Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzare un filtro del vocabolario personalizzato
Una volta creato il filtro del vocabolario personalizzato, puoi includerlo nelle tue richieste di trascrizione; consulta le sezioni seguenti per alcuni esempi.
La lingua del filtro del vocabolario personalizzato da includere nella richiesta deve corrispondere al codice della lingua specificato per i file multimediali. Se utilizzi l'identificazione della lingua e specifichi le opzioni multilingue, puoi includere un filtro di vocabolario personalizzato per lingua specificata. Se le lingue dei filtri del vocabolario personalizzato non corrispondono alla lingua identificata nell'audio, i filtri non vengono applicati alla trascrizione e non vengono visualizzati avvisi o errori.
Utilizzo di un filtro del vocabolario personalizzato in una trascrizione in batch
Per utilizzare un filtro del vocabolario personalizzato con una trascrizione in batch, vedi quanto segue per alcuni esempi:
-
Accedi alla Console di gestione AWS
. -
Nel riquadro di navigazione, scegli Processi di trascrizione, quindi seleziona Crea processo (in alto a destra). Si aprirà la pagina Specifica i dettagli del processo.
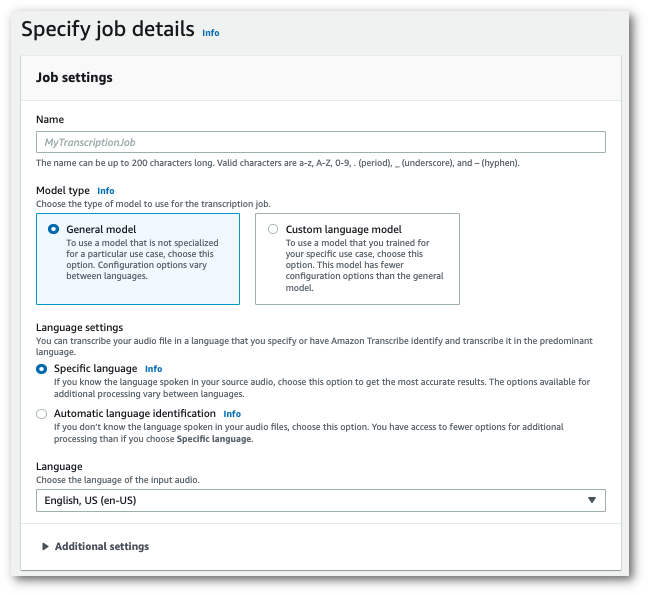
Assegna un nome al tuo processo e specifica i file multimediali di input. Facoltativamente, includi qualsiasi altro campo, quindi scegli Avanti.
-
Nella pagina Configura processo, nel pannello Rimozione contenuti, attiva il filtraggio del vocabolario.
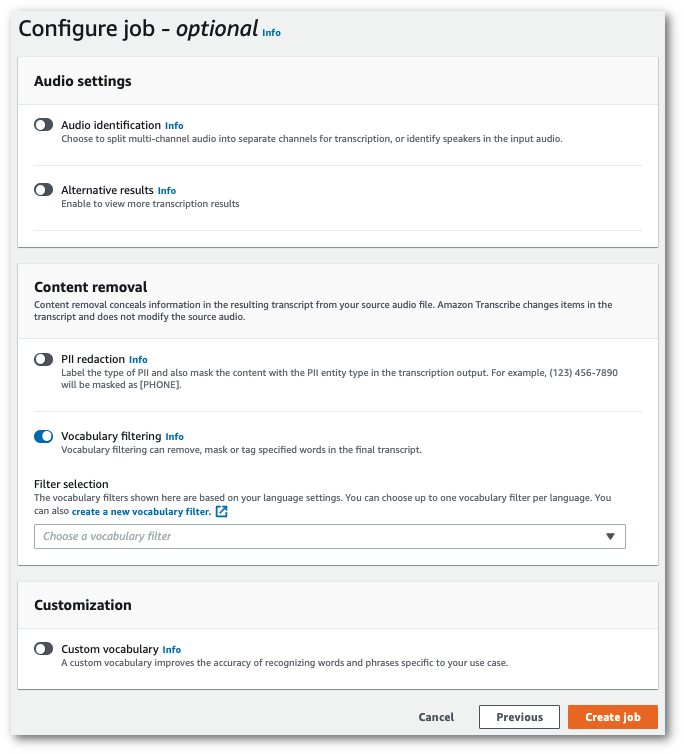
-
Seleziona il filtro del vocabolario personalizzato dal menu a discesa e specifica il metodo di filtraggio.
