest/ug/what-is)와 같은 SQL 엔진에서 이 S3 데이터에 액세스하여 테이블의 실시간 트랜잭션 워크로드에 영향을 주지 않고 DynamoDB 데이터에 대한 분석 쿼리를 실행할 수 있습니다. 심각도 수준별 불만 사항 수를 확인하기 위한 샘플 Athena 쿼리는 다음과 같습니다.
```
SELECT Item.severity.S as "Severity", COUNT(Item) as "Count"
FROM "complaint_management"."data"
WHERE NOT Item.severity.S = ''
GROUP BY Item.severity.S ;
```
이 Athena 쿼리는 다음 결과를 반환합니다.

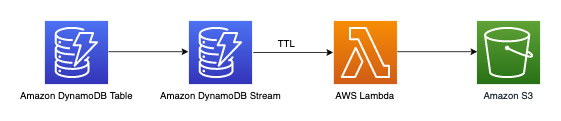
**3년 이상 경과된 데이터 아카이빙**
DynamoDB [TTL(Time to Live)](TTL.md) 기능을 활용하면 추가 비용 없이 DynamoDB 테이블에서 사용되지 않는 데이터를 삭제할 수 있습니다(다른 리전에 복제된 TTL 삭제가 쓰기 용량을 소비하는 2019.11.21(현재) 버전의 글로벌 테이블 복제본인 경우 제외). 이 데이터는 표시되며 DynamoDB Streams에서 소비되어 Amazon S3에 아카이빙될 수 있습니다. 이 요구 사항에 대한 워크플로는 다음과 같습니다.
## 불만 관리 시스템 엔터티 관계 다이어그램
다음은 불만 관리 스키마 설계에 사용할 엔터티 관계 다이어그램(ERD)입니다.

## 불만 관리 시스템 액세스 패턴
다음은 불만 관리 스키마를 설계할 때 고려할 액세스 패턴입니다.
1. createComplaint
1. updateComplaint
1. updateSeveritybyComplaintID
1. getComplaintByComplaintID
1. addCommentByComplaintID
1. getAllCommentsByComplaintID
1. getLatestCommentByComplaintID
1. getAComplaintbyCustomerIDAndComplaintID
1. getAllComplaintsByCustomerID
1. escalateComplaintByComplaintID
1. getAllEscalatedComplaints
1. getEscalatedComplaintsByAgentID(최신 것부터 가장 오래된 것 순)
1. getCommentsByAgentID(두 날짜 사이)
## 불만 관리 시스템 스키마 설계 진화
이는 불만 관리 시스템이므로 대부분의 액세스 패턴에서 불만 사항이 기본 엔터티입니다. `ComplaintID`는 카디널리티가 높을 때 기본 파티션에 데이터가 균일하게 배포되도록 하며 식별된 액세스 패턴에 대한 가장 일반적인 검색 기준이기도 합니다. 따라서 `ComplaintID`는 이 데이터 세트에서 좋은 파티션 키 후보입니다.
**1단계: 액세스 패턴 1(`createComplaint`), 2(`updateComplaint`), 3(`updateSeveritybyComplaintID`), 4(`getComplaintByComplaintID`) 처리**
'metadata'(또는 'AA')라는 일반 정렬 키 값을 사용하여 `CustomerID`, `State`, `Severity`, `CreationDate`와 같은 불만 사항별 정보를 저장할 수 있습니다. `PK=ComplaintID` 및 `SK=“metadata”`인 싱글톤 작업을 사용하여 다음을 수행합니다.
1. [https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_PutItem.html](https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_PutItem.html)을 통해 새 불만 사항 생성
1. [https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_UpdateItem.html](https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_UpdateItem.html)을 통해 불만 사항 메타데이터의 심각도 또는 기타 필드 업데이트
1. [https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_GetItem.html](https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_GetItem.html)을 통해 불만 사항에 대한 메타데이터 가져오기

