翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
IAM アクセス管理
以下のセクションでは、Amazon SageMaker Pipelines の AWS Identity and Access Management (IAM) 要件について説明します。これらのアクセス許可の実装例については、「前提条件」を参照してください。
トピック
パイプラインロールのアクセス許可
パイプラインには、パイプラインの作成時に Pipelines に渡される IAM パイプライン実行ロールが必要です。パイプラインの作成に使用する SageMaker AI インスタンスのロールには、パイプライン実行ロールを指定するiam:PassRoleアクセス許可を持つポリシーが必要です。これは、インスタンスがパイプラインの作成と実行に使用するパイプライン実行ロールを Pipelines サービスに渡すためのアクセス許可が必要なためです。IAM ロールの詳細については、「IAM ロール」を参照してください。
パイプラインの実行ロールには、次のアクセス許可が必要です。
-
(デフォルトで使用されるパイプライン実行ロールではなく) パイプライン内の任意の SageMaker AI ジョブステップに、一意またはカスタマイズされたロールを使用できます。パイプライン実行ロールが、これらの各ロールを指定する
iam:PassRoleアクセス許可を持つポリシーを追加していることを確認します。 -
パイプライン内の各ジョブタイプに対する
CreateとDescribeのアクセス許可。 -
JsonGet関数を使用するための Amazon S3 アクセス許可。Amazon S3 リソースへのアクセスは、リソースベースのポリシーとアイデンティティベースのポリシーを使用して制御します。リソースベースのポリシーが Amazon S3 バケットに適用され、Pipelines にバケットへのアクセス権が付与されます。アイデンティティベースのポリシーは、アカウントから Amazon S3 呼び出しを行う機能をパイプラインに提供します。リソースベースのポリシーとアイデンティティベースのポリシーの詳細については、「アイデンティティベースのポリシーとリソースベースのポリシー」を参照してください。{ "Action": [ "s3:GetObject" ], "Resource": "arn:aws:s3:::<your-bucket-name>/*", "Effect": "Allow" }
パイプラインステップのアクセス許可
