Lambda を使用したイベント駆動型アーキテクチャの作成
イベントとは、Lambda 関数の実行をトリガーするあらゆる事象を指します。イベントは、直接呼び出し (プッシュ) とイベントソースマッピング (プル) の 2 つの方法で Lambda 関数をトリガーできます。
多くの AWS サービスは、Lambda 関数を直接呼び出すことができます。これらのサービスは、Lambda 関数にイベントをプッシュします。関数をトリガーするイベントは、API Gateway を介した HTTP リクエスト、EventBridge ルールで管理されているスケジュール、AWS IoT イベント、Amazon S3 イベントなど、ほぼどのような形式でも可能です。イベントソースマッピングを使用すると、Lambda はキューまたはストリームからイベントをアクティブに取得 (またはプル) します。サポートされているサービスからのイベントをチェックするように Lambda を設定すると、Lambda は関数のポーリングと呼び出しを処理します。
イベントは、関数に渡すと、JSON 形式で構造化されます。JSON 構造は、JSON を生成するサービスやイベントタイプによって異なります。標準 Lambda 関数の呼び出しは最大 15 分かかることがありますが、Lambda は 1 秒以下の短い呼び出しに最適です。特にイベント駆動型アーキテクチャでは、各 Lambda 関数が特定の限られた命令を実行するマイクロサービスとして扱われますす。
注記
イベント駆動型アーキテクチャは、ネットワークを使用して異なるシステム間で通信するため、レイテンシーが変動します。リアルタイム取引システムなどの、非常に低いレイテンシーを必要とするワークロードでは、この設計は最適な選択肢ではない場合もあります。しかし、スケーラビリティと可用性の高いワークロードや、トラフィックパターンが予測不可能なワークロードの場合は、イベント駆動型アーキテクチャがこれらの需要を満たす効果的な方法を提供できます。
イベント駆動型アーキテクチャのメリット
Lambda は、イベント駆動型アーキテクチャにおいて 2 つの呼び出し方法をサポートしています。
-
直接呼び出し (プッシュメソッド): AWS サービスは Lambda 関数を直接トリガーします。例えば、次のようになります。
-
Amazon S3 は、ファイルのアップロード時に関数をトリガーします。
-
API Gateway は、HTTP リクエストを受信すると関数をトリガーします。
-
-
イベントソースマッピング (プルメソッド): Lambda はイベントを取得し、関数を呼び出します。例えば、次のようになります。
-
Lambda は Amazon SQS キューからメッセージを取得し、関数を呼び出します。
-
Lambda は DynamoDB ストリームからレコードを読み取り、関数を呼び出します。
-
以下に説明するように、どちらの方法もイベント駆動型アーキテクチャの利点をもたらします。
イベントによるポーリングとウェブフックの置き換え