**2단계: 액세스 패턴 5(`addCommentByComplaintID`) 처리**
이 액세스 패턴에는 불만 사항과 불만 사항에 대한 의견 간의 일대다 관계 모델이 필요합니다. 여기서는 [수직 파티셔닝](data-modeling-blocks.md#data-modeling-blocks-vertical-partitioning) 기법을 통해 정렬 키를 사용하며 다양한 유형의 데이터로 항목 컬렉션을 생성합니다. 액세스 패턴 6(`getAllCommentsByComplaintID`) 및 7(`getLatestCommentByComplaintID`)을 살펴보면 의견을 시간별로 정렬해야 한다는 것을 알 수 있습니다. 또한 여러 개의 의견이 동시에 들어올 수 있으므로 [복합 정렬 키](data-modeling-blocks.md#data-modeling-blocks-composite) 기법을 사용하여 정렬 키 속성에 time과 `CommentID`를 추가할 수 있습니다.
이러한 의견 충돌 가능성에 대처하기 위한 다른 옵션은 타임스탬프의 세분성을 높이거나 `Comment_ID`를 사용하는 대신 증분 숫자를 접미사로 추가하는 것입니다. 이 경우 범위 기반 작업을 활성화하기 위해 의견에 해당하는 항목의 정렬 키 값 앞에 'comm\#'을 붙입니다.
또한 불만 사항 메타데이터의 `currentState`가 새 의견이 추가될 때의 상태를 반영하는지 확인해야 합니다. 의견을 추가하면 불만 사항이 에이전트에게 배정되었거나 해결되었다는 등의 메시지가 표시될 수 있습니다. 의견 추가 및 불만 사항 메타데이터의 현재 상태 업데이트를 전부 아니면 전무 방식으로 묶기 위해 [TransactWriteItems](https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_TransactWriteItems.html) API를 사용합니다. 이제 결과 테이블 상태는 다음과 같습니다.

테이블에 더 많은 데이터를 추가하고 `ComplaintID`에 대한 추가 인덱스가 필요한 경우 모델의 미래 유용성을 높이기 위해 `ComplaintID`를 `PK`와 별도의 필드로 추가해 보겠습니다. 또한 일부 의견에는 첨부 파일이 있을 수 있습니다. 이 첨부 파일은 Amazon Simple Storage Service에 저장하고 해당 참조 또는 URL만 DynamoDB에 보관합니다. 비용과 성능을 최적화하기 위해 트랜잭션 데이터베이스를 최대한 간결하게 유지하는 것이 좋습니다. 데이터는 이제 다음과 같습니다.

**3단계: 액세스 패턴 6(`getAllCommentsByComplaintID`) 및 7(`getLatestCommentByComplaintID`) 처리**
불만 사항에 대한 모든 의견을 가져오려면 정렬 키의 `begins_with` 조건과 함께 [`query`](Query.md) 작업을 사용할 수 있습니다. 이와 같은 정렬 키 조건을 사용하면 메타데이터 항목을 읽기 위해 읽기 용량을 추가로 소비하고 관련 결과를 필터링하는 오버헤드가 발생하는 대신 필요한 항목만 읽을 수 있습니다. 예를 들어, `PK=Complaint123` 및 `SK` begins\_with `comm#`을 사용한 쿼리 작업은 메타데이터 항목을 건너뛰는 동안 다음을 반환합니다.