Pipelines は、SageMaker AI ジョブを実行する手順を提供しています。パイプラインステップでこれらのジョブを実行するには、必要なリソースへのアクセスを提供する IAM ロールがアカウントに必要です。このロールは、パイプラインによって SageMaker AI サービスプリンシパルに渡されます。IAM ロールの詳細については、「IAM ロール」を参照してください。
デフォルトでは、各ステップがパイプラインの実行ロールを取得します。必要に応じて、パイプラインの任意のステップに別のロールを渡すこともできます。こうすることで、パイプライン定義で指定される 2 つのステップ間に直接的な関係がない限り、各ステップのコードは他のステップで使用されるリソースに影響を与えないようになります。これらのロールは、ステップのプロセッサや推定器を定義するときに渡します。これらの定義にロールを含める方法の例については、「SageMaker AI Python SDK ドキュメント
Amazon S3 バケットを使用した CORS 設定
Amazon S3 バケットから Pipelines にイメージが期待どおりにインポートされるようにするには、イメージのインポート元となる Amazon S3 バケットに CORS 設定を追加する必要があります。このセクションでは、必要な CORS 設定を Amazon S3 バケットに設定する方法について説明します。Pipelines に必要な XML CORSConfiguration は、入力イメージデータの CORS 要件 の XML とは異なります。これ以外の場合は、XML に記載されている情報を使用して、Amazon S3 バケットの CORS 要件の詳細を取得できます。
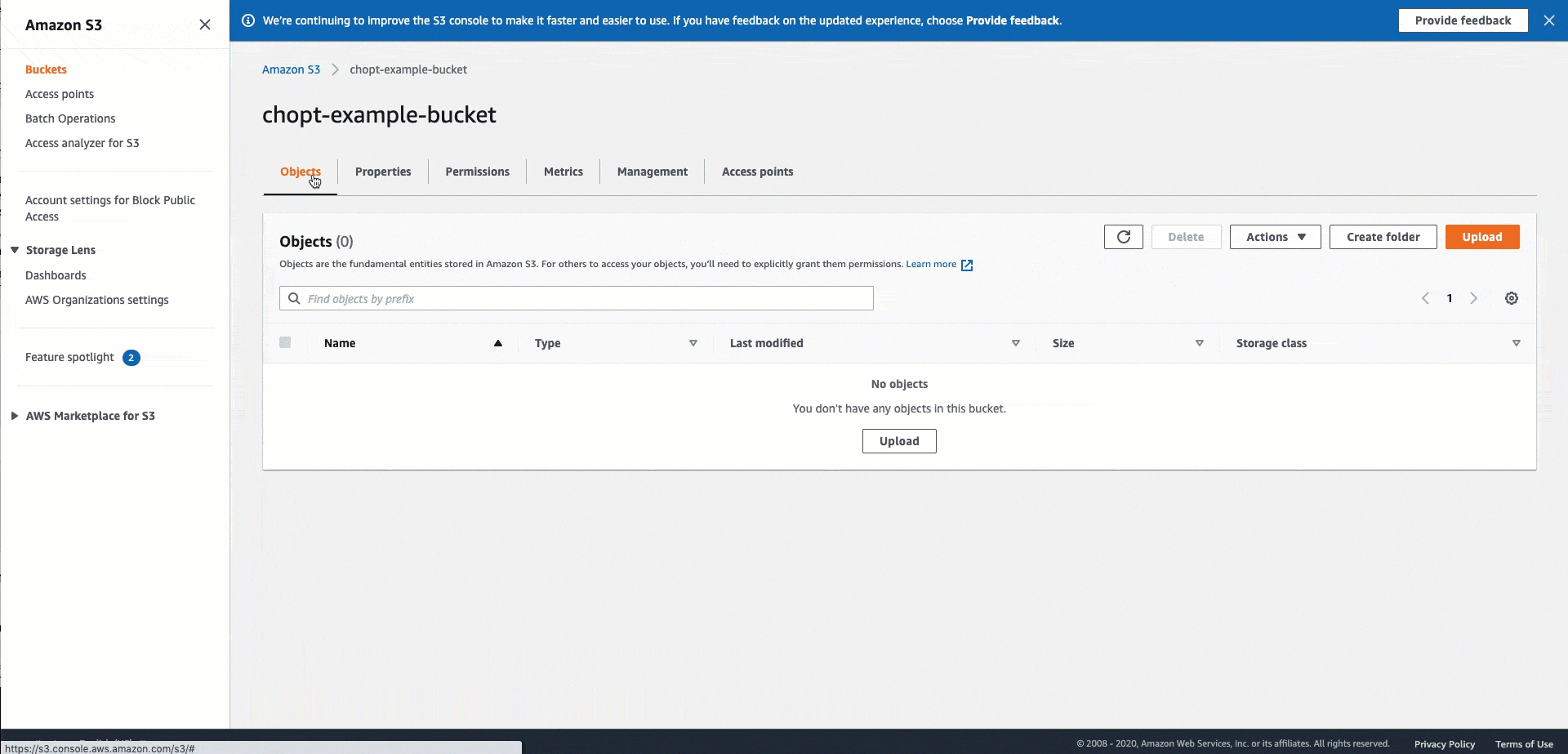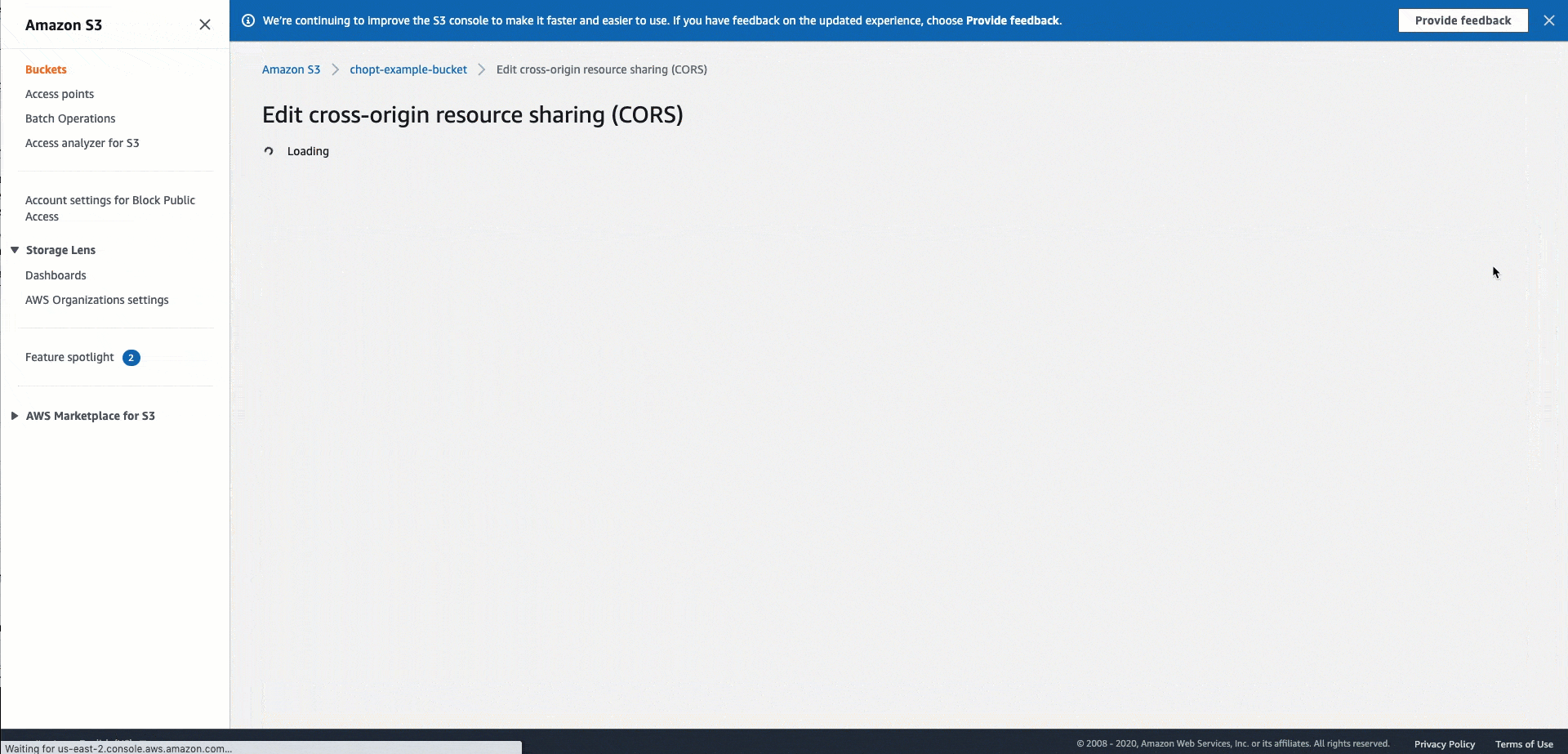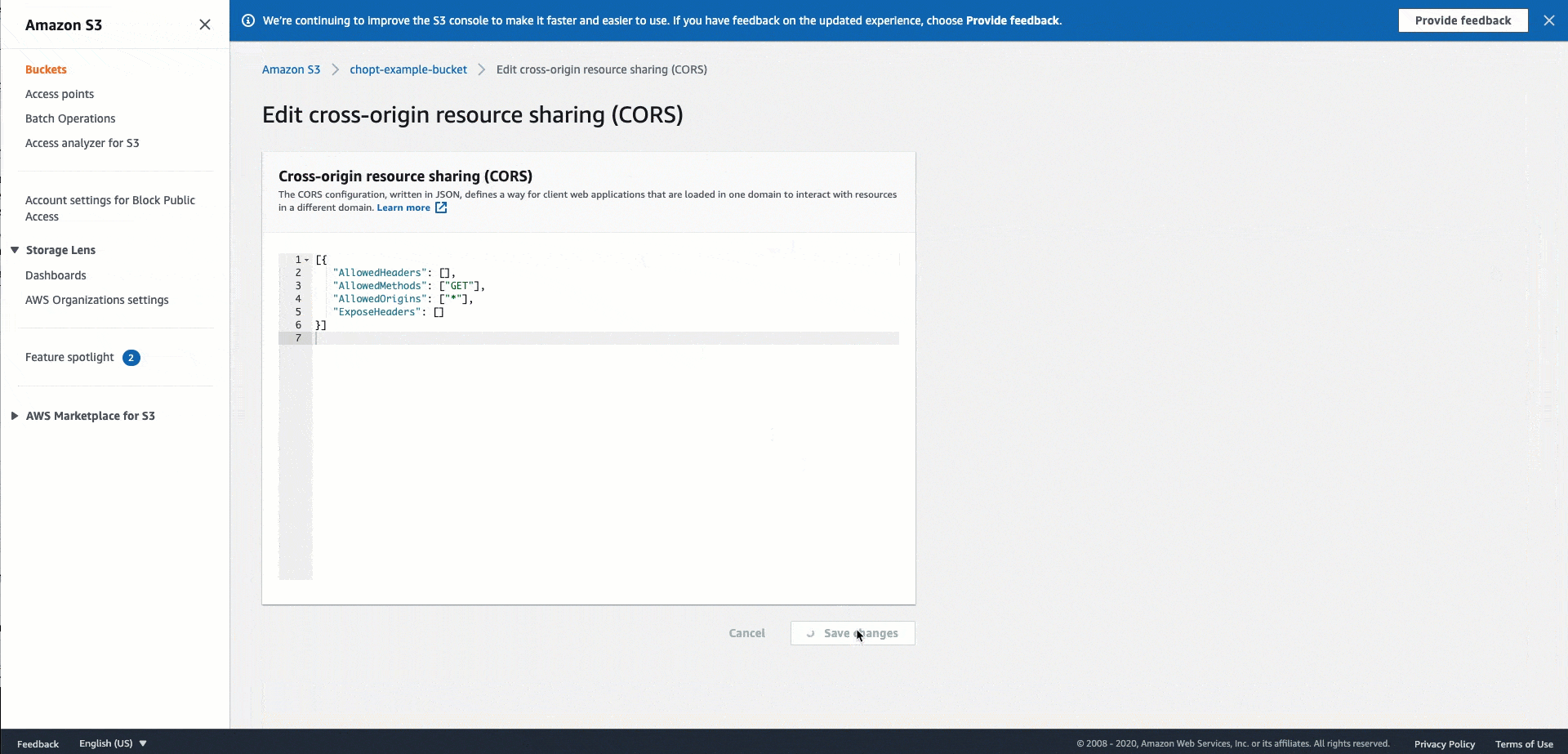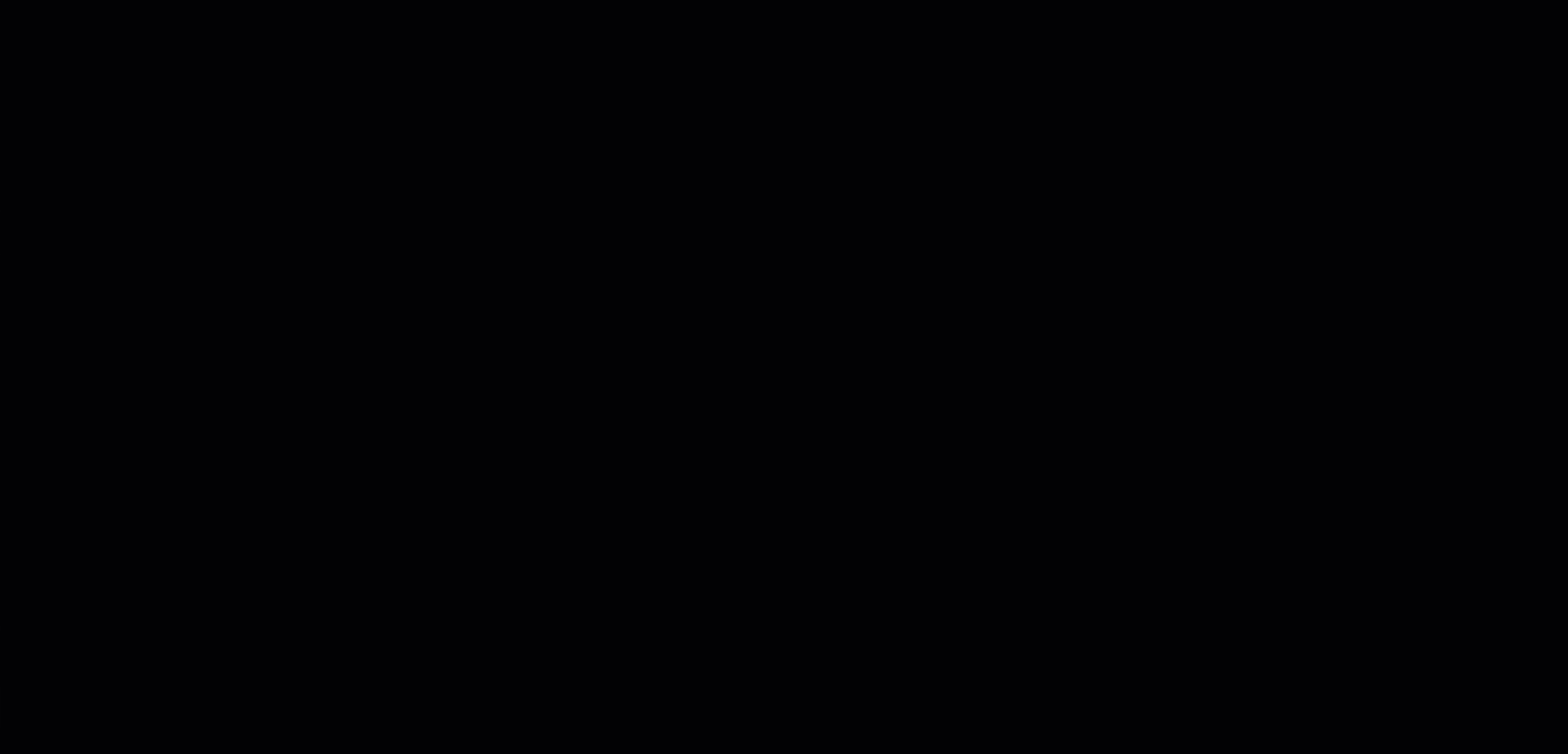
イメージをホストする Amazon S3 バケットには、次の CORS 設定コードを使用します。CORS を設定する手順については、「Amazon Simple Storage Service ユーザーガイド」の「Cross−Origin Resource Sharing (CORS) の設定」を参照してください。Amazon S3 コンソールを使用してポリシーをバケットに追加する場合は、JSON 形式を使用する必要があります。
JSON
[ { "AllowedHeaders": [ "*" ], "AllowedMethods": [ "PUT" ], "AllowedOrigins": [ "*" ], "ExposeHeaders": [ "Access-Control-Allow-Origin" ] } ]
