Amazon Redshift は、パッチ 198 以降、新しい Python UDF の作成をサポートしなくなります。既存の Python UDF は、2026 年 6 月 30 日まで引き続き機能します。詳細については、[ブログ記事](https://aws.amazon.com/blogs/big-data/amazon-redshift-python-user-defined-functions-will-reach-end-of-support-after-june-30-2026/)を参照してください。
# Amazon Redshift の概念実証 (POC) を実施する
Amazon Redshift は、広く利用されているクラウドデータウェアハウスであり、組織の Amazon Simple Storage Service データレイク、リアルタイムストリーム、機械学習 (ML) ワークフロー、トランザクションワークフローなどと連携するクラウドベースのフルマネージドサービスを提供します。以降のセクションでは、Amazon Redshift で概念実証 (POC) を実施するプロセスについて説明します。ここで紹介する情報は、POC の目標を設定する際に役立ちます。ここでは、POC のサービスのプロビジョンと設定を自動化できるツールを活用します。
**注記**
この情報を PDF としてコピーするには、「[Amazon Redshift のリソース](https://aws.amazon.com/redshift/resources/)」ページで [**独自の Redshift 概念実証 (POC) を実行**] リンクを選択します。
Amazon Redshift の POC を実施する場合、クラス最高レベルのセキュリティ機能、伸縮自在なスケーリング、容易な統合と取り込み、柔軟な分散型データアーキテクチャのオプションなど、さまざまな機能をテスト、実証、採用できます。

POC を成功に導くには、以下のステップを実施します。
## ステップ 1: POC の範囲を定義する

POC を実施する際は、独自のデータを使用するか、ベンチマークデータセットを使用するかを選択できます。独自のデータを選択する場合、そのデータに対して独自のクエリを実行します。ベンチマークデータの場合、ベンチマークとともにサンプルクエリが提供されます。独自のデータで POC を実施する準備がまだできていない場合は、「[サンプルデータセットを使用する](#use-sample-datasets)」で詳細を確認してください。
Amazon Redshift の POC については、一般に 2 週間分のデータを使用することをお勧めします。
開始するには、以下を実施します。
1. **ビジネス要件と機能要件を特定**し、完成形から逆向きに作業します。一般的な例には、パフォーマンスの向上、コスト低減、新しいワークロードや機能のテスト、Amazon Redshift と別のデータウェアハウスの比較などがあります。
1. POC の成功基準となる**具体的な目標**を設定します。例えば、**パフォーマンスの向上の場合、高速化する上位 5 つのプロセスをリストアップして、現在の実行時間と必要となる実行時間を目標に含めます。プロセスは、レポート、クエリ、ETL プロセス、データインジェストなど、現在抱えている課題のいずれかで構いません。
1. テストの実行に必要となる**具体的な範囲とアーティファクト**を特定します。Amazon Redshift に移行または継続的に取り込む必要があるデータセットと、テストを実行して成功基準と照らし合わせるうえで必要となるクエリとプロセスを特定します。これには、以下の 2 つの方法があります。