패턴 7(`getLatestCommentByComplaintID`)의 불만 사항에 대한 최신 의견이 필요하므로 두 개의 추가 쿼리 파라미터를 사용하겠습니다.
1. 결과를 내림차순으로 정렬하려면 `ScanIndexForward`를 False로 설정해야 합니다.
1. 최신(단 하나) 의견을 가져오려면 `Limit`를 1로 설정해야 합니다.
액세스 패턴 6(`getAllCommentsByComplaintID`)과 유사하게 `begins_with` `comm#`을 정렬 키 조건으로 사용하여 메타데이터 항목을 건너뜁니다. 이제 `PK=Complaint123`, `SK=begins_with comm#`, `ScanIndexForward=False`, `Limit` 1과 함께 쿼리 작업을 사용하여 이 설계에서 액세스 패턴 7을 수행할 수 있습니다. 대상으로 지정된 다음 항목이 결과로 반환됩니다.
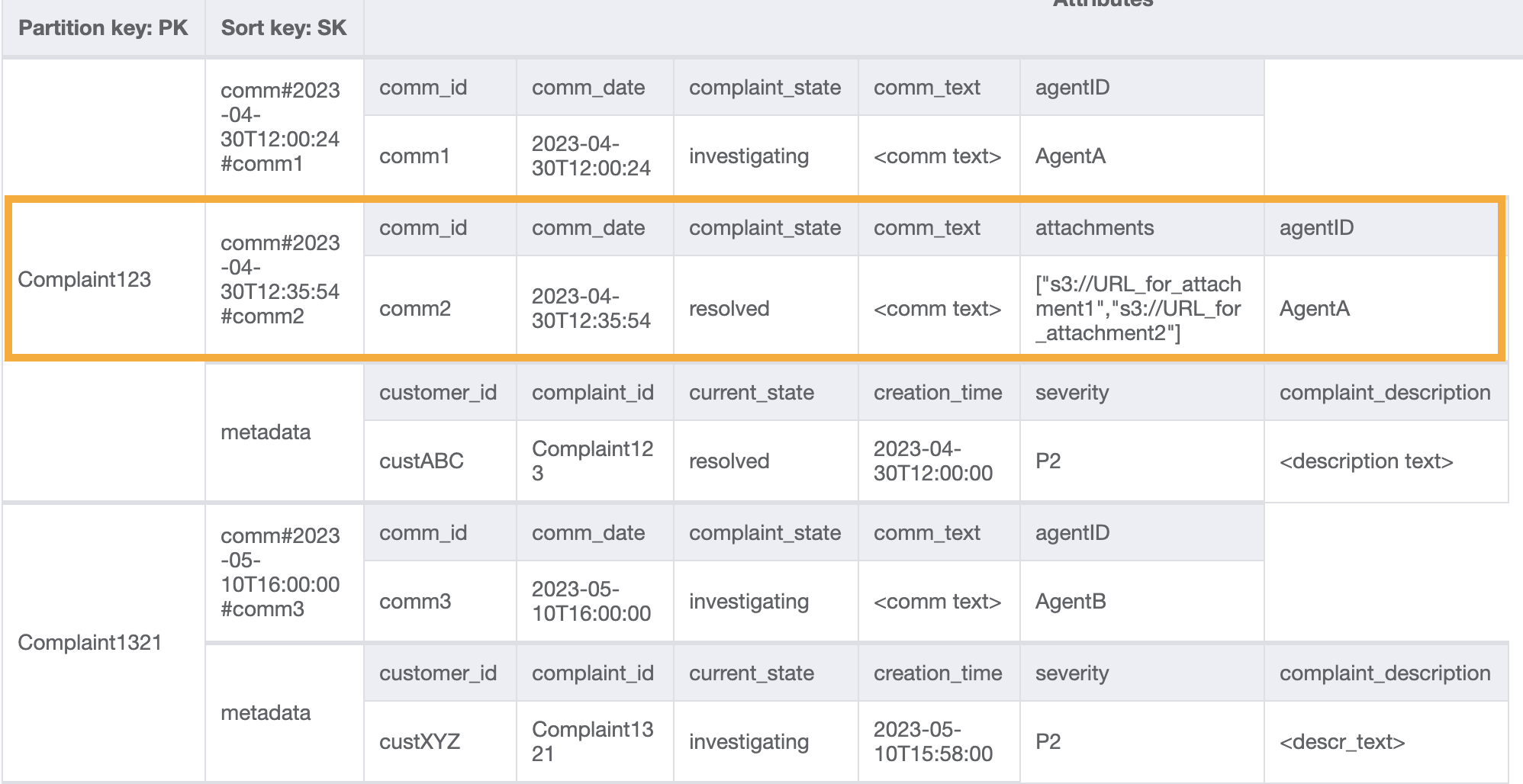
테이블에 더미 데이터를 더 추가해 보겠습니다.

