翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Bedrock と Amazon Transcribe を使用して音声入力から組織の知識を文書化する
Amazon Web Services、Praveen Kumar Jeyarajan、Jundong Qiao、Rajiv Upadhyay、Megan Wu
概要
組織の成功とレジリエンスを確保するためには、組織の知識を記録することが最優先事項です。組織の知識とは、従業員が長期にわたって蓄積した集合的な知恵、インサイト、経験のことで、多くの場合は本質的に暗黙的で、非公式に受け継がれます。この豊富な情報には、他では文書化されていないような複雑な問題に対する独自のアプローチ、ベストプラクティス、解決策が含まれています。この知識を形式化して文書化することにより、企業は組織の記憶を保持し、イノベーションを促進し、意思決定プロセスを強化し、新入社員の学習曲線を加速させることができます。さらに、連携を促進し、個人に権限を与え、継続的な改善の文化を育みます。組織の知識を活用すると、最終的に、企業は最も重要なアセットである従業員の集合的インテリジェンスに基づいて、課題を乗り越え、成長を促進し、動的なビジネス環境で競争上の優位性を維持することができます。
このパターンでは、上級従業員からの音声記録を通じて組織の知識を記録する方法について説明します。Amazon Transcribe と Amazon Bedrock を使用して、体系的な文書化と検証を行います。この非公式な知識を文書化することにより、知識を保存し、後続の従業員の仲間と共有することができます。この取り組みは、運用上の優秀性をサポートするものであり、直接的な経験を通じて獲得した実践的な知識を組み込むことにより、トレーニングプログラムの有効性を向上させます。
前提条件と制限
前提条件
アクティブなAWS アカウント
Docker がインストールされていること
AWS Cloud Development Kit (AWS CDK) バージョン 2.114.1 以降が
us-east-1またはus-west-2AWS リージョンにインストールおよびブートストラップされていることAWS CDK ツールキットバージョン 2.114.1 以降がインストールされていること
Python バージョン 3.12 以降がインストールされていること
Amazon Transcribe、Amazon Bedrock、Amazon Simple Storage Service (Amazon S3)、および AWS Lambda リソースを作成するためのアクセス権限
制限
このソリューションは単一 AWS アカウントにデプロイされます。
このソリューションは、Amazon Bedrock と Amazon Transcribe が利用可能な AWS リージョンでのみデプロイできます。詳細は、Amazon Bedrock と Amazon Transcribe のドキュメントを参照してください。
オーディオファイルは、Amazon Transcribe がサポートする形式である必要があります。サポートされている形式のリストについては、Transcribe ドキュメントの「Media formats」を参照してください。
製品バージョン
AWS SDK for Python (Boto3) バージョン 1.34.57 以降
LangChain バージョン 0.1.12 以降
アーキテクチャ
アーキテクチャは、AWS でのサーバーレスワークフローを表します。AWS Step Functions は、オーディオ処理、テキスト分析、ドキュメント生成のために Lambda 関数を調整します。次の図に、ステートマシンとも呼ばれる Step Functions ワークフローを示します。
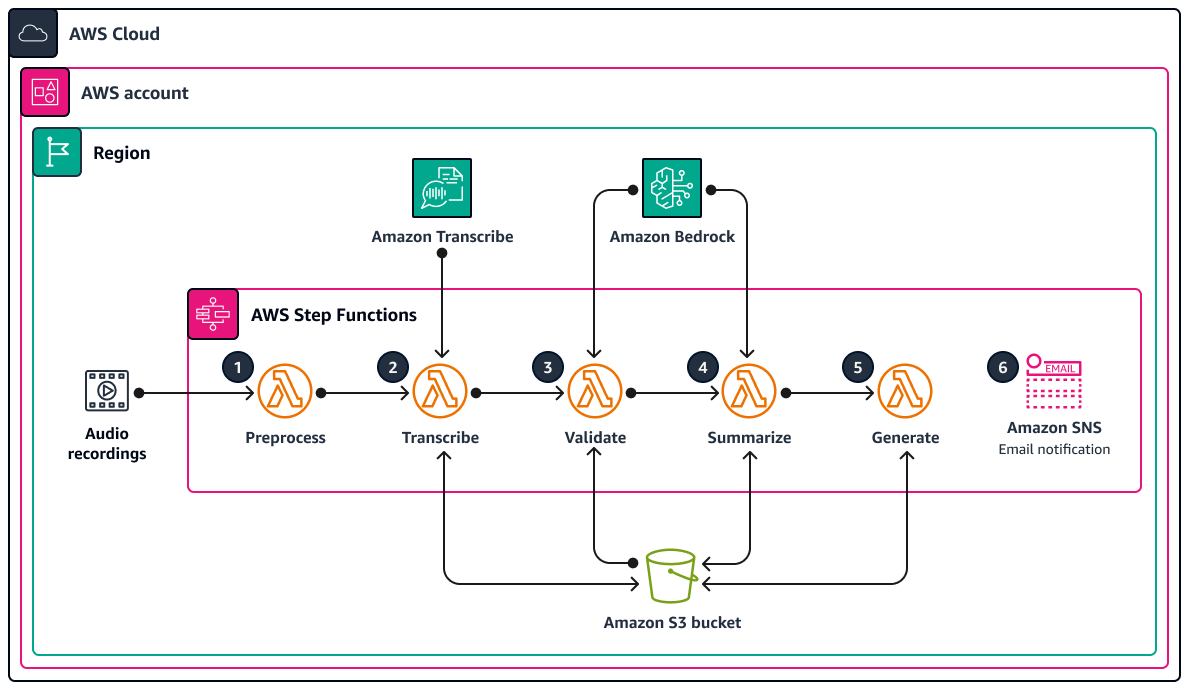
ステートマシンの各ステップは、個別の Lambda 関数によって処理されます。ドキュメント生成プロセスの手順は次のとおりです。