XML
<CORSConfiguration> <CORSRule> <AllowedHeader>*</AllowedHeader> <AllowedOrigin>*</AllowedOrigin> <AllowedMethod>PUT</AllowedMethod> <ExposeHeader>Access-Control-Allow-Origin</ExposeHeader> </CORSRule> </CORSConfiguration>
次の GIF は、Amazon S3 コンソールを使って CORS ヘッダーポリシーを追加する方法に関する Amazon S3 ドキュメントにある手順を示しています。
Pipelines ジョブのアクセス管理をカスタマイズする
IAM ポリシーをさらにカスタマイズして、組織内の特定のメンバーがパイプラインステップの一部またはすべてを実行できるようにすることが可能です。例えば、特定のユーザーにトレーニングジョブを作成するアクセス許可を付与し、別のユーザーグループに処理ジョブを作成するアクセス許可を付与し、すべてのユーザーに残りのステップを実行するアクセス許可を付与できます。この機能を使用するには、ジョブ名にプレフィックスとして付けるカスタム文字列を選択します。管理者は許可された ARN の先頭にプレフィックスを付加し、データサイエンティストはこのプレフィックスをパイプラインのインスタンス化に含めます。許可されたユーザーの IAM ポリシーには、指定されたプレフィックスの付いたジョブ ARN が含まれているため、パイプラインステップの後続のジョブには、続行するために必要なアクセス許可が付与されます。ジョブプレフィックスはデフォルトではオフになっています。使用するには Pipeline クラスでこのオプションをオンにする必要があります。
プレフィックスがオフになっているジョブの場合、ジョブ名は次の表で説明するフィールドを連結した形式になります。
pipelines-<executionId>-<stepNamePrefix>-<entityToken>-<failureCount>
| フィールド | 定義 |
|---|---|
|
pipelines |
常に静的な文字列が先頭に追加されます。この文字列は、パイプラインオーケストレーションサービスをジョブのソースとして識別します。 |
|
executionId |
実行中のパイプラインインスタンス用のランダム化されたバッファ。 |
|
stepNamePrefix |
