소스 RDS 데이터베이스에 데이터 추가 및 쿼리
Amazon RDS에서 Amazon Redshift로 데이터를 복제하는 제로 ETL 통합 생성을 완료하려면 대상 목적지에 데이터베이스를 생성해야 합니다.
Amazon Redshift와의 연결을 위해 Amazon Redshift 클러스터 또는 작업 그룹에 연결하고 통합 식별자에 대한 참조가 있는 데이터베이스를 생성합니다. 그런 다음 소스 RDS 데이터베이스에 데이터를 추가하고 Amazon Redshift 또는 Amazon SageMaker에서 복제된 것을 확인할 수 있습니다.
주제
대상 데이터베이스 생성
통합을 생성한 후에 Amazon Redshift로 데이터 복제를 시작하려면 먼저 대상 데이터 웨어하우스에 데이터베이스를 만들어야 합니다. 이 데이터베이스에는 통합 식별자에 대한 참조가 포함되어야 합니다. Amazon Redshift 콘솔 또는 쿼리 편집기 v2를 사용하여 데이터베이스를 생성할 수 있습니다.
대상 데이터베이스를 생성하는 방법에 대한 지침은 Amazon Redshift에서 대상 데이터베이스 생성을 참조하세요.
소스 데이터베이스에 데이터 추가
통합을 구성한 후, 데이터 웨어하우스로 복제하려는 데이터로 소스 RDS 데이터베이스를 채울 수 있습니다.
참고
Amazon RDS의 데이터 유형과 대상 분석 웨어하우스에는 차이가 있습니다. 데이터 유형 매핑 표는 RDS와 Amazon Redshift 데이터베이스 간의 데이터 유형 차이 섹션을 참조하세요.
먼저, 선택한 MySQL 클라이언트를 사용하여 소스 데이터베이스에 연결합니다. 지침은 MySQL DB 인스턴스에 연결 섹션을 참조하세요.
그런 다음 테이블을 만들고 샘플 데이터 행을 삽입합니다.
중요
테이블에 프라이머리 키가 있는지 확인하세요. 없는 경우 대상 데이터 웨어하우스에 복제할 수 없습니다.
RDS for MySQL
다음 예제에서는 MySQL Workbench 유틸리티
CREATE DATABASEmy_db; USEmy_db; CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
RDS for PostgreSQL:
다음 예제에서는 psql PostgreSQL 대화형 터미널을 사용합니다. 데이터베이스에 연결할 때 복제하려는 데이터베이스 이름을 포함합니다.
psql -hmydatabase.123456789012.us-east-2.rds.amazonaws.com -p 5432 -Uusername-dnamed_db; named_db=> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); named_db=> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
RDS for Oracle:
다음 예제에서는 SQL*Plus를 사용하여 RDS for Oracle 데이터베이스에 연결합니다.
sqlplus 'user_name@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=dns_name)(PORT=port))(CONNECT_DATA=(SID=database_name)))' SQL> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); SQL> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
Amazon Redshift에서 Amazon RDS 데이터 쿼리
RDS 데이터베이스에 데이터를 추가하면 데이터가 대상 데이터베이스에 복제되어 쿼리할 준비가 됩니다.
복제된 데이터를 쿼리하려면
-
Amazon Redshift 콘솔로 이동한 다음 왼쪽 탐색 창에서 쿼리 편집기 v2를 선택합니다.
-
클러스터 또는 작업 그룹에 연결하고 드롭다운 메뉴(이 예시에서는 destination_database)에서 대상 데이터베이스(통합에서 생성한 데이터베이스)를 선택합니다. 대상 데이터베이스를 생성하는 방법에 대한 지침은 Amazon Redshift에서 대상 데이터베이스 생성을 참조하세요.
-
SELECT 문을 사용하여 데이터를 쿼리합니다. 이 예제에서는 다음 명령을 실행하여 소스 RDS 데이터베이스에서 생성한 테이블의 모든 데이터를 선택합니다.