**独自のデータを使用する**
+ 独自のデータをテストするには、成功基準を満たすテストに必要となる、実行可能な最小限のデータアーティファクトのリストを作成します。例えば、現在のデータウェアハウスに 200 のテーブルがあり、テストするレポートで必要となるのが 20 のテーブルのみの場合、テーブルの小型のサブセットのみを使用すると POC の実行を迅速化できます。
**サンプルデータセットを使用する**
+ 独自のデータセットの準備ができていない場合でも、[TPC-DS](https://github.com/awslabs/amazon-redshift-utils/tree/master/src/CloudDataWarehouseBenchmark/Cloud-DWB-Derived-from-TPCDS) や [TPC-H](https://github.com/awslabs/amazon-redshift-utils/tree/master/src/CloudDataWarehouseBenchmark/Cloud-DWB-Derived-from-TPCH) などの業界標準のベンチマークデータを使用して Amazon Redshift で POC を開始し、サンプルベンチマーククエリを実行し、Amazon Redshift の機能を活用できます。上記のデータセットには、作成後に Amazon Redshift データウェアハウス内からアクセスできます。上記データセットとサンプルクエリにアクセスする方法の詳細な手順については、「[ステップ 2: Amazon Redshift を起動する](#proof-of-concept-launch)」を参照してください。
## ステップ 2: Amazon Redshift を起動する

Amazon Redshift を使用すると、高速、簡単、安全な大規模なクラウドデータウェアハウスを使って、インサイト取得までの時間を短縮できます。[Redshift Serverless コンソール](https://console.aws.amazon.com//redshiftv2/home?#serverless-dashboard)でウェアハウスを起動すると、すぐに使用を開始でき、数秒でデータからインサイトを取得できます。Redshift Serverless を使用すると、データウェアハウスの管理にわずらわされることなく、ビジネス成果の実現に集中できます。
### Amazon Redshift Serverless を設定する
Redshift Serverless を初めて使用する場合、コンソールがウェアハウスの起動に必要となる手順をガイドします。また、アカウントでの Redshift サーバーレスの使用状況に対するクレジットの対象となる場合もあります。無料トライアルの選択に関する詳細については、[Amazon Redshift 無料トライアル](https://aws.amazon.com/redshift/free-trial/)を参照してください。「**Amazon Redshift の開始方法」の「[Amazon Redshift Serverless によるデータウェアハウスの作成](https://docs.aws.amazon.com/redshift/latest/gsg/new-user-serverless.html#serverless-console-resource-creation)」の手順に従って、Redshift Serverless でデータウェアハウスを作成します。ロードするデータセットがない場合は、このガイドにサンプルデータセットをロードする手順も記載されています。