**4단계: 액세스 패턴 8(`getAComplaintbyCustomerIDAndComplaintID`) 및 9(`getAllComplaintsByCustomerID`) 처리**
액세스 패턴 8(`getAComplaintbyCustomerIDAndComplaintID`) 및 9(`getAllComplaintsByCustomerID`)에는 `CustomerID`라는 새로운 검색 기준이 도입되었습니다. 기존 테이블에서 가져오려면 모든 데이터를 읽고 해당 `CustomerID`에 대한 관련 항목을 필터링하기 위해 비용이 많이 드는 [https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_Scan.html](https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_Scan.html)이 필요합니다. `CustomerID`를 파티션 키로 사용하여 [글로벌 보조 인덱스(GSI)](GSI.md)를 생성하면 이 검색을 더욱 효율적으로 만들 수 있습니다. 고객과 불만 사항 간의 일대다 관계와 액세스 패턴 9(`getAllComplaintsByCustomerID`)을 염두에 두면 `ComplaintID`가 정렬 키에 적합한 후보가 됩니다.
GSI의 데이터는 다음과 같습니다.
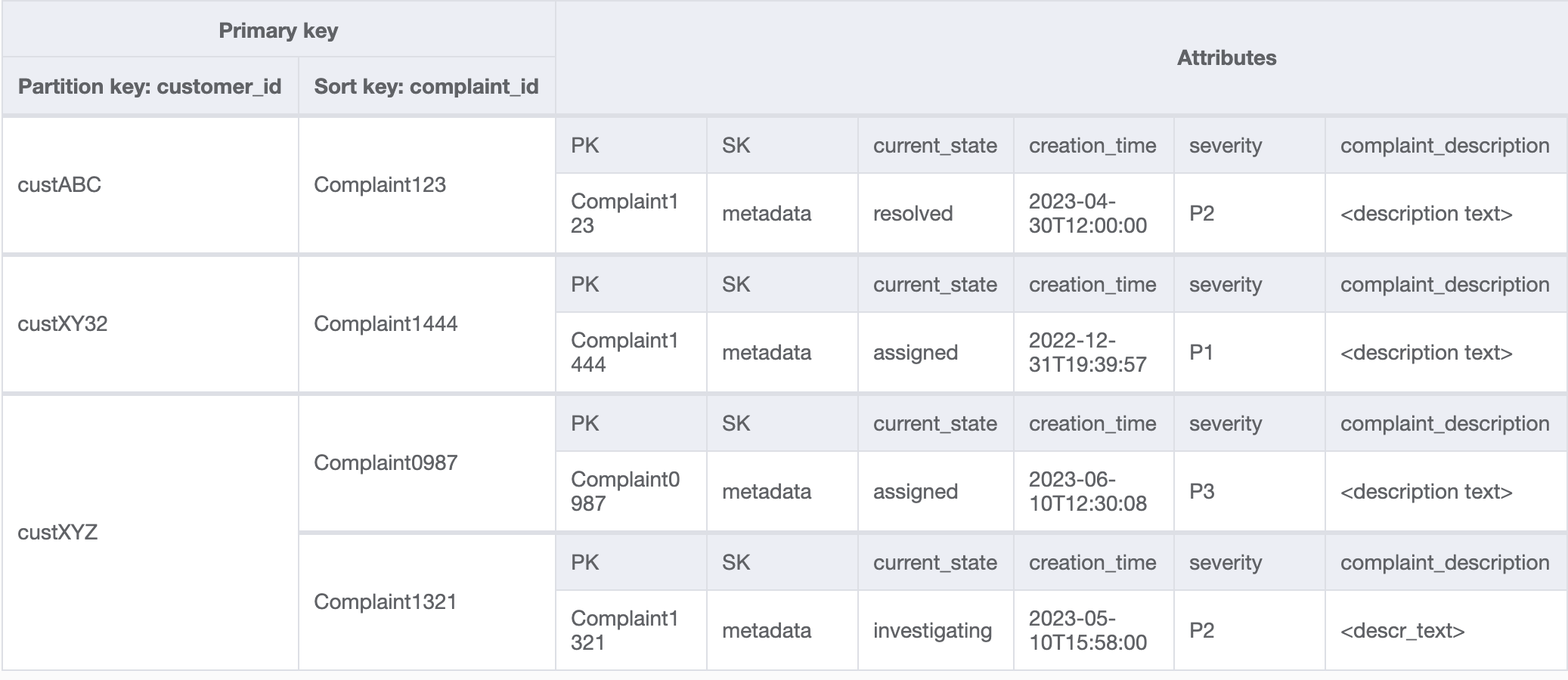
액세스 패턴 8(`getAComplaintbyCustomerIDAndComplaintID`)에 대한 이 GSI의 쿼리 예시는 `customer_id=custXYZ`, `sort key=Complaint1321`입니다. 결과는 다음과 같습니다.