従来のアーキテクチャの多くはポーリングやウェブフックのメカニズムを使用し、異なるコンポーネント間で状態を通信します。ポーリングは、新しいデータが使用可能になってからダウンストリームサービスと同期するまでに遅延があるため、更新を取得する際に非常に非効率的になる可能性があります。ウェブフックは、統合する他のマイクロサービスで常にサポートされているわけではありません。また、カスタムの認可と認証の設定が必要になる場合もあります。どちらの場合も、これらの統合方法は、開発チームによる追加の作業なしにオンデマンドでスケールするのは困難です。
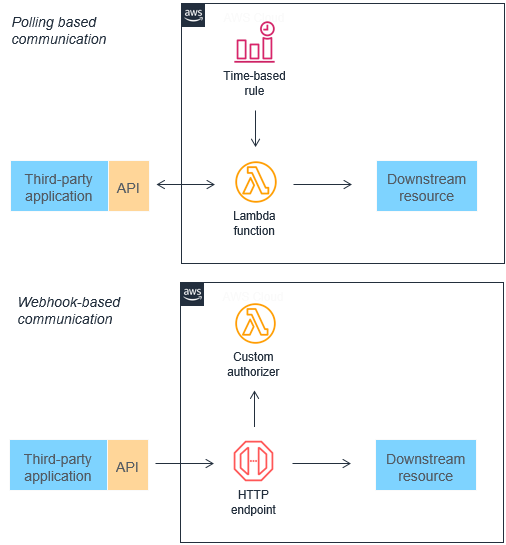
これらのメカニズムの両方をイベントに置き換えることができ、マイクロサービスを使用するために、イベントのフィルタリング、ルーティング、ダウンストリームへのプッシュを行うことができます。このアプローチにより、帯域幅の消費量、CPU 使用率、コストが低下する可能性があります。このようなアーキテクチャでは、各機能ユニットが小規模になり、コードが少なくなることが多いため、複雑さも軽減できます。
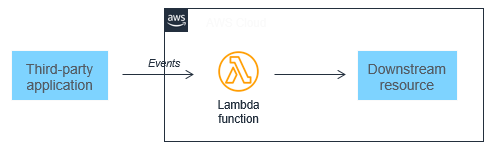
また、イベント駆動型アーキテクチャは、ほぼリアルタイムでのシステムの設計を容易にし、組織がバッチベースの処理から脱却するためにも役立ちます。イベントはアプリケーションの状態が変更された時点で生成されるため、マイクロサービスのカスタムコードは単一のイベントの処理を扱うように設計する必要があります。スケーリングは Lambda サービスによって処理されるため、このアーキテクチャではカスタムコードを変更せずにトラフィックの大幅な増加を処理できます。イベントがスケールアップすると、イベントを処理するコンピューティングレイヤーもスケールアップします。
複雑さの軽減
マイクロサービスを使用すると、デベロッパーとアーキテクトは複雑なワークフローをシンプルにできます。例えば、e コマースモノリスは、個別の在庫、履行、会計のサービスを使用して、注文の承諾と支払いのプロセスに分割できます。モノリスで管理およびオーケストレーションが複雑になる可能性があるものは、イベントと非同期的に通信する一連の分離されたサービスになります。
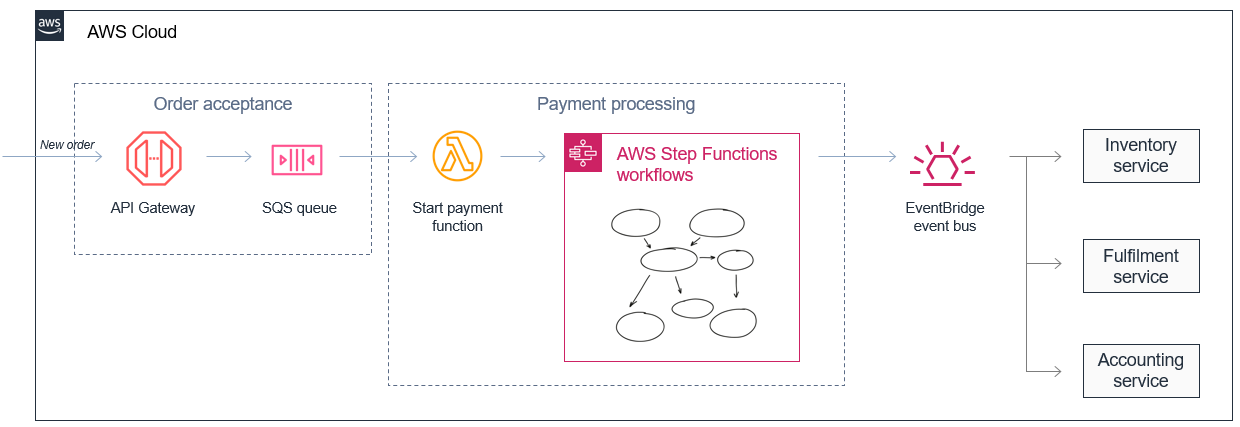
このアプローチにより、さまざまなレートでデータを処理するサービスを組み合わせることもできます。この例では、注文承諾のマイクロサービスは、メッセージを Amazon SQS キューにバッファリングすることで、大量の受信注文を保存できます。
通常、支払い処理サービスは支払い処理の複雑さのためにより遅く、Amazon SQS キューからのメッセージの流れが停滞する可能性があります。AWS Step Functions を使用して複雑な再試行およびエラーの処理ロジックをオーケストレーションし、数十万の注文のアクティブな支払いワークフローを調整することができます。
代替アプローチ: 標準プログラミング言語を使用したオーケストレーションでは、Lambda の耐久性のある関数を使用できます。耐久性のある関数を使用すると、自動チェックポイント設定と再試行を使用して、注文の承諾、支払い処理、通知ロジックをコードに記述できます。このアプローチは、ワークフローに主に Lambda 関数が含まれ、オーケストレーションロジックをコードに保持したい場合に適しています。
