Spark DataFrame をサポートする DynamoDB コネクタ
Spark DataFrame をサポートする DynamoDB コネクタを使用すると、Spark DataFrame API を使用して DynamoDB 内のテーブルとの間で読み書きを行うことができます。コネクタのセットアップ手順は DynamicFrame ベースのコネクタの場合と同じで、こちらから確認できます。
DataFrame ベースのコネクタライブラリにロードするには、必ず DynamoDB 接続を Glue ジョブにアタッチしてください。
注記
Glue コンソール UI は現在、DynamoDB 接続の作成をサポートしていません。Glue CLI (CreateConnection) を使用して DynamoDB 接続を作成できます。
aws glue create-connection \ --connection-input '{ \ "Name": "my-dynamodb-connection", \ "ConnectionType": "DYNAMODB", \ "ConnectionProperties": {}, \ "ValidateCredentials": false, \ "ValidateForComputeEnvironments": ["SPARK"] \ }'
DynamoDB 接続を作成すると、Glue ジョブに CLI (CreateJob、UpdateJob) を介してアタッチするか、「ジョブの詳細」ページで直接アタッチすることができます。
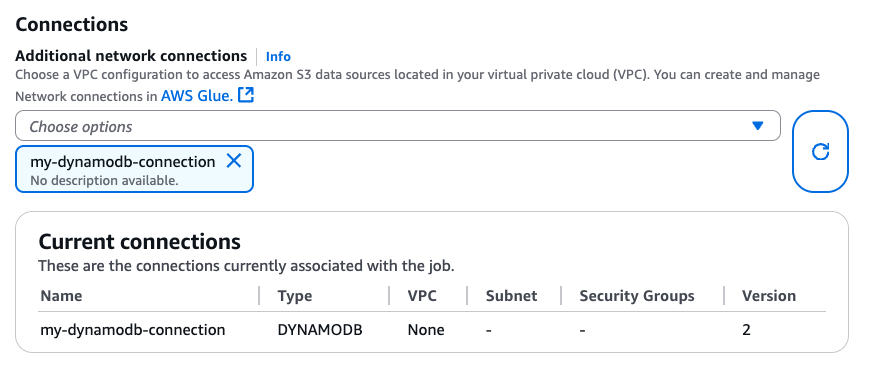
DYNAMODB タイプの接続が Glue ジョブにアタッチされたら、DataFrame ベースのコネクタから次の読み取り、書き込み、エクスポートオペレーションを使用できます。
DataFrame ベースのコネクタを使用した DynamoDB からの読み取りと書き込み
次のコード例は、DynamoDB ベースのコネクタを介した DynamoDB に対する読み込みと書き込みを行う方法を方法を示します。ここでは、あるテーブルから読み取りを行い、別のテーブルに対して書き込みを行っています。
DataFrame ベースのコネクタを介して DynamoDB エクスポートを使用する
80 GB を超える DynamoDB テーブルサイズの読み取りオペレーションでは、エクスポートオペレーションが向上します。次のコード例は、DataFrame ベースのコネクタを介してテーブルからの読み取り、S3 へのエクスポート、パーティションの数の出力を行う例を示します。
注記
DynamoDB エクスポート機能は Scala DynamoDBExport オブジェクトから使用できます。Python ユーザーは、Spark の JVM インターロープを介してアクセスするか、DynamoDB ExportTableToPointInTime API で AWS SDK for Python (Boto3) を使用することができます。
設定オプション
読み取りオプション
| オプション | 説明 | デフォルト |
|---|---|---|
dynamodb.input.tableName |
DynamoDB テーブル名 (必須) | - |
dynamodb.throughput.read |
使用する読み込みキャパシティーユニット (RCU)。指定しない場合、dynamodb.throughput.read.ratio が計算に使用されます。 |
- |
dynamodb.throughput.read.ratio |
使用する読み込みキャパシティーユニット (RCU) の比率。 | 0.5 |
dynamodb.table.read.capacity |
スループットの計算に使用されるオンデマンドテーブルの読み込みキャパシティーユニット。このパラメータは、オンデマンドキャパシティーテーブルでのみ有効です。デフォルトはウォームスループット読み込みユニットです。 | - |
dynamodb.splits |
並列スキャンオペレーションで使用されるセグメントの数を定義します。指定しない場合、コネクタは妥当なデフォルト値を計算します。 | - |
dynamodb.consistentRead |
強力な整合性のある読み込みを使用するかどうか。 | 誤 |
dynamodb.input.retry |