ユーザー指定のステップ名 (パイプラインステップの |
|
entityToken |
ステップエンティティが冪等性であることを保証するためのランダム化されたトークン。 |
|
failureCount |
ジョブを完了するために試行された現在の再試行回数。 |
この場合、ジョブ名の先頭にはカスタムプレフィックスは付けられず、対応する IAM ポリシーがこの文字列と一致する必要があります。
ジョブプレフィックスを有効にするユーザーの場合、基になるジョブ名は次の形式になり、カスタムプレフィックスは MyBaseJobName として指定されます。
<MyBaseJobName>-<executionId>-<entityToken>-<failureCount>
カスタムプレフィックスは、静的な pipelines 文字列を置き換え、パイプラインの一部として SageMaker AI ジョブを実行できるユーザーの選択を絞り込むのに役立ちます。
プレフィックスの長さ制限
ジョブ名には、個々のパイプラインステップに固有の内部の長さ制限があります。この制約により、許可されるプレフィックスの長さも制限されます。プレフィックスの長さの要件は以下のとおりです。
| パイプラインのステップ | プレフィックスの長さ |
|---|---|
|
|
38 |
|
6 |
IAM ポリシーにジョブプレフィックスを適用する
管理者は IAM ポリシーを作成して、特定のプレフィックスを持つユーザーにジョブの作成を許可します。以下のポリシーの例では、データサイエンティストに、MyBaseJobName プレフィックスを使用する場合にトレーニングジョブの作成を許可しています。
{ "Action": "sagemaker:CreateTrainingJob", "Effect": "Allow", "Resource": [ "arn:aws:sagemaker:region:account-id:*/MyBaseJobName-*" ] }
ジョブプレフィックスをパイプラインインスタンス化に適用する
プレフィックスをジョブインスタンスクラスの *base_job_name 引数で指定します。
注記
パイプラインステップを作成する前に、*base_job_name 引数付きのジョブプレフィックスをジョブインスタンスに渡します。このジョブインスタンスには、ジョブをパイプラインのステップとして実行するのに必要な情報が含まれています。この引数は、使用するジョブインスタンスによって異なります。次のリストは、各パイプラインステップタイプにどの引数を使用するかを示しています。
-
Estimator(TrainingStep)、Processor(ProcessingStep)、AutoML(AutoMLStep) クラス用のbase_job_name -
