翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Bedrock エージェントとナレッジベースを使用して、完全に自動化したチャットベースのアシスタントを開発する
Amazon Web Services、Jundong Qiao、Shuai Cao、Noah Hamilton、Kioua Jackson、Praveen Kumar Jeyarajan、Kara Yang
概要
多くの組織が、包括的な回答を提供するために多様なデータソースをオーケストレーションできるチャットベースのアシスタントを作成する際に課題に直面します。このパターンでは、簡単なデプロイによりドキュメントとデータベースの両方からクエリに回答できるチャットベースのアシスタントを開発するためのソリューションを示します。
このフルマネージド生成 AI サービスは、Amazon Bedrock をはじめとして、さまざまな高度な基盤モデル (FM) を提供しています。これにより、プライバシーとセキュリティに重点を置いた生成 AI アプリケーションを簡単に効率よく作成できます。ドキュメントの取得において、検索拡張生成 (RAG) は重要な機能です。ナレッジベースを使用して、外部ソースからのコンテキストに関連する情報で FM プロンプトを補強します。Amazon OpenSearch Serverless インデックスは、Amazon Bedrock ナレッジベースの背後にあるベクトルデータベースとして機能します。この統合は、不正確さを最小限に抑え、応答が事実関係のドキュメントに確実に基づくようにするための慎重なプロンプトエンジニアリングによって強化されます。データベースクエリの場合、Amazon Bedrock の FM により、テキストクエリが構造化された SQL クエリに変換され、特定のパラメータが組み込まれます。これにより、データベースによって管理されるAWS Glue データベースからデータを正確に取得できます。これらのクエリには Amazon Athena が使用されます。
より複雑なクエリを処理し、包括的な回答を得るには、ドキュメントとデータベースの両方から取得された情報が必要です。Amazon Bedrock エージェント は、複雑なタスクを理解し、オーケストレーションのためによりシンプルなタスクに分割できる自律型エージェントを構築するのに役立つ生成 AI 機能です。簡素化されたタスクから取得されるインサイトが Amazon Bedrock の自律型エージェントによって結び付けられることにより、情報の合成が強化され、より詳細で包括的な回答が得られます。このパターンでは、Amazon Bedrock および関連する生成 AI サービスと自動ソリューション内の機能を使用してチャットベースのアシスタントを構築する方法を説明します。
前提条件と制限
前提条件
アクティブな AWS アカウント
Docker がインストールされていること
AWS Cloud Development Kit (AWS CDK)、
us-east-1または にインストールおよびブートストラップus-west-2AWS リージョンAWS CDK Toolkit バージョン 2.114.1 以降、インストール済み
Python バージョン 3.11 以降がインストールされていること
Amazon Bedrock で、Claude 2、Claude 2.1、Claude Instant、Titan Embeddings G1 – Text へのアクセスを有効にすること
制限事項
このソリューションは 1 つの にデプロイされます AWS アカウント。
このソリューションは、Amazon Bedrock と Amazon OpenSearch Serverless がサポートされている AWS リージョン でのみデプロイできます。詳細は、Amazon Bedrock ドキュメントおよび Amazon OpenSearch Serverless ドキュメントを参照してください。
製品バージョン
Llama-index バージョン 0.10.6 以降
Sqlalchemy バージョン 2.0.23 以降
Opensearch-py バージョン 2.4.2 以降
Requests_aws4auth バージョン 1.2.3 以降
AWS SDK for Python (Boto3) バージョン 1.34.57 以降
アーキテクチャ
ターゲットテクノロジースタック
