翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
処理中の復旧とチェックポイントレストレーニング
HyperPod チェックポイントレストレーニングでは、モデルの冗長性を使用して耐障害性トレーニングを有効にします。コア原則は、モデルとオプティマイザの状態が複数のノードグループに完全にレプリケートされ、重みの更新とオプティマイザの状態の変更が各グループ内で同期的にレプリケートされることです。障害が発生すると、正常なレプリカはオプティマイザのステップを完了し、更新されたモデル/オプティマイザの状態を復旧中のレプリカに送信します。
このモデル冗長性ベースのアプローチにより、いくつかの障害処理メカニズムが可能になります。
-
プロセス内の復旧: 障害が発生してもプロセスはアクティブのままで、すべてのモデルとオプティマイザの状態を GPU メモリに最新の値で保持します。
-
正常な中止処理: 影響を受けるオペレーションの制御された中止とリソースクリーンアップ
-
コードブロックの再実行: 再実行可能なコードブロック (RCB) 内の影響を受けるコードセグメントのみを再実行します。
-
トレーニングの進行状況が失われないチェックポイントレスリカバリ: プロセスが保持され、状態がメモリに残るため、トレーニングの進行状況は失われません。障害が発生した場合は、最後に保存されたチェックポイントから再開するのではなく、前のステップからトレーニングを再開します。
チェックポイントレス設定
チェックポイントレストレーニングのコアスニペットを次に示します。
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank wait_rank() def main(): @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=PEFTCheckpointManager(enable_offload=True), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), ) def run_main(cfg, caller: Optional[HPCallWrapper] = None): ... trainer = Trainer( strategy=CheckpointlessMegatronStrategy(..., num_distributed_optimizer_instances=2), callbacks=[..., CheckpointlessCallback(...)], ) trainer.fresume = resume trainer._checkpoint_connector = CheckpointlessCompatibleConnector(trainer) trainer.wrapper = caller
wait_rank: すべてのランクは、HyperpodTrainingOperator インフラストラクチャからのランク情報を待機します。HPWrapper: 再実行可能コードブロック (RCB) の再起動機能を有効にする Python 関数ラッパー。デコレータは実行時にモニタリングする RCBs の数を判断できないため、実装では Python デコレータではなくコンテキストマネージャーを使用します。CudaHealthCheck: GPU と同期することで、現在のプロセスの CUDA コンテキストが正常な状態であることを確認します。LOCAL_RANK 環境変数で指定されたデバイスを使用するか、LOCAL_RANK が設定されていない場合は、デフォルトでメインスレッドの CUDA デバイスになります。HPAgentK8sAPIFactory: この API により、チェックポイントレストレーニングは Kubernetes トレーニングクラスター内の他のポッドのトレーニングステータスをクエリできます。また、続行する前にすべてのランクが正常に中止および再起動操作を完了するインフラストラクチャレベルの障壁も提供します。CheckpointManager: インメモリチェックポイントと、チェックポイントレス耐障害性のためのpeer-to-peerリカバリを管理します。これには、次の主要な責任があります。メモリ内チェックポイント管理: NeMo モデルチェックポイントをメモリに保存して管理し、チェックポイントレスリカバリシナリオ中にディスク I/O なしで高速リカバリを行います。
Recovery Feasibility Validation: グローバルステップの整合性、ランクの正常性、モデル状態の整合性を検証することで、チェックポイントレスリカバリが可能かどうかを判断します。
Peer-to-Peerリカバリオーケストレーション: 高速リカバリのための分散通信を使用して、正常なランクと失敗したランク間のチェックポイント転送を調整します。
RNG 状態管理: 決定論的復旧のために、Python、NumPy、PyTorch、Megatron 全体で乱数ジェネレーターの状態を保存および復元します。
[オプション] チェックポイントオフロード: GPU に十分なメモリ容量がない場合、メモリチェックポイントの CPU へのオフロード。
PEFTCheckpointManager: PEFT 微調整の基本モデルの重みを維持することCheckpointManagerで拡張されます。CheckpointlessAbortManager: エラーが発生したときにバックグラウンドスレッドで中止オペレーションを管理します。デフォルトでは、TransformerEngine、Checkpointing、TorchDistributed、DataLoader は中止されます。ユーザーは、必要に応じてカスタム中止ハンドラーを登録できます。中止が完了すると、リソースリークを防ぐために、すべての通信を停止し、すべてのプロセスとスレッドを終了する必要があります。CheckpointlessFinalizeCleanup: バックグラウンドスレッドで安全に中止またはクリーンアップできないコンポーネントのメインスレッドで最終的なクリーンアップ操作を処理します。CheckpointlessMegatronStrategy: これは Nemo のMegatronStrategyから継承されます。チェックポイントレストレーニングではnum_distributed_optimizer_instances、オプティマイザレプリケーションが行われるように 2 以上が必要です。この戦略では、ルートレスなど、重要な属性登録とプロセスグループの初期化も処理されます。CheckpointlessCallback: NeMo トレーニングをチェックポイントレストレーニングの耐障害性システムと統合する Lightning コールバック。これには、次の主要な責任があります。トレーニングステップライフサイクル管理: トレーニングの進行状況を追跡し、ParameterUpdateLock と調整して、トレーニング状態 (最初のステップとその後のステップ) に基づいてチェックポイントレスリカバリを有効または無効にします。
Checkpoint State Coordination: インメモリ PEFT ベースモデルチェックポイントの保存/復元を管理します。
CheckpointlessCompatibleConnector: チェックポイントファイルをメモリに事前ロードCheckpointConnectorしようとする PTL。ソースパスはこの優先度で決定されます。チェックポイントレスリカバリを試す