SELECT * frommy_db."books_table";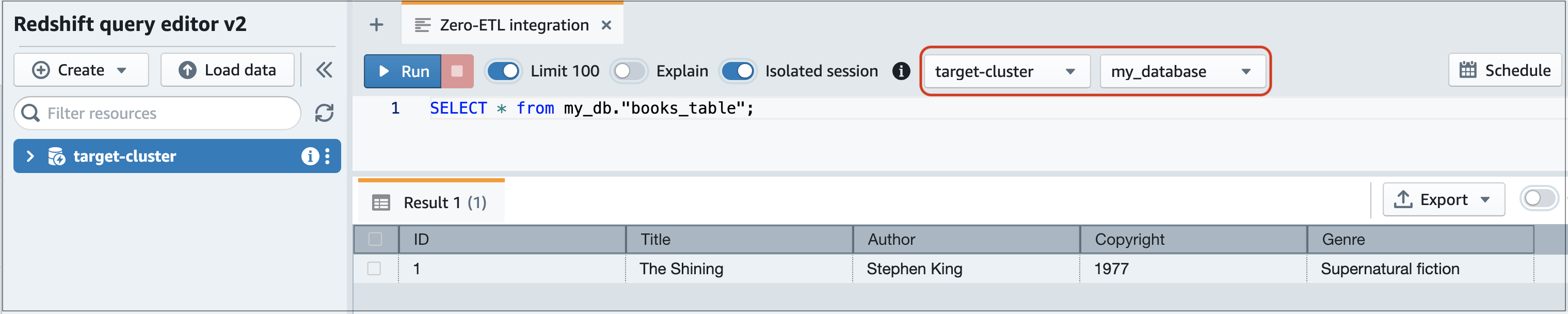
-
my_db -
books_table
-
명령줄 클라이언트를 사용하여 데이터를 쿼리할 수도 있습니다. 예제:
destination_database=# select * frommy_db."books_table"; ID | Title | Author | Copyright | Genre | txn_seq | txn_id ----+–------------+---------------+-------------+------------------------+----------+--------+ 1 | The Shining | Stephen King | 1977 | Supernatural fiction | 2 | 12192
참고
대/소문자를 구분하려면 스키마, 테이블 및 열 이름에 큰따옴표(" ")를 사용합니다. 자세한 내용은 enable_case_sensitive_identifier 단원을 참조하세요.
RDS와 Amazon Redshift 데이터베이스 간의 데이터 유형 차이
다음 표에는 해당하는 대상 데이터 유형에 대한 RDS for MySQL, RDS for PostgreSQL 및 RDS for Oracle 데이터 유형의 매핑이 나와 있습니다. Amazon RDS는 현재 제로 ETL 통합에 이러한 데이터 유형만 지원합니다.
소스 데이터베이스의 테이블에 지원되지 않는 데이터 유형이 포함된 경우 테이블이 동기화되지 않아 대상에서 사용할 수 없습니다. 소스에서 대상으로의 스트리밍은 계속되지만 지원되지 않는 데이터 유형이 있는 테이블은 사용할 수 없습니다. 테이블을 수정하고 대상에서 사용할 수 있게 하려면 주요 변경 사항을 수동으로 되돌린 다음 ALTER DATABASE...INTEGRATION
REFRESH를 실행하여 통합을 새로 고쳐야 합니다.
참고
Amazon SageMaker 레이크하우스와의 제로 ETL 통합은 새로 고칠 수 없습니다. 대신 통합을 삭제하고 다시 생성해 보세요.
RDS for MySQL
| RDS for MySQL 데이터 유형 | 대상 데이터 유형 | 설명 | 제한 사항 |
|---|---|---|---|
| INT | INTEGER | 4바이트 부호화 정수 | 없음 |
| SMALLINT | SMALLINT | 2바이트 부호화 정수 | 없음 |
| TINYINT | SMALLINT | 2바이트 부호화 정수 | 없음 |
| MEDIUMINT | INTEGER | 4바이트 부호화 정수 | 없음 |
| BIGINT | BIGINT | 8바이트 부호화 정수 | 없음 |
| INT UNSIGNED | BIGINT | 8바이트 부호화 정수 | 없음 |
| TINYINT UNSIGNED | SMALLINT | 2바이트 부호화 정수 | 없음 |
| MEDIUMINT UNSIGNED | INTEGER | 4바이트 부호화 정수 | 없음 |
| BIGINT UNSIGNED | DECIMAL(20,0) | 정밀도를 선택할 수 있는 정확한 숫자 | 없음 |
| DECIMAL(p,s) = NUMERIC(p,s) | DECIMAL (p,s) | 정밀도를 선택할 수 있는 정확한 숫자 |
38보다 큰 정밀도 및 37보다 큰 확장은 지원되지 않음 |
| DECIMAL(p,s) UNSIGNED = NUMERIC(p,s) UNSIGNED | DECIMAL (p,s) | 정밀도를 선택할 수 있는 정확한 숫자 |
38보다 큰 정밀도 및 37보다 큰 확장은 지원되지 않음 |
| FLOAT4/REAL | REAL | 단정밀도 부동 소수점 수 | 없음 |
| FLOAT4/REAL UNSIGNED | REAL | 단정밀도 부동 소수점 수 | 없음 |
| DOUBLE/REAL/FLOAT8 | DOUBLE PRECISION | 배정밀도 부동 소수점 수 | 없음 |
| DOUBLE/REAL/FLOAT8 UNSIGNED | DOUBLE PRECISION | 배정밀도 부동 소수점 수 | 없음 |
| BIT(n) | VARBYTE(8) | 가변 길이 이진 값 | 없음 |
| BINARY(n) | VARBYTE(n) | 가변 길이 이진 값 | 없음 |
| VARBINARY(n) | VARBYTE(n) | 가변 길이 이진 값 | 없음 |
| CHAR (n) | VARCHAR(n) | 길이가 가변적인 문자열 값 | 없음 |
| VARCHAR(n) | VARCHAR(n) | 길이가 가변적인 문자열 값 | 없음 |
| TEXT | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
