翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon OpenSearch Service の自動セマンティックエンリッチメント
序章
Amazon OpenSearch Service は、他の従来の検索エンジンと同様に、word-to-word一致 (辞書検索) を使用して結果を検索します。このアプローチは、製品コードやモデル番号などの特定のクエリに適していますが、ユーザーのインテントを理解することが重要になる抽象検索には苦労します。例えば、「ビーチの靴」を検索すると、辞書検索はカタログアイテム内の個々の単語「靴」、「ビーチ」、「for」、「the」に一致し、正確な検索語が含まれていない「耐水靴」や「surf" などの関連製品が欠落している可能性があります。
自動セマンティックエンリッチメントは、キーワード一致と検索の背後にあるコンテキスト上の意味の両方を考慮して、この制限を解決します。この機能は検索インテントを理解し、検索の関連性を最大 20% 向上させます。インデックスのテキストフィールドに対してこの機能を有効にして、検索結果を強化します。
注記
自動セマンティックエンリッチメントは、バージョン 2.19 以降を実行している OpenSearch Service ドメインで使用できます。さらに、OpenSearch バージョン 2.19 のドメインも、最新のサービスソフトウェアバージョン更新に含まれている必要があります。現在、機能はパブリックドメインで使用でき、VPC ドメインはサポートされていません。
モデルの詳細とパフォーマンスベンチマーク
この機能は、基盤となるモデルを公開せずにバックグラウンドの技術的な複雑さを処理しますが、簡単なモデルの説明とベンチマーク結果を通じて透明性を提供し、重要なワークロードでの機能の採用について情報に基づいた意思決定に役立ちます。
自動セマンティックエンリッチメントは、カスタムのファインチューニングを必要とせずに効果的に機能するサービスマネージド型の事前トレーニング済みのスパースモデルを使用します。このモデルは、指定したフィールドを分析し、さまざまなトレーニングデータから学習した関連付けに基づいてスパースベクトルに展開します。拡張された用語とその重要度の重みは、効率的な取得のためにネイティブの Lucene インデックス形式で保存されます。このプロセスは、データの取り込み中にのみエンコードが行われるドキュメント専用モード
機能開発中のパフォーマンス検証では、平均 334 文字のパッセージを含む MS MARCO
-
英語 - 辞書検索よりも 20% の関連性の向上。また、辞書検索よりも P90 検索レイテンシーが 7.7% 短縮されました (BM25 は 26 ミリ秒、自動セマンティックエンリッチメントは 24 ミリ秒)。
-
多言語 - レキシカル検索に比べて関連性が 105% 向上しましたが、P90 検索レイテンシーはレキシカル検索に比べて 38.4% 増加しました (BM25 は 26 ミリ秒、自動セマンティックエンリッチメントは 36 ミリ秒)。
各ワークロードの固有の性質を考慮すると、実装を決定する前に、独自のベンチマーク基準を使用して開発環境でこの機能を評価することをお勧めします。
サポートされている言語
この機能は英語をサポートしています。さらに、このモデルはアラビア語、ベンガル語、中国語、フィンランド語、フランス語、ヒンディー語、インドネシア語、日本語、韓国語、ペルシャ語、ロシア語、スペイン語、スワヒリ語、テルグ語もサポートしています。
ドメインの自動セマンティックエンリッチメントインデックスを設定する
テキストフィールドの自動セマンティックエンリッチメントを有効にしてインデックスを設定することは簡単で、新しいインデックスの作成時にコンソール、APIs、 CloudFormation テンプレートを使用して管理できます。既存のインデックスに対して有効にするには、テキストフィールドに対してセマンティック自動エンリッチメントを有効にしてインデックスを再作成する必要があります。
コンソールエクスペリエンス - AWS コンソールでは、自動セマンティックエンリッチメントフィールドを使用してインデックスを簡単に作成できます。ドメインを選択すると、コンソールの上部にインデックスの作成ボタンが表示されます。インデックスの作成ボタンをクリックすると、自動セマンティックエンリッチメントフィールドを定義するオプションが表示されます。1 つのインデックスでは、英語と多言語の自動セマンティックエンリッチメントと、辞書フィールドの組み合わせを使用できます。
