翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
# Apache Iceberg テーブルの作成
AWS Lake Formation は、Amazon S3 に AWS Glue Data Catalog データが存在する で Apache Parquet データ形式を使用する Apache Iceberg テーブルの作成をサポートしています。Data Catalog のテーブルは、データストア内のデータを表すメタデータ定義です。デフォルトでは、Lake Formation は Iceberg v2 テーブルを作成します。v1 テーブルと v2 テーブルの違いについては、Apache Iceberg ドキュメントの「[形式バージョンの変更](https://iceberg.apache.org/spec/#appendix-e-format-version-changes)」を参照してください。
[Apache Iceberg](https://iceberg.apache.org/) は、非常に大規模な分析データセット用のオープンテーブル形式です。Iceberg では、スキーマの変更 (スキーマ進化とも呼ばれます) を簡単に行うことができます。つまり、基になるデータを中断することなく、データテーブルの列を追加、名前変更、または削除できます。Iceberg はデータのバージョニングもサポートしているため、データの変更を経時的に追跡できます。これにより、タイムトラベル機能が有効になるため、過去のバージョンのデータにアクセスしてクエリを実行し、更新と削除の間に行われたデータの変更を分析できます。
Lake Formation コンソールまたは AWS Glue API の `CreateTable`オペレーションを使用して、データカタログに Iceberg テーブルを作成できます。詳細については、「[CreateTable アクション (Python: create\_table)](https://docs.aws.amazon.com/glue/latest/dg/aws-glue-api-catalog-tables.html#aws-glue-api-catalog-tables-CreateTable)」を参照してください。
Data Catalog に Iceberg テーブルを作成する場合、読み取りと書き込みを実行できるように、Amazon S3 でテーブル形式とメタデータファイルのパスを指定する必要があります。
Lake Formation を使用して、Amazon S3 データロケーションの登録時にきめ細かなアクセスコントロール許可を使用して Iceberg テーブルを保護できます AWS Lake Formation。Amazon S3 のソースデータおよび Lake Formation に登録されていないメタデータの場合、アクセスは Amazon S3 および AWS Glue アクションの IAM アクセス許可ポリシーによって決まります。詳細については、「[Lake Formation 許可の管理](managing-permissions.md)」を参照してください。
**注記**
Data Catalog は、パーティションの作成と Iceberg テーブルプロパティの追加をサポートしていません。
**Topics**
+ [前提条件](#iceberg-prerequisites)
+ [Iceberg テーブルの作成](#create-iceberg-table)
## 前提条件
Data Catalog に Iceberg テーブルを作成し、Lake Formation のデータアクセス許可を設定するには、次の要件を満たす必要があります。
1.
**Lake Formation にデータが登録されていない状態で Iceberg テーブルを作成するために必要なアクセス許可。**
Data Catalog にテーブルを作成するために必要なアクセス許可に加えて、テーブル作成者には次のアクセス許可が必要です。
+ リソース arn:aws:s3:::{bucketName} での `s3:PutObject`
+ リソース arn:aws:s3:::{bucketName} での `s3:GetObject`
+ リソース arn:aws:s3:::{bucketName} での `s3:DeleteObject`
1.
**Lake Formation にデータが登録されている状態で Iceberg テーブルを作成するために必要なアクセス許可:**
Lake Formation を使用してデータレイク内のデータを管理および保護するには、テーブルのデータを含む Amazon S3 ロケーションを Lake Formation に登録します。これは、Lake Formation が Athena、Redshift Spectrum、Amazon EMR などの AWS 分析サービスに認証情報を提供してデータにアクセスできるようにするためです。Amazon S3 ロケーションの登録の詳細については「[データレイクへの Amazon S3 ロケーションの追加](register-data-lake.md)」を参照してください。
Lake Formation に登録されている、基盤となるデータを読み書きするプリンシパルには、次のアクセス許可が必要です。
+ `lakeformation:GetDataAccess`
+ `DATA_LOCATION_ACCESS`
ロケーションに対するデータロケーション許可を持つプリンシパルは、すべての子ロケーションに対するロケーション許可も持っています。
データロケーション許可の詳細については、「[基盤となるデータのアクセスコントロール](access-control-underlying-data.md)」を参照してください。
圧縮を有効にするには、Data Catalog 内のテーブルを更新するアクセス許可を持つ IAM ロールを、サービスが引き受ける必要があります。詳細については、「[テーブル最適化の前提条件](https://docs.aws.amazon.com/glue/latest/dg/optimization-prerequisites.html)」を参照してください。