| TINYTEXT | VARCHAR(255) | 최대 255자의 길이가 가변적인 문자열 값 | 없음 |
| MEDIUMTEXT | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
| LONGTEXT | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
| ENUM | VARCHAR(1,020) | 최대 1,020자의 길이가 가변적인 문자열 값 | 없음 |
| SET | VARCHAR(1,020) | 최대 1,020자의 길이가 가변적인 문자열 값 | 없음 |
| DATE | DATE | 날짜(년, 월, 일) | 없음 |
| DATETIME | TIMESTAMP | 날짜/시간(시간대 제외) | 없음 |
| TIMESTAMP(p) | TIMESTAMP | 날짜/시간(시간대 제외) | 없음 |
| TIME | VARCHAR(18) | 최대 18자의 길이가 가변적인 문자열 값 | 없음 |
| YEAR | VARCHAR(4) | 최대 4자의 길이가 가변적인 문자열 값 | 없음 |
| JSON | SUPER | 반정형 데이터 또는 문서 값 | 없음 |
RDS for PostgreSQL
RDS for PostgreSQL의 제로 ETL 통합은 사용자 지정 데이터 유형이나 확장에서 만든 데이터 유형을 지원하지 않습니다.
| RDS for PostgreSQL 데이터 유형 | Amazon Redshift 데이터 형식 | 설명 | 제한 사항 |
|---|---|---|---|
| 배열 | SUPER | 반정형 데이터 또는 문서 값 | 없음 |
| bigint | BIGINT | 8바이트 부호화 정수 | 없음 |
| bigserial | BIGINT | 8바이트 부호화 정수 | 없음 |
| bit varying(n) | VARBYTE(n) | 최대 16,777,216바이트의 길이가 가변적인 이진 값 | 없음 |
| bit(n) | VARBYTE(n) | 최대 16,777,216바이트의 길이가 가변적인 이진 값 | 없음 |
| bit, bit varying | VARBYTE(16777216) | 최대 16,777,216바이트의 길이가 가변적인 이진 값 | 없음 |
| 부울 | BOOLEAN | 논리적 부울(true/false) | 없음 |
| bytea | VARBYTE(16777216) | 최대 16,777,216바이트의 길이가 가변적인 이진 값 | 없음 |
| char(n) | CHAR (n) | 최대 65,535바이트의 길이가 고정된 문자 문자열 값 | 없음 |
| char varying(n) | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자 문자열 값 | 없음 |
| cid | BIGINT |
8바이트 부호화 정수 |
없음 |
| cidr |
VARCHAR(19) |
최대 19자의 길이가 가변적인 문자열 값 |
없음 |
| 날짜 | DATE | 날짜(년, 월, 일) |
지원되지 않는 294,276 A.D. 값보다 큰 값 |
| double precision | DOUBLE PRECISION | 배정밀도 부동 소수점 수 | 비정상 값은 완전히 지원되지 않음 |
|
gtsvector |
VARCHAR(65,535) |
최대 65,535자의 길이가 가변적인 문자열 값 |
없음 |
| inet |
VARCHAR(19) |
최대 19자의 길이가 가변적인 문자열 값 |
없음 |
| 정수 | INTEGER | 4바이트 부호화 정수 | 없음 |
|
int2vector |
SUPER | 반정형 데이터 또는 문서 값. | 없음 |
| 간격 | INTERVAL | 지속 시간 | YEAR TO MONTH 또는 DAY TO SECOND 한정자를 지정하는 INTERVAL 유형만 지원됩니다. |
| json | SUPER | 반정형 데이터 또는 문서 값 | 없음 |
| jsonb | SUPER | 반정형 데이터 또는 문서 값 | 없음 |
| jsonpath | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
|
macaddr |
VARCHAR(17) | 최대 17자의 길이가 가변적인 문자열 값 | 없음 |
|
macaddr8 |
VARCHAR(23) | 최대 23자의 길이가 가변적인 문자열 값 | 없음 |
| money | DECIMAL(203) | 통화 금액 | 없음 |
| 이름 | VARCHAR(64) | 최대 64자의 길이가 가변적인 문자열 값 | 없음 |
| numeric(p,s) | DECIMAL (p,s) | 사용자 정의 고정 정밀도 값 |
|