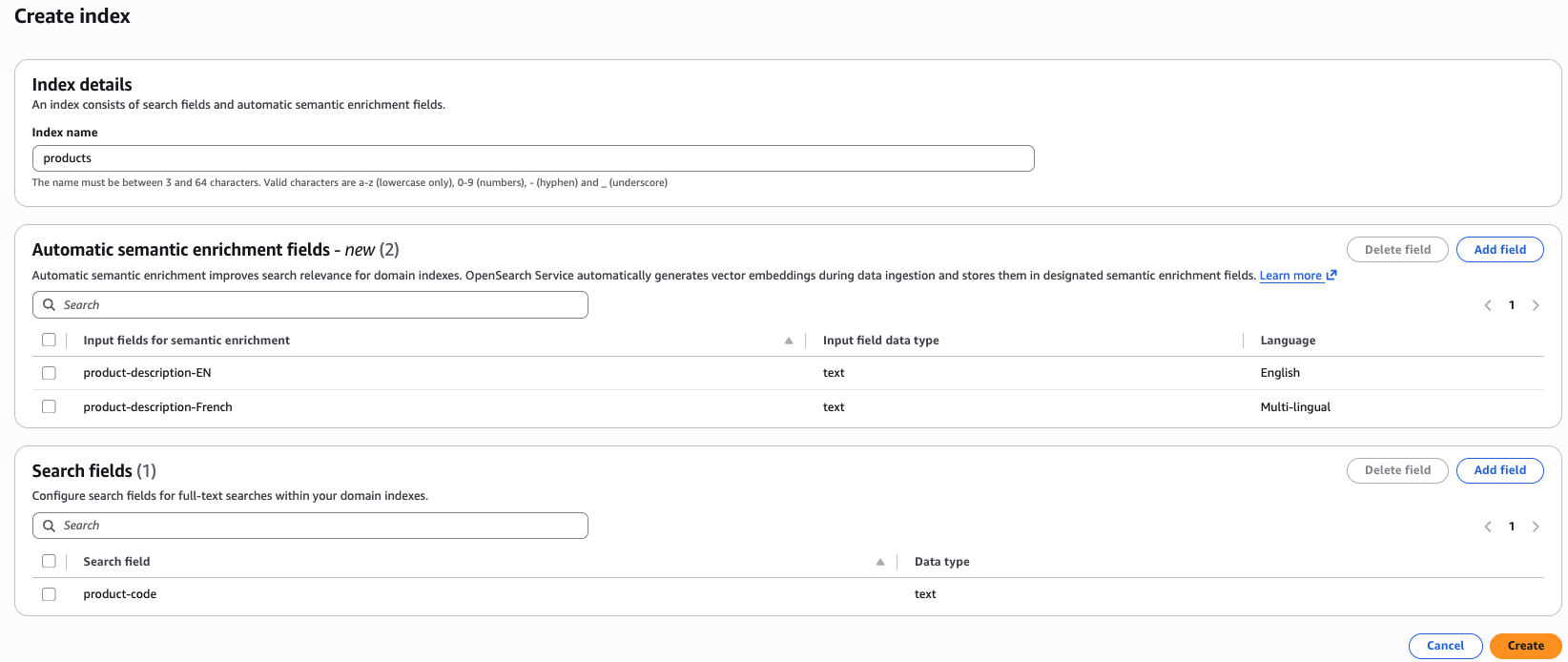
API エクスペリエンス - AWS コマンドラインインターフェイス (AWS CLI) を使用して自動セマンティックエンリッチメントインデックスを作成するには、create-index コマンドを使用します。
aws opensearch create-index \ --domain-name [domain_name] \ --index-name [index_name] \ --index-schema [index_body] \
次の index-schema の例では、title_semantic フィールドのフィールドタイプを text に設定し、パラメータ semantic_enrichment を status ENABLED に設定します。semantic_enrichment パラメータを設定すると、 title_semantic フィールドで自動セマンティックエンリッチメントが有効になります。language_options フィールドを使用して、英語または MULTI-LINGUAL を指定できます。
aws opensearch create-index \ --id XXXXXXXXX \ --index-name 'product-catalog' \ --index-schema '{ "mappings": { "properties": { "product_id": { "type": "keyword" }, "title_semantic": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } }, "title_non_semantic": { "type": "text" } } } }'
作成されたインデックスを記述するには、次のコマンドを使用します。
aws opensearch get-index \ --domain-name [domain_name] \ --index-name [index_name] \
既存のインデックスを更新する
既存のインデックスを更新して、新しいセマンティックエンリッチメントフィールドを追加したり、既存のフィールドでセマンティックエンリッチメントを有効または無効にしたり、非セマンティックテキストフィールドを追加したりできます。update-index コマンドを使用して、 で変更するフィールドのみを指定しますindex-schema。リクエストに含まれていないフィールドは変更されません。
注記
インデックスは更新settingsできません。リクエストにsettingsブロックを含めると、オペレーションは検証エラーを返します。インデックス設定を変更するには、インデックスを削除して再作成する必要があります。
を使用してインデックスを更新するには AWS CLI、 update-index コマンドを使用します。
aws opensearch update-index \ --domain-name [domain_name] \ --index-name [index_name] \ --index-schema [index_body]
新しいセマンティックエンリッチメントフィールドを追加する
セマンティックエンリッチメントを有効にした新しいtextフィールドを既存のインデックスに追加できます。このサービスは、必要な ML モデル、取り込みパイプライン、検索パイプラインを自動的にセットアップします。更新後にインデックス付けされた新しいドキュメントは自動的に強化されます。
重要
既存のドキュメントはバックフィルされません。セマンティックエンリッチメントフィールドを既存のドキュメントに入力するには、更新後に再度取り込む必要があります。再取り込まれるまで、既存のドキュメントは新しいフィールドでのセマンティック検索の恩恵を受けることはありません。
aws opensearch update-index \ --domain-name my-domain \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "description": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } } } } }'
フィールドでセマンティックエンリッチメントを無効にする
現在有効になっているフィールドでセマンティックエンリッチメントを無効にするには、 status を に設定しますDISABLED。フィールドは、取り込みパイプラインと検索パイプラインから削除されます。基盤となるテキストフィールドとその埋め込みフィールドはインデックスに残りますが、強化されなくなります。