スケーラビリティと拡張性の向上
マイクロサービスは、通常は Amazon SNS や Amazon SQS などのメッセージングサービスに発行されるイベントを生成します。これらはマイクロサービス間の弾性バッファのように機能し、トラフィックの増加時にスケーリングを処理するために役立ちます。Amazon EventBridge などのサービスは、その後、ルールでの定義に従い、イベントの内容に応じてメッセージをフィルタリングおよびルーティングすることができます。これにより、イベントベースのアプリケーションは、モノリシックアプリケーションよりもスケーラブルになり、冗長性が向上します。
また、このシステムは非常に拡張しやすく、他のチームが注文処理や支払い処理のマイクロサービスに影響を与えることなく機能を拡張および追加することもできます。このアプリケーションは EventBridge を使用してイベントを発行することで在庫のマイクロサービスなどの既存のシステムと統合されますが、将来のアプリケーションはイベントコンシューマーとして統合することもできます。イベントプロデューサーではイベントコンシューマーが認識されないため、マイクロサービスロジックを簡素化するために役立ちます。
イベント駆動型アーキテクチャのトレードオフ
レイテンシーの変動
単一のデバイス上の同じメモリ空間内ですべてを処理できる場合があるモノリシックアプリケーションとは異なり、イベント駆動型アプリケーションはネットワーク間で通信します。この設計では、レイテンシーが変動します。レイテンシーを最小限に抑えるようにアプリケーションを設計することはできますが、モノリシックアプリケーションはほとんどの場合、スケーラビリティと可用性を犠牲にして、レイテンシーを低くするために最適化できます。
銀行の高頻度な取引用途や倉庫のミリ秒未満のロボットオートメーションなど、一貫した低レイテンシーパフォーマンスを必要とするワークロードは、イベント駆動型アーキテクチャの候補として適していません。
結果整合性
イベントは状態の変化を表し、特定の時点でアーキテクチャ内のさまざまなサービスを多くのイベントが通過するため、このようなワークロードは多くの場合結果整合性
一部のワークロードには、結果整合性 (現在の時間の合計注文数など) または強力な整合性の (現在の在庫など) 要件の組み合わせが含まれています。強力なデータ整合性を必要とするワークロードには、サポートするアーキテクチャパターンがあります。例えば、次のようになります。
-
DynamoDB は強力な整合性のある読み込みを提供できます。レイテンシーが高くなる場合があり、デフォルトモードよりも多くスループットを消費します。DynamoDB は、データ整合性を維持するためにトランザクションをサポートすることもできます。
-
Amazon RDS は ACID プロパティ