preprocessLambda 関数が、Step Functions に渡された入力を検証し、提供された Amazon S3 URI フォルダパスに存在するすべてのオーディオファイルを一覧表示します。ワークフローのダウンストリーム Lambda 関数は、ファイルリストを使用してドキュメントを検証、要約、生成します。transcribeLambda 関数が Amazon Transcribe を使用してオーディオファイルをテキストトランスクリプトに変換します。この Lambda 関数は、文字起こしプロセスを開始し、スピーチをテキストに正確に変換し、後続の処理のために保存します。validateLambda 関数がテキストトランスクリプトを分析し、最初の質問に対する応答の関連性を判断します。Amazon Bedrock で大規模言語モデル (LLM) を使用することにより、トピック関連の回答を特定してトピック外の回答から分離します。summarizeLambda 関数が Amazon Bedrock を使用して、トピック関連の回答の一貫した簡潔な概要を生成します。generateLambda 関数が、概要を構造化されたドキュメントにアセンブルします。事前定義されたテンプレートに従ってドキュメントをフォーマットし、追加の必要なコンテンツやデータを含めることができます。いずれかの Lambda 関数が失敗すると、Amazon Simple Notification Service (Amazon SNS) から E メール通知が送信されます。
このプロセス全体をとおして、AWS Step Functions は各 Lambda 関数が正しい順序で開始されることを確認します。このステートマシンでは、効率を向上させるための並列処理が可能です。Amazon S3 バケットは中央ストレージリポジトリとして機能し、関連するさまざまなメディアおよびドキュメント形式を管理することでワークフローをサポートします。
ツール
AWS サービス
Amazon Bedrock は、主要な AI スタートアップ企業や Amazon が提供する高パフォーマンスな基盤モデル (FM) を、統合 API を通じて利用できるようにするフルマネージド型サービスです。
AWS Lambda は、サーバーのプロビジョニングや管理を行うことなくコードを実行できるコンピューティングサービスです。必要に応じてコードを実行し、自動的にスケーリングするため、課金は実際に使用したコンピューティング時間に対してのみ発生します。
「Amazon Simple Notification Service (Amazon SNS)」は、ウェブサーバーやメールアドレスなど、パブリッシャーとクライアント間のメッセージの交換を調整および管理するのに役立ちます。
Amazon Simple Storage Service (Amazon S3) は、量にかかわらず、データを保存、保護、取得する上で役立つクラウドベースのオブジェクトストレージサービスです。
AWS Step Functionsは、AWS Lambda関数と他のAWS サービスを組み合わせてビジネスクリティカルなアプリケーションを構築できるサーバーレスオーケストレーションサービスです。
Amazon Transcribe は、機械学習モデルを使用して音声をテキストに変換する自動音声認識サービスです。
その他のツール
LangChain
は、言語モデル (LLM) を利用するアプリケーションを開発するためのフレームワークです。
コードリポジトリ
このパターンのコードは、GitHub の genai-knowledge-capture
コードリポジトリには以下のファイルとフォルダが含まれています。
assetsフォルダ - アーキテクチャ図やパブリックデータセットなど、ソリューションの静的アセットcode/lambdasフォルダ - すべての Lambda 関数のための Python コードcode/lambdas/generateフォルダ - S3 バケット内の要約データからドキュメントを生成する Python コードcode/lambdas/preprocessフォルダ - Step Functions ステートマシンの入力を処理する Python コードcode/lambdas/summarizeフォルダ - Amazon Bedrock サービスを使用して文字起こしデータを要約する Python コードcode/lambdas/transcribeフォルダ - Amazon Transcribe を使用してスピーチデータ (オーディオファイル) をテキストに変換する Python コードcode/lambdas/validateフォルダ - すべての回答が同じトピックに関連しているかどうかを検証する Python コード