再試行可能な例外がある場合に実行する再試行回数を定義します。 | 10 |
書き込みオプション
| オプション | 説明 | デフォルト |
|---|---|---|
dynamodb.output.tableName |
DynamoDB テーブル名 (必須) | - |
dynamodb.throughput.write |
使用する書き込みキャパシティーユニット (WCU)。指定しない場合、dynamodb.throughput.write.ratio が計算に使用されます。 |
- |
dynamodb.throughput.write.ratio |
使用する書き込みキャパシティーユニット (WCU) の比率。 | 0.5 |
dynamodb.table.write.capacity |
スループットの計算に使用されるオンデマンドテーブルの書き込みキャパシティーユニット。このパラメータは、オンデマンドキャパシティーテーブルでのみ有効です。デフォルトはウォームスループット書き込みユニットです。 | - |
dynamodb.item.size.check.enabled |
true の場合、コネクタは項目サイズを計算して、サイズが最大サイズを超えた場合はDynamoDB テーブルに書き込む前に中止します。 | TRUE |
dynamodb.output.retry |
再試行可能な例外がある場合に実行する再試行回数を定義します。 | 10 |
エクスポートオプション
| オプション | 説明 | デフォルト |
|---|---|---|
dynamodb.export |
ddb に設定すると、AWS Glue DynamoDB エクスポートコネクタが有効になり、AWS Glue ジョブ中に新しい ExportTableToPointInTimeRequet が呼び出されます。dynamodb.s3.bucket と dynamodb.s3.prefix から渡された場所で新しいエクスポートが生成されます。s3 に設定すると、AWS DynamoDB エクスポートコネクタが有効になりますが、新しい DynamoDB エクスポートの作成はスキップされ、代わりに dynamodb.s3.bucket と dynamodb.s3.prefix がそのテーブルの過去のエクスポートの Amazon S3 ロケーションとして使用されます。 |
ddb |
dynamodb.tableArn |
読み取り元の DynamoDB テーブル。dynamodb.export が ddb に設定されている場合は必須です。 |
|
dynamodb.simplifyDDBJson |
true に設定すると、エクスポートに存在する DynamoDB JSON 構造のスキーマを簡素化するための変換を実行します。 |
誤 |
dynamodb.s3.bucket |
DynamoDB エクスポート中に一時データを保存する S3 バケット (必須)。 | |
dynamodb.s3.prefix |
DynamoDB エクスポート中に一時データを保存する S3 プレフィックス。 | |
dynamodb.s3.bucketOwner |
クロスアカウント Simple Storage Service (Amazon S3) アクセスのために必要なバケット所有者を示します。 | |
dynamodb.s3.sse.algorithm |
一時データが保存されるバケットで使用される暗号化のタイプ。有効な値は、AES256 および KMS です。 |
|
dynamodb.s3.sse.kmsKeyId |
一時データが保存される S3 バケットの暗号化に使用される AWS KMS マネージドキーの ID (該当する場合)。 | |
dynamodb.exportTime |
エクスポートが実行されるべき時点。有効な値: ISO-8601 インスタントを表す文字列。 |
汎用オプション
| オプション | 説明 | デフォルト |
|---|---|---|
dynamodb.sts.roleArn |
クロスアカウントアクセスのために引き受ける IAM ロール の ARN。 | - |
dynamodb.sts.roleSessionName |
STS セッション名。 | glue-dynamodb-sts-session |
dynamodb.sts.region |
STS クライアントのリージョン (クロスリージョンロールの引き受け用)。 | region オプションと同じ。 |