aws opensearch update-index \ --domain-name my-domain \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "title_semantic": { "type": "text", "semantic_enrichment": { "status": "DISABLED" } } } } }'
更新の制限
以下のオペレーションは ではサポートされていないupdate-indexため、インデックスを削除して再作成する必要があります。
-
現在
language_optionsセマンティックエンリッチメントが有効になっているフィールドの変更。最初にフィールドを無効にしてから、新しい言語オプションで再度有効にします。 -
ネストされたフィールドの更新。セマンティックエンリッチメントは最上位
textフィールドでのみサポートされています。 -
インデックス の更新
settings。
注記
インデックスに自動セマンティックエンリッチメントによって作成されなかったカスタム取り込みパイプラインまたは検索パイプラインがある場合、更新オペレーションはブロックされます。セマンティックエンリッチメントフィールドを追加する前に、カスタムパイプラインを削除します。
データの取り込みと検索
自動セマンティックエンリッチメントを有効にしてインデックスを作成すると、この機能はデータ取り込みプロセス中に自動的に機能するため、追加の設定は必要ありません。
データインジェスト: インデックスにドキュメントを追加すると、システムは自動的に次の操作を行います。
-
セマンティックエンリッチメント用に指定したテキストフィールドを分析します
-
OpenSearch Service マネージドスパースモデルを使用してセマンティックエンコーディングを生成します
-
これらの強化された表現を元のデータとともに保存します。
このプロセスでは、OpenSearch の組み込み ML コネクタと取り込みパイプラインを使用します。これは、バックグラウンドで自動的に作成および管理されます。
検索: セマンティックエンリッチメントデータは既にインデックス化されているため、クエリは ML モデルを再度呼び出すことなく効率的に実行されます。つまり、追加の検索レイテンシーのオーバーヘッドなしで、検索の関連性が向上します。
自動セマンティックエンリッチメントのアクセス許可の設定
自動セマンティックエンリッチメントを使用してインデックスを作成する前に、必要なアクセス許可を設定する必要があります。このセクションでは、さまざまなインデックスオペレーションに必要なアクセス許可と、 AWS Identity and Access Management (IAM) ときめ細かなアクセスコントロールシナリオの両方でそれらを設定する方法について説明します。
IAM アクセス許可
自動セマンティックエンリッチメントオペレーションには、次の IAM アクセス許可が必要です。これらのアクセス許可は、実行する特定のインデックスオペレーションによって異なります。
CreateIndex API アクセス許可
自動セマンティックエンリッチメントを使用してインデックスを作成するには、次の IAM アクセス許可が必要です。
-
es:CreateIndex– セマンティックエンリッチメント機能を備えたインデックスを作成します。 -
es:ESHttpHead– HEAD リクエストを実行してインデックスの存在を確認します。 -
es:ESHttpPut– インデックス作成の PUT リクエストを実行します。 -
es:ESHttpPost– インデックスオペレーションの POST リクエストを実行します。
UpdateIndex API アクセス許可
自動セマンティックエンリッチメントで既存のインデックスを更新するには、次の IAM アクセス許可が必要です。
-
es:UpdateIndex– インデックス設定とマッピングを更新します。 -
es:ESHttpPut– インデックス更新の PUT リクエストを実行します。 -
es:ESHttpGet– GET リクエストを実行してインデックス情報を取得します。 -
es:ESHttpPost– インデックスオペレーションの POST リクエストを実行します。
GetIndex API アクセス許可
自動セマンティックエンリッチメントを持つインデックスに関する情報を取得するには、次の IAM アクセス許可が必要です。
