Athena でクエリ結果を再利用する
Athena でクエリを再実行する場合、オプションで最後に保存されたクエリ結果を再利用することを選択できます。このオプションにより、パフォーマンスが向上し、スキャンされるバイト数によりコストが削減されます。クエリの結果を再利用することは、たとえば、特定の時間枠内で結果に変化がないことがわかっている場合に役立ちます。クエリの結果を再利用できる最大有効期間を指定できます。Athena では、指定した経過日数を超えない限り、保存された結果を使用します。詳細については、AWS Big Data Blog の「Reduce cost and improve query performance with Amazon Athena
主な特徴
クエリの結果の再利用を有効にすると、Athena は同じワークグループ内で以前に実行されたクエリを検索します。Athena は、一致を検出すると実行をバイパスし、前の一致する実行のクエリ結果を返します。クエリの結果の再利用はクエリごとに有効にできます。
次の条件がすべて満たされた場合、Athena は最後のクエリ結果を再利用します。
-
Athena による決定に従ってクエリ文字列が一致する。
-
データベースとカタログ名が一致する。
-
前の結果の有効期限が切れていない。
-
クエリ結果設定が前回の実行のクエリ結果設定と一致する。
-
クエリで参照されているすべてのテーブルにアクセスできる。
-
前回の結果が保存されている S3 ファイルの場所にアクセスできる。
これらの条件のいずれかが満たされない場合、Athena はキャッシュされた結果を使用せずにクエリを実行します。
考慮事項と制限事項
クエリ結果の再利用機能を使用する場合は、次の点に注意してください。
-
Athena は同じワークグループ内でのみクエリ結果を再利用します。
-
クエリ結果の再利用機能は、ワークグループの設定を優先します。クエリの結果の設定をオーバーライドすると、この機能は無効になります。
-
Amazon S3 で結果セットを生成するクエリのみがサポートされます。
SELECTとEXECUTE以外のステートメントはサポートされません。 -
AWS Glue で登録された Apache Hive テーブル、Apache Hudi テーブル、Apache Iceberg テーブル、および Linux Foundation Delta Lake テーブルがサポートされています。外部 Hive メタストアはサポートされていません。
-
フェデレーションカタログ、または外部の Hive メタストアを参照するクエリはサポートされていません。
-
Lake Formation の管理対象テーブルでは、クエリ結果の再利用はサポートされていません。
-
テーブルソースの Amazon S3 の場所が Lake Formation のデータの場所として登録されている場合、クエリ結果の再利用はサポートされません。
-
行と列のアクセス許可を持つテーブルはサポートされていません。
-
きめ細かいアクセス制御 (列や行のフィルタリングなど) があるテーブルはサポートされていません。
-
サポートされていないテーブルを参照するクエリでは、クエリ結果の再利用は対象外です。
-
以前に生成された出力ファイルを再利用するには、Athena では Amazon S3 の読み込みアクセス許可が必要です。
-
クエリ結果の再利用機能は、以前の結果の内容が変更されていないことを前提としています。Athena では以前の結果を使用する前にその結果の整合性をチェックしません。
-
前回の実行でのクエリ結果が削除されているか、Amazon S3 の別の場所に移動されている場合、同じクエリを次に実行してもクエリ結果は再利用されません。
-
古い結果が返される可能性があります。Athena では指定した最大再利用期間に達するまで、ソースデータの変更を確認しません。
-
複数の結果を再利用できる場合、Athena は最新の結果を使用します。
-
rand()またはshuffle()のような確定的ではない演算子または関数を使用するクエリは、キャッシュされた結果を使用しません。たとえば、ORDER BYを持たないLIMITは非決定論的でキャッシュされませんが、ORDER BYを持たないLIMITは決定論的でキャッシュされます。 -
JDBC でクエリ結果の再利用機能を使用するには、最低限必要なドライバーバージョンは 2.0.34.1000 です。ODBC に最低限必要なドライバー バージョンは 1.1.19.1002 です。ドライバーのダウンロード情報については、「ODBC および JDBC ドライバーを使用して Amazon Athena に接続する」を参照してください。
-
複数のデータカタログを使用するクエリでは、クエリ結果の再利用はサポートされません。
-
20 を超えるテーブルが含まれるクエリでは、クエリ結果の再利用はサポートされません。
-
サイズが 100 KB 未満のクエリ文字列の場合、コメントと空白の違いは無視され、
INNER JOINとJOINは結果を再利用するために同等として扱われます。100 KB を超えるクエリ文字列は、結果を再利用するために完全に一致している必要があります。 -
クエリ結果は、指定の最大有効期間を超過した場合、または最大有効期間が指定されていない場合はデフォルトの 60 分を超過した場合に、期限切れと見なされます。クエリの結果を再利用できる最大期間は、分数、時間数、または日数で指定できます。指定可能な最大期間は、使用する時間単位に関係なく、同様に 7 日間です。
-
マネージドクエリ結果はサポートされていません。
Athena コンソールでクエリ結果を再利用する方法
この機能を使用するには、Athena クエリエディタの [Reuse query results] (クエリ結果を再利用) オプションを有効にします。
![Athena クエリエディタで、[Reuse query results] (クエリ結果の再利用) を有効にします。](images/reusing-query-results-1.png)
クエリ結果の再利用機能を設定するには
-
Athena クエリエディタの [Reuse query results] (クエリ結果を再利用) オプションで、[up to 60 minutes ago] (最大 60 分前まで) の横にある編集アイコンを選択します。
-
[Edit reuse time] (再利用時間の編集) ダイアログボックスの右側のボックスから、時間の単位 (分、時間、または日) を選択します。
-
左側のボックスで、指定する時間の単位数を入力または選択します。入力できる最大時間は、選択した時間の単位に関係なく 7 日間分に相当します。
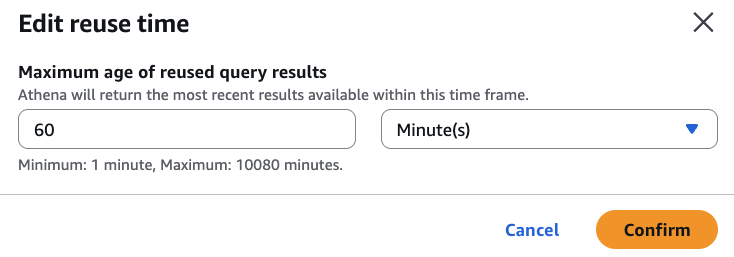
-
[確認] を選択します。
設定の変更を確認するバナーが表示され、[Reuse query results] (クエリ結果を再使用) オプションに新しい設定が表示されます。