チェックポイントレスが None を返す場合は、parent.resume_start() にフォールバックします。
コードにチェックポイントレストレーニング機能を追加するには、例
概念
このセクションでは、チェックポイントレストレーニングの概念について説明します。Amazon SageMaker HyperPod でのチェックポイントレストレーニングは、処理中の復旧をサポートします。この API インターフェイスは、NVRx APIsと同様の形式に従います。
概念 - 再実行可能なコードブロック (RCB)
失敗しても正常なプロセスは存続しますが、トレーニング状態と Python スタックを回復するには、コードの一部を再実行する必要があります。再実行コードブロック (RCB) は、障害復旧中に再実行される特定のコードセグメントです。次の例では、RCB はトレーニングスクリプト全体 (main() の下のすべて) を包含しています。つまり、各障害復旧はインメモリモデルとオプティマイザの状態を維持しながらトレーニングスクリプトを再起動します。
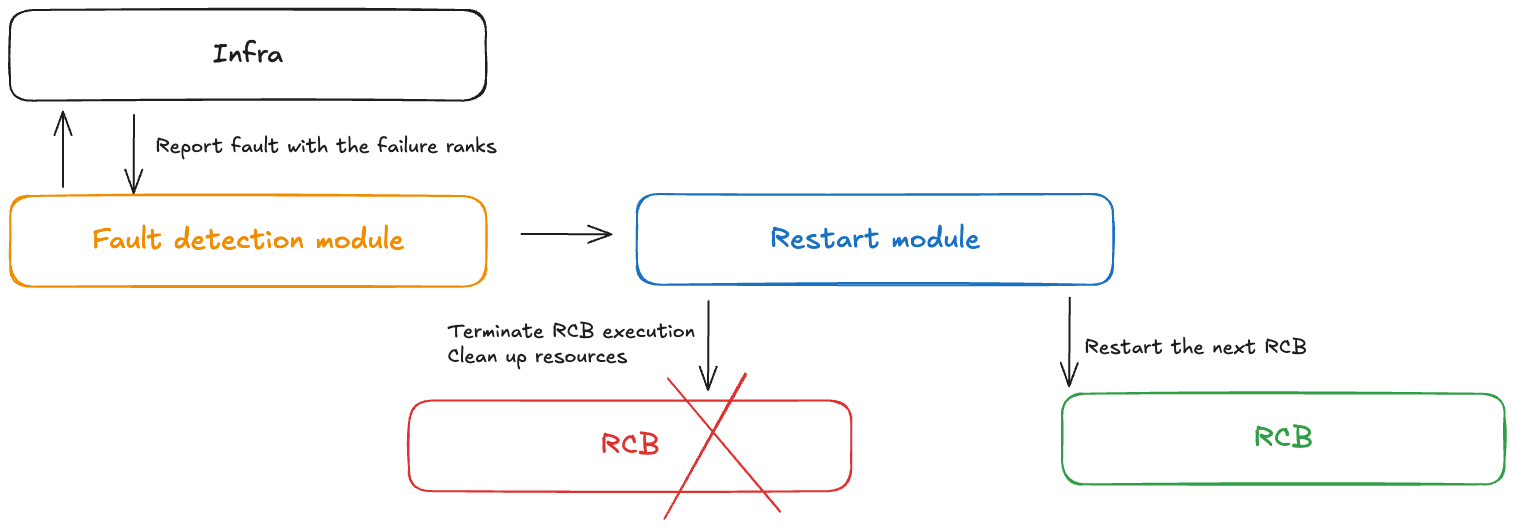
概念 - 障害コントロール
チェックポイントレストレーニング中に障害が発生した場合、障害コントローラーモジュールは通知を受け取ります。この障害コントローラーには、次のコンポーネントが含まれています。
障害検出モジュール: インフラストラクチャの障害通知を受信します
RCB 定義 APIs: ユーザーがコード内の再実行可能コードブロック (RCB) を定義できるようにします
モジュールを再起動する: RCB を終了し、リソースをクリーンアップして、RCB を再起動します
概念 - モデルの冗長性
通常、大規模なモデルトレーニングには、モデルを効率的にトレーニングするための十分なデータ並列サイズが必要です。PyTorch DDP や Horovod などの従来のデータ並列処理では、モデルは完全にレプリケートされます。DeepSpeed ZeRO オプティマイザや FSDP などのより高度なシャーディングデータ並列処理手法は、ハイブリッドシャーディングモードもサポートしています。これにより、シャーディンググループ内のモデル/オプティマイザの状態をシャーディングし、レプリケーショングループ間で完全にレプリケートできます。NeMo には、冗長性を可能にする引数 num_distributed_optimizer_instances によるこのハイブリッドシャーディング機能もあります。
ただし、冗長性を追加すると、モデルがクラスター全体で完全にシャーディングされないため、デバイスのメモリ使用量が増えます。冗長メモリの量は、ユーザーが実装した特定のモデルシャーディング手法によって異なります。精度の低いモデルの重み、勾配、およびアクティベーションメモリは、モデル並列処理によってシャーディングされるため、影響を受けません。高精度のマスターモデルの重み/勾配とオプティマイザの状態に影響します。冗長モデルレプリカを 1 つ追加すると、デバイスのメモリ使用量が 1 つの DCP チェックポイントサイズとほぼ同等に増加します。
ハイブリッドシャーディングは、DP グループ全体の集合体を比較的小さな集合体に分割します。以前は、DP グループ全体に縮小散布と全集計がありました。ハイブリッドシャーディングの後、削減散布は各モデルレプリカ内でのみ実行され、モデルレプリカグループ全体ですべて削減されます。全集合は、各モデルレプリカ内でも実行されます。その結果、通信ボリューム全体はほぼ変更されませんが、集合体はより小さなグループで実行されているため、レイテンシーは向上することが予想されます。
概念 - 失敗と再起動のタイプ
次の表は、さまざまな障害タイプと関連する復旧メカニズムを示しています。チェックポイントレストレーニングは、最初にプロセス内の復旧を介して障害復旧を試み、その後にプロセスレベルの再起動を試みます。致命的な障害が発生した場合 (複数のノードが同時に失敗した場合など) にのみ、ジョブレベルの再起動にフォールバックします。
| 失敗タイプ | 原因 | 復旧タイプ | 復旧メカニズム |
|---|---|---|---|
| 処理中の障害 | コードレベルのエラー、例外 | プロセス内リカバリ (IPR) | 既存のプロセス内で RCB を再実行します。正常なプロセスはアクティブのままです |
| プロセス再起動の失敗 | CUDA コンテキストの破損、プロセスの終了 | プロセスレベルの再起動 (PLR) | SageMaker HyperPod トレーニングオペレーターがプロセスを再起動し、K8s ポッドの再起動をスキップする |
| ノード置換の失敗 | 永続的ノード/GPU ハードウェア障害 | ジョブレベルの再起動 (JLR) | 失敗したノードを置き換え、トレーニングジョブ全体を再起動する |
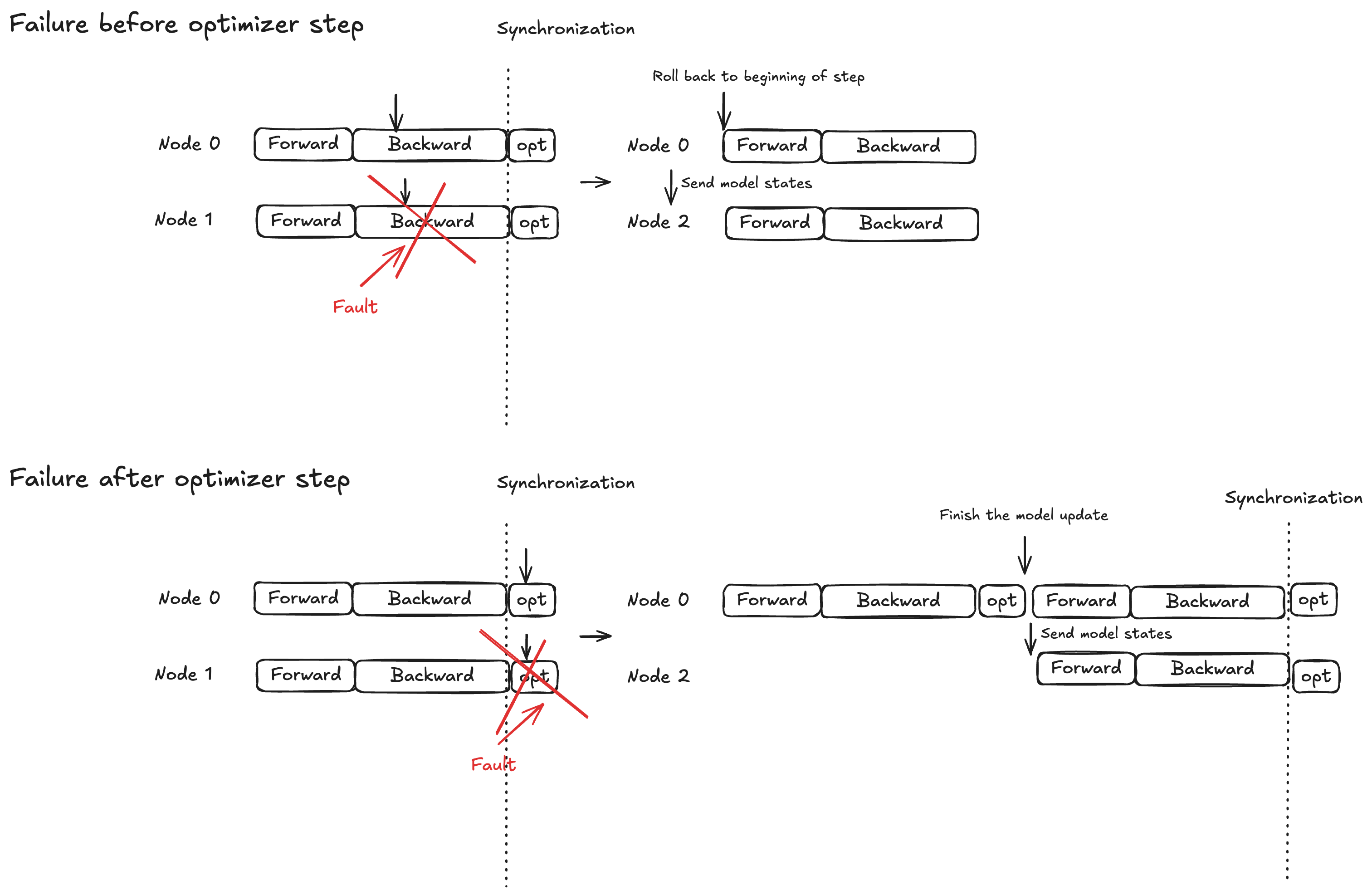
概念 - オプティマイザステップのアトミックロック保護
モデルの実行は、フォワードプロパゲーション、バックワードプロパゲーション、オプティマイザの 3 つのフェーズに分かれています。復旧動作は、障害のタイミングによって異なります。
フォワード/バックワード伝達: 現在のトレーニングステップの先頭にロールバックし、モデルの状態を代替ノード (複数可) にブロードキャストします。
オプティマイザステップ: 正常なレプリカがロック保護の下でステップを完了し、更新されたモデルの状態を代替ノード (複数可) にブロードキャストできるようにします。
この戦略により、完了したオプティマイザの更新が破棄されることがなくなり、障害復旧時間を短縮できます。
チェックポイントレストレーニングフロー図
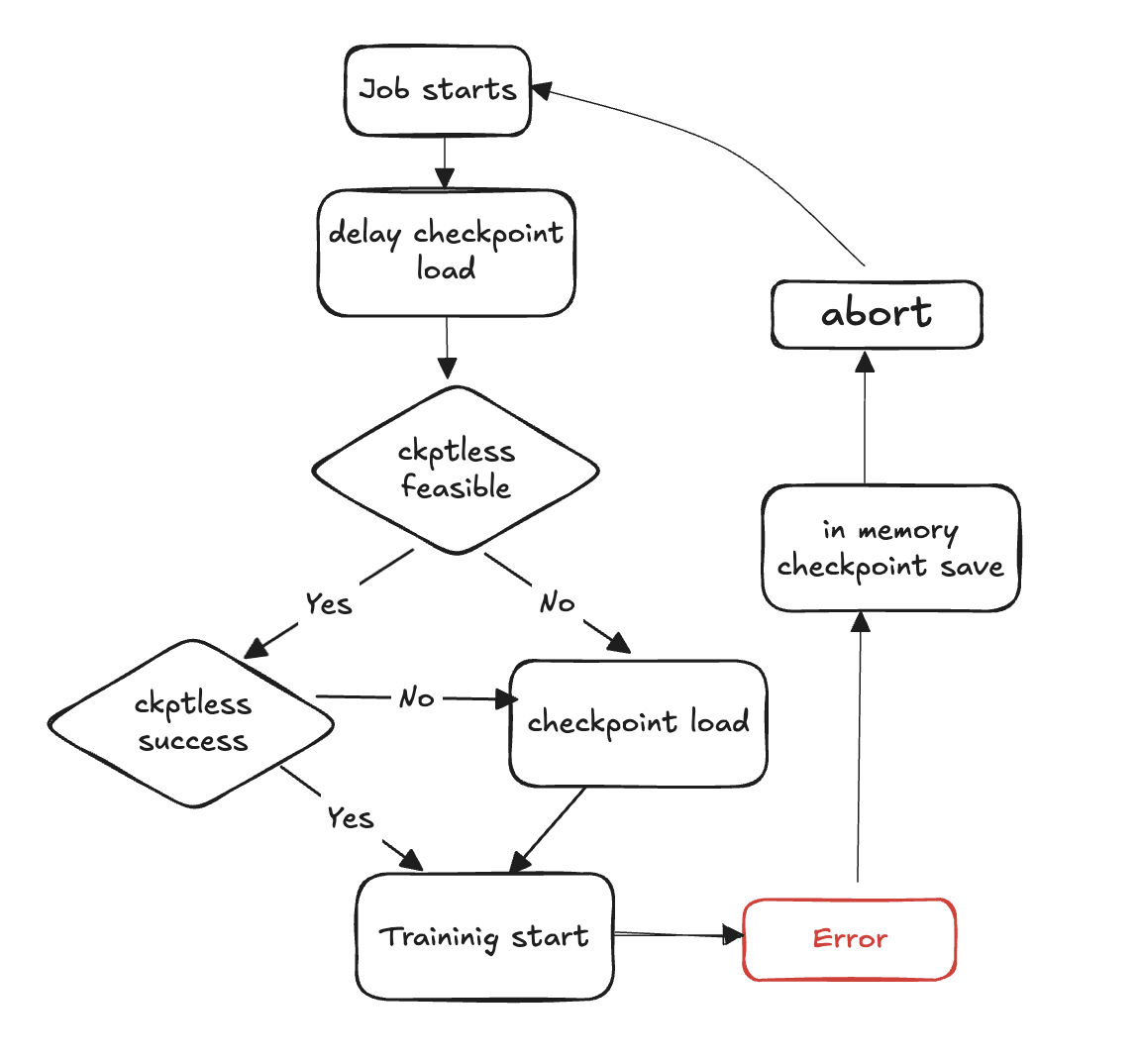
次の手順では、障害検出とチェックポイントレスリカバリプロセスの概要を示します。
トレーニングループの開始
障害が発生する
チェックポイントレス再開の実現可能性を評価する
チェックポイントレス再開が可能かどうかを確認する
可能であれば、チェックポイントレス再利用を試みる
再開が失敗した場合、ストレージからのチェックポイントロードにフォールバックする
再開が成功した場合、トレーニングは復旧状態から続行されます
実行可能でない場合は、ストレージからのチェックポイントロードにフォールバックする
リソースのクリーンアップ - 再起動に備えて、すべてのプロセスグループとバックエンドを中止し、リソースを解放します。
トレーニングループを再開する - 新しいトレーニングループが開始され、プロセスはステップ 1 に戻ります。
API リファレンス
wait_rank
hyperpod_checkpointless_training.inprocess.train_utils.wait_rank()
HyperPod からランク情報を待機して取得し、分散トレーニング変数を使用して現在のプロセス環境を更新します。
この関数は、分散トレーニング用の正しいランク割り当てと環境変数を取得します。これにより、各プロセスが分散トレーニングジョブのロールに適した設定を確実に取得できます。
パラメータ
なし
戻り値
[なし]
Behavior
プロセスチェック: サブプロセスから呼び出された場合に実行をスキップします ( MainProcess でのみ実行されます)