| oid | BIGINT | 8바이트 부호화 정수 | 없음 |
| oidvector | SUPER | 반정형 데이터 또는 문서 값. | 없음 |
| pg_brin_bloom_summary | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
| pg_dependencies | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
| pg_lsn | VARCHAR(17) | 최대 17자의 길이가 가변적인 문자열 값 | 없음 |
| pg_mcv_list | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
| pg_ndistinct | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
| pg_node_tree | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
| pg_snapshot | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
| real | REAL | 단정밀도 부동 소수점 수 | 비정상 값은 완전히 지원되지 않음 |
| refcursor | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
| smallint | SMALLINT | 2바이트 부호화 정수 | 없음 |
| smallserial | SMALLINT | 2바이트 부호화 정수 | 없음 |
| serial | INTEGER | 4바이트 부호화 정수 | 없음 |
| 텍스트 | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
| tid | VARCHAR(23) | 최대 23자의 길이가 가변적인 문자열 값 | 없음 |
| time [(p)] 시간대 제외 | VARCHAR(19) | 최대 19자의 길이가 가변적인 문자열 값 | Infinity 및 -Infinity 값은 지원되지 않음 |
| time [ (p) ](시간대 포함) | VARCHAR(22) | 최대 22자의 길이가 가변적인 문자열 값 | Infinity 및 -Infinity 값은 지원되지 않음 |
| timestamp [(p)] 시간대 제외 | TIMESTAMP | 날짜/시간(시간대 제외) |
|
| timestamp [(p)](시간대 포함) | TIMESTAMPTZ | 날짜/시간(시간대 포함) |
|
| tsquery | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
| tsvector | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
| txid_snapshot | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
| uuid | VARCHAR(36) | 가변 길이 36자 문자열 | 없음 |
| xid | BIGINT | 8바이트 부호화 정수 | 없음 |
| xid8 | DECIMAL(20, 0) | 고정 정밀도 소수 | 없음 |
| xml | VARCHAR(65,535) | 최대 65,535자의 길이가 가변적인 문자열 값 | 없음 |
RDS for Oracle
지원되지 않는 데이터 형식
다음 RDS for Oracle 데이터 형식은 Amazon Redshift에서 지원되지 않습니다.
-
ANYDATA -
BFILE -
REF -
ROWID -
UROWID -
VARRAY -
SDO_GEOMETRY -
사용자 정의 데이터 형식
데이터 형식 차이
다음 표에는 RDS for Oracle이 소스이고 Amazon Redshift가 대상일 때 제로 ETL 통합에 영향을 미치는 데이터 유형 차이가 나와 있습니다.
| RDS for Oracle 데이터 형식 | Amazon Redshift 데이터 형식 |
|---|---|
|
BINARY_FLOAT |
FLOAT4 |
|
BINARY_DOUBLE |
FLOAT8 |
|
BINARY |
VARCHAR(길이) |
|
FLOAT (P) |
정밀도가 24 이하이면 FLOAT4를 사용합니다. 정밀도가 24를 초과하면 FLOAT8을 사용합니다. |
|
NUMBER (P,S) |
크기가 0 이상, 37 이하면 NUMERIC(p,s)을 사용합니다. 크기가 38 이상, 127 이하면 VARCHAR(길이)를 사용합니다. 크기가 0인 경우:
크기가 0 미만이면 INT8을 사용합니다. |
|
DATE |
Redshift 대상 열 유형에 따라 크기가 0 이상, 6 이하라면 다음 중 하나를 사용합니다.