code/code_stack.py- AWS リソースの作成に使用される AWS CDK コンストラクト Python ファイルapp.py- ターゲット AWS アカウントで AWS リソースをデプロイするために使用される AWS CDK アプリケーション Python ファイルrequirements.txt- AWS CDK のためにインストールする必要があるすべての Python 依存関係のリストcdk.json- リソースの作成に必要な値を提供する入力ファイル
ベストプラクティス
ここに示すコード例は、PoC (概念実証) またはパイロットのみを目的としています。ソリューションを本番環境に移行する場合は、次のベストプラクティスに従ってください。
Amazon S3 アクセスログを有効にする
VPC フローログを有効にする
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
アカウントと AWS リージョンの変数をエクスポートする。 | 環境変数を使用して AWS CDK の AWS 認証情報を提供するには、次のコマンドを実行します。
| AWS DevOps、DevOps エンジニア |
AWS CLI 名前付きプロファイルをセットアップする。 | アカウントに AWS CLI 名前付きプロファイルをセットアップするには、「Configuration and credential file settings」の手順に従います。 | AWS DevOps、DevOps エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
ローカルワークステーションにリポジトリのクローンを作成する。 | genai-knowledge-capture
| AWS DevOps、DevOps エンジニア |
(オプション) オーディオファイルを置き換える。 | サンプルアプリケーションをカスタマイズして独自のデータを組み込むには、以下を実行します。
| AWS DevOps、DevOps エンジニア |
Python 仮想環境をセットアップする。 | Python 仮想環境をセットアップするには、次のコマンドを実行します。
| AWS DevOps、DevOps エンジニア |
AWS CDK コードを合成する。 | コードを AWS CloudFormation スタック設定に変換するには、次のコマンドを実行します。
| AWS DevOps、DevOps エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
基盤モデルアクセスをプロビジョニングする。 | AWS アカウントの Anthropic Claude 3 Sonnet モデルへのアクセスを有効にします。手順については、Bedrock ドキュメントの「Add model access」を参照してください。 | AWS DevOps |
アカウントにリソースをデプロイします。 | AWS CDK を使用して AWS アカウントでリソースをデプロイするには、以下を実行します。
| AWS DevOps、DevOps エンジニア |
Amazon SNS トピックを購読します。 | 通知用に Amazon SNS トピックを登録するには、次の手順を実行します。
| AWS 全般 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
ステートマシンを実行します。 |
| アプリ開発者、AWS 全般 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
AWS リソースを削除します。 | ソリューションをテストしたら、リソースをクリーンアップします。
| AWS DevOps、DevOps エンジニア |
関連リソース
AWS ドキュメント
Tag Amazon Bedrock リソース:
AWS CDK リソース:
AWS Step Functions リソース:
その他のリソース
