翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
RAG ワークフローのリトリーバー
このセクションでは、リトリーバーを構築する方法について説明します。Amazon Kendra などのフルマネージド型のセマンティック検索ソリューションを使用することも、 AWS ベクトルデータベースを使用してカスタムセマンティック検索を構築することもできます。
リトリーバーオプションを確認する前に、ベクトル検索プロセスの 3 つのステップを理解していることを確認してください。
-
インデックス作成する必要があるドキュメントを小さな部分に分割します。これはチャンキングと呼ばれます。
-
埋め込み
と呼ばれるプロセスを使用して、各チャンクを数学ベクトルに変換します。次に、ベクトルデータベース内の各ベクトルのインデックスを作成します。ドキュメントのインデックス作成に使用するアプローチは、検索の速度と精度に影響します。インデックス作成のアプローチは、ベクトルデータベースとそれが提供する設定オプションによって異なります。 -
ユーザークエリをベクトルに変換するには、同じプロセスを使用します。リトリーバーは、ユーザーのクエリベクトルに似たベクトルをベクトルデータベースで検索します。類似度
は、ユークリッド距離、コサイン距離、ドット積などのメトリクスを使用して計算されます。
このガイドでは、以下の AWS のサービス またはサードパーティーのサービスを使用してカスタム取得レイヤーを構築する方法について説明します AWS。
Amazon Kendra
Amazon Kendra は、自然言語処理と高度な機械学習アルゴリズムを使用して、データからの検索質問に対する特定の回答を返す、フルマネージド型のインテリジェントな検索サービスです。Amazon Kendra は、複数のソースからドキュメントを直接取り込み、正常に同期された後にドキュメントをクエリするのに役立ちます。同期プロセスにより、取り込まれたドキュメントでベクトル検索を作成するために必要なインフラストラクチャが作成されます。したがって、Amazon Kendra はベクトル検索プロセスの従来の 3 つのステップを必要としません。最初の同期後、定義されたスケジュールを使用して継続的な取り込みを処理できます。
RAG に Amazon Kendra を使用する利点は次のとおりです。
-
Amazon Kendra はベクトル検索プロセス全体を処理するため、ベクトルデータベースを維持する必要はありません。
-
Amazon Kendra には、データベース、ウェブサイトクローラー、Amazon S3 バケット、Microsoft SharePointインスタンス、Atlassian Confluenceインスタンスなどの一般的なデータソース用の構築済みコネクタが含まれています。Box および のコネクタなど、 AWS パートナーによって開発されたコネクタを使用できますGitLab。
-
Amazon Kendra は、エンドユーザーがアクセスできるドキュメントのみを返すアクセスコントロールリスト (ACL) フィルタリングを提供します。
-
Amazon Kendra は、日付やソースリポジトリなどのメタデータに基づいてレスポンスをブーストできます。
次の図は、RAG システムの取得レイヤーとして Amazon Kendra を使用するサンプルアーキテクチャを示しています。詳細については、「Amazon Kendra、、LangChain大規模言語モデルを使用してエンタープライズデータに高精度の生成 AI アプリケーションをすばやく構築する