크기가 7 이상, 9 이하인 경우 VARCHAR(37)를 사용합니다. |
|
INTERVAL_YEAR TO MONTH |
길이가 1~65,535인 경우 VARCHAR(바이트 단위의 길이)를 사용합니다. 길이가 65,536~2,147,483,647인 경우 VARCHAR(65535)를 사용합니다. |
|
INTERVAL_DAY TO SECOND |
길이가 1~65,535인 경우 VARCHAR(바이트 단위의 길이)를 사용합니다. 길이가 65,536~2,147,483,647인 경우 VARCHAR(65535)를 사용합니다. |
|
TIMESTAMP |
Redshift 대상 열 유형에 따라 크기가 0 이상, 6 이하라면 다음 중 하나를 사용합니다.
크기가 7 이상, 9 이하인 경우 VARCHAR(37)를 사용합니다. |
|
TIMESTAMP(시간대 사용) |
길이가 1~65,535인 경우 VARCHAR(바이트 단위의 길이)를 사용합니다. 길이가 65,536~2,147,483,647인 경우 VARCHAR(65535)를 사용합니다. |
|
TIMESTAMP WITH LOCAL TIME ZONE |
길이가 1~65,535인 경우 VARCHAR(바이트 단위의 길이)를 사용합니다. 길이가 65,536~2,147,483,647인 경우 VARCHAR(65535)를 사용합니다. |
|
CHAR |
길이가 1~65,535인 경우 VARCHAR(바이트 단위의 길이)를 사용합니다. 길이가 65,536~2,147,483,647인 경우 VARCHAR(65535)를 사용합니다. |
|
VARCHAR2 |
길이가 4,000바이트보다 큰 경우 VARCHAR(최대 LOB 크기)를 사용합니다. 최대 LOB 크기는 63KB를 초과할 수 없습니다. Amazon Redshift는 64KB를 초과하는 VARCHAR를 지원하지 않습니다. 길이가 4,000바이트 이하인 경우 VARCHAR(바이트 단위의 길이)를 사용합니다. |
|
NCHAR |
길이가 1~65,535인 경우 NVARCHAR(바이트 단위의 길이)를 사용합니다. 길이가 65,536~2,147,483,647인 경우 NVARCHAR(65535)를 사용합니다. |
|
NVARCHAR2 |
길이가 4,000바이트보다 큰 경우 NVARCHAR(최대 LOB 크기)를 사용합니다. 최대 LOB 크기는 63KB를 초과할 수 없습니다. Amazon Redshift는 64KB를 초과하는 VARCHAR를 지원하지 않습니다. 길이가 4,000바이트 이하인 경우 NVARCHAR(바이트 단위의 길이)를 사용합니다. |
|
RAW |
VARCHAR(길이) |
|
REAL |
FLOAT8 |
|
BLOB |
VARCHAR(최대 LOB 크기 *2) 최대 LOB 크기는 31KB를 초과할 수 없습니다. Amazon Redshift는 64KB를 초과하는 VARCHAR를 지원하지 않습니다. |
|
CLOB |
VARCHAR(최대 LOB 크기) 최대 LOB 크기는 63KB를 초과할 수 없습니다. Amazon Redshift는 64KB를 초과하는 VARCHAR를 지원하지 않습니다. |
|
NCLOB |
NVARCHAR(최대 LOB 크기) 최대 LOB 크기는 63KB를 초과할 수 없습니다. Amazon Redshift는 64KB를 초과하는 VARCHAR를 지원하지 않습니다. |
|
LONG |
VARCHAR(최대 LOB 크기) 최대 LOB 크기는 63KB를 초과할 수 없습니다. Amazon Redshift는 64KB를 초과하는 VARCHAR를 지원하지 않습니다. |
|
LONG RAW |
VARCHAR(최대 LOB 크기 *2) 최대 LOB 크기는 31KB를 초과할 수 없습니다. Amazon Redshift는 64KB를 초과하는 VARCHAR를 지원하지 않습니다. |
|
XMLTYPE |
VARCHAR(최대 LOB 크기) 최대 LOB 크기는 63KB를 초과할 수 없습니다. Amazon Redshift는 64KB를 초과하는 VARCHAR를 지원하지 않습니다. |
RDS for PostgreSQL에 대한 DDL 작업
Amazon Redshift는 PostgreSQL에서 파생되므로 일반적인 PostgreSQL 아키텍처로 인해 RDS for PostgreSQL과 여러 기능을 공유합니다. 제로 ETL 통합은 이러한 유사성을 활용하여 RDS for PostgreSQL에서 Amazon Redshift로의 데이터 복제를 간소화하고, 데이터베이스를 이름으로 매핑하며, 공유 데이터베이스, 스키마 및 테이블 구조를 활용합니다.