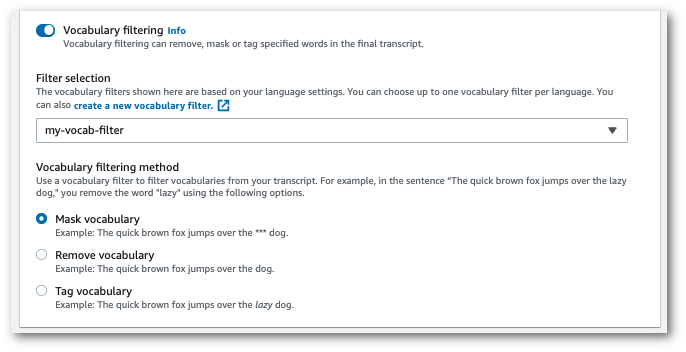
-
Seleziona Crea processo per eseguire il processo di trascrizione.
Questo esempio utilizza il comando avvia processo trascrizioneSettings con il sottoparametro VocabularyFilterName e VocabularyFilterMethod. Per ulteriori informazioni, consultare StartTranscriptionJob e Settings.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --settings VocabularyFilterName=my-first-vocabulary-filter,VocabularyFilterMethod=mask
Ecco un altro esempio che utilizza il comando avvia processo trascrizione
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-vocabulary-filter-job.json
Il file my-first-vocabulary-filter-job.json contiene il seguente corpo della richiesta.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "Settings": { "VocabularyFilterName": "my-first-vocabulary-filter", "VocabularyFilterMethod": "mask" } }
Questo esempio utilizza AWS SDK per Python (Boto3) per includere un filtro di vocabolario personalizzato utilizzando l'argomento per il metodo start_transcription_job. SettingsStartTranscriptionJob e Settings.
Per ulteriori esempi di utilizzo degli AWS SDK, inclusi esempi relativi a funzionalità specifiche, scenari e interservizi, consulta il capitolo. Esempi di codice per l'utilizzo di Amazon Transcribe AWS SDK
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', Settings = { 'VocabularyFilterName': 'my-first-vocabulary-filter', 'VocabularyFilterMethod': 'mask' } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Utilizzo di un filtro del vocabolario personalizzato in una trascrizione in streaming
Per utilizzare un filtro del vocabolario personalizzato con una trascrizione in streaming, vedi quanto segue per alcuni esempi:
-
Accedi alla Console di gestione AWS
. -
Nel riquadro di navigazione, scegli trascrizione. Real-time Scorri verso il basso fino a Impostazioni rimozione dei contenuti ed espandi questo campo se è ridotto al minimo.
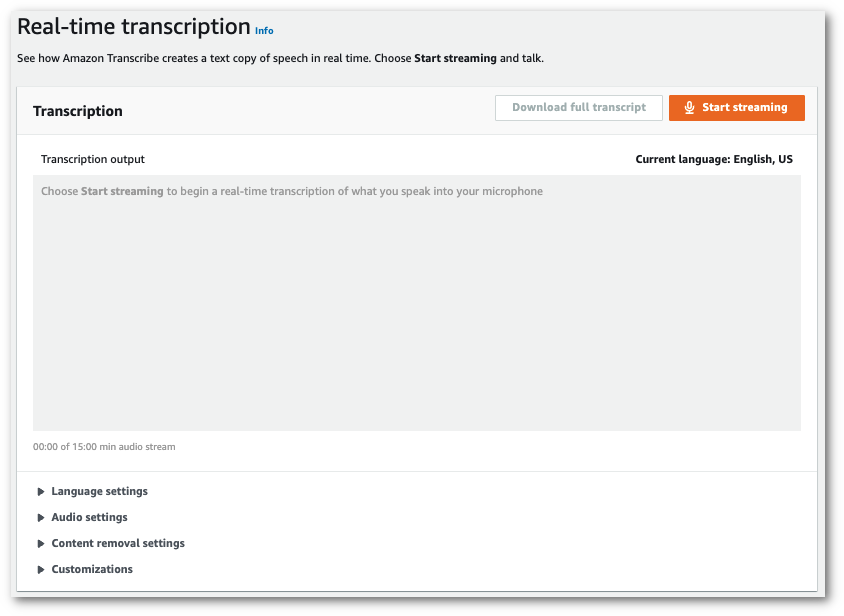
-
Attiva il filtraggio del vocabolario. Seleziona un filtro del vocabolario personalizzato dal menu a discesa e specifica il metodo di filtraggio.