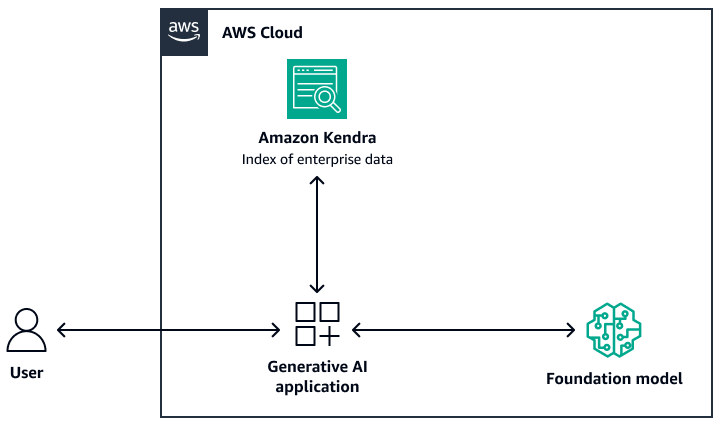
基盤モデルでは、Amazon Bedrock または Amazon SageMaker AI JumpStart を介してデプロイされた LLM を使用できます。 AWS Lambda で を使用してLangChain
Amazon OpenSearch Service
Amazon OpenSearch Service は、ベクトル検索を実行するために、K 最近傍 (k-NN)
ベクトル検索に OpenSearch Service を使用する利点は次のとおりです。
-
OpenSearch Serverless を使用してスケーラブルなベクトル検索を構築するなど、ベクトルデータベースを完全に制御できます。
-
これにより、チャンキング戦略を制御できます。
-
非メトリクススペースライブラリ (NMSLIB)、Faiss、Apache Lucene ライブラリからの近似近傍 (ANN)
アルゴリズムを使用して、k-NN 検索を強化します。 https://github.com/facebookresearch/faiss https://lucene.apache.org/ ユースケースに基づいてアルゴリズムを変更できます。OpenSearch Service を使用してベクトル検索をカスタマイズするためのオプションの詳細については、「Amazon OpenSearch Service のベクトルデータベース機能の説明 」(AWS ブログ記事) を参照してください。 -
OpenSearch Serverless は、ベクトルインデックスとして Amazon Bedrock ナレッジベースと統合されます。
Amazon Aurora PostgreSQL と pgvector
Amazon Aurora PostgreSQL 互換エディションは、PostgreSQL デプロイのセットアップ、運用、スケーリングに役立つフルマネージドのリレーショナルデータベースエンジンです。pgvector
pgvector と Aurora PostgreSQL 互換を使用する利点は次のとおりです。
-
近傍検索と近似近傍検索をサポートしています。また、L2 距離、内部積、コサイン距離の類似度メトリクスもサポートしています。
-
フラット圧縮 (IVFFlat) および階層ナビゲーション可能なスモールワールド (HNSW) インデックスを持つ反転ファイル
をサポートしています。 https://github.com/pgvector/pgvector#hnsw -
ベクトル検索を、同じ PostgreSQL インスタンスで利用可能なドメイン固有のデータに対するクエリと組み合わせることができます。
-
Aurora PostgreSQL 互換 は I/O 用に最適化されており、階層型キャッシュを提供します。使用可能なインスタンスメモリを超えるワークロードの場合、pgvector はベクトル検索のクエリを 1 秒あたり最大 8 回まで増やすことができます。
Amazon Neptune Analytics
Amazon Neptune Analytics は、分析用のメモリ最適化グラフデータベースエンジンです。グラフトラバーサル内の最適化されたグラフ分析アルゴリズム、低レイテンシーのグラフクエリ、ベクトル検索機能のライブラリをサポートしています。また、ベクトル類似度検索が組み込まれています。グラフの作成、データのロード、クエリの呼び出し、ベクトル類似度検索を実行する 1 つのエンドポイントを提供します。Neptune Analytics を使用する RAG ベースのシステムを構築する方法の詳細については、「ナレッジグラフを使用して Amazon Bedrock と Amazon Neptune で GraphRAG アプリケーションを構築する