Tunerクラス (TuningStep) 用のtuning_base_job_name -
Transformerクラス (TransformStep) 用のtransform_base_job_name -
QualityCheckStep(品質チェック) クラスとClarifyCheckstep(明確化チェック) クラス用のCheckJobConfigのbase_job_name -
Modelクラスに使用される引数は、結果をModelStepに渡す前にモデルに対してcreateを実行するかregisterを実行するかによって異なります。-
createを呼び出す場合、カスタムプレフィックスはモデルを構築するときのname引数から取得されます (つまりModel(name=))。 -
registerを呼び出す場合、カスタムプレフィックスはregister呼び出しのmodel_package_name引数から取得されます (つまりmy_model.register(model_package_name=)
-
次の例は、新しいトレーニングジョブインスタンスのプレフィックスを指定する方法を示しています。
# Create a job instance xgb_train = Estimator( image_uri=image_uri, instance_type="ml.m5.xlarge", instance_count=1, output_path=model_path, role=role, subnets=["subnet-0ab12c34567de89f0"], base_job_name="MyBaseJobName" security_group_ids=["sg-1a2bbcc3bd4444e55"], tags = [ ... ] encrypt_inter_container_traffic=True, ) # Attach your job instance to a pipeline step step_train = TrainingStep( name="TestTrainingJob", estimator=xgb_train, inputs={ "train": TrainingInput(...), "validation": TrainingInput(...) } )
ジョブプレフィックスはデフォルトではオフになっています。この機能を有効にするには、以下のスニペットに示す PipelineDefinitionConfig の use_custom_job_prefix オプションを使用します。