環境の取得: 環境変数
WORLD_SIZEから現在のRANKと を取得します。HyperPod 通信: HyperPod からランク情報を取得
hyperpod_wait_rank_info()するための呼び出し環境の更新: HyperPod から受信したワーカー固有の環境変数を使用して、現在のプロセス環境を更新します。
環境変数
関数は、次の環境変数を読み取ります。
RANK (int) – 現在のプロセスランク (デフォルト: 設定されていない場合は -1)
WORLD_SIZE (int) – 分散ジョブ内のプロセスの合計数 (デフォルト: 設定されていない場合は 0)
レイズ
AssertionError – HyperPod からのレスポンスが想定どおりにない場合、または必須フィールドがない場合
例
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank # Call before initializing distributed training wait_rank() # Now environment variables are properly set for this rank import torch.distributed as dist dist.init_process_group(backend='nccl')
Notes (メモ)
メインプロセスでのみ実行されます。サブプロセス呼び出しは自動的にスキップされます
HyperPod がランク情報を提供するまで、関数はブロックします
HPWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPWrapper( *, abort=Compose(HPAbortTorchDistributed()), finalize=None, health_check=None, hp_api_factory=None, abort_timeout=None, enabled=True, trace_file_path=None, async_raise_before_abort=True, early_abort_communicator=False, checkpoint_manager=None, check_memory_status=True)
HyperPod チェックポイントレストレーニングで再実行可能コードブロック (RCB) の再起動機能を有効にする Python 関数ラッパー。
このラッパーは、トレーニングの実行をモニタリングし、障害が発生したときに分散プロセス全体の再起動を調整することで、耐障害性と自動復旧機能を提供します。デコレータではなくコンテキストマネージャーアプローチを使用して、トレーニングライフサイクルを通じてグローバルリソースを維持します。
パラメータ
abort (中止、オプション) – 障害が検出されると、実行を非同期的に中止します。デフォルト:
Compose(HPAbortTorchDistributed())finalize (Finalize、オプション) – 再起動時に実行されるランクローカルの finalize ハンドラー。デフォルト:
Nonehealth_check (HealthCheck、オプション) – 再起動時に実行されるランクローカルヘルスチェック。デフォルト:
Nonehp_api_factory (呼び出し可能、オプション) – HyperPod とやり取りするための HyperPod API を作成するためのファクトリー関数。デフォルト:
Noneabort_timeout (浮動小数点、オプション) – 障害制御スレッドでの中止呼び出しのタイムアウト。デフォルト:
Noneenabled (bool、オプション) – ラッパー機能を有効にします。の場合
False、ラッパーはパススルーになります。デフォルト:Truetrace_file_path (str、オプション) – VizTracer プロファイリングのトレースファイルへのパス。デフォルト:
Noneasync_raise_before_abort (bool、オプション) — 障害制御スレッドで中止する前にレイズを有効にします。デフォルト:
Trueearly_abort_communicator (bool、オプション) – データローダーを中止する前にコミュニケーター (NCCL/Gloo) を中止します。デフォルト:
Falsecheckpoint_manager (任意、オプション) – 復旧中にチェックポイントを処理するマネージャー。デフォルト:
Nonecheck_memory_status (bool、オプション) – メモリステータスのチェックとログ記録を有効にします。デフォルト:
True
方法
def __call__(self, fn)
関数をラップして再起動機能を有効にします。
パラメータ :
fn (呼び出し可能) – 再起動機能でラップする関数
戻り値:
呼び出し可能 – 再起動機能を備えたラップされた関数、または無効になっている場合は元の関数
例
from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager from hyperpod_checkpointless_training.nemo_plugins.patches import patch_megatron_optimizer from hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector import CheckpointlessCompatibleConnector from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=CheckpointManager(enable_offload=False), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), )def training_function(): # Your training code here pass
Notes (メモ)
ラッパーを使用可能に
torch.distributedする必要がありますの場合
enabled=False、ラッパーはパススルーになり、元の関数は変更されずに返されます。ラッパーは、トレーニングライフサイクルを通じてスレッドのモニタリングなどのグローバルリソースを維持します。
trace_file_pathが提供されているときに VizTracer プロファイリングをサポートHyperPod と統合して、分散トレーニング全体で障害処理を調整
HPCallWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPCallWrapper(wrapper)
実行中にコードブロックの再起動 (RCB) の状態を監視および管理します。
このクラスは、障害検出、再起動のための他のランクとの調整、クリーンアップオペレーションなど、RCB 実行のライフサイクルを処理します。分散同期を管理し、すべてのトレーニングプロセスにわたって一貫した復旧を確保します。
パラメータ
ラッパー (HPWrapper) – グローバルプロセス内復旧設定を含む親ラッパー
属性
step_upon_restart (int) – 前回の再起動以降のステップを追跡するカウンター。再起動戦略の決定に使用されます。