Neptune Analytics を使用する利点は次のとおりです。
-
埋め込みをグラフクエリに保存および検索できます。
-
Neptune Analytics を と統合する場合LangChain、このアーキテクチャは自然言語グラフクエリをサポートします。
-
このアーキテクチャは、大きなグラフデータセットをメモリに保存します。
Amazon MemoryDB
Amazon MemoryDB は、超高速のパフォーマンスを提供する耐久性の高いインメモリデータベースサービスです。すべてのデータはメモリに保存され、マイクロ秒の読み取り、1 桁ミリ秒の書き込みレイテンシー、高スループットをサポートします。MemoryDB のベクトル検索は MemoryDB の機能を拡張し、既存の MemoryDB 機能と組み合わせて使用できます。詳細については、GitHub の「LLM および RAG リポジトリを使用した質問への回答
次の図は、MemoryDB をベクトルデータベースとして使用するサンプルアーキテクチャを示しています。
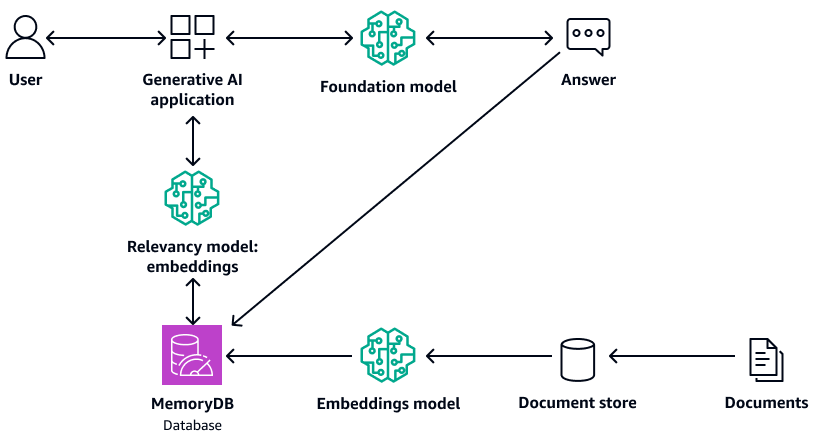
MemoryDB を使用する利点は次のとおりです。
-
フラットインデックス作成アルゴリズムと HNSW インデックス作成アルゴリズムの両方をサポートしています。詳細については、「 AWS ニュースブログ」の「Amazon MemoryDB のベクトル検索が一般公開されました
」を参照してください。 -
また、基盤モデルのバッファメモリとしても機能します。つまり、以前に回答した質問は、取得および生成プロセスを繰り返すのではなく、バッファから取得されます。以下の図はこのプロセスを示しています。
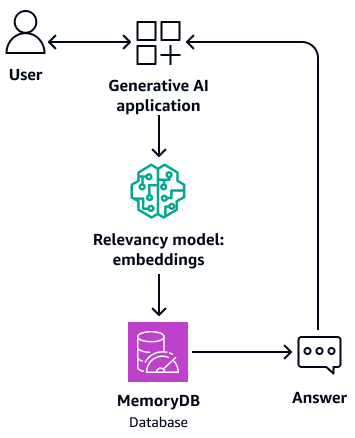
-
インメモリデータベースを使用するため、このアーキテクチャはセマンティック検索に 1 桁ミリ秒のクエリ時間を提供します。
-
95~99% の再現率で 1 秒あたり最大 33,000 件のクエリを提供し、99% を超える再現率で 1 秒あたり最大 26,500 件のクエリを提供します。詳細については、AWS 「re:Invent 2023 - Ultra-low latency vector search for Amazon MemoryDB
video on 」を参照してくださいYouTube。
Amazon DocumentDB
Amazon DocumentDB (MongoDB 互換) は、高速で信頼性の高いフルマネージドデータベースサービスです。クラウドで MongoDB互換データベースを簡単にセットアップ、運用、スケーリングできます。Amazon DocumentDB のベクトル検索は、JSON ベースのドキュメントデータベースの柔軟性と豊富なクエリ機能とベクトル検索の能力を組み合わせています。詳細については、GitHub の「LLM および RAG リポジトリを使用した質問への回答
次の図は、Amazon DocumentDB をベクトルデータベースとして使用するサンプルアーキテクチャを示しています。
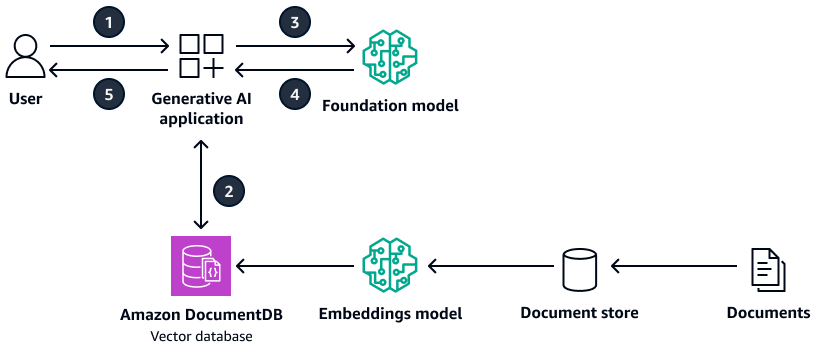
この図表は、次のワークフローを示しています:
-
ユーザーは生成 AI アプリケーションにクエリを送信します。
-
生成 AI アプリケーションは、Amazon DocumentDB ベクトルデータベースで類似度検索を実行し、関連するドキュメント抽出を取得します。
-
生成 AI アプリケーションは、取得したコンテキストでユーザークエリを更新し、ターゲット基盤モデルにプロンプトを送信します。
-
基盤モデルは、コンテキストを使用してユーザーの質問に対するレスポンスを生成し、レスポンスを返します。
-
生成 AI アプリケーションは、ユーザーにレスポンスを返します。
Amazon DocumentDB を使用する利点は次のとおりです。
-
HNSW と IVFFlat の両方のインデックス作成メソッドをサポートしています。
-
ベクトルデータで最大 2,000 のディメンションをサポートし、ユークリッド、コサイン、ドット積の距離メトリクスをサポートします。
-
ミリ秒の応答時間を提供します。
Pinecone
Pinecone
次の図は、 をベクトルデータベースPineconeとして使用するアーキテクチャの例を示しています。
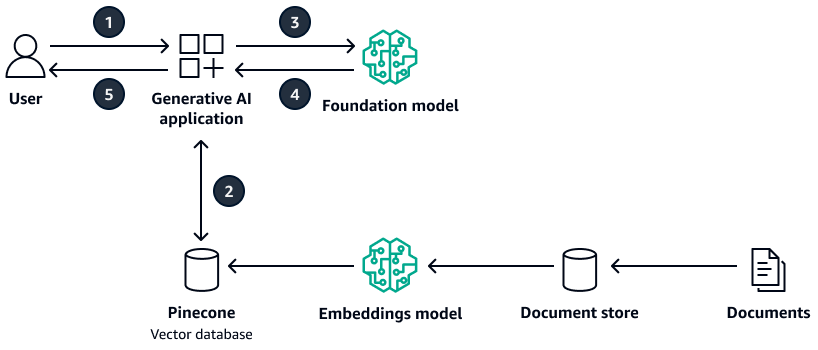
この図表は、次のワークフローを示しています:
-
ユーザーは生成 AI アプリケーションにクエリを送信します。
-
生成 AI アプリケーションは、Pineconeベクトルデータベースで類似度検索を実行し、関連するドキュメント抽出を取得します。
-
生成 AI アプリケーションは、取得したコンテキストでユーザークエリを更新し、ターゲット基盤モデルにプロンプトを送信します。
-
基盤モデルは、コンテキストを使用してユーザーの質問に対するレスポンスを生成し、レスポンスを返します。
-
生成 AI アプリケーションは、ユーザーにレスポンスを返します。
を使用する利点は次のとおりですPinecone。
-
これはフルマネージド型のベクトルデータベースであり、独自のインフラストラクチャを管理するオーバーヘッドを排除します。
-
フィルタリング、ライブインデックスの更新、キーワードブースト (ハイブリッド検索) の追加機能を提供します。
MongoDB Atlas
MongoDB Atlas
RAG のMongoDB Atlasベクトル検索の使用方法の詳細については、「 を使用した検索拡張生成LangChain」、Amazon SageMaker AI JumpStart」、およびMongoDB Atlas「セマンティック検索
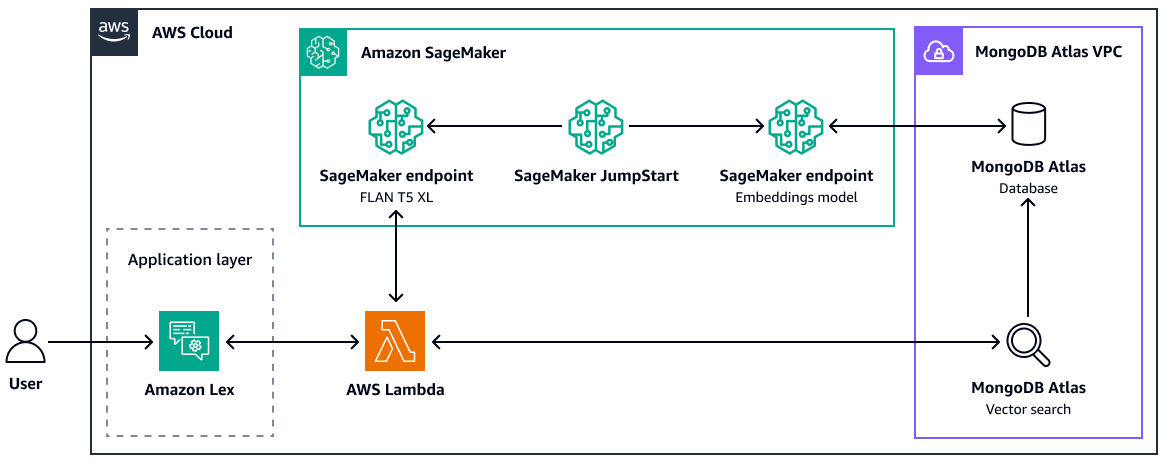
MongoDB Atlas ベクトル検索を使用する利点は次のとおりです。
-
の既存の実装を使用してMongoDB Atlas、ベクトル埋め込みを保存および検索できます。
-
MongoDB Query API
を使用して、ベクトル埋め込みをクエリできます。 -
ベクトル検索とデータベースは個別にスケールできます。
-
ベクトル埋め込みはソースデータ (ドキュメント) の近くに保存されるため、インデックス作成のパフォーマンスが向上します。
Weaviate
Weaviate
を使用する利点は次のとおりですWeaviate。
-
これはオープンソースであり、強力なコミュニティに支えられています。
-
ハイブリッド検索 (ベクトルとキーワードの両方) 用に構築されています。
-
AWS マネージド Software as a Service (SaaS) サービスまたは Kubernetes クラスターとして にデプロイできます。