-
es:GetIndex– インデックス情報と設定を取得します。 -
es:ESHttpGet— GET リクエストを実行してインデックスデータを取得します。
DeleteIndex API アクセス許可
自動セマンティックエンリッチメントを含むインデックスを削除するには、次の IAM アクセス許可が必要です。
-
es:DeleteIndex– インデックスとそのセマンティックエンリッチメントコンポーネントを削除します。 -
es:ESHttpDelete– インデックス削除の DELETE リクエストを実行します。
サンプルの IAM ポリシー
次の ID ベースのアクセスポリシーのサンプルは、ユーザーが自動セマンティックエンリッチメントでインデックスを管理するために必要なアクセス許可を提供します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowSemanticEnrichmentIndexOperations", "Effect": "Allow", "Action": [ "es:CreateIndex", "es:UpdateIndex", "es:GetIndex", "es:DeleteIndex", "es:ESHttpHead", "es:ESHttpGet", "es:ESHttpPut", "es:ESHttpPost", "es:ESHttpDelete" ], "Resource": "arn:aws:es:aws-region:111122223333:domain/domain-name" } ] }
aws-region、111122223333、domain-name を特定の値に置き換えます。リソース ARN で特定のインデックスパターンを指定することで、アクセスをさらに制限できます。
きめ細かなアクセス制御のアクセス許可
Amazon OpenSearch Service ドメインできめ細かなアクセスコントロールが有効になっている場合は、IAM アクセス許可以外の追加のアクセス許可が必要です。インデックスオペレーションごとに次のアクセス許可が必要です。
CreateIndex API アクセス許可
きめ細かなアクセスコントロールが有効になっている場合、自動セマンティックエンリッチメントでインデックスを作成するには、次の追加のアクセス許可が必要です。
-
indices:admin/create– インデックスオペレーションを作成します。 -
indices:admin/mapping/put– インデックスマッピングを作成および更新します。 -
cluster:admin/opensearch/ml/create_connector– セマンティック処理用の機械学習コネクタを作成します。 -
cluster:admin/opensearch/ml/register_model– セマンティックエンリッチメント用の機械学習モデルを登録します。 -
cluster:admin/ingest/pipeline/put– データ処理用の取り込みパイプラインを作成します。 -
cluster:admin/search/pipeline/put– クエリ処理用の検索パイプラインを作成します。
UpdateIndex API アクセス許可
きめ細かなアクセスコントロールが有効になっている場合、自動セマンティックエンリッチメントでインデックスを更新するには、次の追加のアクセス許可が必要です。
-
indices:admin/get– インデックス情報を取得します。 -
indices:admin/settings/update– インデックス設定を更新します。 -
indices:admin/mapping/put– インデックスマッピングを更新します。 -
cluster:admin/opensearch/ml/create_connector– 機械学習コネクタを作成します。 -
cluster:admin/opensearch/ml/register_model– 機械学習モデルを登録します。 -
cluster:admin/ingest/pipeline/put– 取り込みパイプラインを作成します。 -
cluster:admin/search/pipeline/put– 検索パイプラインを作成します。 -
cluster:admin/ingest/pipeline/get– 取り込みパイプライン情報を取得します。 -
cluster:admin/search/pipeline/get– 検索パイプライン情報を取得します。