既にアカウントで Redshift Serverless を起動したことがある場合は、「**Amazon Redshift 管理ガイド」の「[名前空間を伴うワークグループの作成](https://docs.aws.amazon.com/redshift/latest/mgmt/serverless-console-workgroups-create-workgroup-wizard.html)」の手順に従ってください。ウェアハウスが利用できるようになったら、Amazon Redshift で利用可能なサンプルデータのロードを選択できます。Amazon Redshift クエリエディタ v2 を使用してデータをロードする方法の詳細については、「**Amazon Redshift 管理ガイド」の「[サンプルデータのロード](https://docs.aws.amazon.com/redshift/latest/mgmt/query-editor-v2-loading.html#query-editor-v2-loading-sample-data)」を参照してください。
サンプルデータセットをロードする代わりに独自のデータを使用する場合は、「[ステップ 3: サンプルデータをロードする](#proof-of-concept-load-data)」を参照してください。
## ステップ 3: サンプルデータをロードする

Redshift Serverless 起動後の次のステップは、POC のためのデータのロードです。シンプルな CSV ファイルをアップロードする場合でも、S3 から半構造化データを取り込む場合でも、データを直接ストリーミングする場合でも、Amazon Redshift は、データをソースから Amazon Redshift テーブルに迅速かつ簡単に移動する柔軟性を提供します。
データのロードには、次のいずれかの方法を選択します。
### ローカルファイルをアップロードする
手早くデータを取り込み、分析するには、[Amazon Redshift クエリエディタ v2](https://docs.aws.amazon.com/redshift/latest/mgmt/query-editor-v2.html) を使用して、ローカルのデスクトップからデータファイルを簡単にロードできます。Redshift は、CSV、JSON、AVRO、PARQUET、ORC など、さまざまな形式のファイルを処理する機能を備えています。ユーザーが管理者としてクエリエディタ v2 を使用してローカルデスクトップからデータをロードできるようにするには、共有の Amazon S3 バケットを指定し、ユーザーアカウントに[適切なアクセス許可を設定](https://docs.aws.amazon.com/redshift/latest/mgmt/query-editor-v2-loading.html#query-editor-v2-loading-data-local)する必要があります。ステップバイステップガイダンスについては、「[クエリエディタ V2 を使用して Amazon Redshift でのデータロードを簡単かつ安全に行う方法](https://aws.amazon.com/blogs//big-data/data-load-made-easy-and-secure-in-amazon-redshift-using-query-editor-v2/)」に従ってください。