を必要とする機能に使用できますが、リレーショナルデータベースは DynamoDB などの NoSQL データベースよりもスケーラビリティが一般的に低下します。Amazon RDS Proxy は、Lambda 関数などのエフェメラルコンシューマーからの接続プーリングとスケーリングを管理するのに役立ちます。
イベントベースのアーキテクチャは、通常、大量のデータのバッチではなく、個々のイベントを中心に設計されています。通常、ワークフローは、複数のイベントを同時に操作するのではなく、個々のイベントまたは実行フローのステップを管理するために設計されています。サーバーレスでは、バッチ処理よりもリアルタイムのイベント処理が推奨され、バッチは多くて小さな増分更新プログラムに置き換えられます。これにより、ワークロードの可用性およびスケーラビリティが向上しますが、イベントが他のイベントを認識することが難しくなります。
呼び出し元に値を返す
多くの場合、イベントベースのアプリケーションは非同期です。そのため、呼び出し元のサービスは他のサービスからのリクエストを待機せず、他の作業を続行します。これは、スケーラビリティと柔軟性を実現するイベント駆動型アーキテクチャの基本的な特性です。戻り値やワークフローの結果を渡すことが、同期実行フローよりも複雑になることを意味します。
本番システムのほとんどの Lambda 呼び出しは非同期であり、Amazon S3 や Amazon SQS などのサービスからのイベントに対応します。このような場合、イベントの処理の成功または失敗が、値を返すことよりも重要であることがよくあります。Lambda のデッドレターキュー (DLQ) などの機能は、呼び出し元に通知することなく、失敗したイベントを特定して再試行できるように提供されています。
サービスおよび関数間のデバッグ
イベント駆動型システムのデバッグもモノリシックアプリケーションとは異なります。さまざまなシステムやサービスがイベントを渡すため、エラーが発生したときに複数のサービスの正確な状態を記録して再現することは不可能です。サービスと関数の呼び出しごとにログファイルが異なるため、エラーの原因となった特定のイベントに何が起こったかを判断することがより複雑になる可能性があります。
イベント駆動型システムで成功するデバッグアプローチを構築するには、3 つの重要な要件があります。まず、堅牢なログ記録システムが重要です。これは AWS のサービス間で提供され、Amazon CloudWatch によって Lambda 関数に埋め込まれます。次に、これらのシステムで、ログを検索する際に役立つように、トランザクション全体の各ステップでログに記録されるトランザクション識別子がすべてのイベントにあることを確認することが重要です。
最後に、AWS X-Ray などのデバッグおよびモニタリングサービスを使用し、ログの解析および分析を自動化することを強くお勧めします。これにより、複数の Lambda 呼び出しおよびサービス間でログを使用できるため、問題の根本原因をより簡単に特定できます。トラブルシューティングに X-Ray を使用する詳細な説明については、「トラブルシューティングのチュートリアル」を参照してください。
Lambda ベースのイベント駆動型アプリケーションのアンチパターン
