# AWS Glue ジョブ実行インサイトでのモニタリング
AWS Glue ジョブ実行インサイトは、AWS Glue ジョブのデバッグとジョブの最適化を簡素化する AWS Glue の機能です。AWS Glue は、[Spark UI](https://docs.aws.amazon.com/glue/latest/dg/monitor-spark-ui.html)、および AWS Glue ジョブをモニタリングするための[CloudWatch Logs とメトリクス](https://docs.aws.amazon.com/glue/latest/dg/monitor-cloudwatch.html)を提供します。この機能を使用すると、AWS Glue ジョブの実行に関する情報を取得できます:
+ エラーが発生した AWS Glue ジョブスクリプトの行番号。
+ ジョブの失敗の直前に Spark クエリプランで最後に実行された Spark アクション。
+ 時系列ログストリームに表示される障害に関連する Spark 例外イベント。
+ 根本原因の分析と、問題を解決するための推奨アクション(スクリプトのチューニングなど)。
+ 根本原因に対処する推奨アクションを含む共通の Spark イベント(Spark アクションに関連するログメッセージ)。
これらのインサイトはすべて、AWS Glue ジョブの CloudWatch Logs 内の 2 つの新しいログストリームを使用して利用できます。
## 要件
AWS Glue ジョブ実行インサイト機能は、AWS Glue バージョン 2.0 以降で利用できます。既存のジョブの[移行ガイド](https://docs.aws.amazon.com/glue/latest/dg/migrating-version-30.html)に従って、古い AWS Glue バージョンからアップグレードすることができます。
## AWS Glue ETL ジョブのジョブ実行インサイトの有効化
ジョブ実行インサイトは、AWS Glue Studio または CLI によって有効にできます。
### AWS Glue Studio
AWS Glue Studio でジョブを作成する場合、[**ジョブの詳細**] タブでジョブ実行インサイトを有効または無効にすることができます。**[ジョブインサイトを生成する]** ボックスが選択されていることを確認します。

### コマンドライン
CLI を使用してジョブを作成する場合は、単一の新しい[ジョブパラメータ](https://docs.aws.amazon.com/glue/latest/dg/aws-glue-programming-etl-glue-arguments.html)でジョブの実行を開始できます: `--enable-job-insights = true`。
デフォルトでは、ジョブ実行インサイトログストリームは、[AWS Glue連続ログ記録](https://docs.aws.amazon.com/glue/latest/dg/monitor-continuous-logging.html) (つまり `/aws-glue/jobs/logs-v2/`)で使用されるのと同じデフォルトロググループの下に作成されます。連続ログ記録に同じ引数のセットを使用して、カスタムロググループ名、ログフィルター、およびロググループ構成を設定できます。詳細については、「[AWS Glue ジョブの連続ログ記録の有効化](https://docs.aws.amazon.com/glue/latest/dg/monitor-continuous-logging-enable.html)」を参照してください。
## CloudWatch でのジョブ実行インサイトログストリームへのアクセス
ジョブ実行インサイト機能を有効にすると、ジョブ実行が失敗したときに 2 つのログストリームが作成されることがあります。ジョブが正常に終了すると、いずれのストリームも生成されません。
1. *例外分析ログストリーム*:`-job-insights-rca-driver`。このストリームは、以下を提供します:
+ エラーが発生した AWS Glue ジョブスクリプトの行番号。
+ Spark クエリプラン (DAG) で最後に実行された Spark アクション。
+ Spark ドライバおよび例外に関連するエグゼキュータからの簡潔な時系列イベント。完全なエラーメッセージ、失敗した Spark タスク、およびそのエグゼキューター ID などの詳細を調べて、必要に応じてさらに詳細な調査を行うために、特定のエグゼキューターのログストリームに集中できます。
1. *ルールベースのインサイトストリーム*:
+ エラーの修正方法に関する根本原因の分析とレコメンデーション(特定のジョブパラメータを使用してパフォーマンスを最適化するなど)。
+ 関連する Spark イベントは、根本原因の分析および推奨アクションの基礎として機能します。