### Amazon S3 ファイルをロードする
Amazon S3 バケットから Amazon Redshift にデータをロードするには、まず [COPY コマンド](https://docs.aws.amazon.com/redshift/latest/dg/t_loading-tables-from-s3.html)を使用します。コマンドでは、ソースの Amazon S3 の場所とターゲットの Amazon Redshift テーブルを指定します。指定した Amazon S3 バケットに Amazon Redshift がアクセスできるように、IAM ロールとアクセス許可が適切に設定されていることを確認します。ステップバイステップのガイダンスについては、「[チュートリアル: Amazon S3 からデータをロードする](https://docs.aws.amazon.com/redshift/latest/dg/tutorial-loading-data.html)」を参照してください。クエリエディタ v2 で **[データのロード]** オプションを選択して、S3 バケットから直接データをロードすることもできます。
### 継続的なデータインジェスト
[Autocopy (プレビュー中)](https://docs.aws.amazon.com/redshift/latest/dg/loading-data-copy-job.html) は、[COPY コマンド](https://docs.aws.amazon.com/redshift/latest/dg/t_loading-tables-from-s3.html)の拡張機能であり、Amazon S3 バケットからの継続的なデータのロードを自動化します。COPY ジョブを作成すると、Amazon Redshift は、指定されたパスに新しい Amazon S3 ファイルが作成されたことを検出し、ユーザーの操作なしで自動的にロードします。Amazon Redshift は、ロードされたファイルを記録して、ロードされたのは 1 回だけであることを確認します。COPY ジョブの作成手順については、「[COPY JOB](r_COPY-JOB.md)」を参照してください。
**注記**
Autocopy は現時点ではプレビュー段階であり、特定の AWS リージョン でプロビジョンされたクラスターでのみサポートされています。Autocopy 向けのプレビュークラスターを作成するには、「[S3 イベント統合を作成して Amazon S3 バケットからファイルを自動的にコピーする](loading-data-copy-job.md)」を参照してください。
### ストリーミングデータをロードする
ストリーミング取り込み機能を使用すると、[Amazon Kinesis Data Streams](https://aws.amazon.com/kinesis/data-streams/) と [Amazon Managed Streaming for Apache Kafka](https://aws.amazon.com/msk/) から Amazon Redshift へのストリームデータの低レイテンシーかつ高速な取り込みができます。Amazon Redshift のストリーミング取り込みは、マテリアライズドビューを使用します。マテリアライズドビューは、[自動更新](https://docs.aws.amazon.com/redshift/latest/dg/materialized-view-refresh.html#materialized-view-auto-refresh)を利用してストリームから直接更新されます。マテリアライズドビューは、ストリームのデータソースにマッピングされています。マテリアライズドビューの定義を行う際には、ストリームデータをフィルタリングしたり集計したりできます。