액세스 패턴 9(`getAllComplaintsByCustomerID`)에 대한 고객의 모든 불만 사항을 가져오려면 GSI에 대한 쿼리는 파티션 키 조건으로 `customer_id=custXYZ`입니다. 결과는 다음과 같습니다.
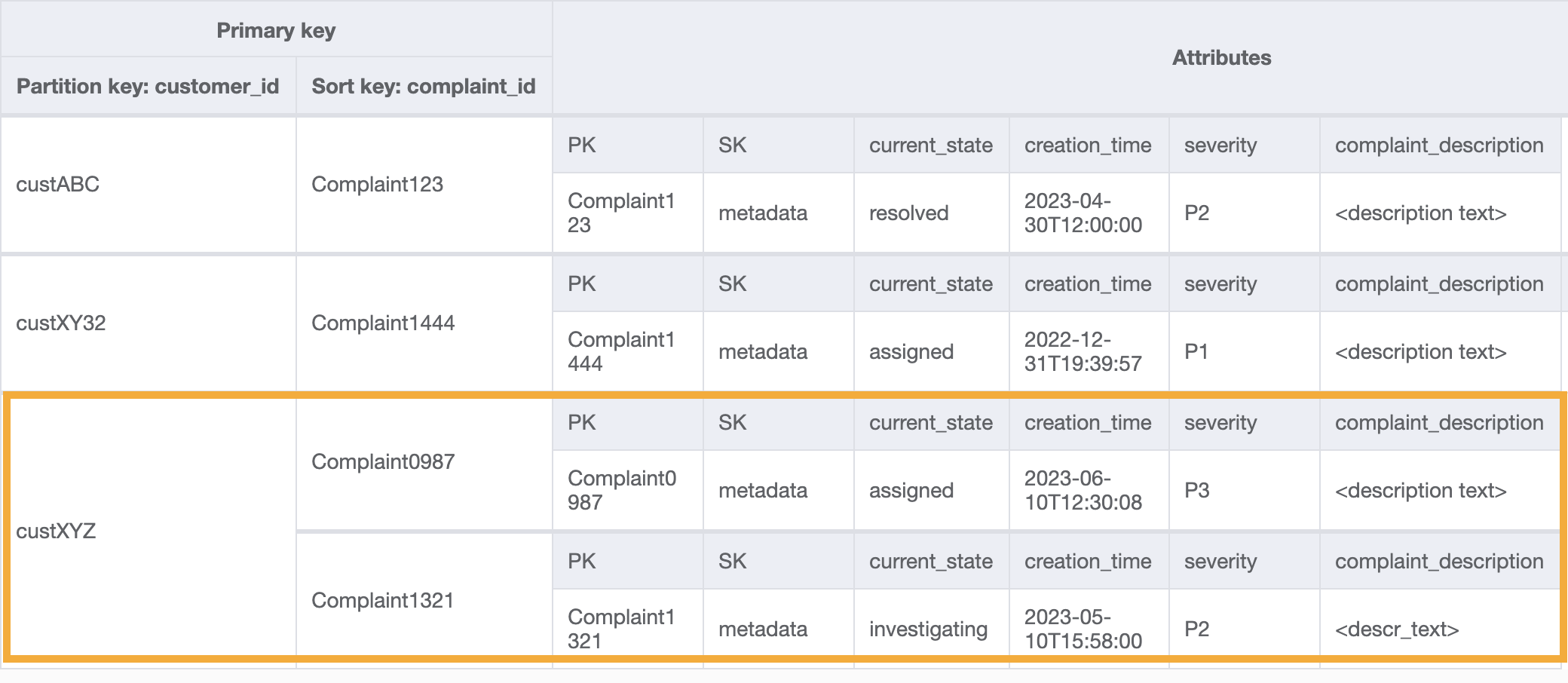
**5단계: 액세스 패턴 10(`escalateComplaintByComplaintID`) 처리**
이 액세스에는 에스컬레이션 측면이 도입됩니다. 불만 사항을 에스컬레이션하기 위해 `UpdateItem`을 사용하여 `escalated_to` 및 `escalation_time`과 같은 속성을 기존 불만 사항 메타데이터 항목에 추가할 수 있습니다. DynamoDB는 유연한 스키마 설계를 제공하므로 키가 아닌 속성 세트가 여러 항목 간에 균일하거나 이산적일 수 있습니다. 아래 예를 참조하세요.
`UpdateItem with PK=Complaint1444, SK=metadata`