RDS for PostgreSQL 제로 ETL 통합을 관리할 때는 다음 사항을 고려하세요.
-
격리는 데이터베이스 수준에서 관리됩니다.
-
복제는 데이터베이스 수준에서 발생합니다.
-
RDS for PostgreSQL 데이터베이스는 이름별로 Amazon Redshift 데이터베이스에 매핑되며, 원본 이름이 변경된 경우 해당 이름이 변경된 Redshift 데이터베이스로 데이터가 흐릅니다.
유사점에도 불구하고 Amazon Redshift와 RDS for PostgreSQL 간에는 중요한 차이점이 있습니다. 다음 섹션에서는 일반적인 DDL 작업에 대한 Amazon Redshift 시스템 응답을 간략하게 설명합니다.
데이터베이스 작업
다음 표는 데이터베이스 DDL 작업에 대한 시스템 응답을 보여줍니다.
| DDL 작업 | Redshift 시스템 응답 |
|---|---|
CREATE DATABASE |
작업 없음 |
DROP DATABASE |
Amazon Redshift는 대상 Redshift 데이터베이스에서 모든 데이터를 삭제합니다. |
RENAME DATABASE |
Amazon Redshift는 원래 대상 데이터베이스의 모든 데이터를 삭제하고 새 대상 데이터베이스의 데이터를 다시 동기화합니다. 새 데이터베이스가 없는 경우 수동으로 생성해야 합니다. 자세한 지침은 Amazon Redshift에서 대상 데이터베이스 생성을 참조하세요. |
스키마 작업
다음 표는 스키마 DDL 작업에 대한 시스템 응답을 보여줍니다.
| DDL 작업 | Redshift 시스템 응답 |
|---|---|
CREATE SCHEMA |
작업 없음 |
DROP SCHEMA |
Amazon Redshift는 원래 스키마를 삭제합니다. |
RENAME SCHEMA |
Amazon Redshift는 원래 스키마를 삭제한 다음 새 스키마의 데이터를 다시 동기화합니다. |
테이블 작업
다음 표는 테이블 DDL 작업에 대한 시스템 응답을 보여줍니다.
| DDL 작업 | Redshift 시스템 응답 |
|---|---|
CREATE TABLE |
Amazon Redshift는 테이블을 생성합니다. 프라이머리 키 없이 테이블을 생성하거나 선언적 파티셔닝을 수행하는 등의 일부 작업으로 인해 테이블 생성이 실패합니다. 자세한 내용은 제한 사항 및 Amazon RDS 제로 ETL 통합 문제 해결(을)를 참조하세요. |
DROP TABLE |
Amazon Redshift는 테이블을 삭제합니다. |
TRUNCATE TABLE |
Amazon Redshift는 테이블을 자릅니다. |
ALTER TABLE
(RENAME...) |
Amazon Redshift는 테이블 또는 열의 이름을 바꿉니다. |
ALTER TABLE (SET
SCHEMA) |
Amazon Redshift는 원래 스키마에서 테이블을 삭제하고 새 스키마의 테이블을 다시 동기화합니다. |
ALTER TABLE (ADD PRIMARY
KEY) |
Amazon Redshift는 프라이머리 키를 추가하고 테이블을 다시 동기화합니다. |
ALTER TABLE (ADD
COLUMN) |
Amazon Redshift는 테이블에 열을 추가합니다. |
ALTER TABLE (DROP
COLUMN) |
Amazon Redshift는 프라이머리 키 열이 아닌 경우 열을 삭제합니다. 그렇지 않으면 테이블이 다시 동기화됩니다. |
ALTER TABLE (SET
LOGGED/UNLOGGED) |
테이블을 로깅되도록 변경하면 Amazon Redshift가 테이블을 다시 동기화합니다. 테이블을 로깅되지 않도록 변경하면 Amazon Redshift가 테이블을 삭제합니다. |