AWS Cloud Development Kit (AWS CDK) は、コードでクラウドインフラストラクチャを定義し、それをプロビジョニングするためのオープンソースのソフトウェア開発フレームワークです AWS CloudFormation。このパターンで使用される AWS CDK スタックは、次の AWS リソースをデプロイします。
AWS Key Management Service (AWS KMS)
Amazon Simple Storage Service (Amazon S3)
AWS Glue Data Catalog AWS Glue データベースコンポーネントの 。
AWS Lambda
AWS Identity and Access Management (IAM)
Amazon OpenSearch Serverless
Amazon Elastic Container Registry (Amazon ECR)
Amazon Elastic Container Service (Amazon ECS)
AWS Fargate
Amazon Virtual Private Cloud (Amazon VPC)
ターゲット アーキテクチャ
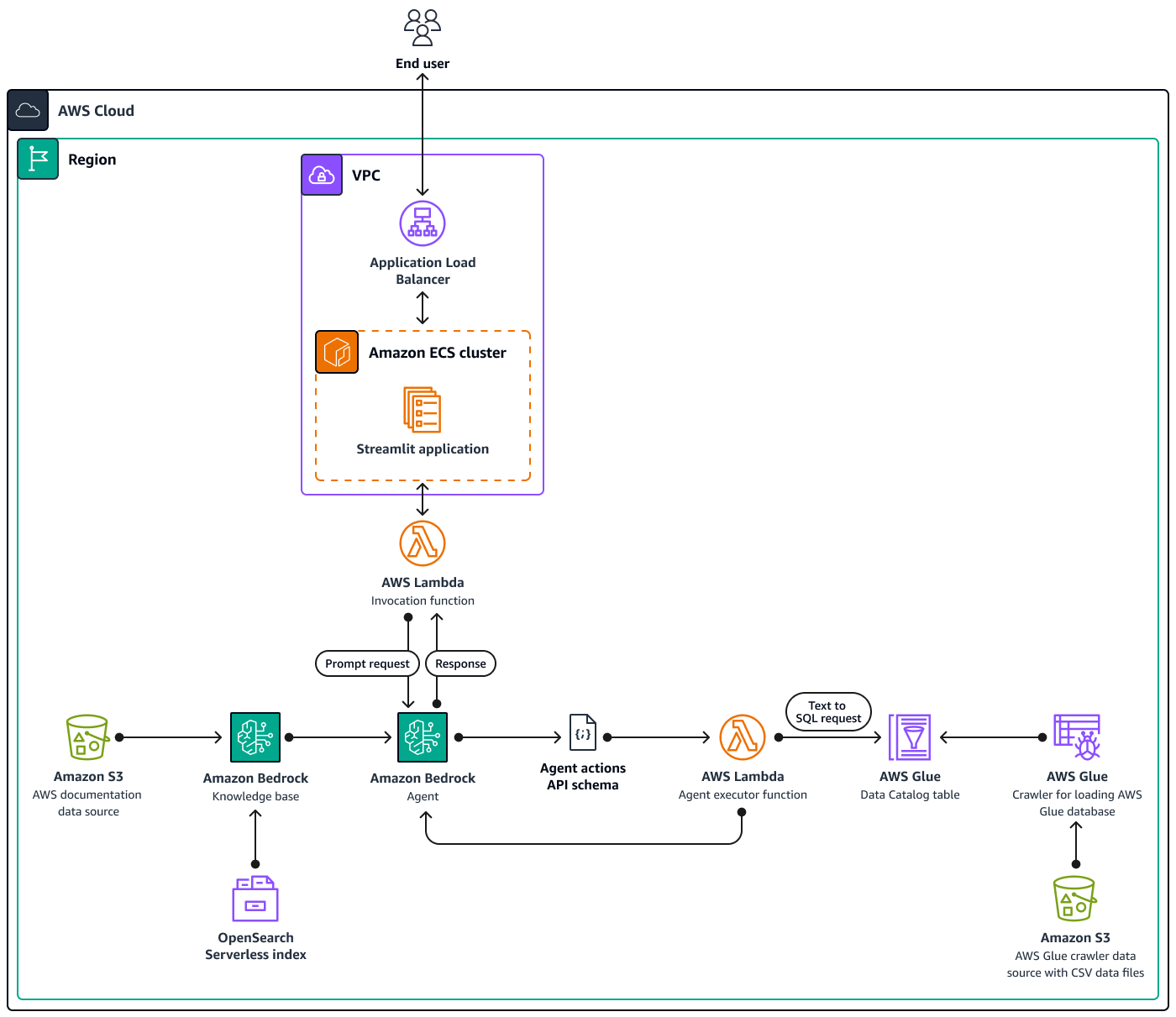
この図は、複数の を使用した AWS リージョン、単一の 内の包括的な AWS クラウドネイティブセットアップを示しています AWS のサービス。チャットベースのアシスタントの主なインターフェイスは、Amazon ECS クラスターでホストされている StreamlitInvocation Lambda 関数をアクティブ化し、それによって Amazon Bedrock エージェントとのインターフェイスが行われます。このエージェントは、Amazon Bedrock ナレッジベースを参照するか、Agent executor Lambda 関数を呼び出して、ユーザーの問い合わせに応答します。この関数は、事前定義された API スキーマに従って、エージェントに関連付けられた一連のアクションをトリガーします。Amazon Bedrock ナレッジベースは、OpenSearch Serverless インデックスをベクトルデータベース基盤として使用します。さらに、Agent executor関数は Amazon Athena を介して AWS Glue データベースに対して実行される SQL クエリを生成します。
ツール
AWS のサービス
Amazon Athenaは、標準 SQL を使用して Amazon Simple Storage Service (Amazon S3) 内のデータを直接分析できるようにするインタラクティブなクエリサービスです。
Amazon Bedrock は、主要な AI スタートアップ企業や Amazon が提供する高パフォーマンスな基盤モデル (FM) を、統合 API を通じて利用できるようにするフルマネージド型サービスです。
AWS Cloud Development Kit (AWS CDK) は、 AWS クラウドインフラストラクチャをコードで定義してプロビジョニングするのに役立つソフトウェア開発フレームワークです。
AWS Command Line Interface (AWS CLI) は、コマンドラインシェルのコマンド AWS のサービス を使用して を操作するのに役立つオープンソースツールです。
「Amazon Elastic Container Service (Amazon ECS)」 は、クラスターでのコンテナの実行、停止、管理を支援する、高速でスケーラブルなコンテナ管理サービスです。
受信したアプリケーションまたはネットワークトラフィックを複数のターゲットに分散するには、Elastic Load Balancing を使用します。例えば、1 つまたは複数のアベイラビリティーゾーンの Amazon Elastic Compute Cloud (Amazon EC2) インスタンス、コンテナ、および IP アドレスにトラフィックを分散できます。
AWS Glue は、フルマネージド型の抽出、変換、ロード (ETL) サービスです。これにより、データストアとデータストリーム間でのデータの分類、整理、強化、移動を確実に行うことができます。このパターンでは、 クローラと AWS Glue AWS Glue Data Catalog テーブルを使用します。
AWS Lambda は、サーバーのプロビジョニングや管理を行うことなくコードを実行できるコンピューティングサービスです。必要に応じてコードを実行し、自動的にスケーリングするため、課金は実際に使用したコンピューティング時間に対してのみ発生します。