方法
def initialize_barrier()
RCB からの例外が発生した後、HyperPod 障壁の同期を待ちます。
def start_hp_fault_handling_thread()
障害のモニタリングと調整のために障害処理スレッドを開始します。
def handle_fn_exception(call_ex)
実行関数または RCB からの例外を処理します。
パラメータ :
call_ex (例外) – モニタリング関数からの例外
def restart(term_ex)
確定、ガベージコレクション、ヘルスチェックなどの再起動ハンドラーを実行します。
パラメータ :
term_ex (RankShouldRestart) — 再起動をトリガーする終了例外
def launch(fn, *a, **kw)
適切な例外処理を使用して RCB を実行します。
パラメータ :
fn (呼び出し可能) – 実行する関数
a – 関数引数
kw – 関数キーワード引数
def run(fn, a, kw)
再起動と障壁の同期を処理するメイン実行ループ。
パラメータ :
fn (呼び出し可能) – 実行する関数
a – 関数引数
kw – 関数キーワード引数
def shutdown()
障害処理とモニタリングスレッドをシャットダウンします。
Notes (メモ)
調整された復旧の
RankShouldRestart例外を自動的に処理するメモリの追跡と中止、再起動中のガベージコレクションを管理します
障害のタイミングに基づいて、プロセス内の復旧戦略と PLR (プロセスレベルの再起動) 戦略の両方をサポートします。
CudaHealthCheck
class hyperpod_checkpointless_training.inprocess.health_check.CudaHealthCheck(timeout=datetime.timedelta(seconds=30))
チェックポイントレストレーニングの復旧中に、現在のプロセスの CUDA コンテキストが正常な状態であることを確認します。
このヘルスチェックは GPU と同期して、トレーニングの失敗後に CUDA コンテキストが破損していないことを確認します。GPU 同期オペレーションを実行して、トレーニングの再開が成功しない可能性のある問題を検出します。ヘルスチェックは、分散グループが破棄され、確定が完了した後に実行されます。
パラメータ
timeout (datetime.timedelta、オプション) – GPU 同期オペレーションのタイムアウト期間。デフォルト:
datetime.timedelta(seconds=30)
方法
__call__(state, train_ex=None)
CUDA ヘルスチェックを実行して GPU コンテキストの整合性を検証します。
パラメータ :
状態 (HPState) — ランクと分散情報を含む現在の HyperPod 状態
train_ex (例外、オプション) – 再起動をトリガーした元のトレーニング例外。デフォルト:
None
戻り値:
タプル – ヘルスチェックに合格した場合に
(state, train_ex)変更されない を含むタプル
レイズ:
TimeoutError – GPU 同期がタイムアウトし、破損した可能性のある CUDA コンテキストを示す場合
状態の保存: すべてのチェックに合格した場合、元の状態と例外は変更されません
例
import datetime from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # Create CUDA health check with custom timeout cuda_health_check = CudaHealthCheck( timeout=datetime.timedelta(seconds=60) ) # Use with HPWrapper for fault-tolerant training @HPWrapper( health_check=cuda_health_check, enabled=True ) def training_function(): # Your training code here pass
Notes (メモ)
スレッディングを使用して GPU 同期のタイムアウト保護を実装
トレーニングの再開が成功しない可能性のある破損した CUDA コンテキストを検出するように設計されています。
分散トレーニングシナリオで耐障害性パイプラインの一部として使用する必要があります
HPAgentK8sAPIFactory
class hyperpod_checkpointless_training.inprocess.train_utils.HPAgentK8sAPIFactory()
HyperPod インフラストラクチャと通信して分散トレーニングを調整する HPAgentK8sAPI インスタンスを作成するためのファクトリークラス。
このファクトリーは、トレーニングプロセスと HyperPod コントロールプレーン間の通信を処理する HPAgentK8sAPI オブジェクトを作成および設定するための標準化された方法を提供します。基盤となるソケットクライアントと API インスタンスの作成をカプセル化し、トレーニングシステムのさまざまな部分で一貫した設定を確保します。
方法
__call__()
HyperPod 通信用に設定された HPAgentK8sAPI インスタンスを作成して返します。
戻り値:
HPAgentK8sAPI – HyperPod インフラストラクチャと通信するように設定された API インスタンス
例
from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck # Create the factory hp_api_factory = HPAgentK8sAPIFactory() # Use with HPWrapper for fault-tolerant training hp_wrapper = HPWrapper( hp_api_factory=hp_api_factory, health_check=CudaHealthCheck(), abort_timeout=60.0, enabled=True ) @hp_wrapper def training_function(): # Your distributed training code here pass
Notes (メモ)
HyperPod の Kubernetes ベースのインフラストラクチャとシームレスに連携するように設計されています。分散トレーニングシナリオの調整された障害処理と復旧に不可欠です
CheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.CheckpointManager( enable_checksum=False, enable_offload=False)
分散トレーニングにおけるチェックポイントレス耐障害性のためのインメモリチェックポイントとpeer-to-peerリカバリを管理します。
このクラスは、メモリ内の NeMo モデルチェックポイントを管理し、復旧の実現可能性を検証し、正常なランクと失敗したランク間のpeer-to-peerチェックポイント転送を調整することで、HyperPod チェックポイントレストレーニングのコア機能を提供します。これにより、復旧中のディスク I/O が不要になり、平均復旧時間 (MTTR) が大幅に短縮されます。