ストリームからデータをロードするステップバイステップのガイダンスについては、「[Amazon Kinesis Data Streams の開始方法](https://docs.aws.amazon.com/redshift/latest/dg/materialized-view-streaming-ingestion-getting-started.html)」または「[Amazon Managed Streaming for Apache Kafka からのストリーミング取り込みを開始する](https://docs.aws.amazon.com/redshift/latest/dg/materialized-view-streaming-ingestion-getting-started-MSK.html)」を参照してください。
## ステップ 4: データを分析する

Redshift Serverless ワークグループと名前空間を作成し、データをロードしたら、[Redshift Serverless コンソール](https://console.aws.amazon.com//redshiftv2/home?#serverless-dashboard)のナビゲーションパネルから **[クエリエディタ v2]** を開いて、直ちにクエリを実行できます。クエリエディタ v2 を使用して、独自のデータセットに対してクエリ機能をテストしたり、クエリのパフォーマンスをテストしたりできます。
### Amazon Redshift クエリエディタ v2 を使用してクエリを実行する
Amazon Redshift コンソールからクエリエディタ v2 にアクセスできます。クエリエディタ v2 を使用してクエリを設定、接続、実行する方法に関する完全なガイドについては、「[Amazon Redshift クエリエディタ v2 でデータ分析を簡素化する](https://aws.amazon.com/blogs//big-data/simplify-your-data-analysis-with-amazon-redshift-query-editor-v2/)」を参照してください。
別の方法として、POC の一環で負荷テストを実行する場合は、以下の手順で Apache JMeter をインストールして実行することもできます。
### Apache JMeter を使用して負荷テストを実行する
「N」人のユーザーが Amazon Redshift に同時にクエリを送信するシミュレーションを行う負荷テストを実行するには、オープンソースの Java ベースのツールである [Apache JMeter](https://jmeter.apache.org/) を使用できます。
Apache JMeter をインストールして Redshift Serverless ワークグループに対して実行させるように設定するには、「[AWS Analytics Automation Toolkit を使用して Amazon Redshift の負荷テストを自動化する](https://aws.amazon.com/blogs//big-data/automate-amazon-redshift-load-testing-with-the-aws-analytics-automation-toolkit/)」の手順に従ってください。これは、Redshift ソリューションを動的にデプロイするためのオープンソースユーティリティである [AWS Analytics Automation toolkit (AAA)](https://github.com/aws-samples/amazon-redshift-infrastructure-automation/tree/main) を使用して、上記リソースを自動的に起動します。独自のデータを Amazon Redshift にロードした場合は、必ず「ステップ 5 – SQL オプションをカスタマイズする」に従い、テーブルに対してテストすべき適切な SQL ステートメントを明確に指定して実行します。クエリエディタ v2 を使用してこのような SQL ステートメントを各 1 回ずつテストして、エラーなく実行されることを確認します。