**注記**
最初のストリームは、失敗したジョブ実行で例外の Spark イベントが使用できる場合にのみ存在し、2 番目のストリームは、失敗したジョブ実行に対して利用可能なインサイトがある場合にのみ存在します。例えば、ジョブが正常に終了した場合、どちらのストリームも生成されません。ジョブが失敗しても、失敗シナリオと一致するサービス定義のルールがない場合は、最初のストリームだけが生成されます。
AWS Glue Studio からジョブが作成された場合、上記のストリームへのリンクは、[ジョブ実行の詳細] タブ (ジョブ実行インサイト) の下で「簡潔で統合されたエラーログ」および「エラー分析とガイダンス」としても使用できます。
![ログストリームへのリンクを含む [ジョブ実行の詳細] ページ。](http://docs.aws.amazon.com/ja_jp/glue/latest/dg/images/monitor-job-run-insights-2.png)
## AWS Glue ジョブ実行インサイトの例
このセクションでは、ジョブ実行インサイト機能が、失敗したジョブの問題を解決するためにどのように役立つかの例を紹介します。この例では、ユーザーは AWS Glue ジョブで必要なモジュール (tensorflow) をインポートし、データに基づいて機械学習モデルを分析および構築するのを忘れていました。
```
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.types import *
from pyspark.sql.functions import udf,col
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
data_set_1 = [1, 2, 3, 4]
data_set_2 = [5, 6, 7, 8]
scoresDf = spark.createDataFrame(data_set_1, IntegerType())
def data_multiplier_func(factor, data_vector):
import tensorflow as tf
with tf.compat.v1.Session() as sess:
x1 = tf.constant(factor)
x2 = tf.constant(data_vector)
result = tf.multiply(x1, x2)
return sess.run(result).tolist()
data_multiplier_udf = udf(lambda x:data_multiplier_func(x, data_set_2), ArrayType(IntegerType(),False))
factoredDf = scoresDf.withColumn("final_value", data_multiplier_udf(col("value")))
print(factoredDf.collect())
```
ジョブ実行インサイト機能がないと、ジョブが失敗すると、Spark によってスローされる次のメッセージのみが表示されます。
`An error occurred while calling o111.collectToPython. Traceback (most recent call last):`
メッセージがあいまいなので、デバッグ体験が制限されます。この場合、この機能は 2 つの CloudWatch Logs ストリームに追加のインサイトを提供します。
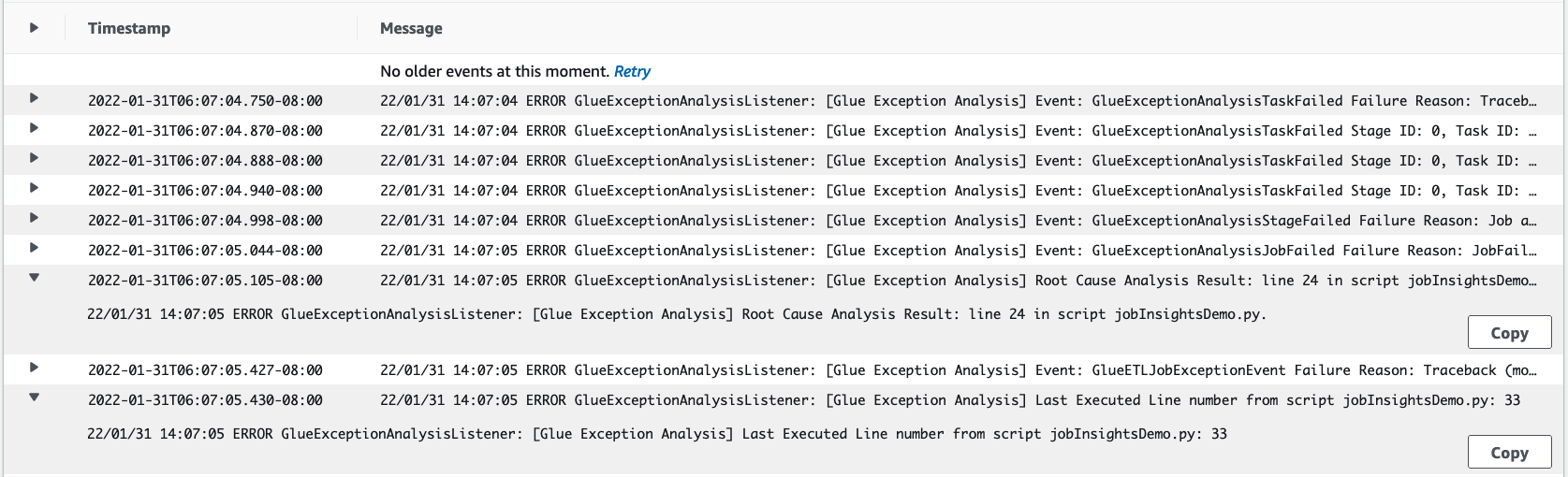
1. `job-insights-rca-driver` ログストリーム:
+ *例外イベント*: このログストリームは、Spark ドライバおよびさまざまな分散ワーカーから収集された障害に関連する Spark 例外イベントを提供します。これらのイベントは、障害のあるコードが Spark タスク、エグゼキューター、および AWS Glue ワーカーに分散されたステージ全体で実行されるときに、例外の時系列の伝播を理解するのに役立ちます。
+ *行番号*: このログストリームは、失敗の原因となった欠落している Python モジュールをインポートするための呼び出しを行った 21 行目を識別します。 また、スクリプトで最後に実行された行として、Spark アクション `collect()` の呼び出しである 24 行目も識別します。
1. `job-insights-rule-driver` ログストリーム:
+ *根本原因とレコメンデーション*:スクリプトの障害の行番号と最後に実行された行番号に加えて、このログストリームには、根本原因の分析と、AWS Glue ドキュメントに従って、AWS Glue ジョブの追加の Python モジュールを使用するために必要なジョブパラメーターを設定するためのレコメンデーションが表示されます。
+ *基本イベント*: このログストリームには、根本原因を推測してレコメンデーションを提供するために、サービス定義ルールで評価された Spark 例外イベントも表示されます。