Lambda でイベント駆動型アーキテクチャを構築する場合は、次の一般的なアンチパターンは避けてください。これらのパターンは機能しますが、コストと複雑さが増す可能性があります。
Lambda モノリス
Amazon EC2 インスタンスや Elastic Beanstalk アプリケーションなどの従来サーバーから移行された多くのアプリケーションでは、開発者は既存のコードを「リフトアンドシフト」します。これにより、多くの場合、すべてのイベントに対してトリガーされるすべてのアプリケーションロジックを含む単一の Lambda 関数が生成されます。基本的なウェブアプリケーションの場合、モノリシック Lambda 関数がすべての API Gateway ルートを処理し、必要なすべてのダウンストリームリソースと統合されます。
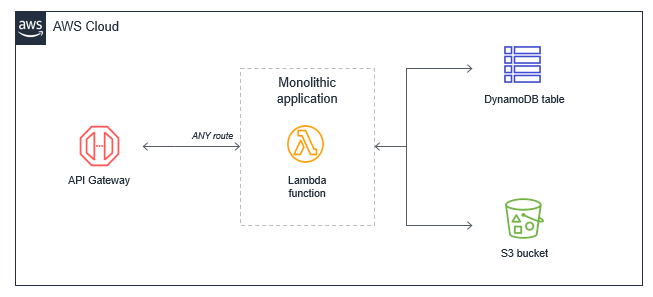
このアプローチにはいくつかの欠点があります。
-
パッケージサイズ – 可能性があるすべてのコードがすべてのパスに含まれているため、Lambda 関数が非常に大きくなる場合もあります。これにより、Lambda サービスの実行が遅くなります。
-
最小特権の強制が困難 – 関数の実行ロールは、すべてのパスに必要なすべてのリソースへのアクセスを許可する必要があり、アクセス許可が非常に広範になります。これはセキュリティ上の懸念です。機能モノリスの多くのパスには、付与されたすべてのアクセス許可は必要ありません。
-
アップグレードが困難 - 本番システムでは、単一の関数をアップグレードするリスクが高くなり、アプリケーション全体が破損する可能性があります。Lambda 関数の単一パスのアップグレードは、関数全体のアップグレードになります。
-
維持が困難 - モノリシックコードリポジトリであるため、複数の開発者がサービスに取り組むことが難しくなります。また、開発者の認知負荷が高まり、コードの適切なテストカバレッジを作成することが難しくなります。
-
コードの再利用が困難 - 再利用可能なライブラリをモノリスから分離することが難しくなり、コードの再利用が難しくなります。より多くのプロジェクトを開発してサポートするにつれて、コードのサポートやチームの速度のスケーリングが難しくなる可能性があります。
-
テストが困難 - コードの行が増えると、コードベースの入力およびエントリポイントの可能なすべての組み合わせをユニットテストすることが難しくなります。一般的に、コードの少ない小規模なサービスに対してユニットテストを実装する方が簡単です。
推奨される代替方法は、モノリシック Lambda 関数を個々のマイクロサービスに分解し、単一の Lambda 関数を単一の明確に定義されたタスクにマッピングすることです。いくつかの API エンドポイントを持つこのシンプルなウェブアプリケーションでは、結果として得られるマイクロサービスベースのアーキテクチャを API Gateway ルートに基づいて作成できます。
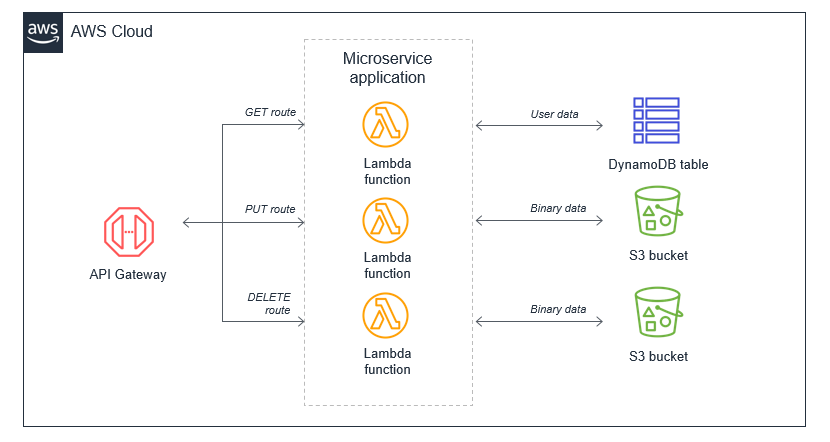
Lambda 関数が暴走する原因となる再帰パターン
