翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
メモリマッピングされたデータローダー
もう 1 つの再起動オーバーヘッドはデータのロードに起因します。データローダーが初期化し、リモートファイルシステムからデータをダウンロードしてバッチ処理している間、トレーニングクラスターはアイドル状態のままになります。
これに対処するために、Memory Mapped DataLoader (MMAP) Dataloader を導入しました。この Dataloader は、プリフェッチされたバッチを永続メモリにキャッシュし、障害による再起動後も使用できるようにします。このアプローチにより、データローダーのセットアップ時間がなくなり、キャッシュされたバッチを使用してトレーニングをすぐに再開できます。一方、データローダーは後続のデータをバックグラウンドで同時に再初期化してフェッチします。データキャッシュは、トレーニングデータを必要とする各ランクに存在し、2 種類のバッチを維持します。トレーニングに使用された最近消費されたバッチと、すぐに使用できるプリフェッチされたバッチです。
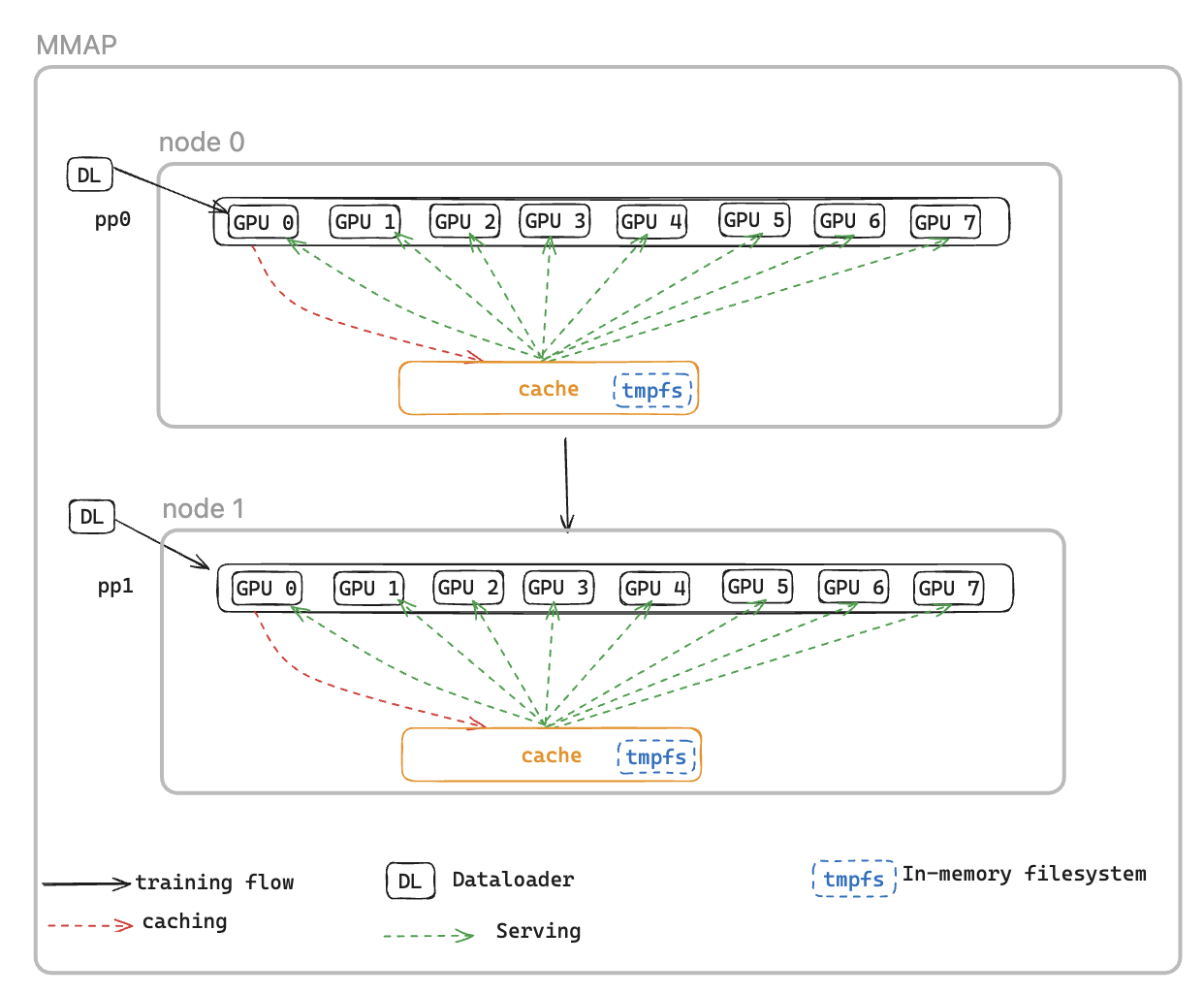
MMAP データローダーには次の 2 つの機能があります。
データプリフェッチ - データローダーによって生成されたデータをプロアクティブにフェッチしてキャッシュします
永続的キャッシュ - プロセスの再起動後も存続する一時的なファイルシステムに、消費されたバッチとプリフェッチされたバッチの両方を保存します。
キャッシュを使用すると、トレーニングジョブは次の利点があります。
メモリフットプリントの削減 - メモリマップ I/O を活用して、ホスト CPU メモリ内のデータの単一の共有コピーを維持し、GPU プロセス間の冗長コピーを排除GPUs (8 GPU を搭載した p5 インスタンスで 8 コピーから 1 コピーに削減するなど)。
Faster Recovery - キャッシュされたバッチからトレーニングをすぐに再開できるようにすることで、平均再起動時間 (MTTR) を短縮し、データローダーの再初期化と最初のバッチ生成の待機をなくします。
MMAP 設定
MMAP を使用するには、元のデータモジュールを に渡します。 MMAPDataModule
data_module=MMAPDataModule( data_module=MY_DATA_MODULE(...), mmap_config=CacheResumeMMAPConfig( cache_dir=self.cfg.mmap.cache_dir, checkpoint_frequency=self.cfg.mmap.checkpoint_frequency), )
CacheResumeMMAPConfig: MMAP Dataloader パラメータは、キャッシュディレクトリの場所、サイズ制限、データフェッチ委任を制御します。デフォルトでは、ノードあたりの TP ランク 0 のみがソースからデータを取得し、同じデータレプリケーショングループ内の他のランクは共有キャッシュから読み取るため、冗長な転送がなくなります。
MMAPDataModule: 元のデータモジュールをラップし、トレーニングと検証の両方のために mmap データローダーを返します。
MMAP を有効にする例を参照してください
API リファレンス
CacheResumeMMAPConfig
class hyperpod_checkpointless_training.dataloader.config.CacheResumeMMAPConfig( cache_dir='/dev/shm/pdl_cache', prefetch_length=10, val_prefetch_length=10, lookback_length=2, checkpoint_frequency=None, model_parallel_group=None, enable_batch_encryption=False)
HyperPod チェックポイントレストレーニングのキャッシュ再開メモリマップ (MMAP) データローダー機能の設定クラス。
この設定により、キャッシュ機能とプリフェッチ機能による効率的なデータロードが可能になり、キャッシュされたデータバッチをメモリマップファイルに維持することで、障害発生後すぐにトレーニングを再開できます。
パラメータ
-
cache_dir (str、オプション) – キャッシュされたデータバッチを保存するためのディレクトリパス。デフォルト: "/dev/shm/pdl_cache"
-
prefetch_length (int、オプション) – トレーニング中にプリフェッチするバッチの数。デフォルト: 10
-
val_prefetch_length (int、オプション) – 検証中にプリフェッチするバッチの数。デフォルト: 10
-
lookback_length (int、オプション) – 再利用の可能性のためにキャッシュに保持する以前に使用したバッチの数。デフォルト: 2
-
checkpoint_frequency (int、オプション) – モデルチェックポイントステップの頻度。キャッシュパフォーマンスの最適化に使用されます。デフォルト: なし
-