パラメータ
enable_checksum (bool、オプション) – 復旧中の整合性チェックのモデル状態チェックサム検証を有効にします。デフォルト:
Falseenable_offload (bool、オプション) – GPU から CPU メモリへのチェックポイントオフロードを有効にして、GPU メモリの使用量を減らします。デフォルト:
False
属性
global_step (int または None) – 保存されたチェックポイントに関連付けられた現在のトレーニングステップ
rng_states (リストまたはなし) – 決定論的復旧のために保存された乱数ジェネレーターの状態
checksum_manager (MemoryChecksumManager) – モデル状態チェックサム検証用のマネージャー
parameter_update_lock (ParameterUpdateLock) – 復旧中のパラメータ更新を調整するためのロック
方法
save_checkpoint(trainer)
NeMo モデルチェックポイントをメモリに保存して、チェックポイントレスリカバリの可能性に備えます。
パラメータ :
トレーナー (pytorch_lightning.Trainer) – PyTorch Lightning トレーナーインスタンス
注意:
バッチ終了時または例外処理中に CheckpointlessCallback によって呼び出されます
ディスク I/O オーバーヘッドなしで復旧ポイントを作成します
完全なモデル、オプティマイザ、スケジューラの状態を保存します
delete_checkpoint()
インメモリチェックポイントを削除し、クリーンアップオペレーションを実行します。
注意:
チェックポイントデータ、RNG 状態、キャッシュされたテンソルをクリアします
ガベージコレクションと CUDA キャッシュのクリーンアップを実行します
復旧が成功した後、またはチェックポイントが不要になったときに呼び出されます
try_checkpointless_load(trainer)
ピアランクから状態をロードしてチェックポイントレスリカバリを試行します。
パラメータ :
トレーナー (pytorch_lightning.Trainer) — PyTorch Lightning トレーナーインスタンス
戻り値:
dict または None – 成功した場合は復元されたチェックポイント、ディスクへのフォールバックが必要な場合はなし
注意:
チェックポイントレスリカバリの主なエントリポイント
P2P 転送を試みる前に復旧の実現可能性を検証します
復旧の試行後に常にインメモリチェックポイントをクリーンアップする
checkpointless_recovery_feasible(trainer, include_checksum_verification=True)
現在の障害シナリオでチェックポイントレスリカバリが可能かどうかを確認します。
パラメータ :
トレーナー (pytorch_lightning.Trainer) — PyTorch Lightning トレーナーインスタンス
include_checksum_verification (bool、オプション) – チェックサム検証を含めるかどうか。デフォルト:
True
戻り値:
bool – チェックポイントレスリカバリが可能であれば true、それ以外の場合は False
検証基準:
正常なランク間のグローバルステップの一貫性
復旧に使用できる十分な正常なレプリカ
モデル状態のチェックサムの整合性 (有効になっている場合)
store_rng_states()
決定論的復旧のために、すべての乱数ジェネレーターの状態を保存します。
注意:
Python、NumPy、PyTorch CPU/GPU、Megatron RNG の状態をキャプチャします
復旧後にトレーニング決定論を維持するのに不可欠
load_rng_states()
確定的な復旧を継続するために、すべての RNG 状態を復元します。
注意:
以前に保存したすべての RNG 状態を復元します
トレーニングが同一のランダムシーケンスで継続されるようにします
maybe_offload_checkpoint()
オフロードが有効になっている場合、チェックポイントを GPU から CPU メモリにオフロードします。
注意:
大規模モデルの GPU メモリ使用量を削減
次の場合にのみ実行されます。
enable_offload=True復旧のためのチェックポイントアクセシビリティを維持します
例
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=CheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
検証: チェックサムを使用してチェックポイントの整合性を検証します (有効になっている場合)
Notes (メモ)
分散通信プリミティブを使用して効率的な P2P 転送を実現
テンソルの dtype 変換とデバイスの配置を自動的に処理する
MemoryChecksumManager – モデル状態の整合性検証を処理します
PEFTCheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.PEFTCheckpointManager( *args, **kwargs)
チェックポイントレスリカバリを最適化するために、個別のベース処理とアダプター処理を使用して PEFT (パラメータ効率ファインチューニング) のチェックポイントを管理します。
この特殊なチェックポイントマネージャーは、CheckpointManager を拡張して、ベースモデルの重みをアダプターパラメータから分離することで PEFT ワークフローを最適化します。
パラメータ
CheckpointManager からすべてのパラメータを継承します。
enable_checksum (bool、オプション) – モデル状態チェックサムの検証を有効にします。デフォルト:
Falseenable_offload (bool、オプション) — CPU メモリへのチェックポイントオフロードを有効にします。デフォルト:
False
追加の属性
params_to_save (セット) – アダプターパラメータとして保存する必要があるパラメータ名のセット
base_model_weights (dict または None) – キャッシュされたベースモデルの重み、一度保存して再利用
base_model_keys_to_extract (リストまたはなし) – P2P 転送中にベースモデルテンソルを抽出するためのキー
方法
maybe_save_base_model(trainer)
ベースモデルの重みを 1 回保存し、アダプターパラメータを除外します。
パラメータ :
トレーナー (pytorch_lightning.Trainer) – PyTorch Lightning トレーナーインスタンス
注意:
最初の呼び出し時にのみベースモデルの重みを保存します。後続の呼び出しは no-ops です。
アダプターパラメータをフィルタリングして、フリーズしたベースモデルの重みのみを保存します
基本モデルの重みは複数のトレーニングセッションにわたって保持されます
save_checkpoint(trainer)