Amazon OpenSearch Serverless は、Amazon OpenSearch Service 用のオンデマンドサーバーレス設定です。このパターンでは、OpenSearch Serverless インデックスは Amazon Bedrock ナレッジベースのベクトルデータベースとして機能します。
Amazon Simple Storage Service (Amazon S3) は、あらゆる量のデータを保存、保護、取得できるクラウドベースのオブジェクトストレージサービスです。
その他のツール
Streamlit
は、データアプリケーションを作成するためのオープンソースの Python フレームワークです。
コードリポジトリ
このパターンのコードは、GitHub の genai-bedrock-agent-chatbot
assetsフォルダ – アーキテクチャ図やパブリックデータセットなどの静的アセット。code/lambdas/action-lambdaフォルダ – Amazon Bedrock エージェントのアクションとして機能する Lambda 関数の Python コード。code/lambdas/create-index-lambdaフォルダ – OpenSearch Serverless インデックスを作成する Lambda 関数の Python コード。code/lambdas/invoke-lambdaフォルダ – Amazon Bedrock エージェントを呼び出す Lambda 関数の Python コード。Streamlit アプリケーションから直接呼び出されます。code/lambdas/update-lambdaフォルダ – を介してリソースがデプロイされた後に AWS リソースを更新または削除する Lambda 関数の Python コード AWS CDK。code/layers/boto3_layerフォルダ – すべての Lambda 関数間で共有される Boto3 レイヤーを作成する AWS CDK スタック。code/layers/opensearch_layerフォルダ – インデックスを作成するためのすべての依存関係をインストールする OpenSearch Serverless レイヤーを作成する AWS CDK スタック。code/streamlit-appフォルダ – Amazon ECS のコンテナイメージとして実行される Python コード。code/code_stack.py– AWS リソースを作成する AWS CDK コンストラクト Python ファイル。app.py– ターゲット AWS アカウントに AWS リソースをデプロイする AWS CDK スタック Python ファイル。requirements.txt– にインストールする必要があるすべての Python 依存関係のリスト AWS CDK。cdk.json— リソースの作成に必要な値を提供する入力ファイル。また、context/configフィールドでは、状況に応じてソリューションをカスタマイズできます。カスタマイズの詳細は、「追加情報」セクションを参照してください。
ベストプラクティス
ここに示すコード例は、PoC (概念実証) またはパイロットのみを目的としています。コードを本番環境に移行する場合は、次のベストプラクティスに従ってください。
Amazon S3 アクセスログを有効にする
VPC フローログを有効にする
Lambda 関数のモニタリングとアラートを設定します。詳細については、「Lambda 関数をモニタリングおよびトラブルシューティングする」を参照してください。ベストプラクティスについては、「 AWS Lambda 関数を使用するためのベストプラクティス」を参照してください。
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
アカウントとリージョンの変数をエクスポートする。 | 環境変数 AWS CDK を使用して の AWS 認証情報を提供するには、次のコマンドを実行します。
| AWS DevOps、DevOps エンジニア |
AWS CLI 名前付きプロファイルを設定します。 | アカウント AWS CLI の名前付きプロファイルを設定するには、「設定と認証情報ファイルの設定」の手順に従います。 | AWS DevOps、DevOps エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
ローカルワークステーションにリポジトリのクローンを作成する。 | リポジトリのクローンを作成するには、ターミナルで次のコマンドを実行します。