AWS サービスは Lambda 関数を呼び出すイベントを生成し、Lambda 関数は AWS サービスにメッセージを送信できます。一般に、Lambda 関数を呼び出すサービスまたはリソースは、関数の出力先のサービスまたはリソースとは異なる必要があります。これを管理しないと、無限ループが発生する可能性があります。
例えば、Lambda 関数が Amazon S3 オブジェクトにオブジェクトを書き込むと、配置イベントを介して同じ Lambda 関数が呼び出されます。この呼び出しにより 2 番目のオブジェクトがバケットに書き込まれ、同じ Lambda 関数が呼び出されます。
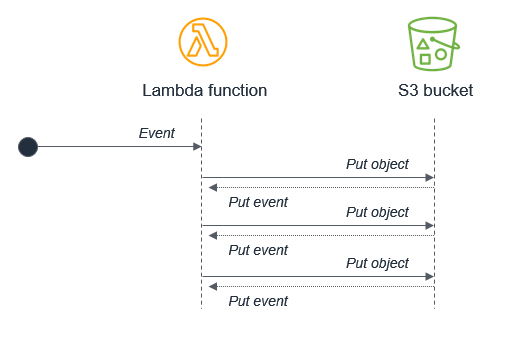
ほとんどのプログラミング言語で無限ループが発生する可能性がありますが、このアンチパターンはサーバーレスアプリケーションでより多くのリソースを消費する可能性があります。Lambda および Amazon S3 の両方がトラフィックに基づいて自動的にスケールされるため、ループによって Lambda が利用可能なすべての同時実行数を消費するようにスケールする可能性があり、Amazon S3 が引き続きオブジェクトを書き込んで Lambda 用により多くのイベントを生成します。
この例では S3 を使用していますが、再帰ループのリスクは Amazon SNS、Amazon SQS、DynamoDB、その他のサービスにも存在します。再帰ループ検出を使用し、このアンチパターンを見つけて回避できます。
Lambda 関数を呼び出す Lambda 関数
関数を使用すると、カプセル化とコードの再利用が可能になります。ほとんどのプログラミング言語は、コードベース内で関数を同期的に呼び出すコードの概念をサポートしています。この場合、呼び出し元は関数がレスポンスを返すまで待機します。
注記
他の Lambda 関数を直接呼び出す Lambda 関数は、コストと複雑さの懸念から一般的にアンチパターンですが、これは耐久性のある関数には適用されません。耐久性のある関数は、他の関数を呼び出してマルチステップワークフローをオーケストレーションするように特別に設計されています。
これが従来のサーバーまたは仮想インスタンスで発生すると、オペレーティングシステムスケジューラが使用可能な他の作業に切り替えます。サーバーの所有と運用のための固定コストを支払うため、CPU が 0% で動作している場合も 100% で動作している場合も、アプリケーションの全体的なコストには影響しません。
このモデルは、多くの場合、サーバーレス開発にはうまく適応しません。例えば、注文を処理する 3 つの Lambda 関数で構成されるシンプルな e コマースアプリケーションについて考えてみましょう。
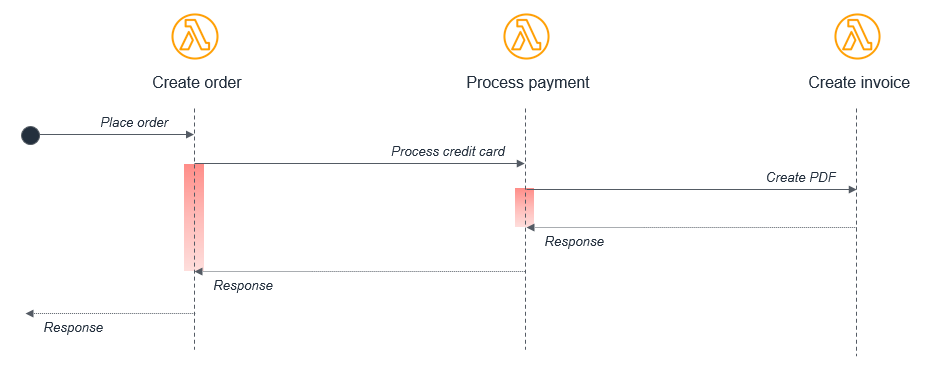
この例では、Create order 関数が Process payment 関数を呼び出し、次にこの関数が Create invoice 関数を呼び出します。この同期フローはサーバー上の単一のアプリケーション内では機能する場合もありますが、分散サーバーレスアーキテクチャでは次のようないくつかの回避可能な問題が発生します。