NeMo PEFT アダプターモデルのチェックポイントをメモリに保存して、チェックポイントレスリカバリの可能性に備えます。
パラメータ :
トレーナー (pytorch_lightning.Trainer) — PyTorch Lightning トレーナーインスタンス
注意:
ベースモデルがまだ保存されていない場合
maybe_save_base_model()に を自動的に呼び出すアダプターパラメータとトレーニング状態のみを含めるようにチェックポイントをフィルタリングします
完全なモデルチェックポイントと比較してチェックポイントサイズを大幅に削減
try_base_model_checkpointless_load(trainer)
ピアランクから状態をロードして、PEFT ベースモデルの重み付けチェックポイントレスリカバリを試みます。
パラメータ :
トレーナー (pytorch_lightning.Trainer) — PyTorch Lightning トレーナーインスタンス
戻り値:
dict または None – 成功した場合はベースモデルチェックポイントを復元し、フォールバックが必要な場合はなし
注意:
基本モデルの重みを回復するためにモデルの初期化中に使用される
復旧後にベースモデルの重みをクリーンアップしない (再利用のために保存)
model-weights-only復旧シナリオ向けに最適化
try_checkpointless_load(trainer)
PEFT アダプターを試行すると、ピアランクから状態をロードしてチェックポイントレスリカバリが重み付けされます。
パラメータ :
トレーナー (pytorch_lightning.Trainer) — PyTorch Lightning トレーナーインスタンス
戻り値:
dict または None – 成功した場合はアダプターチェックポイントを復元し、フォールバックが必要な場合はなし
注意:
アダプターパラメータ、オプティマイザの状態、スケジューラのみを復旧します
復旧が成功すると、オプティマイザとスケジューラの状態を自動的にロードします
復旧の試行後にアダプターチェックポイントをクリーンアップします
is_adapter_key(key)
状態ディクトキーがアダプターパラメータに属しているかどうかを確認します。
パラメータ :
key (str またはタプル) — チェックするステートディクトキー
戻り値:
bool – key がアダプターパラメータの場合は true、base model パラメータの場合は False
検出ロジック:
キーが設定されているかどうかを確認します
params_to_save".adapter" を含むキーを識別します。substring
「.adapters」で終わるキーを識別します
タプルキーの場合、 パラメータにグラデーションが必要かどうかを確認します
maybe_offload_checkpoint()
ベースモデルの重みを GPU から CPU メモリにオフロードします。
注意:
親メソッドを拡張してベースモデルのウェイトオフロードを処理します
アダプターの重みは通常小さく、オフロードは必要ありません
オフロード状態を追跡する内部フラグを設定します
Notes (メモ)
パラメータ効率の高いファインチューニングシナリオ (LoRA、アダプターなど) 向けに特別に設計
ベースモデルとアダプターパラメータの分離を自動的に処理する
例
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import PEFTCheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=PEFTCheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
CheckpointlessAbortManager
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessAbortManager()
チェックポイントレス耐障害性のための中止コンポーネント構成を作成および管理するためのファクトリークラス。
このユーティリティクラスは、HyperPod チェックポイントレストレーニングの障害処理中に使用される中止コンポーネントコンポジションを作成、カスタマイズ、管理する静的メソッドを提供します。これにより、障害復旧中の分散トレーニングコンポーネント、データローダー、フレームワーク固有のリソースのクリーンアップを処理する中止シーケンスの設定が簡素化されます。
パラメータ
なし (すべてのメソッドは静的)
静的メソッド
get_default_checkpointless_abort()
すべての標準中止コンポーネントを含むデフォルトの中止構成インスタンスを取得します。
戻り値:
Compose – すべての中止コンポーネントを含むデフォルトの構成中止インスタンス
デフォルトのコンポーネント:
AbortTransformerEngine() – TransformerEngine リソースをクリーンアップします
HPCheckpointingAbort() – チェックポイントシステムのクリーンアップを処理します
HPAbortTorchDistributed() – PyTorch 分散オペレーションを中止
HPDataLoaderAbort() – データローダーを停止してクリーンアップします
create_custom_abort(abort_instances)
指定された中止インスタンスのみを使用してカスタム中止構成を作成します。
パラメータ :
abort_instances (中止) – 構成に含める中止インスタンスの可変数
戻り値:
Compose – 指定されたコンポーネントのみを含む新しい構成中止インスタンス
レイズ:
ValueError – 中止インスタンスが指定されていない場合
override_abort(abort_compose, abort_type, new_abort)
Compose インスタンス内の特定の中止コンポーネントを新しいコンポーネントに置き換えます。
パラメータ :
abort_compose (Compose) – 変更する元の Compose インスタンス
abort_type (タイプ) – 置き換える中止コンポーネントのタイプ (例:
HPCheckpointingAbort)new_abort (中止) – 置き換えとして使用する新しい中止インスタンス
戻り値:
Compose – 指定されたコンポーネントが置き換えられた新しい Compose インスタンス
レイズ:
ValueError – abort_compose に「インスタンス」属性がない場合
例
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager # The strategy automatically integrates with HPWrapper @HPWrapper( abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), health_check=CudaHealthCheck(), finalize=CheckpointlessFinalizeCleanup(), enabled=True ) def training_function(): trainer.fit(...)