model_parallel_group (オブジェクト、オプション) – モデル並列処理のプロセスグループ。None の場合、 は自動的に作成されます。デフォルト: なし
-
enable_batch_encryption (bool、オプション) – キャッシュされたバッチデータの暗号化を有効にするかどうか。デフォルト: False
方法
create(dataloader_init_callable, parallel_state_util, step, is_data_loading_rank, create_model_parallel_group_callable, name='Train', is_val=False, cached_len=0)
設定された MMAP データローダーインスタンスを作成して返します。
パラメータ
-
dataloader_init_callable (呼び出し可能) – 基盤となるデータローダーを初期化する関数
-
parallel_state_util (オブジェクト) – プロセス間で並列状態を管理するためのユーティリティ
-
step (int) – トレーニング中に から再開するデータステップ
-
is_data_loading_rank (Callable) – 現在のランクがデータをロードする必要がある場合に True を返す関数
-
create_model_parallel_group_callable (呼び出し可能) – モデル並列プロセスグループを作成する関数
-
name (str、オプション) – データローダーの名前識別子。デフォルト: 「トレーニング」
-
is_val (bool、オプション) – これが検証データローダーかどうか。デフォルト: False
-
cached_len (int、オプション) – 既存のキャッシュから再開する場合のキャッシュデータの長さ。デフォルト: 0
CacheResumePrefetchedDataLoader または を返します CacheResumeReadDataLoader – 設定された MMAP データローダーインスタンス
ステップパラメータが ValueErrorの場合、 が上がりますNone。
例
from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig # Create configuration config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100, enable_batch_encryption=False ) # Create dataloader dataloader = config.create( dataloader_init_callable=my_dataloader_init, parallel_state_util=parallel_util, step=current_step, is_data_loading_rank=lambda: rank == 0, create_model_parallel_group_callable=create_mp_group, name="TrainingData" )
Notes (メモ)
-
キャッシュディレクトリには十分な容量と高速 I/O パフォーマンス (インメモリストレージの /dev/shm など) が必要です。
-
を設定することで、キャッシュ管理をモデルチェックポイントに合わせることでキャッシュパフォーマンス
checkpoint_frequencyが向上します。 -
検証データローダー (
is_val=True) の場合、ステップは 0 にリセットされ、コールドスタートが強制されます。 -
現在のランクがデータのロードを担当するかどうかに基づいて、さまざまなデータローダー実装が使用されます。
MMAPDataModule
class hyperpod_checkpointless_training.dataloader.mmap_data_module.MMAPDataModule( data_module, mmap_config, parallel_state_util=MegatronParallelStateUtil(), is_data_loading_rank=None)
チェックポイントレストレーニングのためにメモリマップ (MMAP) データロード機能を既存の DataModule に適用する PyTorch Lightning DataModules ラッパー。
このクラスは、既存の PyTorch Lightning DataModule をラップし、MMAP 機能で強化します。これにより、トレーニングの失敗時に効率的なデータキャッシュと高速リカバリが可能になります。チェックポイントレストレーニング機能を追加しながら、元の DataModule インターフェイスとの互換性を維持します。
パラメータ
- data_module (pl.LightningDataModule)
ラップする基盤となる DataModule (LLMDataModule など)
- mmap_config (MMAPConfig)
キャッシュ動作とパラメータを定義する MMAP 設定オブジェクト
parallel_state_util(MegatronParallelStateUtil、オプション)分散プロセス全体で並列状態を管理するためのユーティリティ。デフォルト: MegatronParallelStateUtil()