**6단계: 액세스 패턴 11(`getAllEscalatedComplaints`) 및 12(`getEscalatedComplaintsByAgentID`) 처리**
전체 데이터 세트에서 소수의 불만 사항만 에스컬레이션될 것으로 예상됩니다. 따라서 에스컬레이션 관련 속성에 대한 인덱스를 생성하면 효율적인 조회는 물론 비용 효율적인 GSI 저장이 가능합니다. 이를 위해 [희소 인덱스](data-modeling-blocks.md#data-modeling-blocks-sparse-index) 기법을 활용할 수 있습니다. 파티션 키가 `escalated_to`이고 정렬 키가 `escalation_time`인 GSI는 다음과 같습니다.

액세스 패턴 11(`getAllEscalatedComplaints`)에 대해 에스컬레이션된 모든 불만 사항을 가져오려면 이 GSI를 스캔하면 됩니다. 이 스캔은 GSI의 크기 때문에 성능과 비용 효율성이 뛰어납니다. 특정 에이전트에 대해 에스컬레이션된 불만 사항을 가져오려면(액세스 패턴 12(`getEscalatedComplaintsByAgentID`)) 파티션 키를 `escalated_to=agentID`로 지정하고 `ScanIndexForward`를 `False`로 설정하여 최신 항목부터 오래된 항목 순으로 정렬합니다.
**7단계: 액세스 패턴 13(`getCommentsByAgentID`) 처리**
마지막 액세스 패턴의 경우 새로운 차원인 `AgentID`로 조회를 수행해야 합니다. 또한 두 날짜 사이의 의견을 읽으려면 시간 기반 순서가 필요하므로 파티션 키로 `agent_id`를, 정렬 키로 `comm_date`를 사용하여 GSI를 생성합니다. 이 GSI의 데이터는 다음과 같습니다.

이 GSI에 대한 예시 쿼리는 `partition key agentID=AgentA` 및 `sort key=comm_date between (2023-04-30T12:30:00, 2023-05-01T09:00:00)`이며, 그 결과는 다음과 같습니다.