## Iceberg テーブルの作成
このページに記載されている AWS Command Line Interface ように、Lake Formation コンソールまたは を使用して Iceberg v1 および v2 テーブルを作成できます。 AWS Glue コンソールまたは を使用して Iceberg テーブルを作成することもできます AWS Glue クローラー。詳細については、「 AWS Glue デベロッパーガイド」の「[Data Catalog とクローラー](https://docs.aws.amazon.com/glue/latest/dg/catalog-and-crawler.html)」を参照してください。
**Iceberg テーブルを作成するには**
------
#### [ Console ]
1. にサインインし AWS マネジメントコンソール、[https://console.aws.amazon.com/lakeformation/](https://console.aws.amazon.com/lakeformation/) で Lake Formation コンソールを開きます。
1. Data Catalog で **[テーブル]** を選択し、**[テーブルの作成]** ボタンを使用して次の属性を指定します。
+ **テーブル名**: テーブルの名前を入力します。Athena を使用してテーブルにアクセスする場合は、「Amazon Athena ユーザーガイド」の[命名に関するヒント](https://docs.aws.amazon.com/athena/latest/ug/tables-databases-columns-names.html)を使用します。
+ **データベース**: 既存のデータベースを選択するか、新しいデータベースを作成します。
+ **説明**: テーブルの説明。テーブルの内容を理解しやすくするために説明を記入できます。
+ **テーブル形式**: **[テーブル形式]** として、[Apache Iceberg] を選択します。
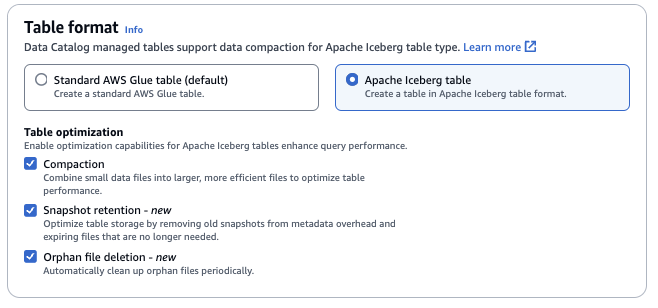
+ **テーブル最適化**
+ **圧縮** - データファイルをマージして書き換えて、古くなったデータを削除し、断片化されたデータをより大きい効率的なファイルに統合します。
+ **スナップショット保持** - スナップショットは、Iceberg テーブルのタイムスタンプ付きバージョンです。スナップショット保持設定を使用すると、スナップショットを保持する期間と保持するスナップショットの数を強制できます。スナップショット保持オプティマイザーを設定すると、古い不要なスナップショットと、その基になる関連付けられたファイルを削除して、ストレージのオーバーヘッドを管理できます。
+ **孤立ファイルの削除** — 孤立ファイルは、Iceberg テーブルメタデータによって参照されなくなったファイルです。これらのファイルは、特にテーブルの削除や ETL ジョブの失敗などのオペレーションの後、時間の経過と共に蓄積される可能性があります。孤立ファイルの削除を有効にすると AWS Glue 、 はこれらの不要なファイルを定期的に識別して削除し、ストレージを解放できます。
詳細については、「[Iceberg テーブルの最適化](https://docs.aws.amazon.com/glue/latest/dg/table-optimizers.html)」を参照してください。
+ **IAM ロール**: 圧縮を実行する場合、サービスはユーザーに代わって IAM ロールを引き受けます。IAM ロールは、ドロップダウンを使用して選択できます。圧縮を有効にするために必要なアクセス許可がロールにあることを確認します。
必要なアクセス許可の詳細については、「[テーブル最適化の前提条件](https://docs.aws.amazon.com/glue/latest/dg/optimization-prerequisites.html)」を参照してください。
+ **ロケーション**: メタデータテーブルを保存する Amazon S3 内のフォルダへのパスを指定します。Iceberg が読み取りと書き込みを実行するには、メタデータファイルと Data Catalog 内のロケーションが必要です。
+ **スキーマ**: **[列を追加]** を選択して、列と、列のデータ型を追加します。空のテーブルを作成して、後でスキーマを更新することもできます。Data Catalog は Hive データ型をサポートしています。詳細については、「[Hive データ型](https://cwiki.apache.org/confluence/plugins/servlet/mobile?contentId=27838462#content/view/27838462)」を参照してください。
Iceberg では、テーブルを作成した後でスキーマとパーティションを進化させることができます。[[Athena クエリ]](https://docs.aws.amazon.com/athena/latest/ug/querying-iceberg-evolving-table-schema.html) を使用してテーブルスキーマを更新し、[[Spark クエリ]](https://iceberg.apache.org/docs/latest/spark-ddl/#alter-table-sql-extensions) を使用してパーティションを更新できます。
------
#### [ AWS CLI ]
```
aws glue create-table \
--database-name iceberg-db \
--region us-west-2 \
--open-table-format-input '{
"IcebergInput": {
"MetadataOperation": "CREATE",
"Version": "2"
}
}' \
--table-input '{"Name":"{{test-iceberg-input-demo}}",
"TableType": "EXTERNAL_TABLE",
"StorageDescriptor":{
"Columns":[
{"Name":"col1", "Type":"int"},
{"Name":"col2", "Type":"int"},
{"Name":"col3", "Type":"string"}
],
"Location":"s3://{{DOC_EXAMPLE_BUCKET_ICEBERG}}/"
}
}'
```
------