Amazon Redshift は、パッチ 198 以降、新しい Python UDF の作成をサポートしなくなります。既存の Python UDF は、2026 年 6 月 30 日まで引き続き機能します。詳細については、[ブログ記事](https://aws.amazon.com/blogs/big-data/amazon-redshift-python-user-defined-functions-will-reach-end-of-support-after-june-30-2026/)を参照してください。
# クラスターのパフォーマンスデータを表示する
Amazon Redshift のクラスターメトリクスを使用することにより、次のような一般的なパフォーマンスタスクを実行することができるようになります。
+ 指定された時間範囲でクラスターメトリクスが異常かどうかを判断し、異常な場合は、パフォーマンスに影響しているクエリを識別します。
+ 過去または現在のクエリがクラスターのパフォーマンスに影響しているかどうかを確認します。問題があるクエリを特定した場合は、クエリ実行中のクラスターのパフォーマンスなど、それに関する詳細を確認できます。この情報を使用して、クエリが低速だった理由と、パフォーマンスを向上させるための操作を診断できます。
**パフォーマンスデータを表示するには**
1. AWS マネジメントコンソール にサインインして、[https://console.aws.amazon.com/redshiftv2/](https://console.aws.amazon.com/redshiftv2/) で Amazon Redshift コンソールを開きます。
1. ナビゲーションメニューで **[Clusters]** (クラスター) を選択し、リストからクラスターの名前を選択してその詳細を開きます。クラスターの詳細が、**[クラスターのパフォーマンス]** タブ、**[クエリのモニタリング]** タブ、**[データベース]** タブ、**[データ共有]** タブ、**[スケジュール]** タブ、**[メンテナンス]** タブ、**[プロパティ]** タブなどに表示されます。
1. [**Cluster performance (クラスターのパフォーマンス)**] タブを選択して、次を含むパフォーマンス情報を表示します。
+ **CPU 使用率**
+ **ディスク使用率**
+ **データベース接続**
+ **ヘルスステータス**
+ **クエリの期間**
+ **クエリのスループット**
+ **同時実行スケーリングアクティビティ**
利用可能なメトリクスが大幅に増えました。利用可能なメトリクスを確認して、表示するメトリクスを選択するには、[**設定**] アイコンを選択します。
## クラスターのパフォーマンスグラフ
次の例は、新しい Amazon Redshift コンソールに表示されるグラフの一部を示しています。
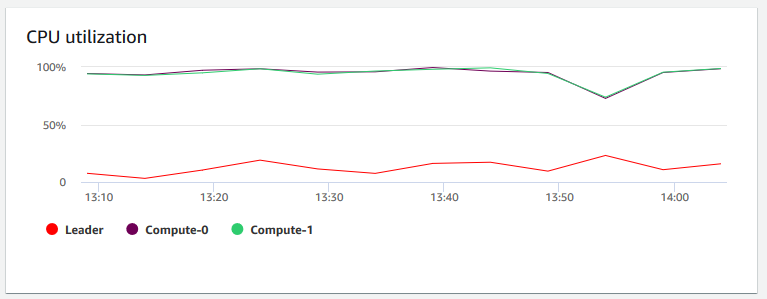
+ **CPU 使用率** – すべてのノード (リーダーとコンピューティング) の CPU 使用率を示します。クラスターの移行やリソースを消費するその他のオペレーションをスケジュールする前に、クラスターの使用率が最も低い時間を見つけるには、このグラフをモニタリングして、個々のノードまたはすべてのノードの CPU 使用率を確認します。
+ **メンテナンスモード** – 選択した時間にクラスターがメンテナンスモードになっているかどうかを、`On` インジケータと `Off` インジケータで示します。クラスターがメンテナンス中である時間を確認できます。次に、この時間をクラスターに対して実行されたオペレーションと関連付けて、定期的なイベントの将来のダウンタイムを推定できます。