from sagemaker.workflow.pipeline_definition_config import PipelineDefinitionConfig # Create a definition configuration and toggle on custom prefixing definition_config = PipelineDefinitionConfig(use_custom_job_prefix=True); # Create a pipeline with a custom prefix pipeline = Pipeline( name="MyJobPrefixedPipeline", parameters=[...] steps=[...] pipeline_definition_config=definition_config )
パイプラインを作成して実行します。次の例では、パイプラインを作成して実行し、ジョブのプレフィックスをオフにしてパイプラインを再実行する方法も示しています。
pipeline.create(role_arn=sagemaker.get_execution_role()) # Optionally, call definition() to confirm your prefixed job names are in the built JSON pipeline.definition() pipeline.start() # To run a pipeline without custom-prefixes, toggle off use_custom_job_prefix, update the pipeline # via upsert() or update(), and start a new run definition_config = PipelineDefinitionConfig(use_custom_job_prefix=False) pipeline.pipeline_definition_config = definition_config pipeline.update() execution = pipeline.start()
同様に、既存のパイプラインでもこの機能をオンに切り替えて、ジョブプレフィックスを使用する新規の実行を開始できます。
definition_config = PipelineDefinitionConfig(use_custom_job_prefix=True) pipeline.pipeline_definition_config = definition_config pipeline.update() execution = pipeline.start()
