翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
MyDumper
MyDumper
-
MyDumper は、MySQL データベースの整合性のあるバックアップをエクスポートします。複数の並列スレッドを使用したデータベースのバックアップが可能で、使用可能な CPU コアごとに最大 1 つのスレッドをサポートします。
-
myloader は、MyDumper によって作成されたバックアップファイルを読み取り、ターゲットデータベースインスタンスに接続してから、データベースを復元します。
次の図は、MyDumper バックアップファイルを使用したデータベースの移行に関する大まかな手順を示しています。このアーキテクチャ図には、バックアップファイルをオンプレミスデータセンターから AWS クラウドの EC2 インスタンスに移行するための 3 つのオプションが含まれています。
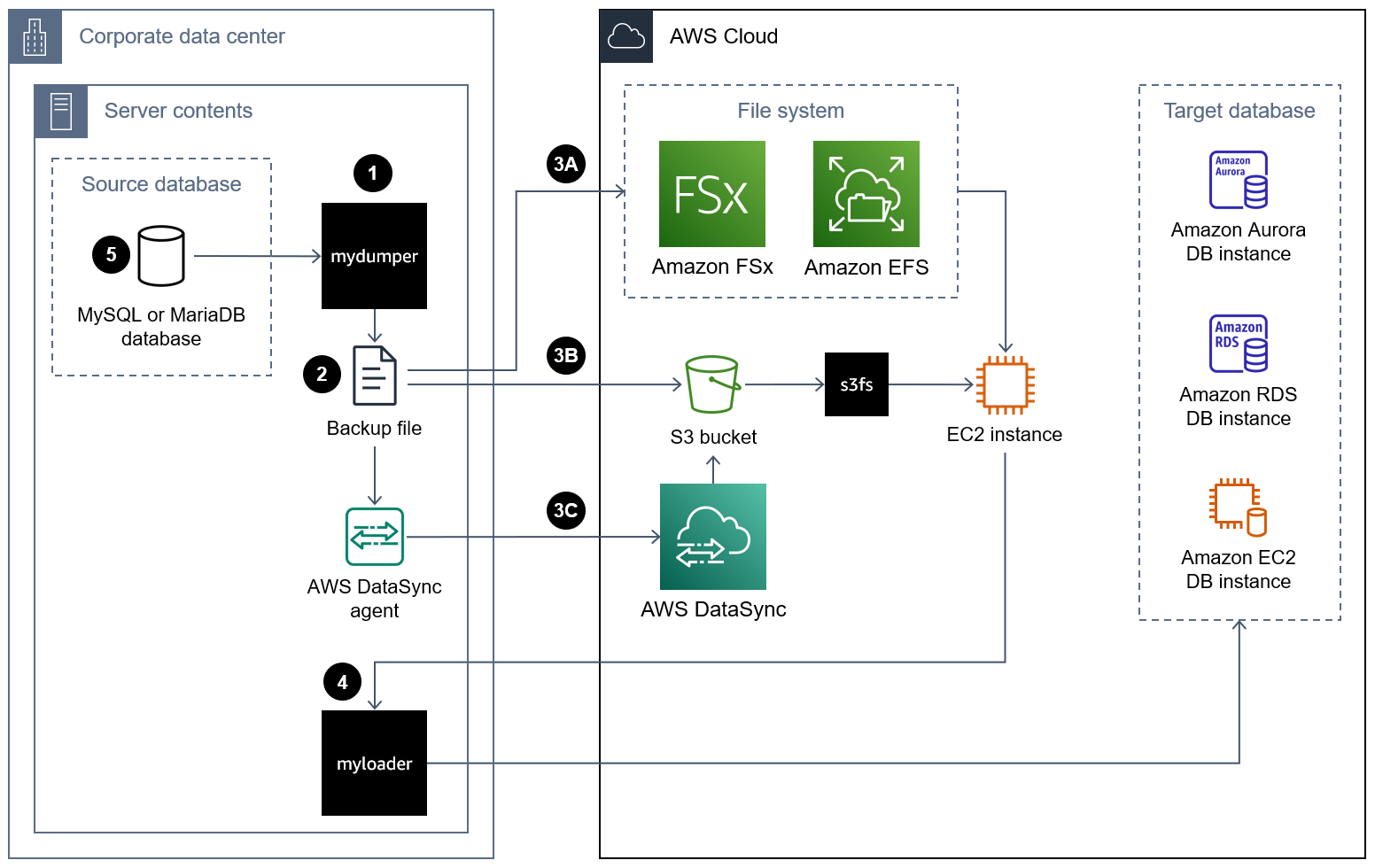
MyDumper を使用してデータベースを AWS クラウドに移行する手順は次のとおりです。
-
MyDumper と myloader をインストールします。手順については、「How to install mydumper/myloader
」(GitHub) を参照してください。 -
MyDumper を使用して、ソース MySQL または MariaDB データベースのバックアップを作成します。手順については、「MyDumper の使用方法
」を参照してください。 -
次のいずれかの方法 AWS クラウド を使用して、バックアップファイルを の EC2 インスタンスに移動します。
アプローチ 3A – Amazon FSx または Amazon Elastic File System (Amazon EFS) ファイルシステムを、データベースインスタンスを実行するオンプレミスサーバーにマウントします。 AWS Direct Connect または を使用して接続 Site-to-Site VPN を確立できます。データベースをマウントされたファイル共有に直接バックアップすることも、データベースをローカルファイルシステムにバックアップしてからマウントされた FSx または EFS ボリュームにアップロードする 2 段階の手順でバックアップを実行することもできます。次に、オンプレミスサーバーにマウントされている Amazon FSx または Amazon EFS ファイルシステムを EC2 インスタンスにマウントします。
アプローチ 3B – AWS CLI、 AWS SDK、または Amazon S3 REST API を使用して、バックアップファイルをオンプレミスサーバーから S3 バケットに直接移動します。ターゲット S3 バケットがデータセンターから AWS リージョン 離れた にある場合は、Amazon S3 Transfer Acceleration を使用してファイルをより迅速に転送できます。s3fs-fuse
ファイルシステムを使用して、EC2 インスタンスに S3 バケットをマウントします。 アプローチ 3C – オンプレミスデータセンターに AWS DataSync エージェントをインストールし、AWS DataSync を使用してバックアップファイルを Amazon S3 バケットに移動します。s3fs-fuse
ファイルシステムを使用して、EC2 インスタンスに S3 バケットをマウントします。 注記
Amazon S3 File Gateway を使用して、大容量のデータベースバックアップファイルを AWS クラウドの S3 バケットに転送することもできます。詳細については、このガイドの「Amazon S3 File Gateway を使用したバックアップファイルの転送」を参照してください。
-
myloader を使用して、ターゲットデータベースインスタンスのバックアップを復元します。手順については、「myloader usage
」(GitHub) を参照してください。 -
(オプション) ソースデータベースとターゲットデータベースインスタンス間のレプリケーションを設定できます。バイナリログ (binlog) レプリケーションを使用すると、ダウンタイムを短縮できます。詳細については次を参照してください:
-
MySQL ドキュメントの「Setting the Replication Source Configuration