Notes (メモ)
カスタム設定により、クリーンアップ動作を微調整できます。
障害復旧中の適切なリソースクリーンアップには、オペレーションの中止が不可欠です
CheckpointlessFinalizeCleanup
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessFinalizeCleanup()
障害検出後に包括的なクリーンアップを実行し、チェックポイントレストレーニング中の処理中の復旧に備えます。
このファイナライズハンドラーは、トレーニングコンポーネントの参照を破棄することで、Megatron/TransformerEngine の中止、DDP クリーンアップ、モジュールの再ロード、メモリクリーンアップなどのフレームワーク固有のクリーンアップオペレーションを実行します。これにより、完全なプロセス終了を必要とせずに、トレーニング環境が適切にリセットされ、プロセス内の復旧が成功します。
パラメータ
なし
属性
トレーナー (pytorch_lightning.Trainer または None) — PyTorch Lightning トレーナーインスタンスへの参照
方法
__call__(*a, **kw)
プロセス内の復旧準備のための包括的なクリーンアップオペレーションを実行します。
パラメータ :
a – 可変位置引数 (Finalize インターフェイスから継承)
kw – 変数キーワード引数 (Finalize インターフェイスから継承)
クリーンアップオペレーション:
Megatron Framework Cleanup – Megatron 固有のリソースをクリーンアップ
abort_megatron()するための呼び出しTransformerEngine クリーンアップ – TransformerEngine リソースをクリーンアップ
abort_te()するための呼び出しRoPE クリーンアップ – 回転位置埋め込みリソースをクリーンアップ
cleanup_rope()するための呼び出しDDP クリーンアップ – DistributedDataParallel リソースをクリーンアップ
cleanup_ddp()するための呼び出しモジュールのリロード — フレームワークモジュールを再ロード
reload_megatron_and_te()するための呼び出しLightning Module Cleanup – オプションで Lightning モジュールをクリアして GPU メモリを削減
メモリクリーンアップ — トレーニングコンポーネントの空きメモリへの参照を破棄します
register_attributes(trainer)
クリーンアップ操作中に使用するトレーナーインスタンスを登録します。
パラメータ :
トレーナー (pytorch_lightning.Trainer) — 登録する PyTorch Lightning トレーナーインスタンス
CheckpointlessCallback との統合
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( ... finalize=CheckpointlessFinalizeCleanup(), ) def training_function(): trainer.fit(...)
Notes (メモ)
クリーンアップオペレーションは、依存関係の問題を回避するために特定の順序で実行されます。
メモリクリーンアップでは、ガベージコレクションのイントロスペクションを使用してターゲットオブジェクトを検索します。
すべてのクリーンアップオペレーションは冪等性があり、安全に再試行できるように設計されています
CheckpointlessMegatronStrategy
class hyperpod_checkpointless_training.nemo_plugins.megatron_strategy.CheckpointlessMegatronStrategy(*args, **kwargs)
NeMo Megatron 戦略は、耐障害性のある分散トレーニングのための統合されたチェックポイントレスリカバリ機能を備えています。
チェックポイントレストレーニングではnum_distributed_optimizer_instances、オプティマイザレプリケーションが行われるように 2 以上が必要です。この戦略では、必須属性の登録とプロセスグループの初期化も行います。
パラメータ
MegatronStrategy からすべてのパラメータを継承します。
標準 NeMo MegatronStrategy 初期化パラメータ
分散トレーニング設定オプション
モデル並列処理の設定
属性
base_store (torch.distributed.TCPStore または None) – プロセスグループ調整用の分散ストア
方法
setup(trainer)
戦略を初期化し、耐障害性コンポーネントをトレーナーに登録します。
パラメータ :
トレーナー (pytorch_lightning.Trainer) – PyTorch Lightning トレーナーインスタンス
セットアップオペレーション:
親セットアップ – 親 MegatronStrategy セットアップを呼び出します
フォールトインジェクション登録 — 存在する場合は HPFaultInjectionCallback フックを登録します
登録の確定 – トレーナーをクリーンアップハンドラーの確定に登録します
登録の中止 – 登録をサポートする中止ハンドラーにトレーナーを登録します
setup_distributed()
プレフィックス付き TCPStore またはルートレス接続を使用してプロセスグループを初期化します。
load_model_state_dict(checkpoint, strict=True)
チェックポイントレスリカバリの互換性があるロードモデルステートディクト。
パラメータ :
チェックポイント (Mapping[str, Any]) – モデル状態を含むチェックポイントディクショナリ
strict (bool、オプション) – ステートディクトキーマッチングを厳密に適用するかどうか。デフォルト:
True
get_wrapper()
耐障害性の調整のために HPCallWrapper インスタンスを取得します。
戻り値:
HPCallWrapper – 耐障害性のためにトレーナーにアタッチされたラッパーインスタンス
is_peft()
PEFT コールバックをチェックして、トレーニング設定で PEFT (パラメータ効率ファインチューニング) が有効になっているかどうかを確認します。
戻り値:
bool – PEFT コールバックが存在する場合は true、それ以外の場合は False
teardown()
PyTorch Lightning ネイティブのティアダウンを上書きして、ハンドラーを中止するクリーンアップを委任します。
例
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( checkpoint_manager=checkpoint_manager, enabled=True ) def training_function(): trainer = pl.Trainer(strategy=CheckpointlessMegatronStrategy()) trainer.fit(model, datamodule)
CheckpointlessCallback
class hyperpod_checkpointless_training.nemo_plugins.callbacks.CheckpointlessCallback( enable_inprocess=False, enable_checkpointless=False, enable_checksum=False, clean_tensor_hook=False, clean_lightning_module=False)
NeMo トレーニングをチェックポイントレストレーニングの耐障害性システムと統合する Lightning コールバック。
このコールバックは、処理中の復旧機能のステップ追跡、チェックポイントの保存、およびパラメータ更新の調整を管理します。PyTorch Lightning トレーニングループと HyperPod チェックポイントレストレーニングメカニズム間の主要な統合ポイントとして機能し、トレーニングライフサイクル全体で耐障害性オペレーションを調整します。
パラメータ
enable_inprocess (bool、オプション) – 処理中の復旧機能を有効にします。デフォルト:
Falseenable_checkpointless (bool、オプション) – チェックポイントレスリカバリを有効にします ( が必要です
enable_inprocess=True)。デフォルト:Falseenable_checksum (bool、オプション) – モデル状態チェックサム検証を有効にします ( が必要です
enable_checkpointless=True)。デフォルト:Falseclean_tensor_hook (bool、オプション) – クリーンアップ (高価なオペレーション) 中にすべての GPU テンソルからテンソルフックをクリアします。デフォルト:
Falseclean_lightning_module (bool、オプション) – 再起動のたびに Lightning モジュールのクリーンアップを有効にして GPU メモリを解放します。デフォルト:
False
属性
tried_adapter_checkpointless (bool) – アダプターチェックポイントレス復元が試行されたかどうかを追跡するフラグ
方法
get_wrapper_from_trainer(trainer)
耐障害性の調整のために、トレーナーから HPCallWrapper インスタンスを取得します。