最後に、パイプライン実行時に list_steps を呼び出して、カスタムプレフィックスが付いたジョブを表示できます。
steps = execution.list_steps() prefixed_training_job_name = steps['PipelineExecutionSteps'][0]['Metadata']['TrainingJob']['Arn']
パイプラインバージョンへのアクセスをカスタマイズする
sagemaker:PipelineVersionId 条件キーを使用して、特定のバージョンの Amazon SageMaker Pipelines へのカスタマイズされたアクセスを許可できます。例えば、以下のポリシーは、バージョン ID 6 以降にたいしてのみ、実行を開始したり、パイプラインバージョンを更新したりするためのアクセスを許可します。
サポートされる条件キーの詳細については、「Amazon SageMaker AI の条件キー」を参照してください。
Pipelines を使用したサービスコントロールポリシー
サービスコントロールポリシー (SCP) は、組織のアクセス許可の管理に使用できる組織ポリシーの一種です。SCP では、組織のすべてのアカウントで使用可能な最大アクセス許可を一元的に制御できます。組織内で Pipelines を使用することで、データサイエンティストが AWS コンソールを操作することなくパイプラインの実行を管理できるようになります。
Amazon S3 へのアクセスを制限する SCP で VPC を使用する場合、他の Amazon S3 リソースへのアクセスをパイプラインに許可するための手順を実行する必要があります。
VPC 外の Amazon S3 に Pipelines が JsonGet 関数を使用してアクセスできるようにするには、Pipelines を使用するロールが Amazon S3 にアクセスできるように組織の SCP を更新します。これを行うには、プリンシパルタグと条件キーを使用して、パイプラインの実行ロールを介して Pipelines エグゼキュターが使用するロールの例外を作成します。
VPC 外の Amazon S3 へのアクセスを Pipelines に許可するには
-
「IAM ユーザーとロールのタグ付け」の手順に従って、パイプラインの実行ロールに固有のタグを作成します。
-
作成したタグの
Aws:PrincipalTag IAM条件キーを使用して、SCP で例外を付与します。詳細については、「サービスコントロールポリシーの作成、更新、削除」を参照してください。