SQL ステートメントのカスタマイズを完了し、テスト計画を最終化したら、テスト計画を保存して、Redshift Serverless ワークグループに対して実行します。テストの進行状況をモニタリングするには、[Redshift Serverless コンソール](https://console.aws.amazon.com/redshiftv2/home?#serverless-query-and-database-monitoring) を開いて **[クエリとデータベースモニタリング]** に移動し、**[クエリ履歴]** タブをクリックして、クエリについての情報を確認します。
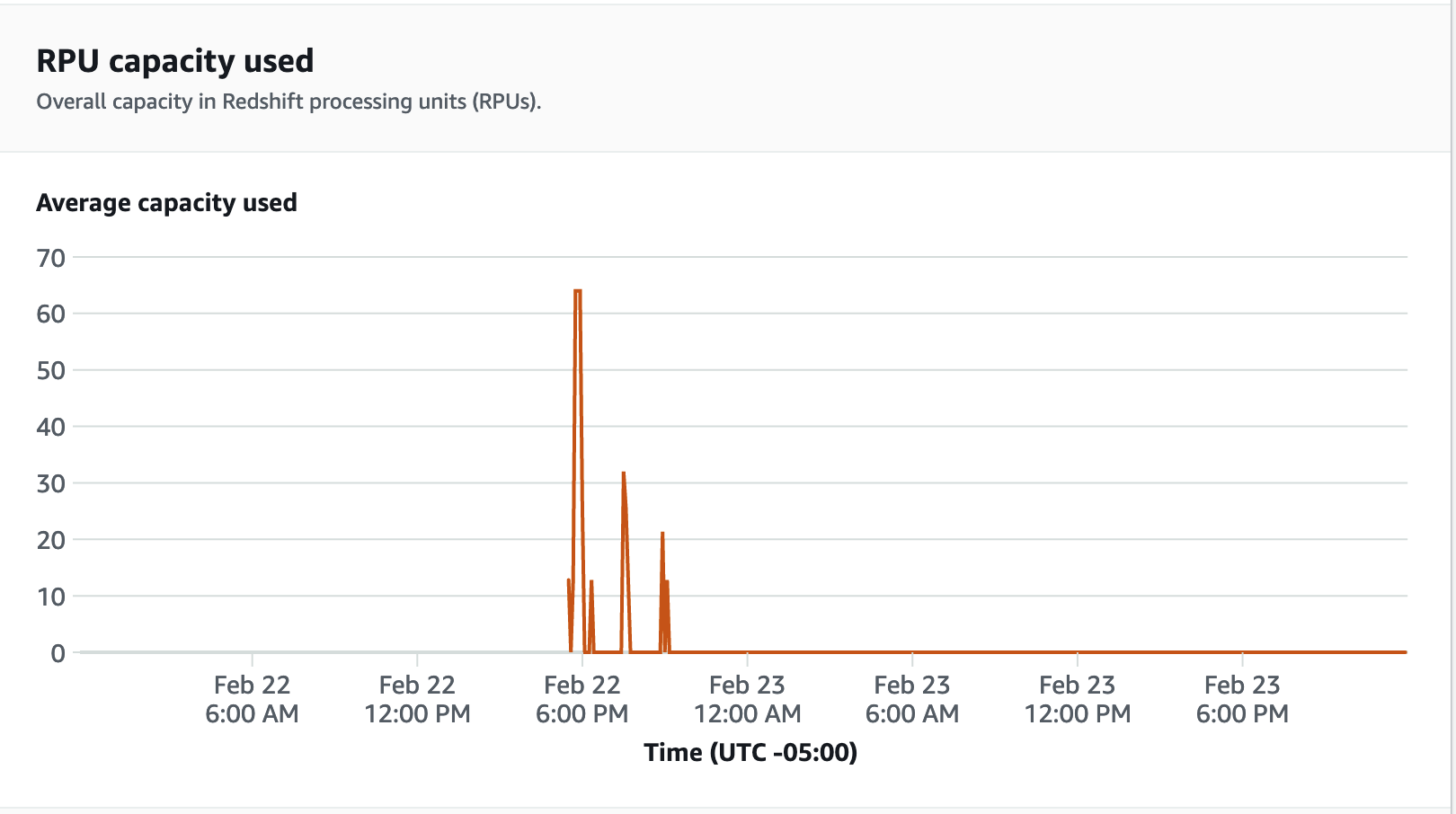
パフォーマンスメトリクスについては、Redshift Serverless コンソールの **[データベースパフォーマンス]** タブをクリックして、**[データベース接続]** や **[CPU 使用率]** などのメトリクスをモニタリングします。このタブでは、使用されている RPU 容量をモニタリングするグラフを表示して、ワークグループでの負荷テスト実行中に、Redshift Serverless が同時ワークロードの需要を満たすために自動的にスケールしているのを確認できます。
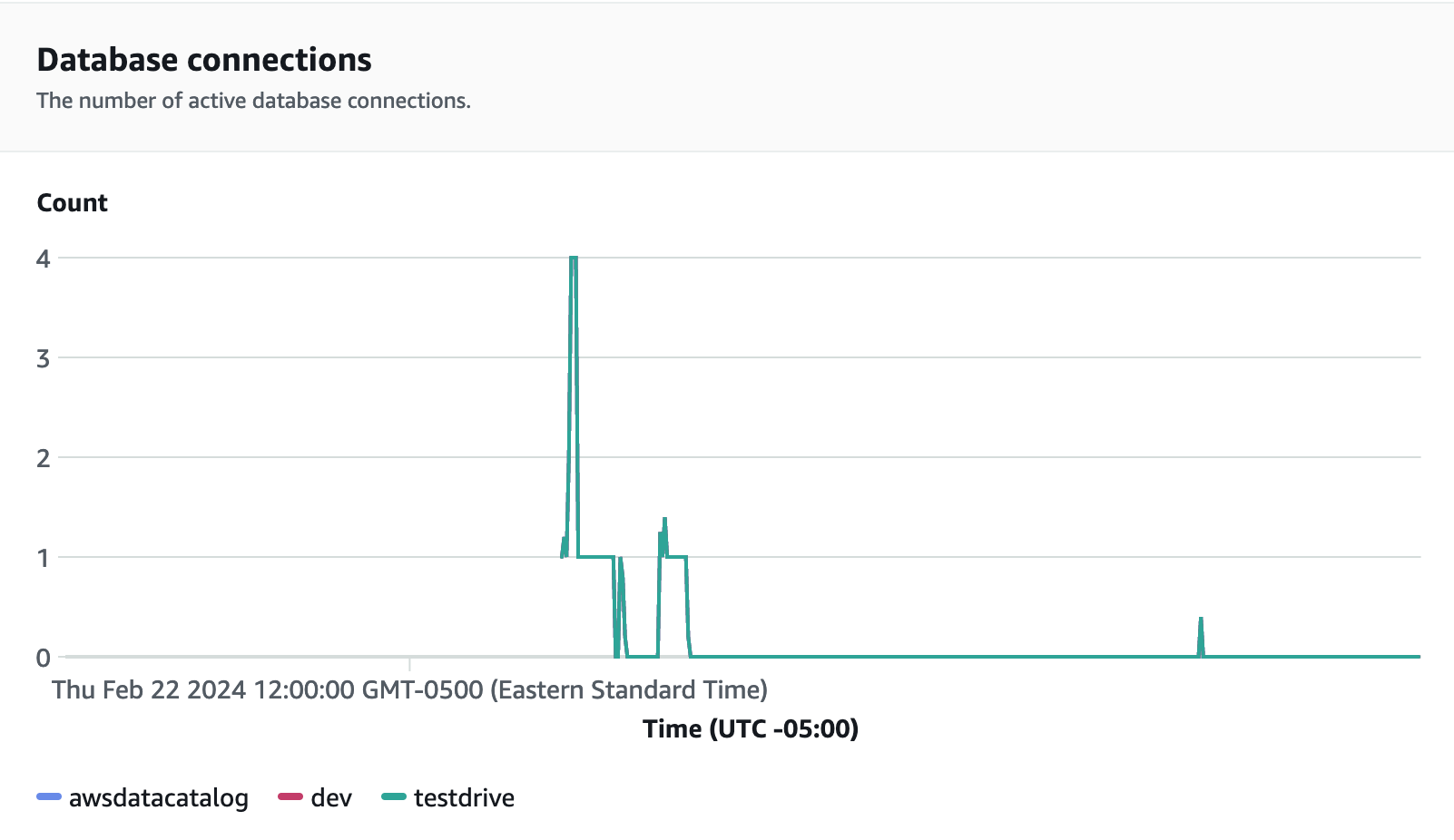
負荷テストの実行中にモニタリングすべきもう 1 つの有用なメトリクスに、データベース接続があります。増加するワークロード需要に対応するために、ワークグループが特定の時点で一度に多数の同時接続を処理しているのを確認できます。
## ステップ 5: 最適化する

Amazon Redshift は、個別のユースケースをサポートするさまざまな設定と機能を提供しており、毎日数万人ものユーザーがエクサバイトのデータを処理することができます。Amazon Redshift は、このような分析ワークロードを支える基盤となっています。さまざまなオプションの中から選択する際、お客様は Amazon Redshift ワークロードをサポートするための最適なデータウェアハウス設定を決定するうえで役立つツールを求めています。
### Test Drive
[Test Drive](https://github.com/aws/redshift-test-drive/tree/main) を利用すると、既存のワークロードに対して考えうる設定で自動再生を行い、対応する出力を分析し、ワークロードの移行先として最適なターゲットを評価できます。Test Drive を使用してさまざまな Amazon Redshift の設定を評価する方法については、「[Redshift Test Drive を使用してワークロードに最適な Amazon Redshift の設定を判断する](https://aws.amazon.com/blogs/big-data/find-the-best-amazon-redshift-configuration-for-your-workload-using-redshift-test-drive/)」を参照してください。