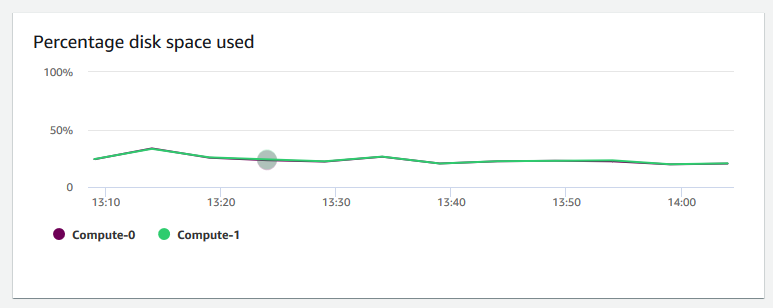
+ **ディスク容量使用率** – クラスター全体ではなく、コンピューティングノードあたりのディスク容量の使用率を示します。このグラフを表示して、ディスク使用率をモニタリングできます。VACUUM や COPY などのメンテナンスオペレーションでは、ソートオペレーションに中間の一時ストレージ領域が使用されるため、ディスク使用率のスパイクが予想されます。
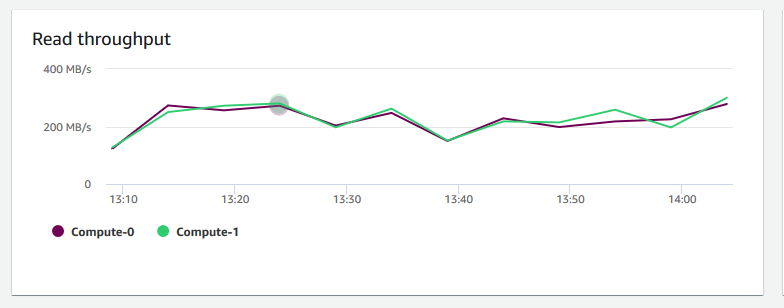
+ **読み込みスループット** – ディスクから読み取られた 1 秒あたりの平均メガバイト数を示します。このグラフを評価して、クラスターの対応する物理側面をモニタリングできます。クラスターとそのボリューム内のインスタンス間のネットワークトラフィックは、このスループットに含まれません。
+ **読み込みレイテンシー** – ディスク読み取り I/O オペレーションにかかった平均時間 (ミリ秒単位) を示します。返されるデータの応答時間を表示できます。レイテンシーが高い場合、送信側がアイドル時間 (新しいパケットを送信しない時間) に費やす時間が長くなり、スループットが低下します。

+ **書き込みスループット** – ディスクに書き込まれた 1 秒あたりの平均メガバイト数を示します。このメトリクスを評価して、クラスターの対応する物理側面をモニタリングできます。クラスターとそのボリューム内のインスタンス間のネットワークトラフィックは、このスループットに含まれません。

+ **書き込みレイテンシー** – ディスク書き込み I/O オペレーションにかかった平均時間 (ミリ秒単位) を示します。書き込み確認応答が返されるまでの時間を評価できます。レイテンシーが高い場合、送信側がアイドル時間 (新しいパケットを送信しない時間) に費やす時間が長くなり、スループットが低下します。

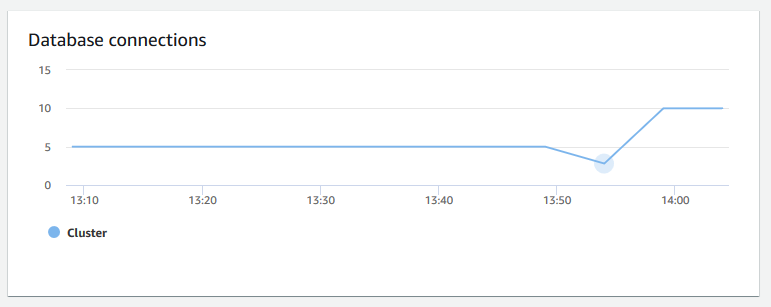
+ **データベース接続** – クラスターへのデータベース接続の数を示します。このグラフを使用して、データベースに対して確立されている接続数を確認し、クラスターの使用率が最も低い時間を見つけることができます。
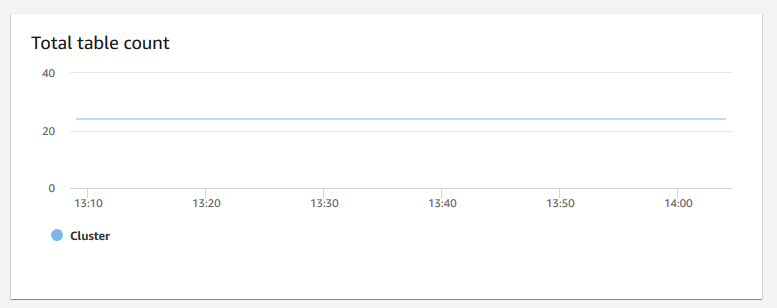
+ **合計テーブル数** – 特定の時点でクラスター内で開いているユーザーテーブルの数を示します。開いているテーブルの数が多い場合は、クラスターのパフォーマンスをモニタリングできます。
+ **ヘルスステータス** – クラスターのヘルスを `Healthy` または `Unhealthy` で示します。クラスターがデータベースに接続でき、単純なクエリを正常に実行できる場合、クラスターは正常であると見なされます。それ以外の場合、クラスターは正常な状態ではありません。正常でない状態が発生する可能性があるのは、クラスターデータベースに極端に高い負荷がかかっているか、クラスター上のデータベースに設定の問題がある場合です。