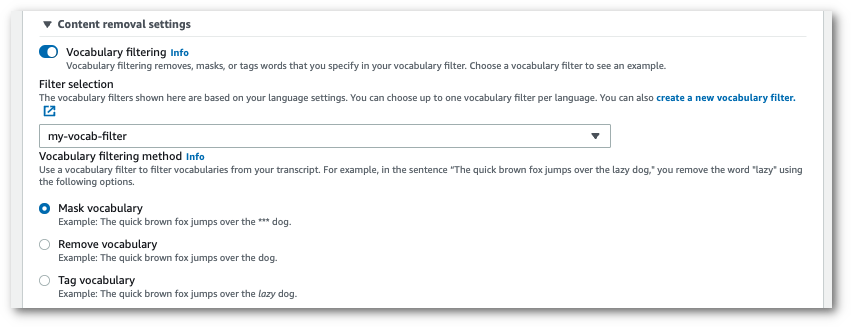
Includi tutte le altre impostazioni che desideri applicare allo flusso.
-
A questo punto puoi eseguire la trascrizione del flusso. Seleziona Avvia streaming e inizia a parlare. Per terminare la dettatura, seleziona Interrompi streaming.
Questo esempio crea una HTTP/2 richiesta che include il filtro del vocabolario e il metodo di filtro personalizzati. Per ulteriori informazioni sull'utilizzo HTTP/2 dello streaming con Amazon Transcribe, consulta. Configurare uno stream HTTP/2 Per ulteriori dettagli sui parametri e sulle intestazioni specifici di Amazon Transcribe, consulta StartStreamTranscription.
POST /stream-transcription HTTP/2 host: transcribestreaming.us-west-2.amazonaws.com X-Amz-Target: com.amazonaws.transcribe.Transcribe.StartStreamTranscriptionContent-Type: application/vnd.amazon.eventstream X-Amz-Content-Sha256:stringX-Amz-Date:20220208T235959Z Authorization: AWS4-HMAC-SHA256 Credential=access-key/20220208/us-west-2/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature=stringx-amzn-transcribe-language-code:en-USx-amzn-transcribe-media-encoding:flacx-amzn-transcribe-sample-rate:16000x-amzn-transcribe-vocabulary-filter-name:my-first-vocabulary-filterx-amzn-transcribe-vocabulary-filter-method:masktransfer-encoding: chunked
Le definizioni dei parametri sono disponibili nell'API Reference; i parametri comuni a tutte le operazioni AWS API sono elencati nella sezione Parametri comuni.
Questo esempio crea un URL predefinito che applica il filtro del vocabolario personalizzato a uno stream. WebSocket Le interruzioni di riga sono state aggiunte per la leggibilità. Per ulteriori informazioni sull'utilizzo degli WebSocket stream con, consulta. Amazon TranscribeConfigurare uno WebSocket stream Per ulteriori dettagli sui parametri, consulta StartStreamTranscription.
GET wss://transcribestreaming.us-west-2.amazonaws.com:8443/stream-transcription-websocket? &X-Amz-Algorithm=AWS4-HMAC-SHA256 &X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20220208%2Fus-west-2%2Ftranscribe%2Faws4_request &X-Amz-Date=20220208T235959Z &X-Amz-Expires=300&X-Amz-Security-Token=security-token&X-Amz-Signature=string&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date &language-code=en-US&media-encoding=flac&sample-rate=16000&vocabulary-filter-name=my-first-vocabulary-filter&vocabulary-filter-method=mask
Le definizioni dei parametri sono disponibili nell'API Reference; i parametri comuni a tutte le operazioni AWS API sono elencati nella sezione Parametri comuni.