パラメータ :
トレーナー (pytorch_lightning.Trainer) — PyTorch Lightning トレーナーインスタンス
戻り値:
HPCallWrapper – 耐障害性オペレーション用のラッパーインスタンス
on_train_batch_start(trainer, pl_module, batch, batch_idx, *args, **kwargs)
ステップの追跡と復旧を管理するために、各トレーニングバッチの開始時に呼び出されます。
パラメータ :
トレーナー (pytorch_lightning.Trainer) — PyTorch Lightning トレーナーインスタンス
pl_module (pytorch_lightning.LightningModule) – トレーニング中の稲妻モジュール
batch – 現在のトレーニングバッチデータ
batch_idx (int) – 現在のバッチのインデックス
args – 追加の位置引数
kwargs – 追加のキーワード引数
on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx)
各トレーニングバッチの最後にパラメータ更新ロックを解放します。
パラメータ :
トレーナー (pytorch_lightning.Trainer) – PyTorch Lightning トレーナーインスタンス
pl_module (pytorch_lightning.LightningModule) – トレーニング中の稲妻モジュール
出力 (STEP_OUTPUT) – トレーニングステップ出力
batch (Any) – 現在のトレーニングバッチデータ
batch_idx (int) – 現在のバッチのインデックス
注意:
ロックリリースタイミングにより、パラメータの更新が完了した後にチェックポイントレスリカバリを続行できます。
enable_inprocessと の両方enable_checkpointlessが True の場合にのみ実行されます。
get_peft_callback(trainer)
トレーナーのコールバックリストから PEFT コールバックを取得します。
パラメータ :
トレーナー (pytorch_lightning.Trainer) – PyTorch Lightning トレーナーインスタンス
戻り値:
PEFT または None – 見つかった場合は PEFT コールバックインスタンス、それ以外の場合はなし
_try_adapter_checkpointless_restore(trainer, params_to_save)
PEFT アダプターパラメータのチェックポイントレス復元を試行します。
パラメータ :
トレーナー (pytorch_lightning.Trainer) – PyTorch Lightning トレーナーインスタンス
params_to_save (セット) – アダプターパラメータとして保存するパラメータ名のセット
注意:
トレーニングセッションごとに 1 回のみ実行されます (
tried_adapter_checkpointlessフラグで制御)アダプターパラメータ情報を使用してチェックポイントマネージャーを設定します
例
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager import pytorch_lightning as pl # Create checkpoint manager checkpoint_manager = CheckpointManager( enable_checksum=True, enable_offload=True ) # Create checkpointless callback with full fault tolerance checkpointless_callback = CheckpointlessCallback( enable_inprocess=True, enable_checkpointless=True, enable_checksum=True, clean_tensor_hook=True, clean_lightning_module=True ) # Use with PyTorch Lightning trainer trainer = pl.Trainer( callbacks=[checkpointless_callback], strategy=CheckpointlessMegatronStrategy() ) # Training with fault tolerance trainer.fit(model, datamodule=data_module)
メモリ管理
clean_tensor_hook: クリーンアップ中にテンソルフックを削除します (高価ですが徹底的)
clean_lightning_module: 再起動中に Lightning モジュール GPU メモリを解放します
どちらのオプションも、障害復旧中のメモリフットプリントの削減に役立ちます。
ParameterUpdateLock との調整によるスレッドセーフなパラメータ更新の追跡
CheckpointlessCompatibleConnector
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector.CheckpointlessCompatibleConnector()
チェックポイントレスリカバリを従来のディスクベースのチェックポイントロードと統合する PyTorch Lightning チェックポイントコネクタ。
このコネクタは PyTorch Lightning を拡張_CheckpointConnectorして、チェックポイントレスリカバリと標準チェックポイント復元のシームレスな統合を提供します。最初にチェックポイントレスリカバリを試行し、チェックポイントレスリカバリが実行可能でない場合や失敗した場合、ディスクベースのチェックポイントロードにフォールバックします。
パラメータ
_CheckpointConnector からすべてのパラメータを継承します
方法
resume_start(checkpoint_path=None)
チェックポイントレスリカバリの優先度でチェックポイントをプリロードしようとします。
パラメータ :
checkpoint_path (str または None、オプション) – フォールバック用のディスクチェックポイントへのパス。デフォルト:
None
resume_end()
チェックポイントのロードプロセスを完了し、ロード後のオペレーションを実行します。
Notes (メモ)
チェックポイントレスリカバリのサポートにより PyTorch Lightning の内部
_CheckpointConnectorクラスを拡張標準の PyTorch Lightning チェックポイントワークフローとの完全な互換性を維持します
CheckpointlessAutoResume
class hyperpod_checkpointless_training.nemo_plugins.resume.CheckpointlessAutoResume()
NeMo の AutoResume を遅延セットアップで拡張し、チェックポイントパス解決前のチェックポイントレス復旧検証を有効にします。
このクラスは、従来のディスクベースのチェックポイントロードにフォールバックする前にチェックポイントレスリカバリ検証を実行できるようにする 2 段階の初期化戦略を実装します。条件付きで AutoResume のセットアップを遅らせてチェックポイントパスの早期解決を防止し、CheckpointManagerチェックポイントレスpeer-to-peerリカバリが実行可能かどうかを最初に検証できるようにします。
パラメータ
AutoResume からすべてのパラメータを継承します
方法
setup(trainer, model=None, force_setup=False)
AutoResume のセットアップを条件付きで遅らせて、チェックポイントレスリカバリの検証を有効にします。
パラメータ :
トレーナー (pytorch_lightning.Trainer またはLightning.fabric.Fabric) – PyTorch Lightning トレーナーまたは Fabric インスタンス
model (オプション) – セットアップ用のモデルインスタンス。デフォルト:
Noneforce_setup (bool、オプション) – True の場合、遅延をバイパスして AutoResume セットアップをすぐに実行します。デフォルト:
False
例
from hyperpod_checkpointless_training.nemo_plugins.resume import CheckpointlessAutoResume from hyperpod_checkpointless_training.nemo_plugins.megatron_strategy import CheckpointlessMegatronStrategy import pytorch_lightning as pl # Create trainer with checkpointless auto-resume trainer = pl.Trainer( strategy=CheckpointlessMegatronStrategy(), resume=CheckpointlessAutoResume() )
Notes (メモ)
チェックポイントレスリカバリを有効にする遅延メカニズムを使用して NeMo の AutoResume クラスを拡張
と連動
CheckpointlessCompatibleConnectorして完全な復旧ワークフローを実現