모든 액세스 패턴과 스키마 설계에서 이를 처리하는 방법이 아래 표에 요약되어 있습니다.
| 액세스 패턴 | 기본 테이블/GSI/LSI | 연산 | 파티션 키 값 | 정렬 키 값 | 기타 조건/필터 |
| --- | --- | --- | --- | --- | --- |
| createComplaint | 기본 테이블 | PutItem | PK=complaint\_id | SK=metadata | |
| updateComplaint | 기본 테이블 | UpdateItem | PK=complaint\_id | SK=metadata | |
| updateSeveritybyComplaintID | 기본 테이블 | UpdateItem | PK=complaint\_id | SK=metadata | |
| getComplaintByComplaintID | 기본 테이블 | GetItem | PK=complaint\_id | SK=metadata | |
| addCommentByComplaintID | 기본 테이블 | TransactWriteItems | PK=complaint\_id | SK=metadata, SK=comm\#comm\_date\#comm\_id | |
| getAllCommentsByComplaintID | 기본 테이블 | 쿼리 | PK=complaint\_id | SK begins\_with "comm\#" | |
| getLatestCommentByComplaintID | 기본 테이블 | 쿼리 | PK=complaint\_id | SK begins\_with "comm\#" | scan\_index\_forward=False, Limit 1 |
| getAComplaintbyCustomerIDAndComplaintID | Customer\_complaint\_GSI | 쿼리 | customer\_id=customer\_id | complaint\_id = complaint\_id | |
| getAllComplaintsByCustomerID | Customer\_complaint\_GSI | 쿼리 | customer\_id=customer\_id | 해당 사항 없음 | |
| escalateComplaintByComplaintID | 기본 테이블 | UpdateItem | PK=complaint\_id | SK=metadata | |
| getAllEscalatedComplaints | Escalations\_GSI | 스캔 | 해당 사항 없음 | 해당 사항 없음 | |
| getEscalatedComplaintsByAgentID(최신 것부터 가장 오래된 것 순) | Escalations\_GSI | 쿼리 | escalated\_to=agent\_id | 해당 사항 없음 | scan\_index\_forward=False |
| getCommentsByAgentID(두 날짜 사이) | Agents\_Comments\_GSI | 쿼리 | agent\_id=agent\_id | SK between (date1, date2) | |
## 불만 관리 시스템 최종 스키마
다음은 최종 스키마 설계입니다. 이 스키마 설계를 JSON 파일로 다운로드하려면 GitHub의 [DynamoDB 예제](https://github.com/aws-samples/aws-dynamodb-examples/blob/master/schema_design/SchemaExamples/ComplainManagement/ComplaintManagementSchema.json)를 참조하세요.
**기본 테이블**

**Customer\_Complaint\_GSI**

**Escalations\_GSI**

**Agents\_Comments\_GSI**

## 이 스키마 설계와 함께 NoSQL Workbench 사용
이 최종 스키마를 DynamoDB 데이터 모델링, 데이터 시각화, 쿼리 개발 기능을 제공하는 시각적 도구인 [NoSQL Workbench](workbench.md)로 가져와서 새 프로젝트를 추가로 탐색하고 편집할 수 있습니다. 시작하려면 다음 단계를 따릅니다.
1. NoSQL Workbench 다운로드 자세한 내용은 [DynamoDB용 NoSQL Workbench 다운로드](workbench.settingup.md) 섹션을 참조하세요.
1. 위에 나열된 JSON 스키마 파일을 다운로드합니다. 이 파일은 이미 NoSQL Workbench 모델 형식으로 되어 있습니다.
1. JSON 스키마 파일을 NoSQL Workbench로 가져옵니다. 자세한 내용은 [기존 데이터 모델 가져오기](workbench.Modeler.ImportExisting.md) 섹션을 참조하세요.
1. NOSQL Workbench로 가져온 후 데이터 모델을 편집할 수 있습니다. 자세한 내용은 [기존 데이터 모델 편집](workbench.Modeler.Edit.md) 섹션을 참조하세요.