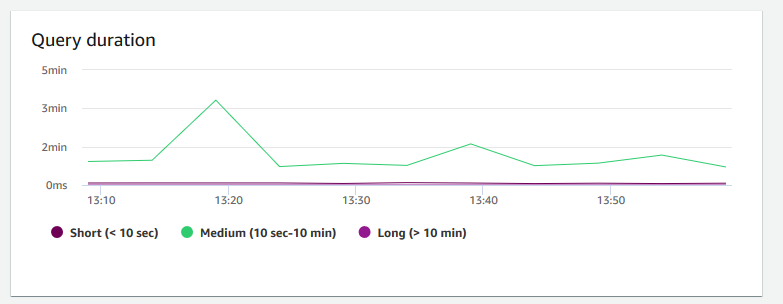
+ **クエリ期間** – クエリを完了するまでの平均時間 (マイクロ秒単位) を示します。このグラフのデータをベンチマークして、クラスター内の I/O パフォーマンスを測定し、最も時間のかかるクエリを必要に応じて調整できます。
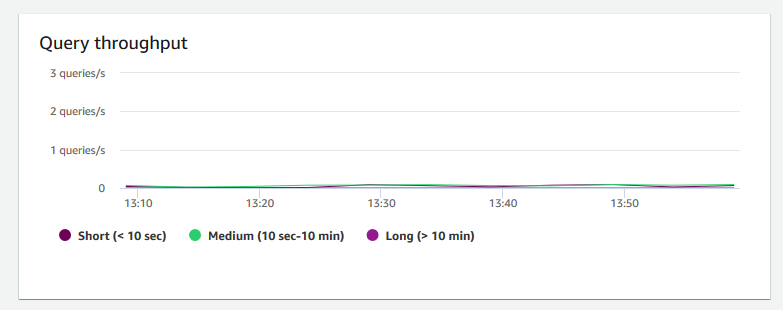
+ **クエリスループット** – 1 秒あたりの完了済みクエリの平均数を示します。このグラフ上のデータを分析して、データベースのパフォーマンスを測定し、バランスのとれた方法でマルチユーザーのワークロードに対応するシステム能力を明らかにできます。
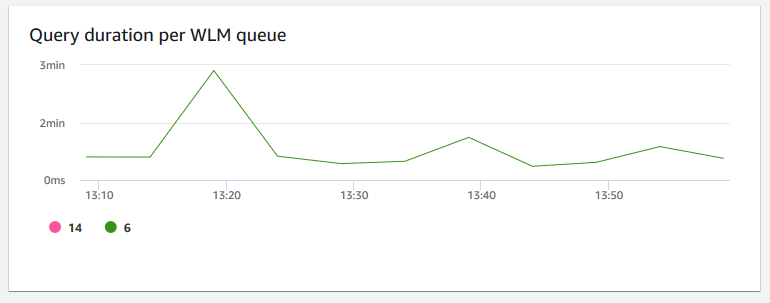
+ **WLM キューあたりのクエリの期間** – クエリを完了するまでの平均時間 (マイクロ秒単位) を示します。このグラフのデータをベンチマークして、WLM キューあたりの I/O パフォーマンスを測定し、最も時間のかかるクエリを必要に応じて調整できます。
+ **WLM キューあたりのクエリスループット** – 1 秒あたりの完了済みクエリの平均数を示します。このグラフのデータを分析して、WLM キューごとのデータベースパフォーマンスを測定できます。

+ **同時実行スケーリングアクティビティ** – アクティブな同時実行スケーリングクラスターの数を表示します。同時実行スケーリングが有効になっていると、同時読み込みクエリの増加を処理する必要がある場合、Amazon Redshift は自動的に追加のクラスター容量を追加します。