-
コスト - Lambda を使用すると、呼び出しの時間に対して課金されます。この例では、図に赤で示されているように、Create invoice 関数の実行中に他の 2 つの関数も待機状態で実行されます。
-
エラー処理 - ネストされた呼び出しでは、エラー処理が大幅に複雑化する可能性があります。例えば、Create invoice でエラーが発生した場合、Process payment 関数で請求を取り消す必要がある場合も、そうではなく Create invoice プロセスを再試行する場合もあります。
-
密結合 - 支払いの処理は、通常、インボイスの作成よりも時間がかかります。このモデルでは、ワークフロー全体の可用性が最も遅い関数によって制限されます。
-
スケーリング - 3 つすべての関数の同時実行数が等しくなければなりません。これにより、負荷の高いシステムでは、他で必要な数よりも多くの同時実行数が使用されます。
サーバーレスアプリケーションでは、このパターンを回避するための一般的なアプローチが 2 つあります。まず、Lambda 関数間で Amazon SQS キューを使用します。ダウンストリームプロセスがアップストリームプロセスよりも遅い場合、キューがメッセージを永続的に存続させて、2 つの関数を分離します。この例では、Create order 関数が Amazon SQS キューにメッセージを発行し、Process payment 関数がキューからのメッセージを消費します。
2 つ目の方法は AWS Step Functions を使用することです。複数のタイプの障害と再試行のロジックを持つ複雑なプロセスの場合、ワークフローのオーケストレーションに必要なカスタムコードの量を減らすために Step Functions が役立ちます。これにより、Step Functions が作業をオーケストレーションし、エラーと再試行を堅牢に処理するため、Lambda 関数にはビジネスロジックのみが含まれます。
単一の Lambda 関数内での同期待機
同時実行の可能性があるアクティビティが単一の Lambda 関数内で同期的にスケジュールされていないことを確認します。例えば、Lambda 関数が S3 バケットに書き込んでから、DynamoDB テーブルに書き込む場合があります。
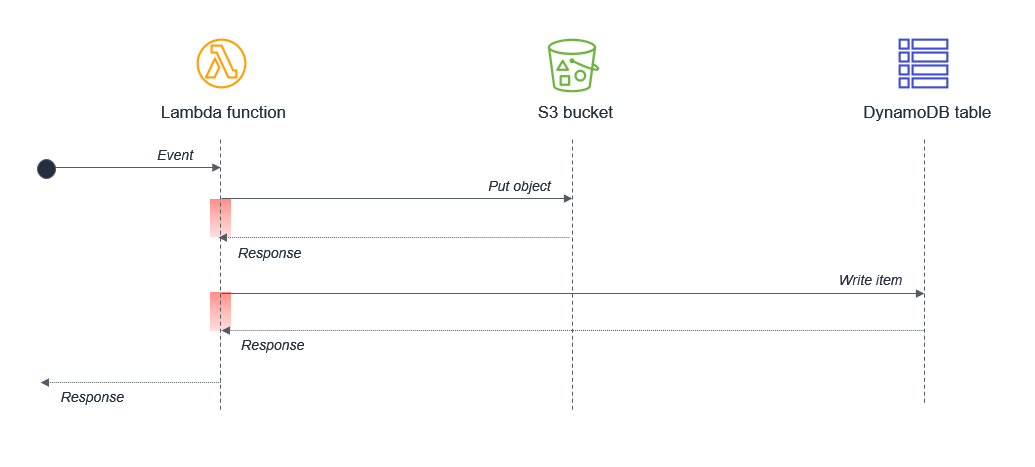
この設計では、アクティビティがシーケンシャルであるため、待機時間が複合化されます。2 番目のタスクが最初のタスクの完了に依存する場合、個別の Lambda 関数を 2 つ持つことによって合計の待機時間および実行コストを削減できます。
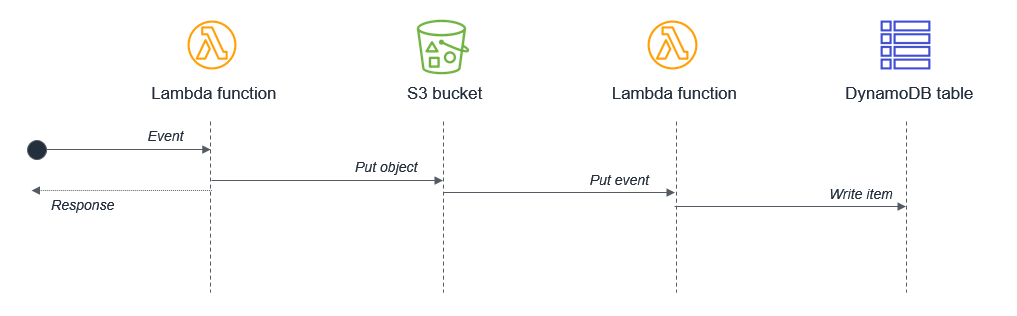
この設計では、オブジェクトを Amazon S3 バケットに配置した直後に、最初の Lambda 関数が応答します。S3 サービスが 2 番目の Lambda 関数を呼び出し、これにより DynamoDB テーブルにデータが書き込まれます。このアプローチにより、Lambda 関数の実行の合計待機時間が最小限に抑えられます。