is_data_loading_rank(呼び出し可能、オプション)現在のランクがデータをロードする必要がある場合に True を返す関数。None の場合、デフォルトで parallel_state_util.is_tp_0 になります。デフォルト: なし
属性
global_step(int)チェックポイントからの再開に使用される現在のグローバルトレーニングステップ
cached_train_dl_len(int)トレーニングデータローダーのキャッシュされた長さ
cached_val_dl_len(int)検証データローダーのキャッシュされた長さ
方法
setup(stage=None)
指定されたトレーニングステージの基盤となるデータモジュールをセットアップします。
stage(str、オプション)トレーニングのステージ ('fit'、'validate'、'test'、または 'predict')。デフォルト: なし
train_dataloader()
MMAP ラッピングを使用してトレーニング DataLoader を作成します。
戻り値: DataLoader – キャッシュ機能とプリフェッチ機能を備えた MMAP ラップトレーニング DataLoader
val_dataloader()
MMAP ラップを使用して検証 DataLoader を作成します。
戻り値: DataLoader – キャッシュ機能を備えた MMAP ラップ検証 DataLoader
test_dataloader()
基盤となるデータモジュールがサポートしている場合は、テスト DataLoader を作成します。
戻り値: DataLoader または None – 基盤となるデータモジュールから DataLoader をテストするか、サポートされていない場合は None
predict_dataloader()
基盤となるデータモジュールがサポートしている場合は、予測 DataLoader を作成します。
戻り値: DataLoader または None – 基盤となるデータモジュールから DataLoader を予測するか、サポートされていない場合は None
load_checkpoint(checkpoint)
チェックポイント情報をロードして、特定のステップからトレーニングを再開します。
- チェックポイント (dict)
'global_step' キーを含むチェックポイントディクショナリ
get_underlying_data_module()
基盤となるラップされたデータモジュールを取得します。
戻り値: pl.LightningDataModule – ラップされた元のデータモジュール
state_dict()
チェックポイント用の MMAP DataModule の状態ディクショナリを取得します。
戻り値: dict – キャッシュされたデータローダーの長さを含むディクショナリ
load_state_dict(state_dict)
状態ディクショナリをロードして MMAP DataModule の状態を復元します。
state_dict(dict)ロードする状態ディクショナリ
プロパティ
data_sampler
基盤となるデータモジュールのデータサンプラーを NeMo フレームワークに公開します。
戻り値: オブジェクトまたはなし – 基盤となるデータモジュールのデータサンプラー
例
from hyperpod_checkpointless_training.dataloader.mmap_data_module import MMAPDataModule from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig from my_project import MyLLMDataModule # Create MMAP configuration mmap_config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100 ) # Create original data module original_data_module = MyLLMDataModule( data_path="/path/to/data", batch_size=32 ) # Wrap with MMAP capabilities mmap_data_module = MMAPDataModule( data_module=original_data_module, mmap_config=mmap_config ) # Use in PyTorch Lightning Trainer trainer = pl.Trainer() trainer.fit(model, data=mmap_data_module) # Resume from checkpoint checkpoint = {"global_step": 1000} mmap_data_module.load_checkpoint(checkpoint)
Notes (メモ)
ラッパーは、__getattr__ を使用して、基盤となるデータモジュールへのほとんどの属性アクセスを委任します。
データロードランクのみが基盤となるデータモジュールを実際に初期化して使用します。他のランクはフェイクデータローダーを使用します。
キャッシュされたデータローダーの長さは、トレーニング再開中のパフォーマンスを最適化するために維持されます