」 -
Amazon Aurora については、以下を参照してください。
-
Aurora ドキュメントの「Synchronizing the Amazon Aurora MySQL DB cluster with the MySQL database using replication」
-
Aurora ドキュメントの「Using binlog replication in Amazon Aurora」
-
-
Amazon RDS については、以下を参照してください。
-
Amazon RDS ドキュメントの「MySQL のレプリケーションの使用」
-
Amazon RDS ドキュメントの「MariaDB のレプリケーションの使用」
-
-
Amazon EC2 については、以下を参照してください。
-
MySQL ドキュメントの「Setting Up Binary Log File Position Based Replication
」 -
MySQL ドキュメントの「Setting Up Replicas
」 -
MariaDB ドキュメントの「Setting Up Replication
」
-
-
利点
-
MyDumper はマルチスレッドを使用して並列処理に対応しているため、バックアップと復元オペレーションの速度が向上します。
-
MyDumper はコストのかかる文字セットの変換ルーチンを回避し、コードの効率を高めるのに役立ちます。
-
MyDumper は、テーブルとメタデータで別々のファイルをダンプすることで、データビューと解析を簡素化します。
-
MyDumper は、すべてのスレッドにわたってスナップショットを維持し、プライマリログとセカンダリログの正確な位置を提供します。
-
Perl 互換正規表現 (PCRE) を使用して、テーブルまたはデータベースを含めるか除外するかを指定できます。
制限事項
-
データ変換プロセスで SQL 形式ではなくフラット形式の中間ダンプファイルが必要な場合は、別のツールを選択することが考えられます。
-
myloader はデータベースユーザーアカウントを自動的にインポートしません。Amazon RDS または Aurora にバックアップを復元する場合は、必要なアクセス許可を持つユーザーを再作成します。詳細については、Amazon RDS ドキュメントの「Master user account privileges」を参照してください。Amazon EC2 データベースインスタンスにバックアップを復元する場合は、ソースデータベースユーザーアカウントを手動でエクスポートしてから EC2 インスタンスにインポートできます。
ベストプラクティス
-
各テーブルをセグメントに分割し (セグメントごとに 10,000 行など)、各セグメントを個別のファイルに書き込むように MyDumper を設定します。これにより、後でデータを並行してインポートできます。
-
InnoDB エンジンを使用している場合は、
--trx-consistency-onlyオプションを使用してロックを最小限に抑えます。 -
MyDumper を使用してデータベースをエクスポートすると、読み取り負荷が高まり、処理が本番データベースの全体的なパフォーマンスに影響を与える可能性があります。レプリカデータベースインスタンスがある場合は、レプリカからエクスポートプロセスを実行します。レプリカからエクスポートを実行する前に、レプリケーション SQL スレッドを停止します。これにより、エクスポートプロセスをより迅速に実行できます。
-
営業時間のピーク時にデータベースをエクスポートしないでください。ピーク時間を避けることで、データベースのエクスポート中に、プライマリ本番データベースのパフォーマンスを安定させることができます。
-
Amazon RDS for MySQL は
keyring_awsプラグインをサポートしていません。詳細については、「既知の問題と制限」を参照してください。オンプレミスの暗号化されたテーブルを Amazon RDS インスタンスに移行するには、バックアップスクリプトで、CREATE TABLE構文からENCRYPTIONまたはDEFAULT ENCRYPTIONを削除する必要があります。保存時の暗号化には、 AWS Key Management Service (AWS KMS) キーを使用してください。詳細については、「Amazon RDS リソースの暗号化」を参照してください。