GetIndex API アクセス許可
きめ細かなアクセスコントロールが有効になっている場合、自動セマンティックエンリッチメントを持つインデックスに関する情報を取得するには、次の追加のアクセス許可が必要です。
-
indices:admin/get– インデックス情報を取得します。 -
cluster:admin/ingest/pipeline/get– 取り込みパイプライン情報を取得します。 -
cluster:admin/search/pipeline/get– 検索パイプライン情報を取得します。
DeleteIndex API アクセス許可
きめ細かなアクセスコントロールが有効になっている場合、自動セマンティックエンリッチメントでインデックスを削除するには、次の追加のアクセス許可が必要です。
-
indices:admin/delete– インデックスオペレーションを削除します。
クエリの書き換え
自動セマンティックエンリッチメントは、クエリの変更を必要とせずに、既存の「一致」クエリをセマンティック検索クエリに自動的に変換します。一致クエリが複合クエリの一部である場合、システムはクエリ構造を横断し、一致クエリを検索して、それらをニューラルスパースクエリに置き換えます。現在、この機能では、スタンドアロンクエリでも複合クエリの一部でも、「一致」クエリの置き換えのみがサポートされています。「multi_match」はサポートされていません。さらに、この機能は、ネストされた一致クエリを置き換えるすべての複合クエリをサポートします。複合クエリには、bool、Boosting、Constant_score、dis_max、 function_score、ハイブリッドなどがあります。
自動セマンティックエンリッチメントの制限
自動セマンティック検索は、映画のタイトル、製品説明、レビュー、概要など、自然言語コンテンツを含むsmall-to-medium規模のフィールドに適用すると最も効果的です。セマンティック検索はほとんどのユースケースの関連性を高めますが、特定のシナリオには適していない場合があります。特定のユースケースに自動セマンティックエンリッチメントを実装するかどうかを決定するときは、次の制限を考慮してください。
-
非常に長いドキュメント – 現在のスパースモデルは、各ドキュメントの最初の 8,192 トークンのみを英語で処理します。多言語ドキュメントの場合、トークンは 512 個です。長い記事については、完全なコンテンツ処理を確保するためにドキュメントチャンキングの実装を検討してください。
-
ログ分析ワークロード – セマンティックエンリッチメントはインデックスサイズを大幅に増やします。これは、完全一致が通常十分であるログ分析には不要である可能性があります。セマンティックコンテキストを追加すると、増加したストレージ要件を正当化するのに十分なログ検索の有効性が向上することはめったにありません。
-
自動セマンティックエンリッチメントは、派生ソース機能と互換性がありません。
-
スロットリング — OpenSearch Service ドメインのインデックス推論リクエストは現在 200 TPS に制限されています。これはソフト制限です。より高い制限については AWS サポートにお問い合わせください。
料金
Amazon OpenSearch Service は、インデックス作成時にスパースベクトル生成中に消費された OpenSearch Compute Units (OCUs) に基づいて、自動セマンティックエンリッチメントを請求します。自動セマンティックエンリッチメントを有効にしたテキストフィールドのインデックス作成中の実際の使用に対してのみ課金されます。1 つのセマンティック検索 OCU は、英語コンテンツに対して 1,110 万トークンを処理できます。24 億個のトークンを処理するには、約 216 個のセマンティック検索 OCU 時間 (24 億/1,110 万) が必要です。セマンティック検索 OCU 時間あたり 0.24 USD の料金では、自動セマンティック検索のために 10 GB のデータを処理するコストは 51 USD (216 OCU 時間 x 0.24 USD/OCU 時間) になります。検索オペレーション中またはデータストレージには、セマンティック検索 OCU の追加料金はかかりません。
Amazon CloudWatch メトリクス を使用して、この消費量をモニタリングできますSemanticSearchOCU。モデルトークンの制限、OCU あたりのボリュームスループット、およびサンプル計算の例の詳細については、OpenSearch Service の料金