| DevOps エンジニア、AWS DevOps |
Python 仮想環境をセットアップする。 | Python 仮想環境をセットアップするには、次のコマンドを実行します。
必要な依存関係をセットアップするには、次のコマンドを実行します。
| DevOps エンジニア、AWS DevOps |
AWS CDK 環境をセットアップします。 | コードを AWS CloudFormation テンプレートに変換するには、 コマンドを実行します | AWS DevOps、DevOps エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
アカウントにリソースをデプロイします。 | AWS アカウント を使用して にリソースをデプロイするには AWS CDK、以下を実行します。
デプロイが正常に完了したら、CloudFormation コンソールの出力タブにある URL を使用して、チャットベースのアシスタントアプリケーションにアクセスできます。 | DevOps エンジニア、AWS DevOps |
| タスク | 説明 | 必要なスキル |
|---|---|---|
AWS リソースを削除します。 | ソリューションをテストした後、リソースをクリーンアップするには、 | AWS DevOps、DevOps エンジニア |
関連リソース
AWS ドキュメント
Tag Amazon Bedrock リソース:
AWS CDK リソース:
その他の AWS リソース
その他のリソース
追加情報
チャットベースのアシスタントを独自のデータでカスタマイズする
カスタムデータを統合してソリューションをデプロイするには、以下の構造化されたガイドラインに従ってください。これらのステップは、シームレスで効率的な統合プロセスを実現するように設計されており、カスタムデータを使用して効果的にソリューションをデプロイできます。
ナレッジベースのデータ統合の場合
データ準備
assets/knowledgebase_data_source/ディレクトリの場所を確認します。データセットをこのフォルダに配置します。
設定の調整
cdk.jsonファイルを開きます。context/configure/paths/knowledgebase_file_nameフィールドに移動し、それに応じて更新します。bedrock_instructions/knowledgebase_instructionフィールドに移動し、新しいデータセットの意味合いとコンテキストを正確に反映するように更新します。
構造化データ統合の場合
データの整理
assets/data_query_data_source/ディレクトリにtabular_dataなどのサブディレクトリを作成します。構造化データセット (CSV、JSON、ORC、Parquet などの許容される形式) をこの新しく作成されたサブフォルダに配置します。
既存のデータベースに接続する場合は、
code/lambda/action-lambda/build_query_engine.pyのcreate_sql_engine()関数を更新してデータベースに接続します。
設定とコードの更新
cdk.jsonファイルで、新しいデータパスに合わせてcontext/configure/paths/athena_table_data_prefixフィールドを更新します。データセットに対応する新しい text-to-SQL の例を組み込んで
code/lambda/action-lambda/dynamic_examples.csvを修正します。構造化データセットの属性をミラーリングするように
code/lambda/action-lambda/prompt_templates.pyを修正します。cdk.jsonファイルで、Action groupLambda 関数の目的と機能の説明を記述するようにcontext/configure/bedrock_instructions/action_group_descriptionフィールドを更新します。assets/agent_api_schema/artifacts_schema.jsonファイルに、Action groupLambda 関数の新しい機能の説明を記述します。
一般的な更新
cdk.json ファイルの context/configure/bedrock_instructions/agent_instruction セクションに、新しく統合されたデータを考慮して、Amazon Bedrock エージェントの意図した機能と設計目的の包括的な説明を記述します。
